1 Fork/Join framework
1.1 what is Fork/Join framework
Fork/Join framework is a framework for parallel task execution provided by Java 7. It is a framework that divides a large task into several small tasks, and finally summarizes the results of each small task to obtain the results of the large task.
Let's understand the Fork/Join framework through the words fork and join. Fork is to divide a large task into several sub tasks for parallel execution. Join is to merge the execution results of these sub tasks and finally get the results of this large task. For example, calculate 1 + 2 + 10000, which can be divided into 10 subtasks. Each subtask sums the number of 1000 respectively, and finally summarizes the results of these 10 subtasks.
1.2 work stealing algorithm
Work stealing algorithm refers to a thread stealing tasks from other queues to execute. The operation flow chart of work stealing is as follows:
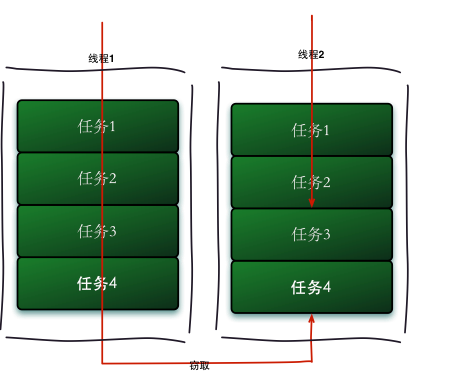
So why use A job theft algorithm? If we need to do A relatively large task, we can divide the task into several independent subtasks. In order to reduce the competition between threads, we put these subtasks into different queues, and create A separate thread for each queue to execute the tasks in the queue. Threads and queues correspond one by one, For example, thread A is responsible for processing tasks in queue A. However, some threads will finish the tasks in their queue first, while there are tasks waiting to be processed in the queue corresponding to other threads. The thread that has finished its work is better to help other threads than wait, so it steals A task from the queue of other threads to execute. At this time, they will access the same queue. Therefore, in order to reduce the competition between the stolen task thread and the stolen task thread, the dual ended queue is usually used. The stolen task thread always takes the task from the head of the dual ended queue for execution, and the stolen task thread always takes the task from the tail of the dual ended queue for execution.
The advantage of work stealing algorithm is to make full use of threads for parallel computing and reduce the competition between threads. Its disadvantage is that there is still competition in some cases, such as when there is only one task in the double ended queue. It also consumes more system resources, such as creating multiple threads and multiple double ended queues.
1.3 introduction to fork / join framework
We already know the requirements of the Fork/Join framework, so we can think about how to design a Fork/Join framework? This thinking is helpful to understand the design of Fork/Join framework.
- The first step is to divide the task. First, we need a fork class to divide a large task into sub tasks. It is possible that the sub tasks are still large, so we need to keep dividing until the sub tasks are small enough.
- Step 2 execute the task and merge the results. The divided subtasks are placed in the dual end queue respectively, and then several startup threads obtain task execution from the dual end queue respectively. The results of the execution of subtasks are uniformly placed in a queue. Start a thread to get data from the queue, and then merge these data.
Fork/Join uses two classes to accomplish the above two things:
- ForkJoin task: to use the ForkJoin framework, we must first create a ForkJoin task. It provides a mechanism to perform fork() and join() operations in tasks. Generally, we do not need to directly inherit the ForkJoinTask class, but only its subclasses. The Fork/Join framework provides the following two subclasses:
RecursiveAction: used for tasks that do not return results.
Recursive task: used for tasks that have returned results. - ForkJoinPool: ForkJoinTask needs to be executed through ForkJoinPool. The subtasks separated from the task will be added to the double ended queue maintained by the current working thread and enter the head of the queue. When there is no task in the queue of a worker thread, it will randomly obtain a task from the end of the queue of other worker threads.
1.4 using Fork/Join framework
Let's use the Fork / Join framework through a simple requirement: calculate the result of 1 + 2 + 3 + 4.
The first thing to consider when using the fork / join framework is how to divide tasks. If we want each subtask to add up to two numbers, we set the threshold of division to 2. Because it is the addition of four numbers, the fork / join framework will fork this task into two subtasks. Subtask 1 is responsible for calculating 1 + 2 and subtask 2 is responsible for calculating 3 + 4, Then join the results of the two subtasks.
