Flume introduction and flume deployment, principle and use
Flume overview
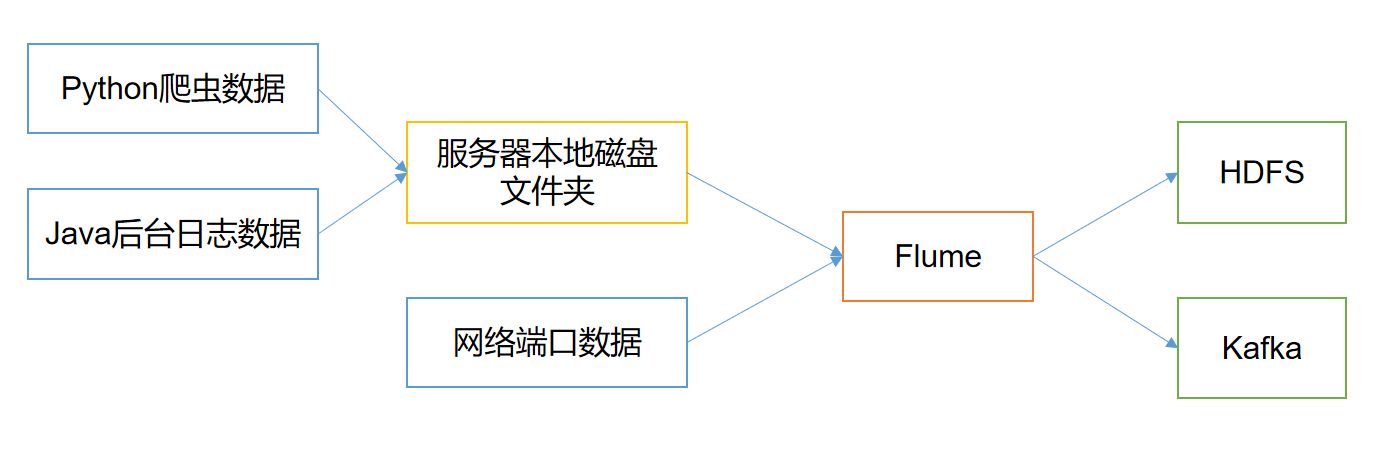
Flume is a highly available, reliable and distributed system for massive log collection, aggregation and transmission provided by Cloudera. Flume is based on streaming architecture, which is flexible and simple.
Flume's main function is to read the data from the server's local disk in real time and write the data to HDFS.
Flume architecture
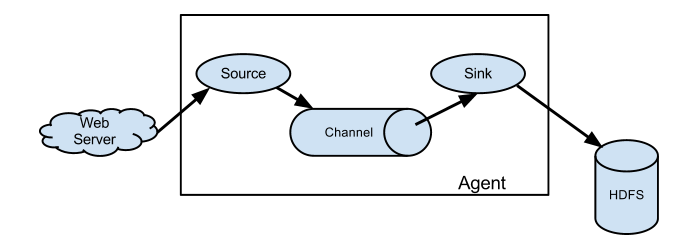
Agent
Agent is a JVM process that sends data from the source to the destination in the form of events.
Agent is mainly composed of three parts: Source, Channel and Sink.
Source
Source is the component responsible for receiving data to Flume Agent. The source component can handle various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http and legacy.
Channel
Channel is the buffer between Source and Sink. Therefore, channel allows Source and Sink to operate at different rates. Channel is thread safe and can handle the write operation of several sources and the read operation of several Sink at the same time.
Flume comes with two channels: Memory Channel and File Channel.
Memory Channel is a queue in memory. Memory Channel is applicable when there is no need to care about data loss. If you need to care about data loss, the Memory Channel should not be used, because program death, machine downtime or restart will lead to data loss.
File Channel writes all events to disk. Therefore, data will not be lost in case of program shutdown or machine downtime.
Sink
Sink constantly polls events in the Channel and removes them in batches, and writes these events in batches to the storage or indexing system, or is sent to another Flume Agent.
Sink component destinations include hdfs, logger, avro, thrift, ipc, file, HBase, solr, and custom.
Event
Transmission unit, the basic unit of Flume data transmission, sends data from the source to the destination in the form of event. Event consists of header and Body. Header is used to store some attributes of the event, which is K-V structure, and Body is used to store the data in the form of byte array.
Header(k=v)
Body(byte array)
Flume installation and deployment
URL link
(1) Flume official website address: http://flume.apache.org/
(2) Document viewing address: http://flume.apache.org/FlumeUserGuide.html
(3) Download address: http://archive.apache.org/dist/flume/
Installation deployment
# Download installation package wangting@ops01:/home/wangting > wangting@ops01:/home/wangting >cd /opt/software/ wangting@ops01:/opt/software >wget http://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz wangting@ops01:/opt/software >ll | grep flume -rw-r--r-- 1 wangting wangting 67938106 Apr 17 14:09 apache-flume-1.9.0-bin.tar.gz # Unzip apache-flume-1.9.0-bin.exe tar. GZ to / opt/module / wangting@ops01:/opt/software >tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/ # Change the directory name mv to streamline the directory wangting@ops01:/opt/software >mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume wangting@ops01:/opt/software >cd /opt/module/flume/ # Directory structure [a small number of directories are generated by subsequent tasks, such as data logs. Don't care] wangting@ops01:/opt/module/flume >ll total 180 drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin -rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG drwxr-xr-x 2 wangting wangting 4096 Apr 17 16:26 conf drwxrwxr-x 2 wangting wangting 4096 Apr 17 15:58 datas -rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES -rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib -rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE drwxrwxr-x 2 wangting wangting 4096 Apr 17 16:28 logs -rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE -rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md -rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools # Put guava-11.0.2. In the lib folder Jar removed to be compatible with Hadoop 3.1.3 wangting@ops01:/opt/module/flume >rm /opt/module/flume/lib/guava-11.0.2.jar # Configure environment variables [add the following content] wangting@ops01:/opt/module/flume >sudo vim /etc/profile #flume export FLUME_HOME=/opt/module/flume export PATH=$PATH:$FLUME_HOME/bin wangting@ops01:/opt/module/flume > wangting@ops01:/opt/module/flume > # Reference / etc/profile to take effect wangting@ops01:/opt/module/flume >source /etc/profile # Verify that the flume ng command is available wangting@ops01:/opt/module/flume >flume-ng version Flume 1.9.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: d4fcab4f501d41597bc616921329a4339f73585e Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018 From source with checksum 35db629a3bda49d23e9b3690c80737f9
Flume use case 1
Scenario: Official case of monitoring port data
Background requirements:
Use Flume to listen to a port, collect the port data, and print it to the console
- By writing Flume configuration file, define an agent task to continuously listen to port 444
- Send text data to port 44444 through the netcat tool, nc ip port [the tool here is only to simulate the data of an application]
- netcat pushes data to 44444 monitored by flume to simulate the log or data pushed by real-time data in business scenarios
- Flume reads port 444 data through the source component
- Flume writes the acquired data to the console through Sink

Preparation, writing configuration
# # # preparation # # # wangting@ops01:/home/wangting >sudo yum install -y nc wangting@ops01:/home/wangting > # Determine whether port 444 is occupied wangting@ops01:/home/wangting >sudo netstat -tunlp | grep 44444 wangting@ops01:/home/wangting >cd /opt/module/flume/ # Create a directory to store definition files wangting@ops01:/opt/module/flume >mkdir datas wangting@ops01:/opt/module/flume >cd datas/ # Create netcatsource under the data folder_ loggersink. conf wangting@ops01:/opt/module/flume/datas >touch netcatsource_loggersink.conf wangting@ops01:/opt/module/flume/datas >ls netcatsource_loggersink.conf wangting@ops01:/opt/module/flume/datas >vim netcatsource_loggersink.conf #bigdata is the name of the agent #The number of defined sources, channels and sink can be multiple, separated by spaces #Define source bigdata.sources = r1 #Define channel bigdata.channels = c1 #Define sink bigdata.sinks = k1 #Declare the specific type of source and some corresponding configurations bigdata.sources.r1.type = netcat bigdata.sources.r1.bind = ops01 bigdata.sources.r1.port = 44444 #Declare the specific type of channel and some corresponding configurations bigdata.channels.c1.type = memory #Number of event s in channel bigdata.channels.c1.capacity = 1000 #Declare the specific type of sink and some corresponding configurations bigdata.sinks.k1.type = logger #Declare the relationship between source,sink and channel bigdata.sources.r1.channels = c1 #A sink can only correspond to one channel, and a channel can correspond to multiple sinks bigdata.sinks.k1.channel = c1 [[note]: ops01 Already in/etc/hosts In the document IP Analysis 11.8.37.50 ops01
Start agent simulation transmission
# Start agent
wangting@ops01:/opt/module/flume >cd /opt/module/flume
wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf conf/ --conf-file datas/netcatsource_loggersink.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/netcatsource_loggersink.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-22 16:51:44,314 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-22 16:51:44,320 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/netcatsource_loggersink.conf
2021-04-22 16:51:44,326 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,327 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,329 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata
2021-04-22 16:51:44,329 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata' has no configfilters.
