Official account: Special House
Author: Peter
Editor: Peter
Hello, I'm Peter~
This article introduces the four row column conversion methods in Pandas, including:
- melt
- transpose T or transfer
- wide_to_long
- explode (explosion function)
Finally, answer a data processing question asked by a reader friend.

Pandas row column conversion
There are many methods in pandas to realize row column conversion:
Import library
import pandas as pd import numpy as np
Function melt
Main parameters of melt:
pandas.melt(frame,
id_vars=None,
value_vars=None,
var_name=None,
value_name='value',
ignore_index=True,
col_level=None)
The meaning of parameters is explained below:
-
Frame: the data frame to process.
-
id_vars: indicates column names that do not need to be converted
-
value_vars: indicates the column name to be converted. If all the remaining columns need to be converted, it is unnecessary to write
-
var_name and value_name: the column name corresponding to the custom setting, which is equivalent to taking a new column name
-
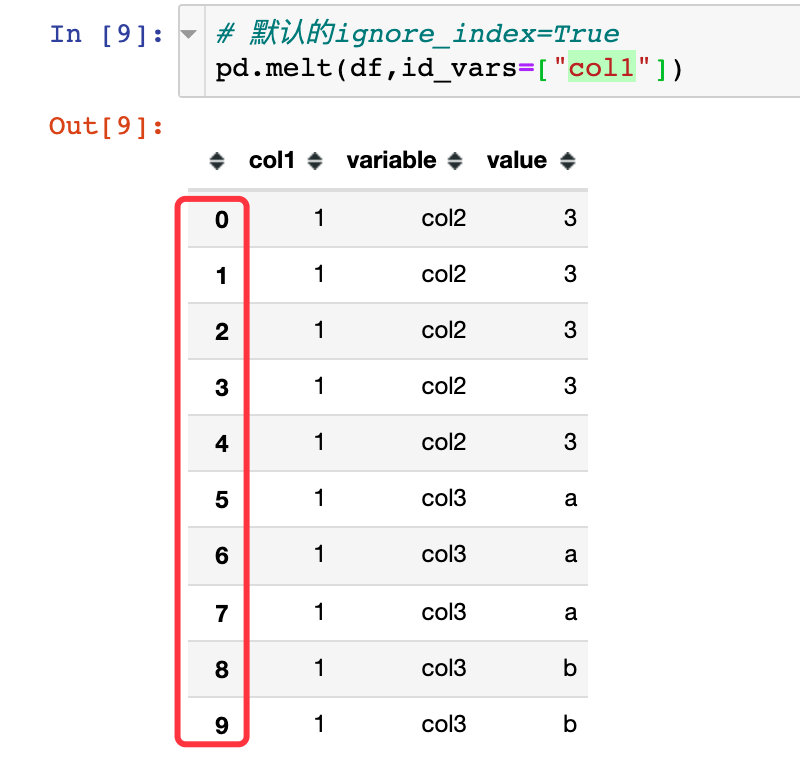
igonore_index: whether to ignore the original column name. The default is True, which means that the original index name is ignored and the natural index of 0,1,2,3,4... Is regenerated
-
col_level: this parameter is used if the column is a multi-level index column MultiIndex; This parameter is rarely used
