I Flume installation deployment
Installation address:
-
Flume official website Address: http://flume.apache.org/
-
Document viewing address : http://flume.apache.org/FlumeUserGuide.html
-
Download address : http://archive.apache.org/dist/flume/
Installation deployment:
CDH 6.3 is used locally Version 1, Flume has been installed. The installation steps are omitted here
II Flume getting started
2.1 official case of monitoring port data
Use Flume to listen to a port, collect the port data, and print it to the console.
2.1. 1 install netcat
Install netcat and check whether the port is occupied
yum -y install nc -- Check whether the port is occupied netstat -nlp | grep 44444
2.1. 2 create Flume Agent configuration file
Create the conf/lib directory under the flume installation directory, and create the flume configuration file
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 mkdir -p conf/job cd conf/job vi flume-netcat-logger.conf
Add the following:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
| configuration file | meaning |
|---|---|
| # N a m e t h e c o m p o n e n t s o n t h i s a g e n t \color{red}{\# Name the components on this agent} #Namethecomponentsonthisagent | a1: represents the name of the agent |
| a1.sources = r1 | r1: indicates the name of the source of a1 |
| a1.sinks = k1 | k1: name of sink representing a1 |
| a1.channels = c1 | c1: name of channel representing a1 |
| # D e s c r i b e / c o n f i g u r e t h e s o u r c e \color{red}{\# Describe/configure the source} #Describe/configurethesource | |
| a1.sources.r1.type = netcat | Indicates that the input source type of a1 is the port type of netcat |
| a1.sources.r1.bind = localhost | Indicates the host that a1 listens to |
| a1.sources.r1.port = 44444 | Indicates a1 listening port number |
| # D e s c r i b e t h e s i n k \color{red}{\# Describe the sink} #Describethesink | |
| a1.sinks.k1.type = logger | Indicates that a1 output destination is console logger type |
| $\color{red}{# Use a channel which buffers events in memory | |
| a1.channels.c1.type = memory | The channel type of a1 is memory |
| a1.channels.c1.capacity = 1000 | Indicates that the total capacity of the channel of a1 is 1000 event s |
| a1.channels.c1.transactionCapacity = 100 | Indicates that 100 event s are collected during channel transmission of a1, and then the transaction is committed |
| # B i n d t h e s o u r c e a n d s i n k t o t h e c h a n n e l \color{red}{\# Bind the source and sink to the channel} #Bindthesourceandsinktothechannel | |
| a1.sources.r1.channels = c1 | Indicates that r1 and c1 are connected |
| a1.sinks.k1.channel = c1 | Indicates that k1 and c1 are connected |
2.1. 3. Open flume listening port first
The first way to write:
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/ bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/job/flume-netcat-logger.conf - Dflume.root.logger=INFO,console
The second way to write:
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/ bin/flume-ng agent -c conf/ -n a1 -f conf/job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
Parameter Description:
– conf/-c: indicates that the configuration file is stored in the conf / directory
– name/-n: indicates that the agent is named a1
– conf file / - F: flume the configuration file read this time is flume telnet under the job folder conf
File.
-Dflume.root.logger=INFO,console: - D indicates that flume is dynamically modified when flume is running root. logger
Parameter attribute value, and set the console log printing level to info level. Log levels include: log, info, warn
error.