Because it is a task with results, it must inherit the RecursiveTask. The implementation code is as follows:
importjava.util.concurrent.ExecutionException;
importjava.util.concurrent.ForkJoinPool;
importjava.util.concurrent.Future;
importjava.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask {
private static final int THRESHOLD= 2;//threshold
private int start;
private int end;
public CountTask(int start,int end) {
this.start= start;
this.end= end;
}
@Override
protected Integer compute() {
int sum = 0;
//If the task is small enough, calculate the task
boolean canCompute = (end-start) <=THRESHOLD;
if(canCompute) {
for(int i =start; i <=end; i++) {
sum += i;
}
}else{
//If the task is greater than the threshold, it is split into two subtasks for calculation
int middle = (start+end) / 2;
CountTask leftTask =new CountTask(start, middle);
CountTask rightTask =new CountTask(middle + 1,end);
leftTask.fork();
rightTask.fork();
//Wait for the execution of the subtask and get its results
int leftResult=(int)leftTask.join();
int rightResult=(int)rightTask.join();
//Merge subtasks
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool =new ForkJoinPool();
//Generate a calculation task to calculate 1 + 2 + 3 + 4
CountTask task =new CountTask(1, 4);
//Perform a task
Future result = forkJoinPool.submit(task);
try{
System.out.println(result.get());
}catch(InterruptedException e) {
}catch(ExecutionException e) {
}
}
}
Let's learn more about ForkJoinTask through this example. The main difference between ForkJoinTask and general tasks is that it needs to implement the compute method. In this method, we first need to judge whether the task is small enough. If it is small enough, we can directly execute the task. If it is not small enough, it must be divided into two subtasks. When each subtask calls the fork method, it will enter the compute method to see whether the current subtask needs to continue to be divided into sub tasks. If it does not need to continue to be divided, it will execute the current subtask and return the results. Using the join method will wait for the subtask to complete and get its results.
1.5 exception handling of fork / join framework
ForkJoinTask may throw exceptions during execution, but we can't catch exceptions directly in the main thread, so ForkJoinTask provides isCompletedAbnormally() method to check whether the task has thrown exceptions or been cancelled, and you can get exceptions through the getException method of ForkJoinTask. Use the following code:
if(task.isCompletedAbnormally()){
System.out.println(task.getException());
}
The getException method returns a Throwable object. If the task is cancelled, it returns a cancelationexception. If the task is not completed or no exception is thrown, null is returned.
1.6 implementation principle of fork / join framework
ForkJoinPool consists of ForkJoinTask array and ForkJoinWorkerThread array. ForkJoinTask array is responsible for storing the tasks submitted by the program to ForkJoinPool, and ForkJoinWorkerThread array is responsible for executing these tasks.
Implementation principle of fork method of ForkJoinTask. When we call the fork method of ForkJoinTask, the program will call the pushTask method of ForkJoinWorkerThread to execute the task asynchronously, and then return the result immediately. The code is as follows:
public final ForkJoinTask fork() {
((ForkJoinWorkerThread) Thread.currentThread())
.pushTask(this);
return this;
}
The pushTask method stores the current task in the ForkJoinTask array queue. Then call the signalWork() method of ForkJoinPool to wake up or create a worker thread to execute the task. The code is as follows:
final void pushTask(ForkJoinTask t) {
ForkJoinTask[] q; int s, m;
if ((q = queue) != null) { // ignore if queue removed
long u = (((s = queueTop) & (m = q.length - 1)) << ASHIFT) + ABASE;
UNSAFE.putOrderedObject(q, u, t);
queueTop = s + 1; // or use putOrderedInt
if ((s -= queueBase) <= 2)
pool.signalWork();
else if (s == m)
growQueue();
}
}
Implementation principle of the join method of ForkJoinTask. The main function of the join method is to block the current thread and wait for the result. Let's take a look at the implementation of the join method of ForkJoinTask. The code is as follows:
public final V join() {
if (doJoin() != NORMAL)
return reportResult();
else
return getRawResult();
}
private V reportResult() {
int s; Throwable ex;
if ((s = status) == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL && (ex = getThrowableException()) != null)
UNSAFE.throwException(ex);
return getRawResult();
}
First of all, it calls the doJoin() method to get the status of the current task through the doJoin() method to judge what result to return. There are four task states: NORMAL, CANCELLED, SIGNAL and exception.