2021-04-22 16:51:44,349 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata]
2021-04-22 16:51:44,349 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-22 16:51:44,356 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory
2021-04-22 16:51:44,363 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c1
2021-04-22 16:51:44,367 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type netcat
2021-04-22 16:51:44,374 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-22 16:51:44,377 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c1 connected to [r1, k1]
2021-04-22 16:51:44,380 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@42d87c9b counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
2021-04-22 16:51:44,382 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c1
2021-04-22 16:51:44,442 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
2021-04-22 16:51:44,442 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started
2021-04-22 16:51:44,442 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-22 16:51:44,443 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-22 16:51:44,443 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting
2021-04-22 16:51:44,456 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/11.8.37.50:44444]
Scene experiment
Start another session window
# View 44444 port service status wangting@ops01:/home/wangting >netstat -tnlpu|grep 44444 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 11.8.37.50:44444 :::* LISTEN 53791/java # The 44444 port corresponds to the process pid 53791. You can see that it is a flume process wangting@ops01:/home/wangting >ll /proc/53791 | grep cwd lrwxrwxrwx 1 wangting wangting 0 Apr 22 16:52 cwd -> /opt/module/flume wangting@ops01:/home/wangting > # Use nc to send data to port 44444 of ops01 (local ip parsing to ops01). The scenario is similar to real-time streaming data push of business applications wangting@ops01:/opt/module/flume/datas >nc ops01 44444 wang OK ting OK 666 OK okokok OK test_sk OK
Console output
# The console started by flume ng agent will have new output content
# Event: { headers:{} body: 77 61 6E 67 wang }
# Event: { headers:{} body: 74 69 6E 67 ting }
# Event: { headers:{} body: 36 36 36 666 }
# Event: { headers:{} body: 6F 6B 6F 6B 6F 6B okokok }
# Event: { headers:{} body: 74 65 73 74 5F 73 6B test_sk }
2021-04-22 17:08:22,500 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 wang }
2021-04-22 17:08:22,501 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 69 6E 67 ting }
2021-04-22 17:08:22,501 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 36 36 36 666 }
2021-04-22 17:08:24,966 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6F 6B 6F 6B 6F 6B okokok }
2021-04-22 17:08:39,968 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 65 73 74 5F 73 6B test_sk }
Conclusion: use Flume to monitor a port, collect the port data, and print it to the console. The test verifies that it meets the requirements of the scene
Configure service log
wangting@ops01:/opt/module/flume >cd /opt/module/flume/conf # Configuration changes in the following lines wangting@ops01:/opt/module/flume/conf >vim log4j.properties #flume.root.logger=DEBUG,LOGFILE flume.root.logger=INFO,LOGFILE flume.log.dir=/opt/module/flume/logs flume.log.file=flume.log wangting@ops01:/opt/module/flume/conf >cd .. wangting@ops01:/opt/module/flume >mkdir logs wangting@ops01:/opt/module/flume >touch logs/flume.log wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf conf/ --conf-file datas/netcatsource_loggersink.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/netcatsource_loggersink.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Start another session
wangting@ops01:/opt/module/flume/ > wangting@ops01:/opt/module/flume/ >nc ops01 44444 aaa OK bbb OK ccc OK
End the agent and view the log file
wangting@ops01:/opt/module/flume/logs >cat flume.log
22 Apr 2021 18:10:53,011 INFO [lifecycleSupervisor-1-0] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start:62) - Configuration provider starting
22 Apr 2021 18:10:53,017 INFO [conf-file-poller-0] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run:138) - Reloading configuration file:datas/netcatsource_loggersink.conf
22 Apr 2021 18:10:53,024 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,025 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,025 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:k1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:c1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:k1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:c1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,027 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty:1117) - Added sinks: k1 Agent: bigdata
22 Apr 2021 18:10:53,027 WARN [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet:623) - Agent configuration for 'bigdata' has no configfilters.
22 Apr 2021 18:10:53,048 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration.validateConfiguration:163) - Post-validation flume configuration contains configuration for agents: [bigdata]
22 Apr 2021 18:10:53,048 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:151) - Creating channels
22 Apr 2021 18:10:53,056 INFO [conf-file-poller-0] (org.apache.flume.channel.DefaultChannelFactory.create:42) - Creating instance of channel c1 type memory
22 Apr 2021 18:10:53,061 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:205) - Created channel c1
22 Apr 2021 18:10:53,064 INFO [conf-file-poller-0] (org.apache.flume.source.DefaultSourceFactory.create:41) - Creating instance of source r1, type netcat
22 Apr 2021 18:10:53,071 INFO [conf-file-poller-0] (org.apache.flume.sink.DefaultSinkFactory.create:42) - Creating instance of sink: k1, type: logger
22 Apr 2021 18:10:53,074 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.getConfiguration:120) - Channel c1 connected to [r1, k1]
22 Apr 2021 18:10:53,078 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:162) - Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
22 Apr 2021 18:10:53,080 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:169) - Starting Channel c1
22 Apr 2021 18:10:53,134 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) - Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
22 Apr 2021 18:10:53,135 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) - Component type: CHANNEL, name: c1 started
22 Apr 2021 18:10:53,135 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:196) - Starting Sink k1
22 Apr 2021 18:10:53,135 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:207) - Starting Source r1
22 Apr 2021 18:10:53,136 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:155) - Source starting
22 Apr 2021 18:10:53,146 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:166) - Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/11.8.37.50:44444]
22 Apr 2021 18:11:03,355 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: { headers:{} body: 61 61 61 aaa }
22 Apr 2021 18:11:10,021 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: { headers:{} body: 62 62 62 bbb }
22 Apr 2021 18:11:11,101 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: { headers:{} body: 63 63 63 ccc }
22 Apr 2021 18:11:15,901 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:125) - Shutting down configuration: { sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:START} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{ name:null counters:{runner.backoffs.consecutive=1, runner.backoffs=4} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:129) - Stopping Source r1
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:START} }
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.source.NetcatSource.stop:197) - Source stopping
22 Apr 2021 18:11:16,403 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:139) - Stopping Sink k1
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{ name:null counters:{runner.backoffs.consecutive=1, runner.backoffs=4} } }
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:149) - Stopping Channel c1
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: org.apache.flume.channel.MemoryChannel{name: c1}
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:149) - Component type: CHANNEL, name: c1 stopped
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:155) - Shutdown Metric for type: CHANNEL, name: c1. channel.start.time == 1619086253135
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:161) - Shutdown Metric for type: CHANNEL, name: c1. channel.stop.time == 1619086276405
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.capacity == 1000
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.current.size == 0
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.put.attempt == 3
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.put.success == 3
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.take.attempt == 8
22 Apr 2021 18:11:16,407 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.take.success == 3
22 Apr 2021 18:11:16,407 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.stop:78) - Stopping lifecycle supervisor 12
22 Apr 2021 18:11:16,411 INFO [agent-shutdown-hook] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider.stop:84) - Configuration provider stopping
Flume use case 2
Scenario: real time monitoring of a single additional file
Background requirements:
Real time monitor the Hive log of the application. When there is new content in the Hive log, it will be uploaded to HDFS synchronously
- Create a flume profile that meets the criteria
- Execute the flume ng configuration file to enable monitoring
- Open Hive and check the Hive log file path / opt / module / Hive / logs / hiveserver2 Log for monitoring
- View and verify data on HDFS
[note]: by default, Hadoop cluster deployment, hive service and other environmental conditions have been met;
Preparation, writing configuration
Write the configuration file in / opt / module / flume / data directory, flume file HDFS conf
wangting@ops01:/opt/module/flume/datas >vim flume-file-hdfs.conf # Name the components on this agent bigdata.sources = r2 bigdata.sinks = k2 bigdata.channels = c2 # Describe/configure the source bigdata.sources.r2.type = exec # Note that the path and log name are configured according to the actual situation bigdata.sources.r2.command = tail -F /opt/module/hive/logs/hiveServer2.log bigdata.sources.r2.shell = /bin/bash -c # Describe the sink bigdata.sinks.k2.type = hdfs # Note that hdfs is configured according to the actual situation bigdata.sinks.k2.hdfs.path = hdfs://ops01:8020/flume/%Y%m%d/%H #Prefix of uploaded file bigdata.sinks.k2.hdfs.filePrefix = logs- #Scroll folders by time bigdata.sinks.k2.hdfs.round = true #How many time units to create a new folder bigdata.sinks.k2.hdfs.roundValue = 1 #Redefine time units bigdata.sinks.k2.hdfs.roundUnit = hour #Use local timestamp bigdata.sinks.k2.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush ing to HDFS bigdata.sinks.k2.hdfs.batchSize = 100 #Set the file type to support compression bigdata.sinks.k2.hdfs.fileType = DataStream #How often do I generate a new file bigdata.sinks.k2.hdfs.rollInterval = 60 #Set the scroll size of each file bigdata.sinks.k2.hdfs.rollSize = 134217700 #The scrolling of files is independent of the number of events bigdata.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory bigdata.channels.c2.type = memory bigdata.channels.c2.capacity = 1000 bigdata.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel bigdata.sources.r2.channels = c2 bigdata.sinks.k2.channel = c2
Start agent
Switch to the / opt/module/flume application directory and start the agent
wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf datas/ --conf-file datas/flume-file-hdfs.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/datas:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/flume-file-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-23 11:18:31,268 INFO [lifecycleSupervisor-1-0] node.PollingPropertiesFileConfigurationProvider (PollingPropertiesFileConfigurationProvider.java:start(62)) - Configuration provider starting
2021-04-23 11:18:31,275 INFO [conf-file-poller-0] node.PollingPropertiesFileConfigurationProvider (PollingPropertiesFileConfigurationProvider.java:run(138)) - Reloading configuration file:datas/flume-file-hdfs.conf
2021-04-23 11:18:31,282 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,283 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:r2
2021-04-23 11:18:31,283 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:r2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addProperty(1117)) - Added sinks: k2 Agent: bigdata
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,288 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,288 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,288 WARN [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:validateConfigFilterSet(623)) - Agent configuration for 'bigdata' has no configfilters.
2021-04-23 11:18:31,309 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:validateConfiguration(163)) - Post-validation flume configuration contains configuration for agents: [bigdata]
2021-04-23 11:18:31,310 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:loadChannels(151)) - Creating channels
2021-04-23 11:18:31,317 INFO [conf-file-poller-0] channel.DefaultChannelFactory (DefaultChannelFactory.java:create(42)) - Creating instance of channel c2 type memory
2021-04-23 11:18:31,324 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:loadChannels(205)) - Created channel c2
2021-04-23 11:18:31,326 INFO [conf-file-poller-0] source.DefaultSourceFactory (DefaultSourceFactory.java:create(41)) - Creating instance of source r2, type exec
2021-04-23 11:18:31,333 INFO [conf-file-poller-0] sink.DefaultSinkFactory (DefaultSinkFactory.java:create(42)) - Creating instance of sink: k2, type: hdfs
2021-04-23 11:18:31,343 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:getConfiguration(120)) - Channel c2 connected to [r2, k2]
2021-04-23 11:18:31,346 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(162)) - Starting new configuration:{ sourceRunners:{r2=EventDrivenSourceRunner: { source:org.apache.flume.source.ExecSource{name:r2,state:IDLE} }} sinkRunners:{k2=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@3a74bd67 counterGroup:{ name:null counters:{} } }} channels:{c2=org.apache.flume.channel.MemoryChannel{name: c2}} }
2021-04-23 11:18:31,348 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(169)) - Starting Channel c2
2021-04-23 11:18:31,406 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: CHANNEL, name: c2: Successfully registered new MBean.
2021-04-23 11:18:31,406 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: CHANNEL, name: c2 started
2021-04-23 11:18:31,406 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(196)) - Starting Sink k2
2021-04-23 11:18:31,407 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(207)) - Starting Source r2
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-1] source.ExecSource (ExecSource.java:start(170)) - Exec source starting with command: tail -F /opt/module/hive/logs/hiveServer2.log
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: SINK, name: k2: Successfully registered new MBean.
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: SINK, name: k2 started
2021-04-23 11:18:31,409 INFO [lifecycleSupervisor-1-1] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: SOURCE, name: r2: Successfully registered new MBean.
2021-04-23 11:18:31,409 INFO [lifecycleSupervisor-1-1] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: SOURCE, name: r2 started
2021-04-23 11:18:35,425 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.HDFSDataStream (HDFSDataStream.java:configure(57)) - Serializer = TEXT, UseRawLocalFileSystem = false
2021-04-23 11:18:35,536 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.BucketWriter (BucketWriter.java:open(246)) - Creating hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp
2021-04-23 11:18:35,873 INFO [hdfs-k2-call-runner-0] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-23 11:18:39,736 INFO [Thread-9] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-04-23 11:19:36,698 INFO [hdfs-k2-roll-timer-0] hdfs.HDFSEventSink (HDFSEventSink.java:run(393)) - Writer callback called.