2.1. 4. Enable netcat
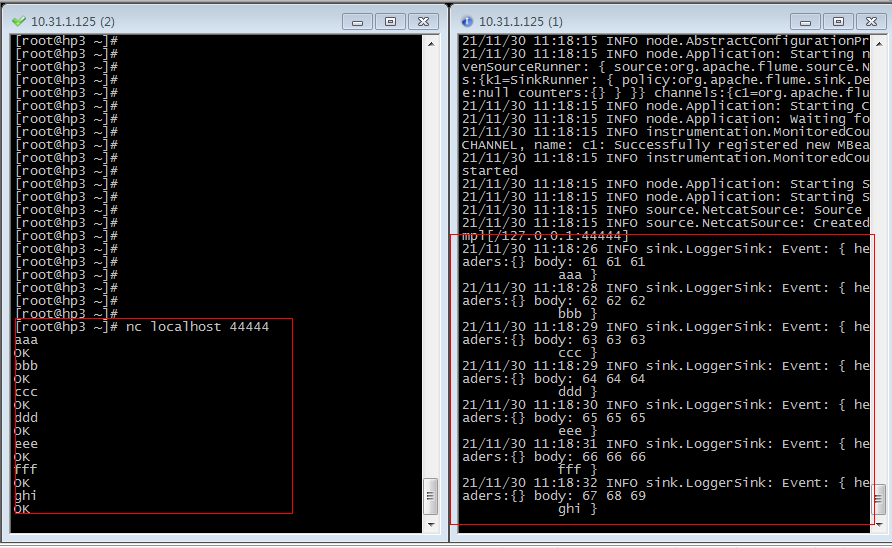
nc localhost 44444
2.1. 5. Observe the received data on the Flume monitoring page
The flume listening page receives the data input by nc and outputs it to the console
2.2 real time monitoring of single additional file
Monitor Hive logs in real time and upload them to HDFS
2.2. 1 create flume profile
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/conf/job vi flume-file-hdfs.conf
Note: if you want to read files in Linux system, you have to execute commands according to the rules of Linux commands. Because Hive logs are in the Linux system, the type of file read is: exec, which means execute. Means to execute linux commands to read files.
Add the following:
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /tmp/root/hive.log # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hp1:8020/user/flume/%Y%m%d/%H #Prefix of uploaded file a2.sinks.k2.hdfs.filePrefix = logs- #Scroll folders by time a2.sinks.k2.hdfs.round = true #How many time units to create a new folder a2.sinks.k2.hdfs.roundValue = 1 #Redefine time units a2.sinks.k2.hdfs.roundUnit = hour #Use local timestamp a2.sinks.k2.hdfs.useLocalTimeStamp = true #How many events are accumulated to flush to HDFS once a2.sinks.k2.hdfs.batchSize = 100 #Set the file type to support compression a2.sinks.k2.hdfs.fileType = DataStream #How often do I generate a new file a2.sinks.k2.hdfs.rollInterval = 60 #Set the scroll size of each file a2.sinks.k2.hdfs.rollSize = 134217700 #File scrolling is independent of the number of events a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
**Note: * * for all time-related escape sequences, there must be a key with "timestamp" in the Event Header (unless hdfs.useLocalTimeStamp is set to true, this method will automatically add timestamp using the TimestampInterceptor).
a3.sinks.k3.hdfs.useLocalTimeStamp = true
2.2. 2 run Flume
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/job/flume-file-hdfs.conf
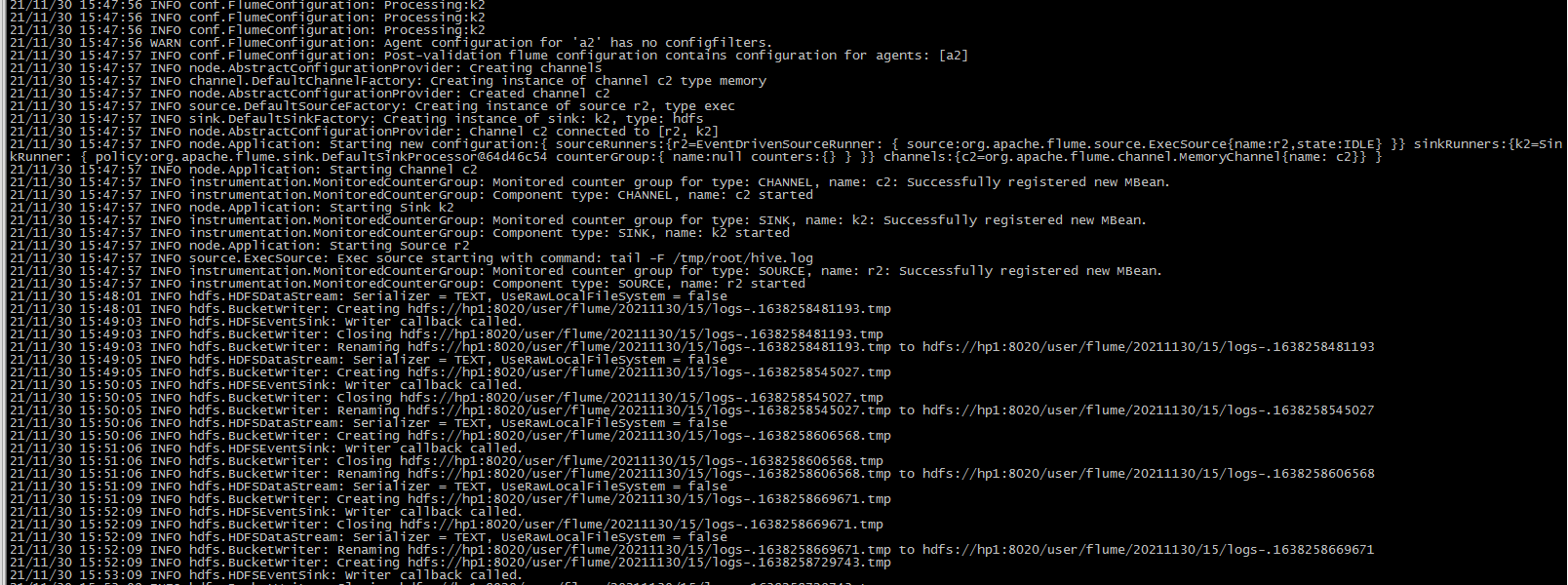
2.2. 3. Start Hive and operate Hive to generate logs
You can see from the log that the file has been uploaded to HDFS:
View on HDFS:
Automatic production of a directory in 1 hour
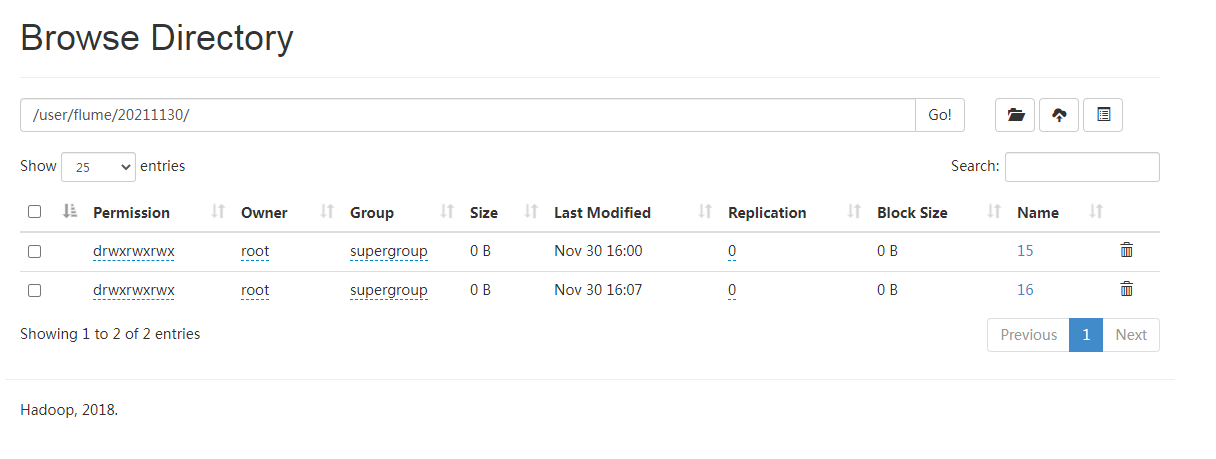
Automatically produce a file in 1 minute
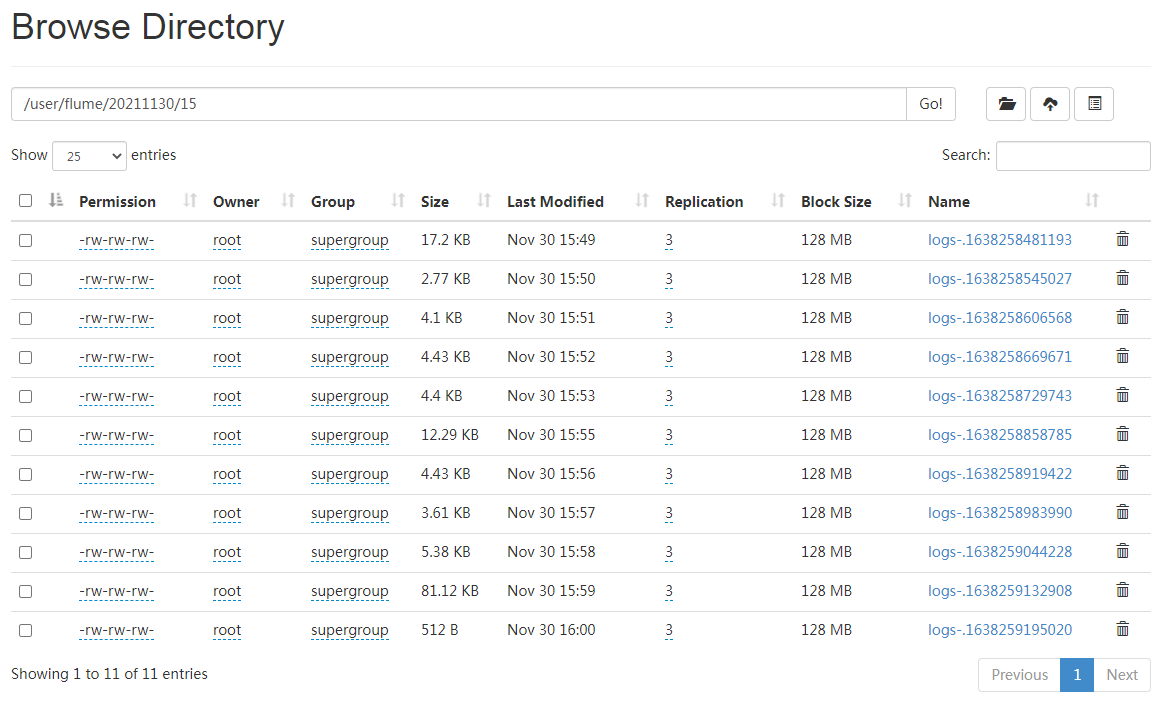
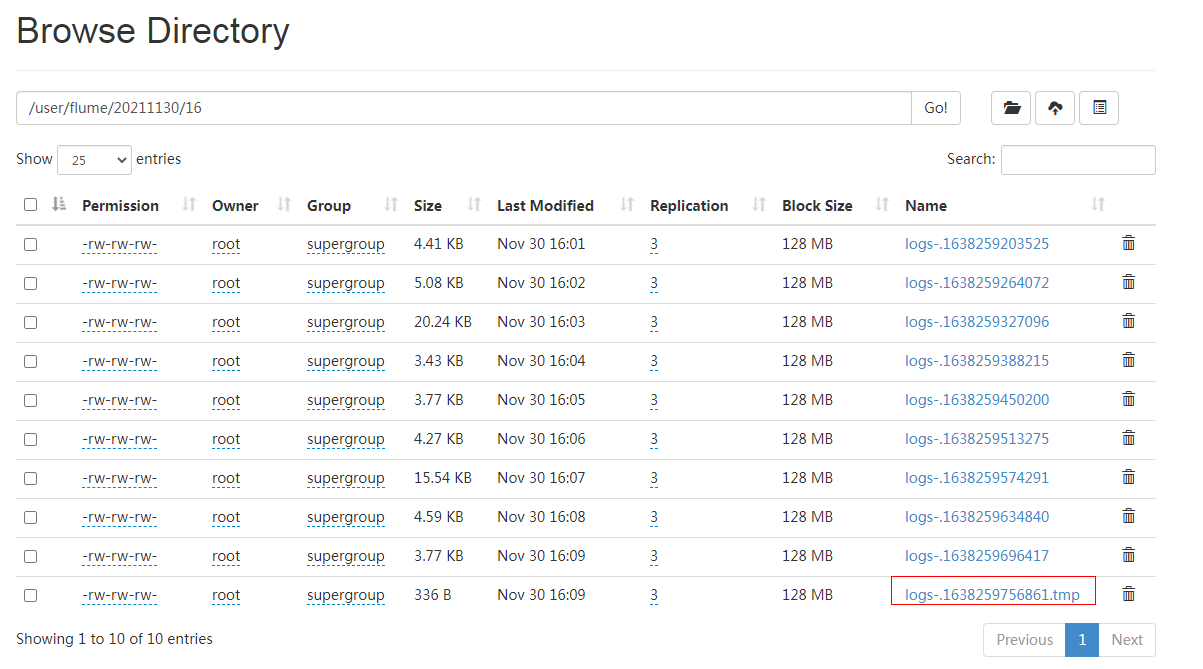
The file at the end of tmp is the file being written. It will be renamed automatically when the time comes
2.3 real time monitoring multiple new files in the directory
Use Flume to listen for files in the entire directory and upload them to HDFS
2.3. 1 create profile
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 vi conf/job/flume-dir-hdfs.conf
Add the following:
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /tmp/flume/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #Ignore all to Files at the end of tmp are not uploaded a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hp1:8020/flume/upload/%Y%m%d/%H #Prefix of uploaded file a3.sinks.k3.hdfs.filePrefix = upload- #Scroll folders by time a3.sinks.k3.hdfs.round = true #How many time units to create a new folder a3.sinks.k3.hdfs.roundValue = 1 # Redefine