If the task status is completed, the task result will be returned directly.
If the task status is cancelled, cancelationexception will be thrown directly.
If the task status is to throw an exception, the corresponding exception will be thrown directly.
Let's analyze the implementation code of doJoin() method again:
private int doJoin() {
Thread t; ForkJoinWorkerThread w; int s; boolean completed;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
if ((s = status) < 0)
return s;
if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}
else
return externalAwaitDone();
}
In the doJoin() method, first check the status of the task to see whether the task has been executed. If it has been executed, it will directly return to the task status. If it has not been executed, it will take out the task from the task array and execute it. If the task is successfully executed and completed, set the task status to NORMAL. If an exception occurs, record the exception and set the task status to EXCEPTIONAL
2 barrier
2.1 CyclicBarrier
2.1.1 CyclicBarrier concept
In Java 5, an obstacle class is added. In order to meet a new design requirement, such as a large task, it is often necessary to allocate multiple subtasks for execution. The main task can be executed only when all subtasks are completed. At this time, the obstacle CyclicBarrier can be selected in addition to the Fork/Join framework above.
CyclicBarrier: from the literal meaning, the Chinese meaning of this class is circular fence. It roughly means a recyclable barrier.
Its function is to make all threads wait for completion before proceeding to the next step.
For example, in life, we will invite friends to a restaurant for dinner. Some friends may arrive early and some friends may arrive late, but the restaurant stipulates that we will not be allowed in until everyone arrives. The friends here are all threads, and the restaurant is CyclicBarrier
2.1. 2 method
2.1. 2.1 construction method
public CyclicBarrier(int parties) public CyclicBarrier(int parties, Runnable barrierAction)
parties is the number of participating threads
The second constructor has a Runnable parameter, which means the task to be done by the last arriving thread
2.1.2.2 await method
public int await() throws InterruptedException, BrokenBarrierException public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException
The thread calls await() to indicate that it has reached the fence
BrokenBarrierException indicates that the fence has been damaged. The reason for the damage may be that one of the threads was interrupted or timed out while await()
2.1. 3 using CyclicBarrier
Obstacle is a means of multithreading concurrency control. Its usage is very simple. Here is an example:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* Java Threads: new features - obstacles
*/
public class Test {
public static void main(String[] args) {
//Create an obstacle, and set the MainTask as the task to be executed when a specified number of threads reach the obstacle point (Runnable)
CyclicBarrier cb = new CyclicBarrier(7, new MainTask());
new SubTask("A", cb).start();
new SubTask("B", cb).start();
new SubTask("C", cb).start();
new SubTask("D", cb).start();
new SubTask("E", cb).start();
new SubTask("F", cb).start();
new SubTask("G", cb).start();
}
}
/**
* Main task
*/
class MainTask implements Runnable {
public void run() {
System.out.println(">>>>The main task is executed!<<<<");
}
}
/**
* Subtask
*/
class SubTask extends Thread {
private String name;
private CyclicBarrier cb;
SubTask(String name, CyclicBarrier cb) {
this.name = name;
this.cb = cb;
}
public void run() {
System.out.println("[Subtask" + name + "]Here we go!");
for (int i = 0; i < 999999; i++) ; //Simulate time-consuming tasks
System.out.println("[Subtask" + name + "]Start execution is complete and notify the obstacle that it has been completed!");
try {
//Notify that the blocker is complete
cb.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
Operation results:
[Subtask E]Here we go!
[Subtask E]Start execution is complete and notify the obstacle that it has been completed!
[Subtask F]Here we go!
[Subtask G]Here we go!
[Subtask F]Start execution is complete and notify the obstacle that it has been completed!
[Subtask G]Start execution is complete and notify the obstacle that it has been completed!
[Subtask C]Here we go!
[Subtask B]Here we go!
[Subtask C]Start execution is complete and notify the obstacle that it has been completed!
[Subtask D]Here we go!
[Subtask A]Here we go!
[Subtask D]Start execution is complete and notify the obstacle that it has been completed!
[Subtask B]Start execution is complete and notify the obstacle that it has been completed!
[Subtask A]Start execution is complete and notify the obstacle that it has been completed!
>>>>The main task is executed!<<<<
It can be seen from the execution results that when all sub tasks are completed, the main task is executed and the control goal is achieved.