2021-04-23 11:19:36,698 INFO [hdfs-k2-roll-timer-0] hdfs.BucketWriter (BucketWriter.java:doClose(438)) - Closing hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp
2021-04-23 11:19:36,722 INFO [hdfs-k2-call-runner-8] hdfs.BucketWriter (BucketWriter.java:call(681)) - Renaming hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp to hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426
2021-04-23 11:20:03,947 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.HDFSDataStream (HDFSDataStream.java:configure(57)) - Serializer = TEXT, UseRawLocalFileSystem = false
2021-04-23 11:20:03,963 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.BucketWriter (BucketWriter.java:open(246)) - Creating hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp
2021-04-23 11:20:06,991 INFO [Thread-15] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-04-23 11:21:03,984 INFO [hdfs-k2-roll-timer-0] hdfs.HDFSEventSink (HDFSEventSink.java:run(393)) - Writer callback called.
2021-04-23 11:21:03,985 INFO [hdfs-k2-roll-timer-0] hdfs.BucketWriter (BucketWriter.java:doClose(438)) - Closing hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp
2021-04-23 11:21:03,998 INFO [hdfs-k2-call-runner-2] hdfs.BucketWriter (BucketWriter.java:call(681)) - Renaming hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp to hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947
[note]: hdfs, hive, yarn and other cluster services have been enabled by default; The deployment and construction of components will not be described in detail here
Scene experiment
Login Hive interactive command line
# Log in to hive wangting@ops01:/opt/module/hive >beeline -u jdbc:hive2://ops01:10000 -n wangting # Execute the correct command 0: jdbc:hive2://ops01:10000> show tables; INFO : Compiling command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4): show tables INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4); Time taken: 0.02 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4): show tables INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4); Time taken: 0.004 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +-------------------------------------+ | tab_name | +-------------------------------------+ | dept | | emp | | f_dmcp_n013_judicative_doc_content | | stu_partition | | test | | test2 | +-------------------------------------+ 6 rows selected (0.037 seconds) # Execute an error command and throw the error cannot recognize input near 'show', 'tablesss' 0: jdbc:hive2://ops01:10000> show tablesssssss; Error: Error while compiling statement: FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablesssssss' '<EOF>' in ddl statement (state=42000,code=40000) # Execute another command case 0: jdbc:hive2://ops01:10000> select count(*) from emp; INFO : Compiling command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea): select count(*) from emp INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null) INFO : Completed compiling command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea); Time taken: 0.119 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea): select count(*) from emp WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. INFO : Query ID = wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea INFO : Total jobs = 1 INFO : Launching Job 1 out of 1 INFO : Starting task [Stage-1:MAPRED] in serial mode INFO : Number of reduce tasks determined at compile time: 1 INFO : In order to change the average load for a reducer (in bytes): INFO : set hive.exec.reducers.bytes.per.reducer=<number> INFO : In order to limit the maximum number of reducers: INFO : set hive.exec.reducers.max=<number> INFO : In order to set a constant number of reducers: INFO : set mapreduce.job.reduces=<number> INFO : number of splits:1 INFO : Submitting tokens for job: job_1615531413182_0098 INFO : Executing with tokens: [] INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_0098/ INFO : Starting Job = job_1615531413182_0098, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0098/ INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0098 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2021-04-23 11:20:12,466 Stage-1 map = 0%, reduce = 0% INFO : 2021-04-23 11:20:20,663 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.53 sec INFO : 2021-04-23 11:20:28,849 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.4 sec INFO : MapReduce Total cumulative CPU time: 5 seconds 400 msec INFO : Ended Job = job_1615531413182_0098 INFO : MapReduce Jobs Launched: INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.4 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS INFO : Total MapReduce CPU Time Spent: 5 seconds 400 msec INFO : Completed executing command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea); Time taken: 25.956 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +------+ | _c0 | +------+ | 14 | +------+ 1 row selected (26.095 seconds) # # Similarly, execute the error command again and throw the error Table not found 'empaaaaa' 0: jdbc:hive2://ops01:10000> select count(*) from empaaaaa; Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'empaaaaa' (state=42S02,code=10001) 0: jdbc:hive2://ops01:10000> # Exit ctrl+c
If there are no problems with the above operations, you can check whether there are expected log files on hdfs and check hdfs to verify
wangting@ops01:/home/wangting > # Check whether the flume directory exists under the hdfs root directory wangting@ops01:/home/wangting >hdfs dfs -ls / 2021-04-23 11:24:55,647 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 9 items drwxr-xr-x - wangting supergroup 0 2021-03-17 11:44 /20210317 drwxr-xr-x - wangting supergroup 0 2021-03-19 10:51 /20210319 drwxr-xr-x - wangting supergroup 0 2021-04-23 11:18 /flume -rw-r--r-- 3 wangting supergroup 338075860 2021-03-12 11:50 /hadoop-3.1.3.tar.gz drwxr-xr-x - wangting supergroup 0 2021-04-04 11:07 /test.db drwxr-xr-x - wangting supergroup 0 2021-03-19 11:14 /testgetmerge drwxr-xr-x - wangting supergroup 0 2021-04-10 16:23 /tez drwx------ - wangting supergroup 0 2021-04-02 15:14 /tmp drwxr-xr-x - wangting supergroup 0 2021-04-02 15:25 /user # Check whether the / flume directory is in accordance with flume file HDFS The hours and conf dates in the directory are defined wangting@ops01:/home/wangting >hdfs dfs -ls /flume 2021-04-23 11:25:05,199 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items drwxr-xr-x - wangting supergroup 0 2021-04-23 11:18 /flume/20210423 wangting@ops01:/home/wangting >hdfs dfs -ls /flume/20210423/ 2021-04-23 11:25:14,685 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items drwxr-xr-x - wangting supergroup 0 2021-04-23 11:21 /flume/20210423/11 wangting@ops01:/home/wangting >hdfs dfs -ls /flume/20210423/11 2021-04-23 11:25:19,814 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 2 items -rw-r--r-- 3 wangting supergroup 4949 2021-04-23 11:19 /flume/20210423/11/logs-.1619147915426 -rw-r--r-- 3 wangting supergroup 1297 2021-04-23 11:21 /flume/20210423/11/logs-.1619148003947 # Check the log file logs-.1619147915426 in the hour directory at 11. You can see the relevant error reports of cannot recognize input near 'show', 'tablesss' wangting@ops01:/home/wangting >hdfs dfs -cat /flume/20210423/11/logs-.1619147915426 2021-04-23 11:25:37,024 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS 2021-04-23 11:25:37,749 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1542) at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39) at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39) at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56) at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:748) FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablessss' '<EOF>' in ddl statement OK OK NoViableAltException(24@[917:1: ddlStatement : ( createDatabaseStatement | switchDatabaseStatement | dropDatabaseStatement | createTableStatement | dropTableStatement | truncateTableStatement | alterStatement | descStatement | showStatement | metastoreCheck | createViewStatement | createMaterializedViewStatement | dropViewStatement | dropMaterializedViewStatement | createFunctionStatement | createMacroStatement | dropFunctionStatement | reloadFunctionStatement | dropMacroStatement | analyzeStatement | lockStatement | unlockStatement | lockDatabase | unlockDatabase | createRoleStatement | dropRoleStatement | ( grantPrivileges )=> grantPrivileges | ( revokePrivileges )=> revokePrivileges | showGrants | showRoleGrants | showRolePrincipals | showRoles | grantRole | revokeRole | setRole | showCurrentRole | abortTransactionStatement | killQueryStatement | resourcePlanDdlStatements );]) at org.antlr.runtime.DFA.noViableAlt(DFA.java:158) at org.antlr.runtime.DFA.predict(DFA.java:144) at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:4244) at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:2494) at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1420) at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:220) at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:74) at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:67) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:616) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1826) at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1773) at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1768) at org.apache.hadoop.hive.ql.reexec.ReExecDriver.compileAndRespond(ReExecDriver.java:126) at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:197) at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:260) at org.apache.hive.service.cli.operation.Operation.run(Operation.java:247) at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:541) at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:527) at sun.reflect.GeneratedMethodAccessor43.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78) at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36) at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59) at com.sun.proxy.$Proxy37.executeStatementAsync(Unknown Source) at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:312) at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:562) at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1557) at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1542) at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39) at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39) at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56) at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:748) FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablesssssss' '<EOF>' in ddl statement # Check the log file logs-.1619148003947 under hour 11 directory, and you can see the relevant error reports of Table not found 'empaaaaa' wangting@ops01:/home/wangting >hdfs dfs -cat /flume/20210423/11/logs-.1619148003947 2021-04-23 11:25:50,566 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS 2021-04-23 11:25:51,293 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Query ID = wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1615531413182_0098, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0098/ Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0098 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2021-04-23 11:20:12,466 Stage-1 map = 0%, reduce = 0% 2021-04-23 11:20:20,663 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.53 sec 2021-04-23 11:20:28,849 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.4 sec MapReduce Total cumulative CPU time: 5 seconds 400 msec Ended Job = job_1615531413182_0098 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.4 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS Total MapReduce CPU Time Spent: 5 seconds 400 msec OK FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'empaaaaa'
Conclusion: the Hive log is monitored in real time. When there is new content in the Hive log, the content is uploaded to HDFS synchronously. The test verifies that it meets the needs of the scene
Flume use case 3
Scenario: real time monitoring multiple new files in the directory
Case 2 uses exec for a single file, and case 3 uses spooldir for multiple files
Background requirements:
Use Flume to monitor the file changes of the whole directory under a certain path of the server and upload them to HDFS
- Create a flume profile that meets the criteria
- Execute the flume ng configuration file to enable monitoring
- Add files to the upload directory. The monitored directory is / opt/module/flume/upload/
- View and verify data on HDFS
- Check whether the uploaded files in the / opt/module/flume/upload directory have been marked as COMPLETED end The tmp suffix ending file was not uploaded.