time units a3.sinks.k3.hdfs.roundUnit = hour #Use local timestamp a3.sinks.k3.hdfs.useLocalTimeStamp = true #How many events are accumulated to flush to HDFS once a3.sinks.k3.hdfs.batchSize = 100 #Set the file type to support compression a3.sinks.k3.hdfs.fileType = DataStream #How often do I generate a new file a3.sinks.k3.hdfs.rollInterval = 60 #Set the scroll size of each file to about 128M a3.sinks.k3.hdfs.rollSize = 134217700 #File scrolling is independent of the number of events a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
2.3. 2 start monitoring folder command
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 bin/flume-ng agent --conf conf/ --name a3 --conf-file conf/job/flume-dir-hdfs.conf
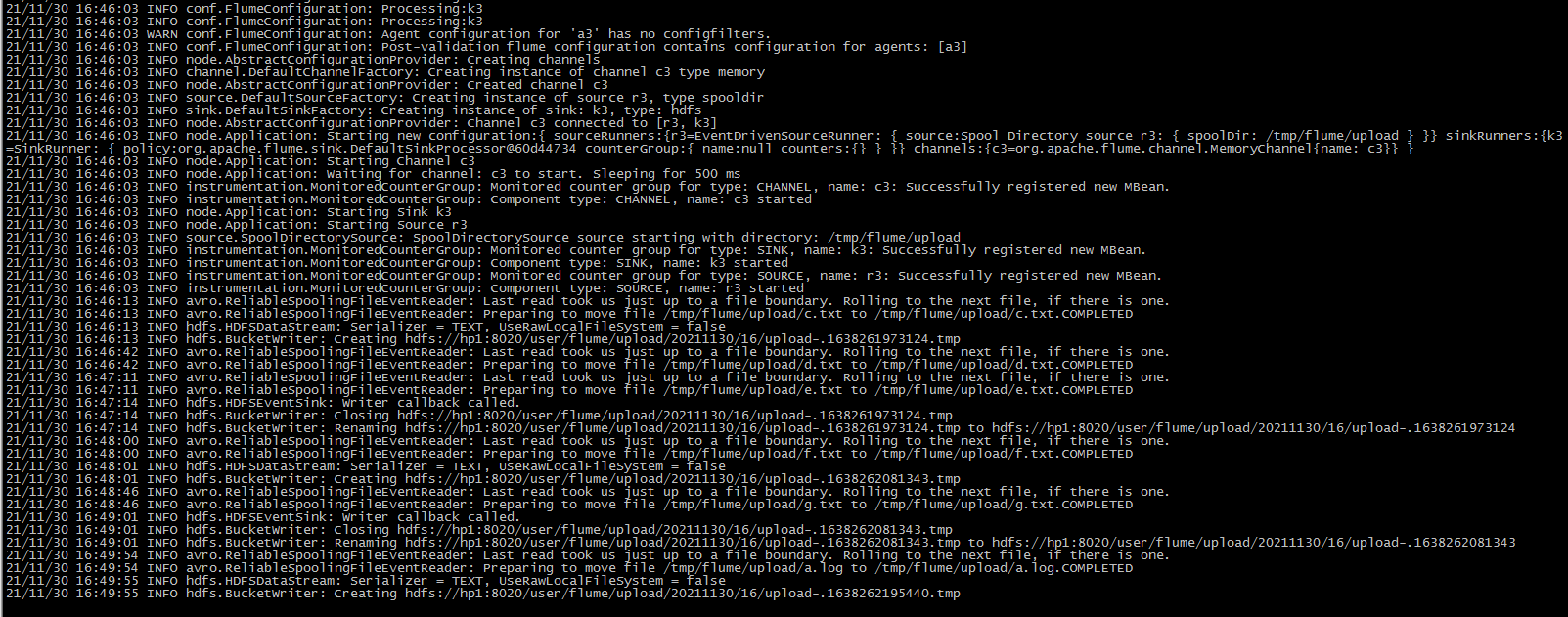
2.3. 3 view output
flume log:
From the log output, you can see that the c.txt of the original directory is directly modified to c.txt Completed, and then upload c.txt to a file with another name. From the output, you can see that the contents of multiple files will be merged and uploaded to a file on hdfs.