2.1. 4. Difference between cyclicbarrier and CountDownLatch
CountDownLatch is disposable and CyclicBarrier is recyclable
The responsibilities of the threads involved in CountDownLatch are different. Some are counting down and some are waiting for the end of the countdown. The thread responsibilities of CyclicBarrier are the same
2.2 CountDownLatch
2.2. 1 what is countdownlatch
CountDownLatch is in java1 5. The concurrency tool classes introduced with it include CyclicBarrier, Semaphore, ConcurrentHashMap and BlockingQueue, all of which exist in Java util. Under concurrent package. CountDownLatch is a synchronization tool class that enables a thread to wait for other threads to complete their work before executing. For example, the main thread of an application wants to execute after the thread responsible for starting the framework service has started all the framework services.
CountDownLatch is implemented through a counter. The initial value of the counter is the number of threads. Every time a thread completes its task, the value of the counter will decrease by 1. When the counter value reaches 0, it indicates that all threads have completed the task, and then the threads waiting on the lock can resume executing the task.
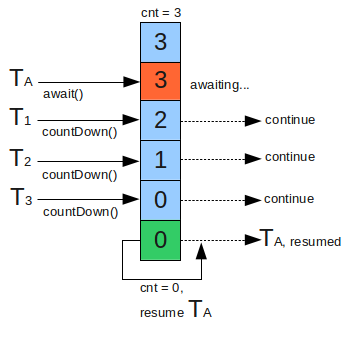
The pseudo code of CountDownLatch is as follows:
Main thread start
Create CountDownLatch for N threads
Create and start N threads
Main thread wait on latch
N threads completes there tasks are returns
Main thread resume execution
2.2. 2 how does countdownlatch work
CountDownLatch. Constructor defined in Java class:
public CountDownLatch(int count) { };
The count in the constructor is actually the number of threads waiting for locking. This value can only be set once, and CountDownLatch does not provide any mechanism to reset this count.
The first interaction with CountDownLatch is that the main thread waits for other threads. The main thread must call CountDownLatch. Immediately after starting other threads Await() method. In this way, the operation of the main thread will block on this method until other threads complete their tasks.
The other N threads must reference the locking object because they need to notify the CountDownLatch object that they have completed their tasks. This notification mechanism is through CountDownLatch Countdown() method; Every time this method is called, the count value initialized in the constructor is reduced by 1. Therefore, when N threads call this method, the value of count is equal to 0, and then the main thread can resume executing its own tasks through the await() method.
There are three methods in the class that are most important:
- Await(): the thread calling await() method will be suspended, and it will wait until the count value is 0
public void await() throws InterruptedException { }; - await(long timeout, TimeUnit unit): similar to await(), the execution will continue if the count value has not changed to 0 after a certain time
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { }; - countDown(): decrease the count value by 1
public void countDown() { };
2.2.3 CountDownLatch usage example
Use a typical i + + example to illustrate:
public class Test {
private int i = 0;
private final CountDownLatch mainLatch = new CountDownLatch(1);
public void add(){
i++;
}
private class Work extends Thread{
private CountDownLatch threadLatch;
public Work(CountDownLatch latch){
threadLatch = latch;
}
@Override
public void run() {
try {
mainLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int j = 0; j < 1000; j++) {
add();
}
threadLatch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
for(int k = 0; k < 10; k++){
Test test = new Test();
CountDownLatch threadLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
test.new Work(threadLatch).start();
}
test.mainLatch.countDown();
threadLatch.await();
System.out.println(test.i);
}
}
}
2.2.4 CountDownLatch example description
java. util. concurrent. Countdown latch acts like a latch or gate. The above code is executed 10 times, starting 10 threads at a time. In 10 threads at a time, mainlatch Await () is equivalent to the latch blocking the thread, keeping the 10 threads ready each time in the waiting state. When the 10 threads are ready each time, call mainlatch Countdown () method, open the latch and let the thread execute at the same time. mainLatch. The reason why await () is used here is to make the 10 threads created ready for concurrent execution. Only in this way can we clearly see the i + + effect in the add method. If CountDownLatch is not introduced, only test new Work(threadLatch). Start(), the result may not show the error caused by the thread competing for shared variables.
The CountDownLatch of threadLatch in the main thread is used to notify the threadLatch of the main thread after all 10 threads have executed the for loop of the run method Await() stops waiting for the value of the current i to be printed out.