Preparation, writing configuration
Write the configuration file in / opt / module / flume / data directory, flume dir HDFS conf
wangting@ops01:/opt/module/flume >ls bin CHANGELOG conf datas DEVNOTES doap_Flume.rdf docs lib LICENSE logs NOTICE README.md RELEASE-NOTES tools wangting@ops01:/opt/module/flume >mkdir upload wangting@ops01:/opt/module/flume >cd datas/ wangting@ops01:/opt/module/flume/datas >ls flume-file-hdfs.conf netcatsource_loggersink.conf wangting@ops01:/opt/module/flume/datas >vim flume-dir-hdfs.conf # source/channel/sink bigdata.sources = r3 bigdata.sinks = k3 bigdata.channels = c3 # Describe/configure the source bigdata.sources.r3.type = spooldir bigdata.sources.r3.spoolDir = /opt/module/flume/upload bigdata.sources.r3.fileSuffix = .COMPLETED bigdata.sources.r3.fileHeader = true #Ignore all to Files at the end of tmp are not uploaded bigdata.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink bigdata.sinks.k3.type = hdfs bigdata.sinks.k3.hdfs.path = hdfs://ops01:8020/flume/upload/%Y%m%d/%H #Prefix of uploaded file bigdata.sinks.k3.hdfs.filePrefix = upload- #Scroll folders by time bigdata.sinks.k3.hdfs.round = true #How many time units to create a new folder bigdata.sinks.k3.hdfs.roundValue = 1 #Redefine time units bigdata.sinks.k3.hdfs.roundUnit = hour #Use local timestamp bigdata.sinks.k3.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush ing to HDFS bigdata.sinks.k3.hdfs.batchSize = 100 #Set the file type to support compression bigdata.sinks.k3.hdfs.fileType = DataStream #How often do I generate a new file bigdata.sinks.k3.hdfs.rollInterval = 60 #Set the scroll size of each file to about 128M bigdata.sinks.k3.hdfs.rollSize = 134217700 #The scrolling of files is independent of the number of events bigdata.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory bigdata.channels.c3.type = memory bigdata.channels.c3.capacity = 1000 bigdata.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel bigdata.sources.r3.channels = c3 bigdata.sinks.k3.channel = c3
Start agent
wangting@ops01:/opt/module/flume >ll upload/ total 0 wangting@ops01:/opt/module/flume >flume-ng agent -c conf/ -n bigdata -f datas/flume-dir-hdfs.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application -n bigdata -f datas/flume-dir-hdfs.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[Note 1]
flume-ng agent -c conf/ -n bigdata -f datas/flume-dir-hdfs.conf
-c is the abbreviation of -- conf
-f is the abbreviation of -- conf file
-n is the abbreviation of -- name
Equivalent to flume ng agent -- conf conf / -- name bigdata -- conf file data / flume dir HDFS conf
[Note 2]
dir is monitored here, the dimension is directory level, and it is a new file; That is to monitor the new changes of files in the monitored directory; Therefore, when using Spooling Directory Source, do not continuously modify the file after uploading and creating in the monitoring directory; The uploaded file will be displayed as COMPLETED end; The monitored folder scans for file changes every 500 milliseconds.
Scene experiment
wangting@ops01:/home/wangting >cd /opt/module/flume/upload/ # The current directory is empty wangting@ops01:/opt/module/flume/upload >ll total 0 # Simulate one txt end file wangting@ops01:/opt/module/flume/upload >touch wang.txt # Simulate one tmp end file wangting@ops01:/opt/module/flume/upload >touch ting.tmp # # Simulate one log end file wangting@ops01:/opt/module/flume/upload >touch ting.log # Simulate a band tmp, but the file at the end of other contents wangting@ops01:/opt/module/flume/upload >touch bigdata.tmp_bak # After creation, ls -l view the validation # Ignore all is defined in the configuration file The file at the end of TMP does not upload the configuration bigdata sources. r3. ignorePattern = ([^ ]*\.tmp) wangting@ops01:/opt/module/flume/upload >ll total 0 -rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 bigdata.tmp_bak.COMPLETED -rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 ting.log.COMPLETED -rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 ting.tmp -rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 wang.txt.COMPLETED # So the result is The at the end of tmp is not read, and others are read; view log wangting@ops01:/opt/module/flume/upload >cd /opt/module/flume/logs/ wangting@ops01:/opt/module/flume/logs >ll total 20 -rw-rw-r-- 1 wangting wangting 19333 Apr 24 14:12 flume.log wangting@ops01:/opt/module/flume/logs >tail -f flume.log 24 Apr 2021 14:11:05,980 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile:497) - Preparing to move file /opt/module/flume/upload/wang.txt to /opt/module/flume/upload/wang.txt.COMPLETED 24 Apr 2021 14:11:07,984 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents:384) - Last read took us just up to a file boundary. Rolling to the next file, if there is one. 24 Apr 2021 14:11:07,985 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile:497) - Preparing to move file /opt/module/flume/upload/bigdata.tmp_bak to /opt/module/flume/upload/bigdata.tmp_bak.COMPLETED 24 Apr 2021 14:11:10,677 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSDataStream.configure:57) - Serializer = TEXT, UseRawLocalFileSystem = false 24 Apr 2021 14:11:10,860 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.BucketWriter.open:246) - Creating hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp 24 Apr 2021 14:11:11,200 INFO [hdfs-k3-call-runner-0] (org.apache.hadoop.conf.Configuration.logDeprecation:1395) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS 24 Apr 2021 14:11:15,019 INFO [Thread-8] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 24 Apr 2021 14:12:11,989 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called. 24 Apr 2021 14:12:11,990 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp 24 Apr 2021 14:12:12,015 INFO [hdfs-k3-call-runner-6] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp to hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678 # Get HDFS related content information hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678
View hdfs information
wangting@ops01:/opt/module/flume/upload >hdfs dfs -ls /flume/upload/20210424/ 2021-04-24 14:13:20,594 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items drwxr-xr-x - wangting supergroup 0 2021-04-24 14:12 /flume/upload/20210424/14 wangting@ops01:/opt/module/flume/upload >hdfs dfs -ls /flume/upload/20210424/14 2021-04-24 14:13:27,463 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items -rw-r--r-- 3 wangting supergroup 3 2021-04-24 14:12 /flume/upload/20210424/14/upload-.1619244670678 wangting@ops01:/opt/module/flume/upload >
Flume use case 4
Scenario: real time monitoring multiple additional files in the directory
Background needs
- Create a flume profile that meets the criteria
- Execute the configuration file and open the agent to monitor the change of file status in the directory\
- Add content to monitoring file
echo wang >> download/file1.txt
echo ting >> download/file2.txt - Monitored file path / opt/module/flume/download
- View data on HDFS
Preparation, writing configuration
Write the configuration file in / opt / module / flume / data directory, flume taildir HDFS conf
wangting@ops01:/opt/module/flume >mkdir download wangting@ops01:/opt/module/flume >cd datas/ wangting@ops01:/opt/module/flume/datas >ll total 12 -rw-rw-r-- 1 wangting wangting 1533 Apr 24 14:05 flume-dir-hdfs.conf -rw-rw-r-- 1 wangting wangting 1405 Apr 23 11:13 flume-file-hdfs.conf -rw-rw-r-- 1 wangting wangting 787 Apr 17 15:58 netcatsource_loggersink.conf wangting@ops01:/opt/module/flume/datas >vim flume-taildir-hdfs.conf bigdata.sources = r3 bigdata.sinks = k3 bigdata.channels = c3 # Describe/configure the source bigdata.sources.r3.type = TAILDIR bigdata.sources.r3.positionFile = /opt/module/flume/tail_dir.json bigdata.sources.r3.filegroups = f1 f2 bigdata.sources.r3.filegroups.f1 = /opt/module/flume/download/.*file.* bigdata.sources.r3.filegroups.f2 = /opt/module/flume/download/.*log.* # Describe the sink bigdata.sinks.k3.type = hdfs bigdata.sinks.k3.hdfs.path = hdfs://ops01:8020/flume/download/%Y%m%d/%H #Prefix of uploaded file bigdata.sinks.k3.hdfs.filePrefix = upload- #Scroll folders by time bigdata.sinks.k3.hdfs.round = true #How many time units to create a new folder bigdata.sinks.k3.hdfs.roundValue = 1 #Redefine time units bigdata.sinks.k3.hdfs.roundUnit = hour #Use local timestamp bigdata.sinks.k3.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush ing to HDFS bigdata.sinks.k3.hdfs.batchSize = 100 #Set the file type to support compression bigdata.sinks.k3.hdfs.fileType = DataStream #How often do I generate a new file bigdata.sinks.k3.hdfs.rollInterval = 60 #Set the scroll size of each file to about 128M bigdata.sinks.k3.hdfs.rollSize = 134217700 #The scrolling of files is independent of the number of events bigdata.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memorytail bigdata.channels.c3.type = memory bigdata.channels.c3.capacity = 1000 bigdata.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel bigdata.sources.r3.channels = c3 bigdata.sinks.k3.channel = c3
Start agent
wangting@ops01:/opt/module/flume >flume-ng agent -c conf/ -n bigdata -f datas/flume-taildir-hdfs.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application -n bigdata -f datas/flume-taildir-hdfs.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Scene experiment
wangting@ops01:/opt/module/flume >ll
total 188
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin
-rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x 2 wangting wangting 4096 Apr 22 18:18 conf
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:59 datas
-rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES
-rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:56 download
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib
-rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE
drwxrwxr-x 2 wangting wangting 4096 Apr 22 18:11 logs
-rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE
-rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md
-rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES
-rw-rw-r-- 1 wangting wangting 0 Apr 24 15:02 tail_dir.json
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools
drwxrwxr-x 3 wangting wangting 4096 Apr 24 14:11 upload
wangting@ops01:/opt/module/flume >pwd
/opt/module/flume
wangting@ops01:/opt/module/flume >echo wang >> download/file1.txt
wangting@ops01:/opt/module/flume >echo ting >> download/file2.txt
wangting@ops01:/opt/module/flume >ll download/
total 8
-rw-rw-r-- 1 wangting wangting 5 Apr 24 15:02 file1.txt
-rw-rw-r-- 1 wangting wangting 5 Apr 24 15:02 file2.txt
wangting@ops01:/opt/module/flume >ll
total 192
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin
-rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x 2 wangting wangting 4096 Apr 22 18:18 conf
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:59 datas
-rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES
-rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs
drwxrwxr-x 2 wangting wangting 4096 Apr 24 15:02 download
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib
-rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE
drwxrwxr-x 2 wangting wangting 4096 Apr 22 18:11 logs
-rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE
-rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md
-rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES
-rw-rw-r-- 1 wangting wangting 145 Apr 24 15:03 tail_dir.json
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools
drwxrwxr-x 3 wangting wangting 4096 Apr 24 14:11 upload
wangting@ops01:/opt/module/flume >cat tail_dir.json
[{"inode":4203350,"pos":5,"file":"/opt/module/flume/download/file1.txt"},{"inode":4203351,"pos":5,"file":"/opt/module/flume/download/file2.txt"}]
wangting@ops01:/opt/module/flume >echo wang222 >> download/file1.txt
wangting@ops01:/opt/module/flume >echo ting222 >> download/file2.txt
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >cat tail_dir.json
[{"inode":4203350,"pos":13,"file":"/opt/module/flume/download/file1.txt"},{"inode":4203351,"pos":13,"file":"/opt/module/flume/download/file2.txt"}]
wangting@ops01:/opt/module/flume >
# Notice the change in the value of pos, which is equivalent to the pointer of the recording position
# View log information
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >tail -f /opt/module/flume/logs/flume.log