Output from hdfs:
Similarly, a file is created every minute, but it will be created only if it is written. If it is not written, it will not work.
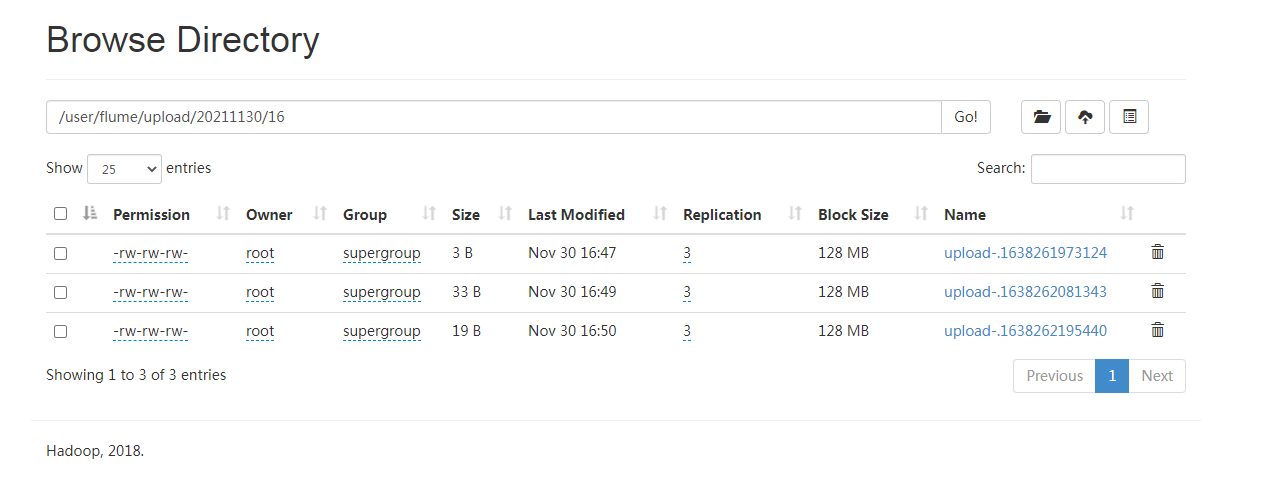
This file puts the contents of d.txt and e.txt together.
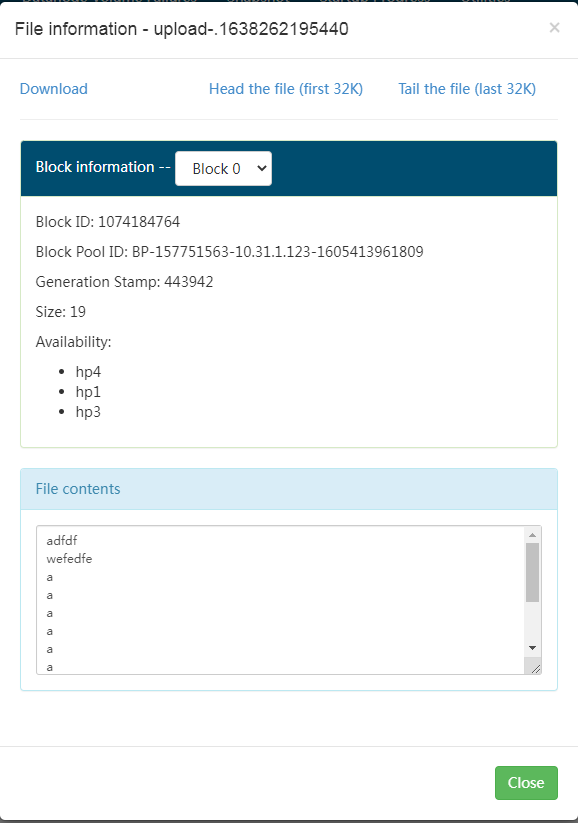
2.4 multiple additional files under the real-time monitoring directory
Exec source is applicable to monitoring a real-time added file, and can not realize continuous transmission at breakpoints; Spooldir Source is suitable for synchronizing new files, but it is not suitable for monitoring and synchronizing files with real-time logs; Taildir Source is suitable for listening to multiple real-time appended files, and can realize breakpoint continuation.