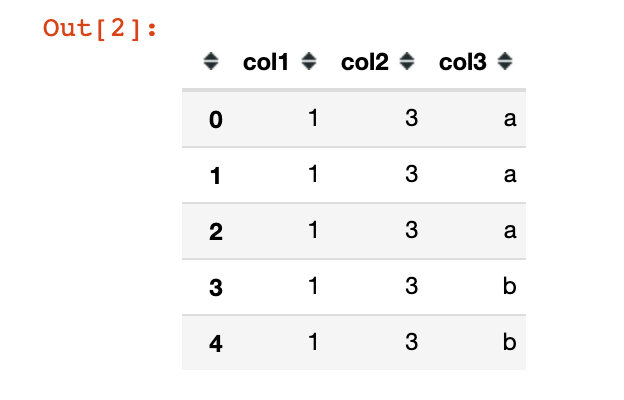
Analog data
# Data to be converted: frame
df = pd.DataFrame({"col1":[1,1,1,1,1],
"col2":[3,3,3,3,3],
"col3":["a","a","a","b","b"]
})
df
id_vars

value_vars

The above two parameters are used simultaneously:
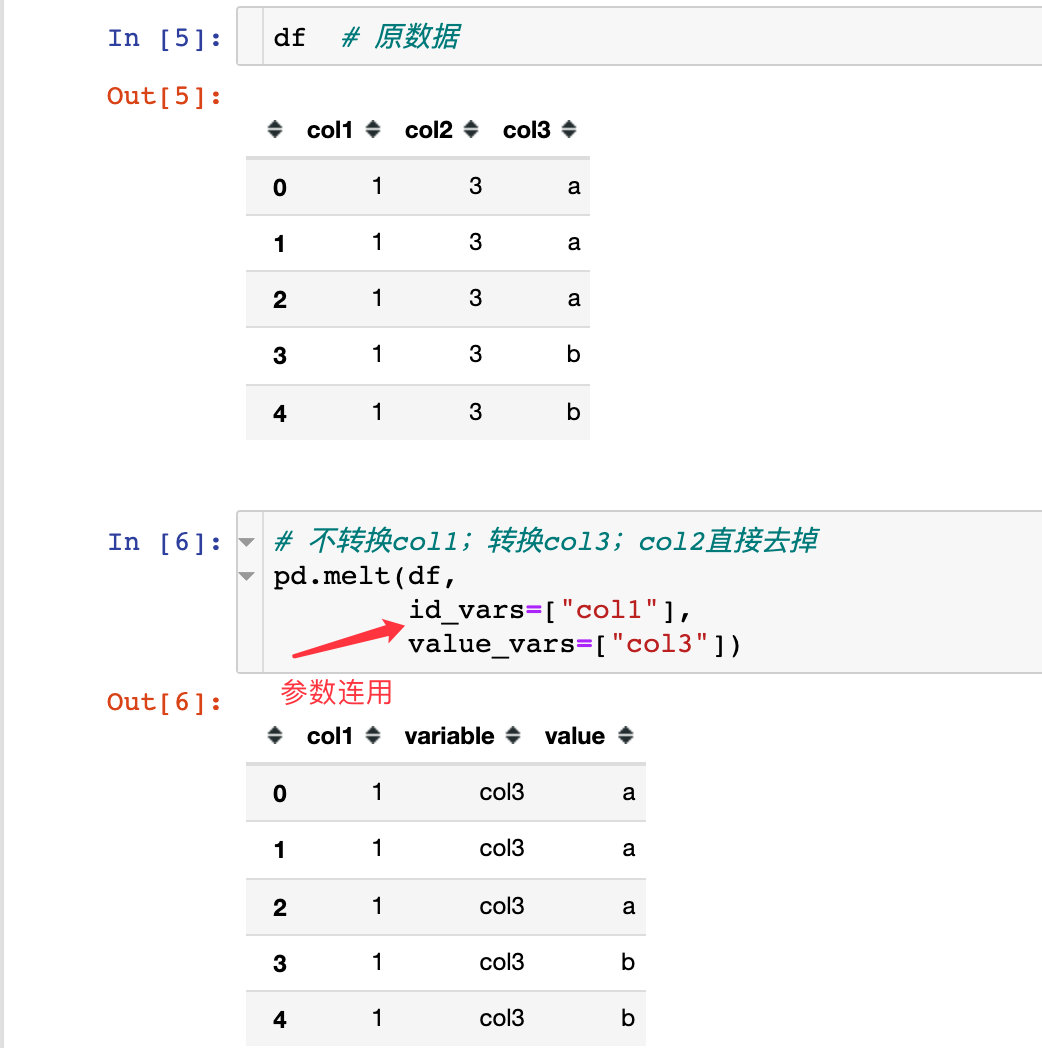
Convert multiple column attributes at the same time:
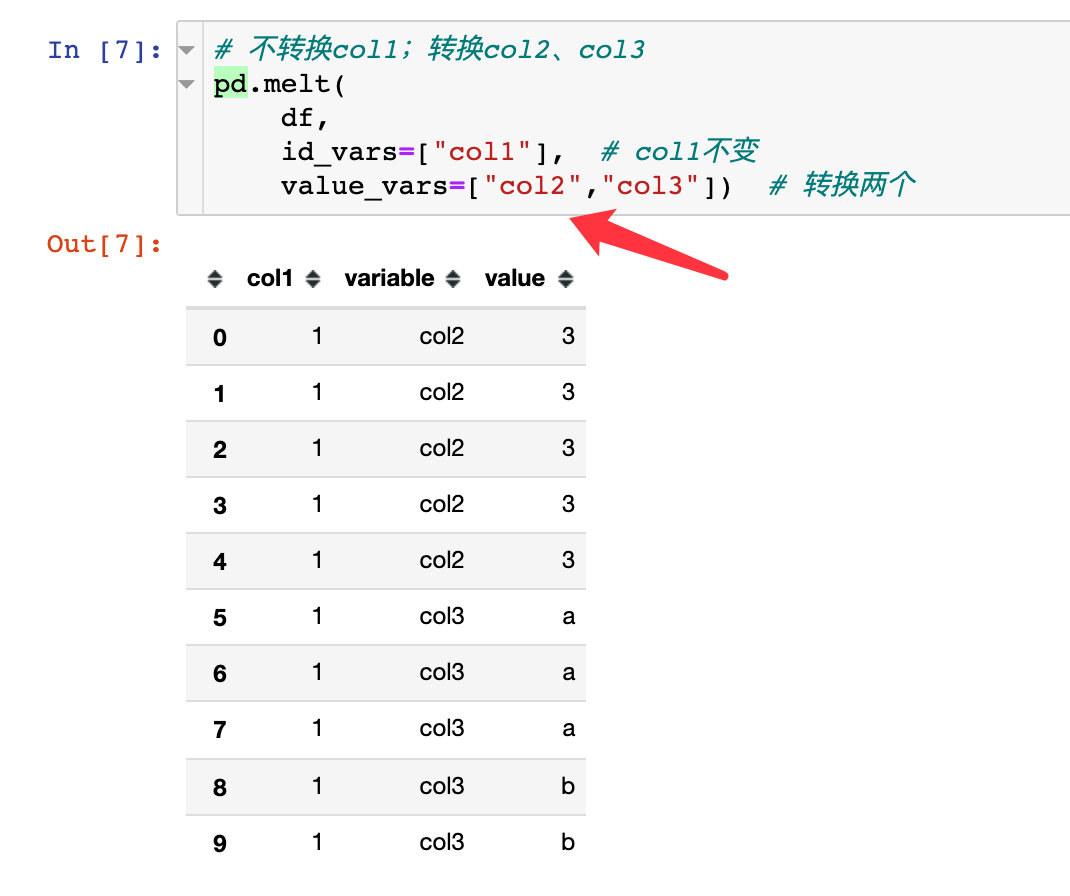
var_name and value_name
pd.melt(
df,
id_vars=["col1"], # unchanged
value_vars=["col3"], # change
var_name="col4", # New column name
value_name="col5" # The new column name of the corresponding value
)
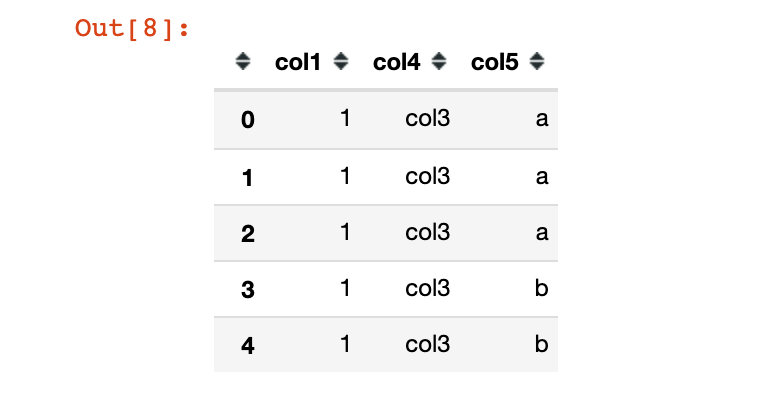