24 Apr 2021 15:03:00,395 INFO [Thread-9] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
24 Apr 2021 15:03:57,359 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called.
24 Apr 2021 15:03:57,360 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033.tmp
24 Apr 2021 15:03:57,381 INFO [hdfs-k3-call-runner-5] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033.tmp to hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033
24 Apr 2021 15:04:26,502 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSDataStream.configure:57) - Serializer = TEXT, UseRawLocalFileSystem = false
24 Apr 2021 15:04:26,515 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.BucketWriter.open:246) - Creating hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp
24 Apr 2021 15:04:29,545 INFO [Thread-15] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
24 Apr 2021 15:05:26,536 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called.
24 Apr 2021 15:05:26,536 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp
24 Apr 2021 15:05:26,550 INFO [hdfs-k3-call-runner-2] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp to hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503
# View hdfs information
wangting@ops01:/opt/module/flume >hdfs dfs -ls /flume/download/20210424/15/
2021-04-24 15:07:19,138 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 2 items
-rw-r--r-- 3 wangting supergroup 10 2021-04-24 15:03 /flume/download/20210424/15/upload-.1619247776033
-rw-r--r-- 3 wangting supergroup 16 2021-04-24 15:05 /flume/download/20210424/15/upload-.1619247866503
wangting@ops01:/opt/module/flume >hdfs dfs -cat /flume/download/20210424/15/upload-.1619247776033
2021-04-24 15:07:37,749 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-24 15:07:38,472 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wang
ting
wangting@ops01:/opt/module/flume >hdfs dfs -cat /flume/download/20210424/15/upload-.1619247866503
2021-04-24 15:07:51,807 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-24 15:07:52,533 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wang222
ting222
[Note 1]
Taildir Source maintains a The position file in json format will regularly update the latest position read by each file in the position file, so the continuous transmission of breakpoints can be realized. The format of position file is as follows:
[{"inode":4203350,"pos":13,"file":"/opt/module/flume/download/file1.txt"},
{"inode":4203351,"pos":13,"file":"/opt/module/flume/download/file2.txt"}]
[Note 2]
The area where file metadata is stored in Linux is called inode. Each inode has a number. The operating system uses the inode number to identify different files. The Unix/Linux system does not use the file name, but uses the inode number to identify files. In this way, inode + pos can locate the pointer position and associate the file name of file
Flume advanced
Flume transaction
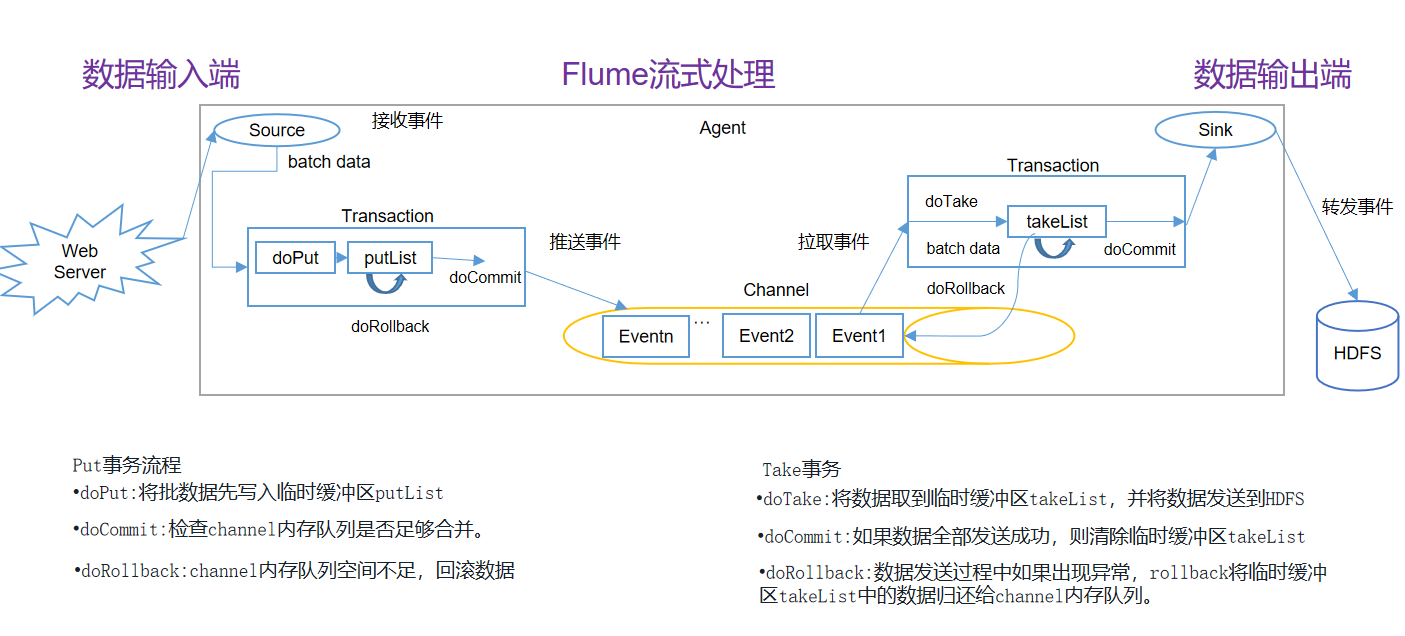
Put transaction flow
doPut: write the batch data to the temporary buffer putList first
doCommit: check whether the channel memory queue is sufficient for merging.
Dorollback: insufficient memory queue space in channel, rollback data
Take transaction
doTake: fetch the data to the makelist buffer and send the data to HDFS
doCommit: if all data is sent successfully, the temporary buffer takeList will be cleared
doRollback: if an exception occurs during data sending, rollback returns the data in the takeList of the temporary buffer to the channel memory queue.
Flume Agent internal principle

Important components:
ChannelSelector
The function of ChannelSelector is to select which Channel the Event will be sent to. There are two types: Replicating and Multiplexing.
ReplicatingSelector will send the same Event to all channels, and Multiplexing will send different events to different channels according to corresponding principles.
SinkProcessor
There are three types of SinkProcessor: DefaultSinkProcessor, loadbalancing SinkProcessor and FailoverSinkProcessor
DefaultSinkProcessor corresponds to a single Sink. Loadbalancing sinkprocessor and FailoverSinkProcessor correspond to Sink Group. Loadbalancing sinkprocessor can realize the function of load balancing, and FailoverSinkProcessor can recover from errors.
Flume topology
Simple series
This mode connects multiple flumes in sequence, from the initial source to the destination storage system of the final sink transfer. This mode does not recommend bridging too many flumes. Too many flumes will not only affect the transmission rate, but also affect the whole transmission system once a node flume goes down in the transmission process.
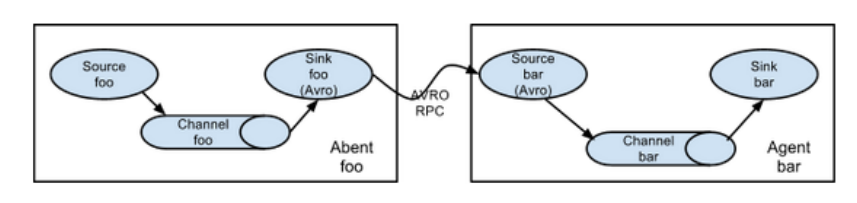
Replication and multiplexing
Flume supports the flow of events to one or more destinations. This mode can copy the same data to multiple channels, or distribute different data to different channels. sink can choose to transfer to different destinations.
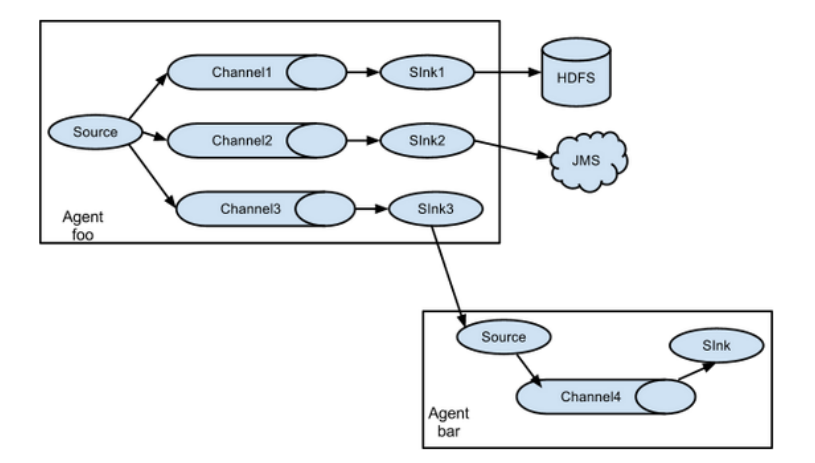
Load balancing and failover
Flume supports the use of to logically divide multiple sinks into a sink group. The sink group can cooperate with different sinkprocessors to realize the functions of load balancing and error recovery.
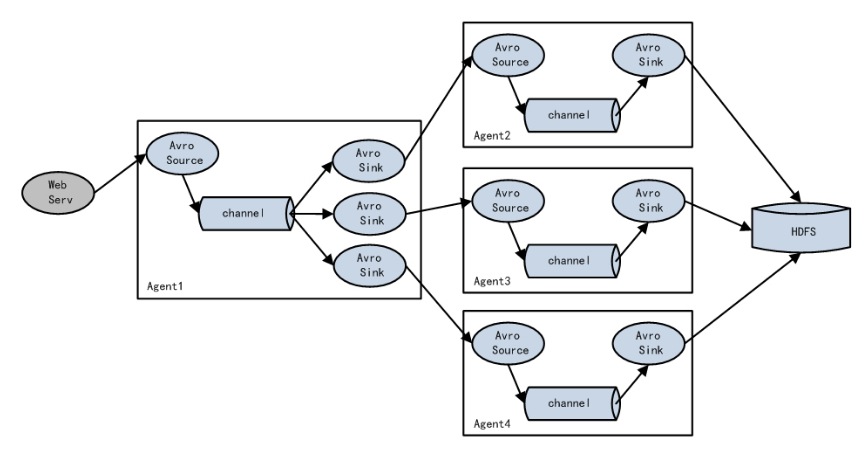
polymerization
This model is the most common and very practical. Daily web applications are usually distributed in hundreds of servers, or even thousands or tens of thousands of servers. The logs generated are also very troublesome to process. This combination of flume can well solve this problem. Each server deploys a flume to collect logs, which is transmitted to a flume that collects logs, and then the flume is uploaded to hdfs, hive, hbase, etc. for log analysis.