Case requirements:
Use Flume to monitor the real-time additional files of the whole directory and upload them to HDFS.
2.4. 1 create flume profile
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 vi conf/job/flume-taildir-hdfs.conf
Add the following:
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = TAILDIR a3.sources.r3.positionFile = /tmp/tail_dir.json a3.sources.r3.filegroups = f1 f2 a3.sources.r3.filegroups.f1 = /tmp/files/.*file.* a3.sources.r3.filegroups.f2 = /tmp/files2/.*log.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hp1:8020/user/flume/upload/%Y%m%d/%H #Prefix of uploaded file a3.sinks.k3.hdfs.filePrefix = upload- #Scroll folders by time a3.sinks.k3.hdfs.round = true #How many time units to create a new folder a3.sinks.k3.hdfs.roundValue = 1 #Redefine time units a3.sinks.k3.hdfs.roundUnit = hour #Use local timestamp a3.sinks.k3.hdfs.useLocalTimeStamp = true #How many events are accumulated to flush to HDFS once a3.sinks.k3.hdfs.batchSize = 100 #Set the file type to support compression a3.sinks.k3.hdfs.fileType = DataStream #How often do I generate a new file a3.sinks.k3.hdfs.rollInterval = 60 #Set the scroll size of each file to about 128M a3.sinks.k3.hdfs.rollSize = 134217700 #File scrolling is independent of the number of events a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
2.4. 2 start monitoring folder command
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567 bin/flume-ng agent --conf conf/ --name a3 --conf-file conf/job/flume-taildir-hdfs.conf
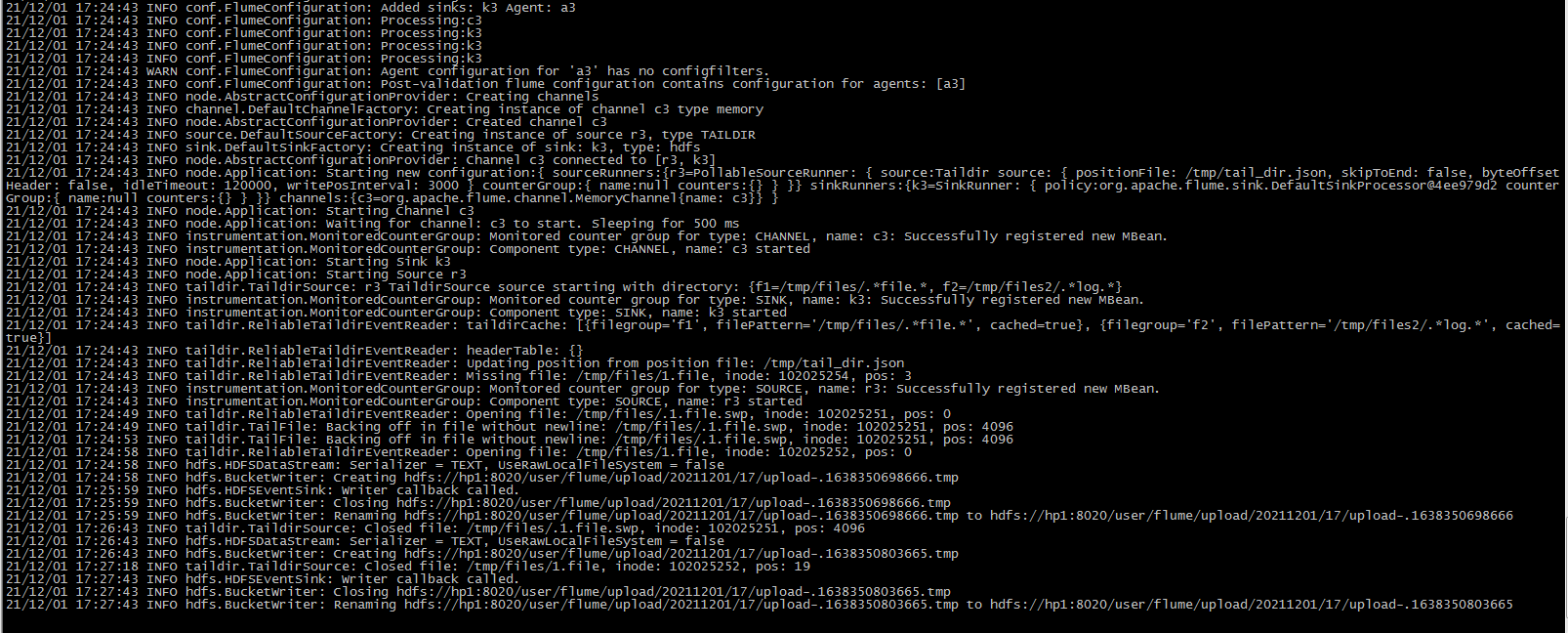
2.4. 3 add content to files folder
cd /tmp/files echo "this is a test" >> 1.file echo "aaa " >> 1.file
flume console output:
HDFS View output file:
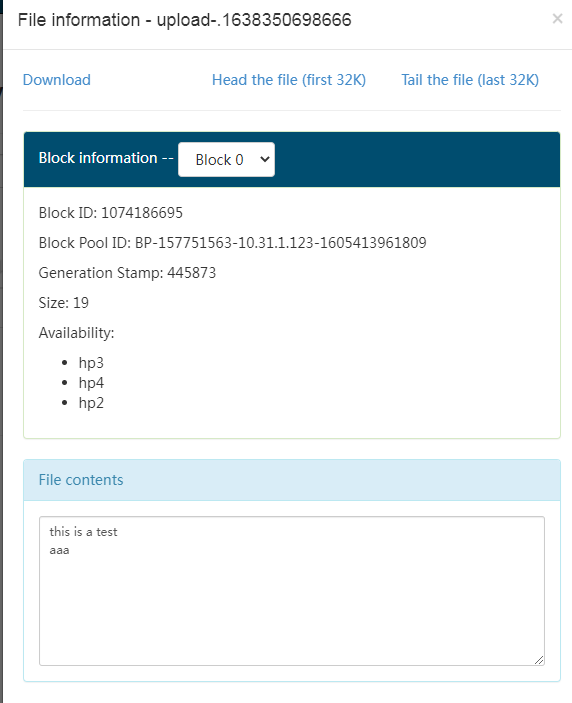
2.4.4 Taildir description