Several obvious results are obtained. Of course, you can also run it several times to see the effect.

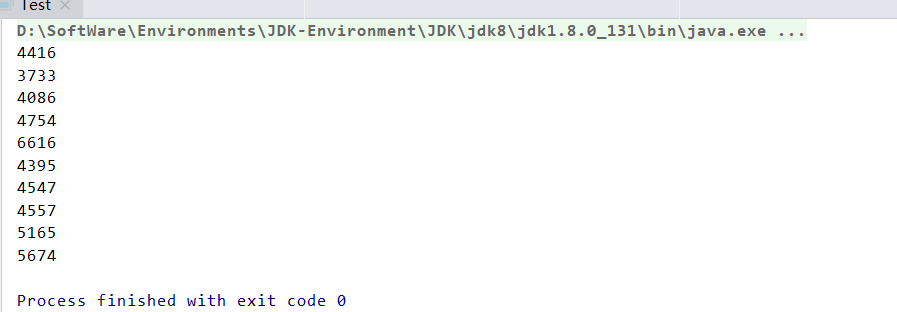
Shared variable i does not do any synchronization operation. When multiple threads have to read and modify it, the problem arises. The correct result should be 10000, but we see that it is not 10000 every time. The original version of this code is not like this, because the CPU core frequency of the current CPU, even the home PC, is very high, so there is no effect at all. The greater the number of cycles in the run method, the more obvious the concurrency problem of i. you can try it. The running results shown in the figure above are related to the hardware platform
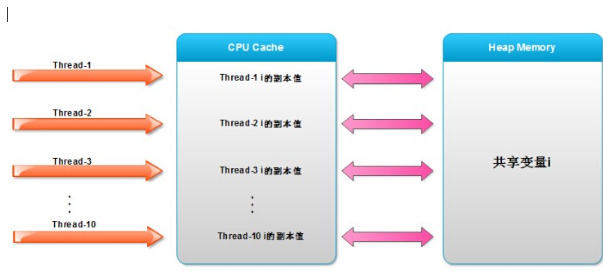
How do threads manipulate shared variables in Java? As we all know, java code will become bytecode after compilation and then run in the JVM. Variables such as instance domain i are stored in Heap Memory, which is an area of memory. In the final analysis, thread execution is CPU execution. Today's CPUs (Intel) are basically multi-core, so multi threads are processed by multi-core CPUs, and there are L1, L2 or L3 CPU caches. In order to improve the processing speed, the CPU will read data from memory to the cache before operation. The process of each thread executing add method operation i + + is as follows:
- The thread reads the value of i from heap memory and copies it into the cache
- Perform the i + + operation in the cache and assign the result to the variable i
- Then refresh the value of variable i in heap memory with the value in cache
The above three steps are not strictly in accordance with the JVM and CPU instructions, but the process is one thing for everyone to understand. Through the above process, we can see the problem. If multiple threads want to modify i at the same time, they need to read the value of variable i in heap memory, copy it to cache, perform i + + operation, and then write the result back to variable i in heap memory. The execution time is very short, maybe only a few tenths of a nanosecond (mainly related to the hardware platform), but there are still errors. The reason for this error is the visibility of shared variables. When thread 1 reads the value of variable i, thread 2 is updating the value of variable i, while thread 1 cannot see the value modified by thread 2. This phenomenon is often referred to as shared variable visibility.
The following figure is an abstract diagram of thread execution, or an abstract diagram of Java memory model. It may not be rigorous, but the general idea is this.
At present, Spring or something like Spring is generally selected as the development framework, and if the dependency injection beans often used in the code are not processed, they will generally be in singleton mode. Imagine referencing a Service or other similar Bean in the following way, accidentally using shared variables in UserService, and not dealing with its shared visibility, that is, synchronization, which will produce unexpected results. Not only the Service is singleton, but also the Controller in Spring MVC is singleton, so you must pay attention to the problem of sharing variables when writing code.
@Autowired
private UserService userService;
Therefore, do not use shared variables as much as possible and avoid it, because it is not a very simple problem to deal with the visibility of shared variables. If you have a reason to use it, use Java util. concurrent. The atomic class under the atomic package replaces the common variable types. For example, AtomicInteger replaces int, AtomicLong replaces long, and so on