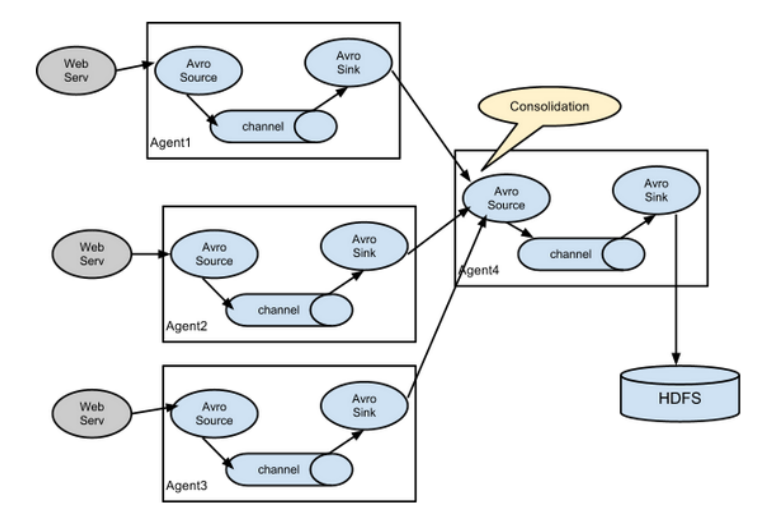
Flume use case 5
Scenario: replication and multiplexing cases
Background needs
Flume-1 is used to monitor file changes. Flume-1 passes the changes to Flume-2, which is responsible for storing them to HDFS. At the same time, flume-1 transmits the changed content to Flume-3, which is responsible for outputting to the local file system, which is equivalent to the cooperation of three agent s.
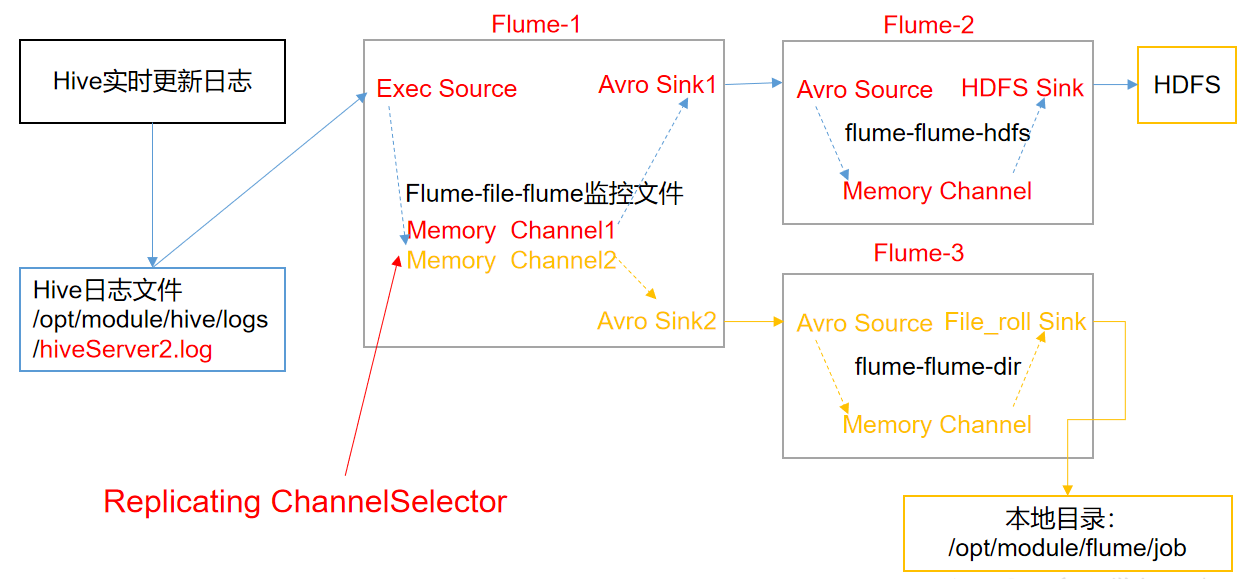
Preparation, writing configuration
Write configuration / opt / module / flume / data / 05-flume-file-flume conf
[note] path log / opt / module / hive / logs / hiveserver2 Log is configured according to the actual situation
wangting@ops01:/opt/module/flume/datas >vim 05-flume-file-flume.conf # Name the components on this agent bigdata01.sources = r1 bigdata01.sinks = k1 k2 bigdata01.channels = c1 c2 # Copy data flow to all channel s bigdata01.sources.r1.selector.type = replicating # Describe/configure the source bigdata01.sources.r1.type = exec bigdata01.sources.r1.command = tail -F /opt/module/hive/logs/hiveServer2.log bigdata01.sources.r1.shell = /bin/bash -c # Describe the sink # avro on sink side is a data sender bigdata01.sinks.k1.type = avro bigdata01.sinks.k1.hostname = ops01 bigdata01.sinks.k1.port = 44441 bigdata01.sinks.k2.type = avro bigdata01.sinks.k2.hostname = ops01 bigdata01.sinks.k2.port = 44442 # Describe the channel bigdata01.channels.c1.type = memory bigdata01.channels.c1.capacity = 1000 bigdata01.channels.c1.transactionCapacity = 100 bigdata01.channels.c2.type = memory bigdata01.channels.c2.capacity = 1000 bigdata01.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel bigdata01.sources.r1.channels = c1 c2 bigdata01.sinks.k1.channel = c1 bigdata01.sinks.k2.channel = c2
Write configuration / opt / module / flume / data / 05 flume flume HDFS conf
[note] bigdata02 sources. r1. Port = 44441 and bigdata01 above are required sinks. k1. Port = 441 port consistent
# Name the components on this agent bigdata02.sources = r1 bigdata02.sinks = k1 bigdata02.channels = c1 # Describe/configure the source # avro on the source side is a data receiving service bigdata02.sources.r1.type = avro bigdata02.sources.r1.bind = ops01 bigdata02.sources.r1.port = 44441 # Describe the sink bigdata02.sinks.k1.type = hdfs bigdata02.sinks.k1.hdfs.path = hdfs://ops01:8020/flume/%Y%m%d/%H #Prefix of uploaded file bigdata02.sinks.k1.hdfs.filePrefix = flume- #Scroll folders by time bigdata02.sinks.k1.hdfs.round = true #How many time units to create a new folder bigdata02.sinks.k1.hdfs.roundValue = 1 #Redefine time units bigdata02.sinks.k1.hdfs.roundUnit = hour #Use local timestamp bigdata02.sinks.k1.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush ing to HDFS bigdata02.sinks.k1.hdfs.batchSize = 100 #Set the file type to support compression bigdata02.sinks.k1.hdfs.fileType = DataStream #How often do I generate a new file bigdata02.sinks.k1.hdfs.rollInterval = 600 #Set the scroll size of each file to about 128M bigdata02.sinks.k1.hdfs.rollSize = 134217700 #The scrolling of files is independent of the number of events bigdata02.sinks.k1.hdfs.rollCount = 0 # Describe the channel bigdata02.channels.c1.type = memory bigdata02.channels.c1.capacity = 1000 bigdata02.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata02.sources.r1.channels = c1 bigdata02.sinks.k1.channel = c1
Write configuration / opt / module / flume / data / 05 flume flume dir conf
[note] bigdata03 sources. r1. Port = 442 and bigdata01 above are required sinks. k2. Port = 442 port consistent
[note] / opt/module/flume/job directory needs to be created by mkdir in advance. The agent task will not automatically create the directory in the corresponding configuration
# Name the components on this agent bigdata03.sources = r1 bigdata03.sinks = k1 bigdata03.channels = c2 # Describe/configure the source bigdata03.sources.r1.type = avro bigdata03.sources.r1.bind = ops01 bigdata03.sources.r1.port = 44442 # Describe the sink bigdata03.sinks.k1.type = file_roll bigdata03.sinks.k1.sink.directory = /opt/module/flume/job # Describe the channel bigdata03.channels.c2.type = memory bigdata03.channels.c2.capacity = 1000 bigdata03.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel bigdata03.sources.r1.channels = c2 bigdata03.sinks.k1.channel = c2
Start agent
[note] you need to start multiple agents, open multiple session windows, and keep multiple agents running continuously
agent-1
flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/05-flume-flume-dir.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/05-flume-flume-dir.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata03 --conf-file datas/05-flume-flume-dir.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
agent-2
flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
agent-3
flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/05-flume-file-flume.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/05-flume-file-flume.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata01 --conf-file datas/05-flume-file-flume.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
# View created configurations wangting@ops01:/opt/module/flume/datas >ll total 28 -rw-rw-r-- 1 wangting wangting 1057 Apr 24 17:01 05-flume-file-flume.conf -rw-rw-r-- 1 wangting wangting 609 Apr 24 17:03 05-flume-flume-dir.conf -rw-rw-r-- 1 wangting wangting 1437 Apr 24 17:02 05-flume-flume-hdfs.conf -rw-rw-r-- 1 wangting wangting 1533 Apr 24 14:05 flume-dir-hdfs.conf -rw-rw-r-- 1 wangting wangting 1405 Apr 23 11:13 flume-file-hdfs.conf -rw-rw-r-- 1 wangting wangting 1526 Apr 24 14:59 flume-taildir-hdfs.conf -rw-rw-r-- 1 wangting wangting 787 Apr 17 15:58 netcatsource_loggersink.conf # Check whether the / opt/module/flume/job directory is created wangting@ops01:/opt/module/flume/datas >ll /opt/module/flume/job total 0
Scene experiment
Open Hive for operation and generate operation log
# Enter Hive command line wangting@ops01:/opt/module/hive/conf >beeline -u jdbc:hive2://ops01:10000 -n wangting Connecting to jdbc:hive2://ops01:10000 Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 3.1.2 by Apache Hive # Query a table at will 0: jdbc:hive2://ops01:10000> select * from emp; INFO : Compiling command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02): select * from emp INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null) INFO : Completed compiling command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02); Time taken: 0.134 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02): select * from emp INFO : Completed executing command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02); Time taken: 0.0 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +------------+------------+------------+----------+---------------+----------+-----------+-------------+ | emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno | +------------+------------+------------+----------+---------------+----------+-----------+-------------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 | +------------+------------+------------+----------+---------------+----------+-----------+-------------+ 14 rows selected (0.247 seconds) # Call MapReduce query 0: jdbc:hive2://ops01:10000> select count(*) from emp; INFO : Compiling command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6): select count(*) from emp INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null) INFO : Completed compiling command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6); Time taken: 0.117 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6): select count(*) from emp WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. INFO : Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6 INFO : Total jobs = 1 INFO : Launching Job 1 out of 1 INFO : Starting task [Stage-1:MAPRED] in serial mode INFO : Number of reduce tasks determined at compile time: 1 INFO : In order to change the average load for a reducer (in bytes): INFO : set hive.exec.reducers.bytes.per.reducer=<number> INFO : In order to limit the maximum number of reducers: INFO : set hive.exec.reducers.max=<number> INFO : In order to set a constant number of reducers: INFO : set mapreduce.job.reduces=<number> INFO : number of splits:1 INFO : Submitting tokens for job: job_1615531413182_0102 INFO : Executing with tokens: [] INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_0102/ INFO : Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/ INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0% INFO : 2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec INFO : 2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec INFO : MapReduce Total cumulative CPU time: 5 seconds 260 msec INFO : Ended Job = job_1615531413182_0102 INFO : MapReduce Jobs Launched: INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS INFO : Total MapReduce CPU Time Spent: 5 seconds 260 msec INFO : Completed executing command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6); Time taken: 23.796 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +------+ | _c0 | +------+ | 14 | +------+ 1 row selected (23.933 seconds) # Query nonexistent tables and create exceptions 0: jdbc:hive2://ops01:10000> select count(*) from emppppppppppppppp; Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' (state=42S02,code=10001) 0: jdbc:hive2://ops01:10000> select count(*) from emppppppppppppppp; Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' (state=42S02,code=10001)
Verify the flume dir mode. You can see that relevant files will be generated synchronously in the / opt/module/flume/job directory
wangting@ops01:/opt/module/flume/job >ll total 16 -rw-rw-r-- 1 wangting wangting 0 Apr 24 17:05 1619255120463-1 -rw-rw-r-- 1 wangting wangting 575 Apr 24 17:05 1619255120463-2 -rw-rw-r-- 1 wangting wangting 3 Apr 24 17:06 1619255120463-3 -rw-rw-r-- 1 wangting wangting 863 Apr 24 17:07 1619255120463-4 -rw-rw-r-- 1 wangting wangting 445 Apr 24 17:07 1619255120463-5 wangting@ops01:/opt/module/flume/job >cat 1619255120463-2 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2021-04-24 16:18:20,663 Stage-1 map = 0%, reduce = 0% 2021-04-24 16:18:25,827 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec 2021-04-24 16:18:31,975 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.19 sec MapReduce Total cumulative CPU time: 6 seconds 190 msec Ended Job = job_1615531413182_0101 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS Total MapReduce CPU Time Spent: 6 seconds 190 msec OK wangting@ops01:/opt/module/flume/job >cat 1619255120463-3 OK wangting@ops01:/opt/module/flume/job >cat 1619255120463-4 Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/ Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0% 2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec wangting@ops01:/opt/module/flume/job >cat 1619255120463-5 2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec MapReduce Total cumulative CPU time: 5 seconds 260 msec Ended Job = job_1615531413182_0102 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS Total MapReduce CPU Time Spent: 5 seconds 260 msec OK FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
Verify the hdfs mode. You can see that the hdfs synchronization also generates the corresponding hive log
# View corresponding directory wangting@ops01:/opt/module/flume/job >hdfs dfs -ls /flume/20210424/17 2021-04-24 17:12:46,127 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS Found 1 items -rw-r--r-- 3 wangting supergroup 575 2021-04-24 17:05 /flume/20210424/17/flume-.1619255148002.tmp # View the write contents of the generated file wangting@ops01:/opt/module/flume/job >hdfs dfs -cat /flume/20210424/17/flume-.1619255148002.tmp 2021-04-24 17:13:17,766 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS 2021-04-24 17:13:18,648 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2021-04-24 16:18:20,663 Stage-1 map = 0%, reduce = 0% 2021-04-24 16:18:25,827 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec 2021-04-24 16:18:31,975 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.19 sec MapReduce Total cumulative CPU time: 6 seconds 190 msec Ended Job = job_1615531413182_0101 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS Total MapReduce CPU Time Spent: 6 seconds 190 msec OK OK Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/ Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0% 2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec 2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec MapReduce Total cumulative CPU time: 5 seconds 260 msec Ended Job = job_1615531413182_0102 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS Total MapReduce CPU Time Spent: 5 seconds 260 msec OK FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
Flume use case 6
Scenario: load balancing and failover
Background needs
Flume1 is used to monitor a port. The sink in the sink group is connected to Flume2 and Flume3 respectively. FailoverSinkProcessor is used to realize the function of failover.