Taildir Source maintains a position File in json format, which will regularly update the latest position read by each file in the position File, so it can realize breakpoint continuation
[root@hp3 tmp]# more tail_dir.json
[{"inode":102025252,"pos":19,"file":"/tmp/files/1.file"},{"inode":20401118,"pos":8,"file":"/tmp/files2/1.log"}]
[root@hp3 tmp]#
Note:
The area where file metadata is stored in Linux is called inode. Each inode has a number. The operating system uses the inode number to identify different files. The Unix/Linux system does not use the file name, but uses the inode number to identify files.
Note that inode will not change after renaming
[root@hp3 20211201]# echo "aaa" > 1.log [root@hp3 20211201]# ll Total consumption 4 -rw-r--r--. 1 root root 4 12 January 17:32 1.log [root@hp3 20211201]# [root@hp3 20211201]# stat 1.log File:"1.log" Size: 4 Block: 8 IO Block: 4096 normal files Equipment: fd00h/64768d Inode: 34103857 Hard link: 1 jurisdiction:(0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Environmental Science: unconfined_u:object_r:user_tmp_t:s0 Recent visit: 2021-12-01 17:32:27.255733849 +0800 Recent changes: 2021-12-01 17:32:27.255733849 +0800 Recent changes: 2021-12-01 17:32:27.255733849 +0800 Created on:- [root@hp3 20211201]# [root@hp3 20211201]# mv 1.log 2.log [root@hp3 20211201]# stat 2.log File:"2.log" Size: 4 Block: 8 IO Block: 4096 normal files Equipment: fd00h/64768d Inode: 34103857 Hard link: 1 jurisdiction:(0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Environmental Science: unconfined_u:object_r:user_tmp_t:s0 Recent visit: 2021-12-01 17:32:27.255733849 +0800 Recent changes: 2021-12-01 17:32:27.255733849 +0800 Recent changes: 2021-12-01 17:32:43.011302080 +0800 Created on:- [root@hp3 20211201]#
reference resources:
- https://flume.apache.org/