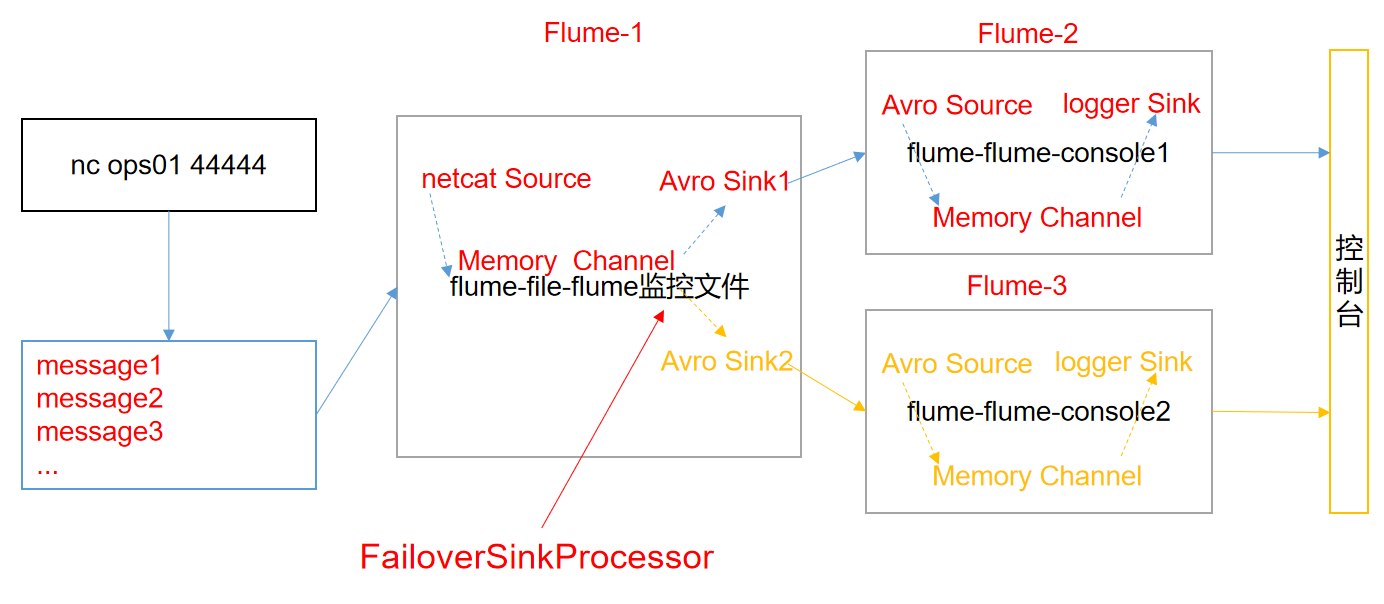
Preparation, writing configuration
Corresponding to 3 profiles
Write configuration / opt / module / flume / data / 06 flume netcat flume conf
[note]:
Source data source input uses netcat to simulate content input, which is intuitive and easy to understand
Sink write out the corresponding two sink, that is, use the source in the two agent s to receive the data later
wangting@ops01:/opt/module/flume/datas >vim 06-flume-netcat-flume.conf # Name the components on this agent bigdata01.sources = r1 bigdata01.channels = c1 bigdata01.sinkgroups = g1 bigdata01.sinks = k1 k2 # Describe/configure the source bigdata01.sources.r1.type = netcat bigdata01.sources.r1.bind = localhost bigdata01.sources.r1.port = 44444 bigdata01.sinkgroups.g1.processor.type = failover bigdata01.sinkgroups.g1.processor.priority.k1 = 5 bigdata01.sinkgroups.g1.processor.priority.k2 = 10 bigdata01.sinkgroups.g1.processor.maxpenalty = 10000 # Describe the sink bigdata01.sinks.k1.type = avro bigdata01.sinks.k1.hostname = ops01 bigdata01.sinks.k1.port = 44441 bigdata01.sinks.k2.type = avro bigdata01.sinks.k2.hostname = ops01 bigdata01.sinks.k2.port = 44442 # Describe the channel bigdata01.channels.c1.type = memory bigdata01.channels.c1.capacity = 1000 bigdata01.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata01.sources.r1.channels = c1 bigdata01.sinkgroups.g1.sinks = k1 k2 bigdata01.sinks.k1.channel = c1 bigdata01.sinks.k2.channel = c1
Write configuration / opt / module / flume / data / 06-flume-flume-console1 conf
wangting@ops01:/opt/module/flume/datas >vim 06-flume-flume-console1.conf # Name the components on this agent bigdata02.sources = r1 bigdata02.sinks = k1 bigdata02.channels = c1 # Describe/configure the source bigdata02.sources.r1.type = avro bigdata02.sources.r1.bind = ops01 bigdata02.sources.r1.port = 44441 # Describe the sink bigdata02.sinks.k1.type = logger # Describe the channel bigdata02.channels.c1.type = memory bigdata02.channels.c1.capacity = 1000 bigdata02.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata02.sources.r1.channels = c1 bigdata02.sinks.k1.channel = c1
Write configuration / opt / module / flume / data / 06-flume-flume-console2 conf
wangting@ops01:/opt/module/flume/datas >vim 06-flume-flume-console2.conf # Name the components on this agent bigdata03.sources = r1 bigdata03.sinks = k1 bigdata03.channels = c2 # Describe/configure the source bigdata03.sources.r1.type = avro bigdata03.sources.r1.bind = ops01 bigdata03.sources.r1.port = 44442 # Describe the sink bigdata03.sinks.k1.type = logger # Describe the channel bigdata03.channels.c2.type = memory bigdata03.channels.c2.capacity = 1000 bigdata03.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel bigdata03.sources.r1.channels = c2 bigdata03.sinks.k1.channel = c2
[note]:
Bigdata01 - > monitor the data sent from port 44444 and netcat;
Bigdata02 - > listen to the data sent from port 441 and bigdata01
Bigdata03 - > listen to the data sent from port 442 and bigdata01
Only one of bigdata02 and bigdata03 can receive data. When the received service is abnormal, the other will receive data; The purpose is to test whether it can automatically and successfully jump to the new port to continue receiving
Start agent
[note]: start multiple session windows and let each agent run continuously.
agent-bigdata03
flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/06-flume-flume-console2.conf -Dflume.root.logger=INFO,console
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/06-flume-flume-console2.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata03 --conf-file datas/06-flume-flume-console2.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-25 09:42:05,310 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-25 09:42:05,315 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/06-flume-flume-console2.conf
2021-04-25 09:42:05,322 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata03
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,325 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata03' has no configfilters.
2021-04-25 09:42:05,345 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata03]
2021-04-25 09:42:05,345 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-25 09:42:05,352 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c2 type memory
2021-04-25 09:42:05,360 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c2
2021-04-25 09:42:05,362 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type avro
2021-04-25 09:42:05,374 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-25 09:42:05,377 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c2 connected to [r1, k1]
2021-04-25 09:42:05,381 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:Avro source r1: { bindAddress: ops01, port: 44442 } }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@502edef6 counterGroup:{ name:null counters:{} } }} channels:{c2=org.apache.flume.channel.MemoryChannel{name: c2}} }
2021-04-25 09:42:05,383 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c2
2021-04-25 09:42:05,441 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c2: Successfully registered new MBean.
2021-04-25 09:42:05,441 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c2 started
2021-04-25 09:42:05,441 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-25 09:42:05,442 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-25 09:42:05,442 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:193)] Starting Avro source r1: { bindAddress: ops01, port: 44442 }...
2021-04-25 09:42:05,776 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2021-04-25 09:42:05,776 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r1 started
2021-04-25 09:42:05,778 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:219)] Avro source r1 started.
2021-04-25 09:43:33,977 (New I/O server boss #17) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] OPEN
2021-04-25 09:43:33,978 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] BOUND: /11.8.37.50:44442
2021-04-25 09:43:33,978 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] CONNECTED: /11.8.37.50:50586
agent-bigdata02
flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/06-flume-flume-console1.conf -Dflume.root.logger=INFO,console
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/06-flume-flume-console1.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata02 --conf-file datas/06-flume-flume-console1.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-25 09:42:28,068 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-25 09:42:28,074 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/06-flume-flume-console1.conf
2021-04-25 09:42:28,081 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata02
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,083 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata02' has no configfilters.
2021-04-25 09:42:28,104 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata02]
2021-04-25 09:42:28,105 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-25 09:42:28,113 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory
2021-04-25 09:42:28,121 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c1
2021-04-25 09:42:28,123 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type avro
2021-04-25 09:42:28,135 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-25 09:42:28,138 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c1 connected to [r1, k1]
2021-04-25 09:42:28,142 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:Avro source r1: { bindAddress: ops01, port: 44441 } }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@550c3c8e counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
2021-04-25 09:42:28,143 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c1
2021-04-25 09:42:28,201 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
2021-04-25 09:42:28,202 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started
2021-04-25 09:42:28,202 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-25 09:42:28,202 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-25 09:42:28,203 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:193)] Starting Avro source r1: { bindAddress: ops01, port: 44441 }...
2021-04-25 09:42:28,544 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2021-04-25 09:42:28,544 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r1 started
2021-04-25 09:42:28,546 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:219)] Avro source r1 started.
2021-04-25 09:43:33,777 (New I/O server boss #17) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] OPEN
2021-04-25 09:43:33,778 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] BOUND: /11.8.37.50:44441
2021-04-25 09:43:33,778 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] CONNECTED: /11.8.37.50:45068
agent-bigdata01
flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access Info: Including Hive libraries found via (/opt/module/hive) for Hive access + exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Scene experiment
# Check that port 444 is running and the agent of bigdata01 is normal wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44444 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 127.0.0.1:44444 :::* LISTEN 6498/java wangting@ops01:/opt/module/flume > wangting@ops01:/opt/module/flume >nc localhost 44444 wang OK # After you see ok, you can check which bigdata agent has received the data on the console, and you can see that 03 has received the Event Only one rev OK # Continue to send the message, but 03 still receives the Event now is 44442 OK # bigdata03 agent runs normally and receives continuously 44442 bigdata03 OK # After sending this 44442 bigdata03, stop the agent of 03 new info OK # Check whether new info is successfully received by bigdata02 now is 44441 OK # Successful verification, successful transfer 44441 bigdata02 OK
bigdata03 (port 44442) console:
2021-04-25 09:45:23,459 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 wang }
2021-04-25 09:47:54,107 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 4F 6E 6C 79 20 6F 6E 65 20 72 65 76 Only one rev }
2021-04-25 09:48:40,111 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6E 6F 77 20 69 73 20 34 34 34 34 32 now is 44442 }
2021-04-25 09:49:57,121 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 34 34 34 34 32 20 62 69 67 64 61 74 61 30 33 44442 bigdata03 }
stopping # Stop 03
wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44442
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44441
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 11.8.37.50:44441 :::* LISTEN 5988/java
wangting@ops01:/opt/module/flume >
# Now only port 441 is available
44atport (gda02) console:
2021-04-25 09:51:30,235 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6E 65 77 20 69 6E 66 6F new info }
2021-04-25 09:51:46,004 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6E 6F 77 20 69 73 20 34 34 34 34 31 now is 44441 }
2021-04-25 09:52:24,006 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 34 34 34 34 31 20 62 69 67 64 61 74 61 30 32 44441 bigdata02 }
Finally, when 03 is abnormal, 02 can normally receive data
Flume use case 7
Scenes: aggregation
Background needs
- Flume-1 monitoring file on ops01 / opt / module / group Log file content changes.
- Flume-2 on ops02 monitors the data flow of a 44444 port.
- Flume-1 and Flume-2 send data to Flume-3 on ops03, and Flume-3 prints the final data to the console.
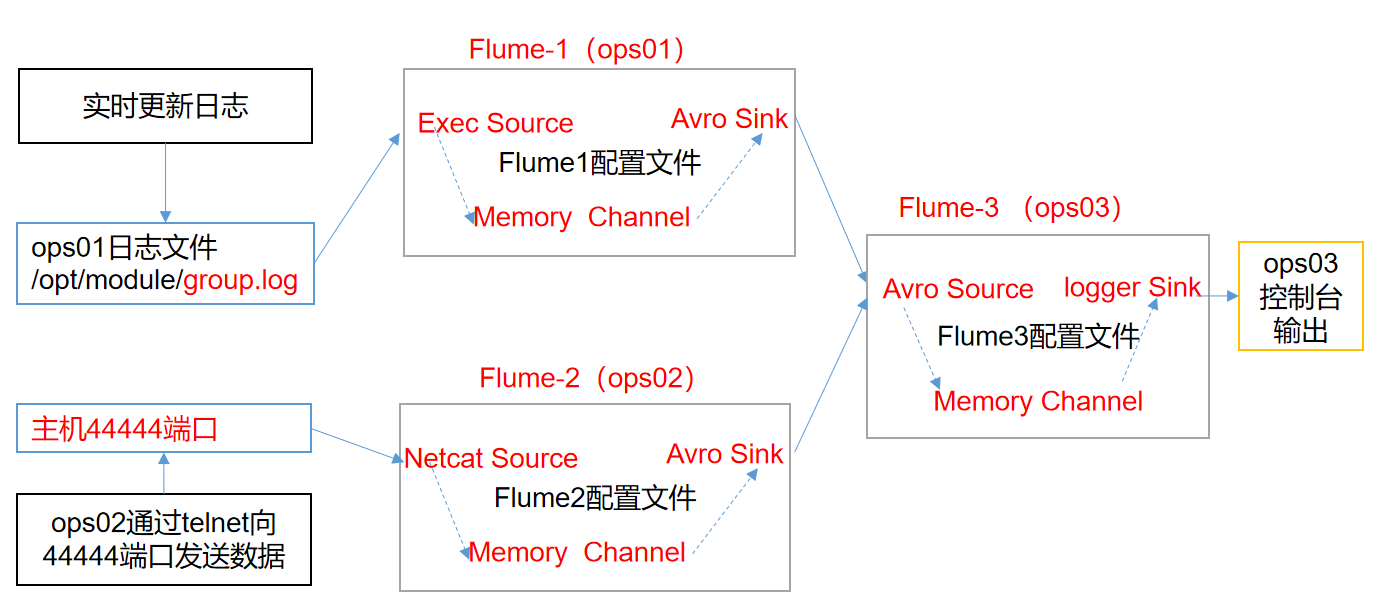
[Note 1]:
Three machines are required; Flume has been deployed. For example, ops01 / ops02 / ops03 refers to the deployment of flume on three servers respectively
[Note 2]:
After deploying flume, you need to configure hosts resolution in / etc/hosts
For example: tail -5 /etc/hosts
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
[Note 3]:
Now the configuration file is different from the previous case. The configuration needs to be written on the corresponding path of the corresponding server on which machine to start the agent
Preparation, writing configuration
ops01 /opt/module/flume/datas/
vim 07-flume1-logger-flume.conf
# Name the components on this agent bigdata01.sources = r1 bigdata01.sinks = k1 bigdata01.channels = c1 # Describe/configure the source bigdata01.sources.r1.type = exec bigdata01.sources.r1.command = tail -F /opt/module/group.log bigdata01.sources.r1.shell = /bin/bash -c # Describe the sink bigdata01.sinks.k1.type = avro bigdata01.sinks.k1.hostname = ops03 bigdata01.sinks.k1.port = 44441 # Describe the channel bigdata01.channels.c1.type = memory bigdata01.channels.c1.capacity = 1000 bigdata01.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata01.sources.r1.channels = c1 bigdata01.sinks.k1.channel = c1
ops02 /opt/module/flume/datas/
vim 07-flume2-netcat-flume.conf
# Name the components on this agent bigdata02.sources = r1 bigdata02.sinks = k1 bigdata02.channels = c1 # Describe/configure the source bigdata02.sources.r1.type = netcat bigdata02.sources.r1.bind = ops02 bigdata02.sources.r1.port = 44444 # Describe the sink bigdata02.sinks.k1.type = avro bigdata02.sinks.k1.hostname = ops03 bigdata02.sinks.k1.port = 44441 # Use a channel which buffers events in memory bigdata02.channels.c1.type = memory bigdata02.channels.c1.capacity = 1000 bigdata02.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata02.sources.r1.channels = c1 bigdata02.sinks.k1.channel = c1
ops03 /opt/module/flume/datas/
vim 07-flume3-flume-logger.conf
# Name the components on this agent bigdata03.sources = r1 bigdata03.sinks = k1 bigdata03.channels = c1 # Describe/configure the source bigdata03.sources.r1.type = avro bigdata03.sources.r1.bind = ops03 bigdata03.sources.r1.port = 44441 # Describe the sink # Describe the sink bigdata03.sinks.k1.type = logger # Describe the channel bigdata03.channels.c1.type = memory bigdata03.channels.c1.capacity = 1000 bigdata03.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel bigdata03.sources.r1.channels = c1 bigdata03.sinks.k1.channel = c1
Start agent
Generally, the starting sequence is from last to first, and the receiving party starts first; There are many examples. Here we only paste the command and omit the info output
# ops03 server, bigdata03, need to see the final display effect, add - dflume root. logger=INFO,console wangting@ops03:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/07-flume3-flume-logger.conf -Dflume.root.logger=INFO,console # ops01 server, bigdata01, corresponding to the change of file content under the test path wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/07-flume1-logger-flume.conf # ops02 server, bigdata02, corresponding to testing the flow data change of a port wangting@ops02:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/07-flume2-netcat-flume.conf
Scene experiment
# ops01, open another session window
wangting@ops01:/opt/module >cd /opt/module
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
# View ops03 agent console output accordingly
2021-04-25 11:33:28,745 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,747 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 wangt }
# ops02, open another session window
wangting@ops02:/opt/module >netstat -tnlpu|grep 44444
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 11.8.36.63:44444 :::* LISTEN 62200/java
wangting@ops02:/opt/module >telnet ops02 44444
Trying 11.8.36.63...
Connected to ops02.
Escape character is '^]'.
wangt
OK
ops02
OK
66666
OK
telnet test
OK
# View ops03 agent console output accordingly
2021-04-25 11:34:19,491 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 61 6E 67 74 0D wangt. }
2021-04-25 11:34:26,318 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6F 70 73 30 32 0D ops02. }
2021-04-25 11:34:35,320 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 36 36 36 36 36 0D 66666. }
2021-04-25 11:34:46,523 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 65 6C 6E 65 74 20 74 65 73 74 0D telnet test. }
Finally, the data is successfully aggregated to 07-flume3-flume-logger On bigdata03 defined by conf.