ignore_index
Natural indexes are generated by default:
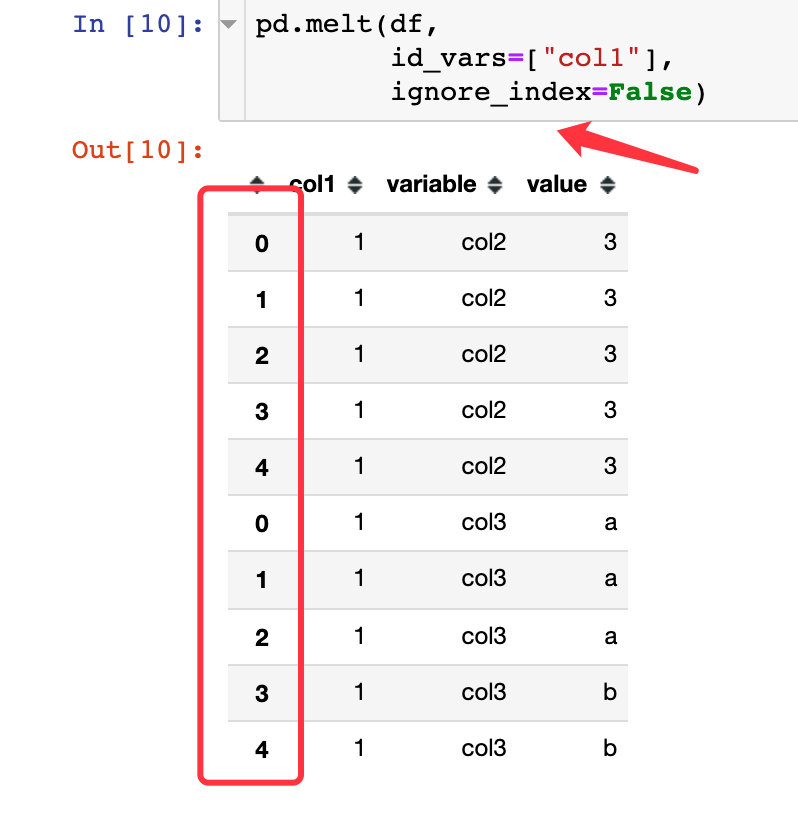
You can change it to False and use the original index:
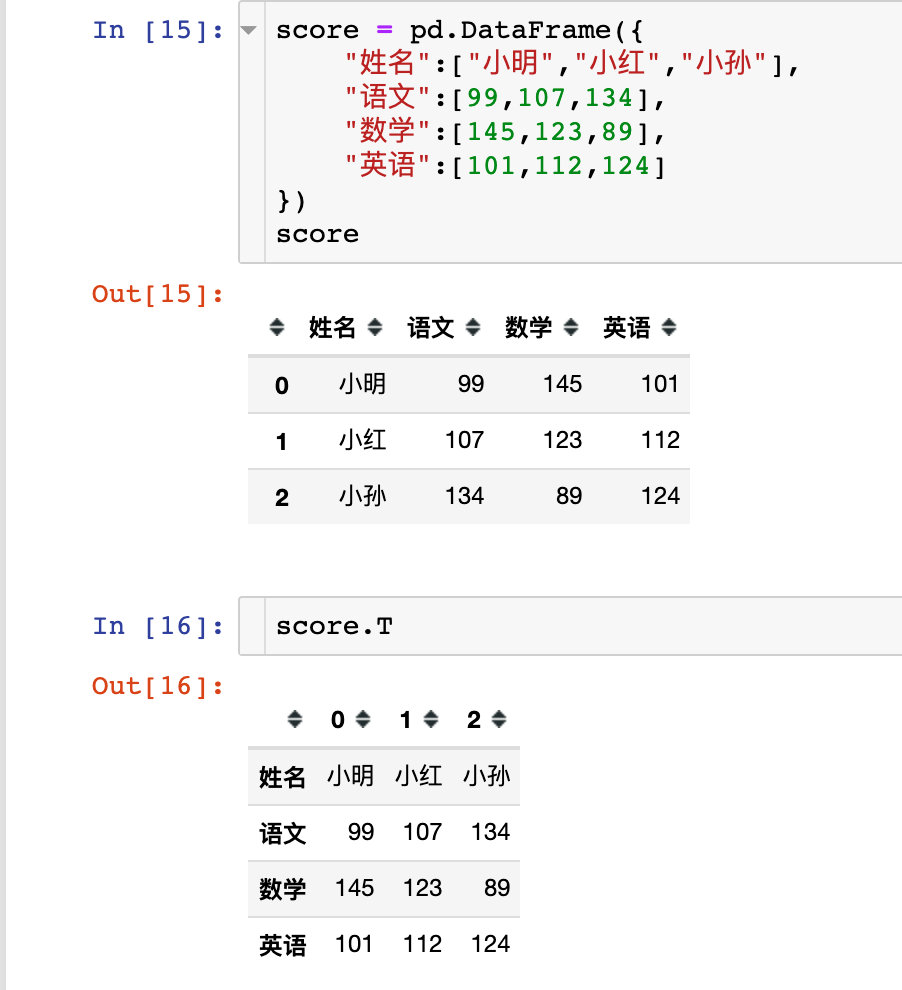
Transpose function
The T attribute or transfer function in pandas implements the function of row to column conversion, which is exactly transpose
Simple transpose
Simulate a piece of data and view the transposed results:

Transpose using the transpose function:

There is another method: first transpose the value values, and then exchange the index and column names:

Finally, let's look at a simple case:
wide_to_long function
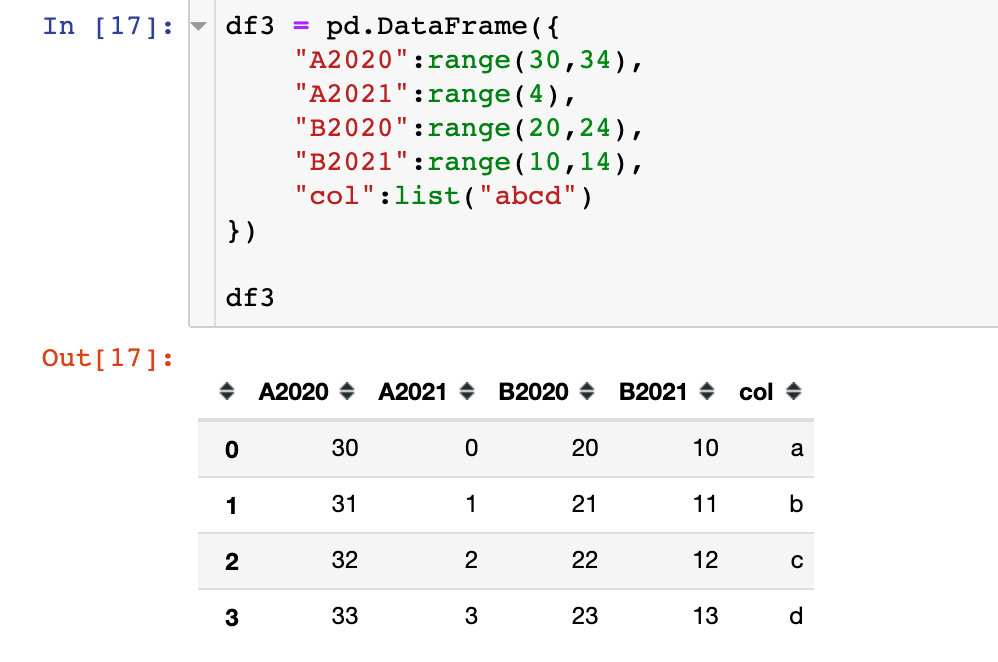
Literally: convert a dataset from a wide format to a long format
wide_to_long(
df,
stubnames,
i,
j,
sep: str = "",
suffix: str = "\\d+"
Specific explanation of parameters:
- df: data frame to be converted
- Stub names: the part of a wide table with the same column name
- i: Column to use as id variable
- j: Set columns for long format suffix columns
- sep: sets the separator to delete. For example, if columns is A-2020, specify sep = '-' to delete the separator. The default value is empty.
- Suffix: get "suffix" by setting regular expression. Default '\ D +' means to obtain a numeric suffix. "Suffix" without numbers can be obtained by '\ D +'
Analog data
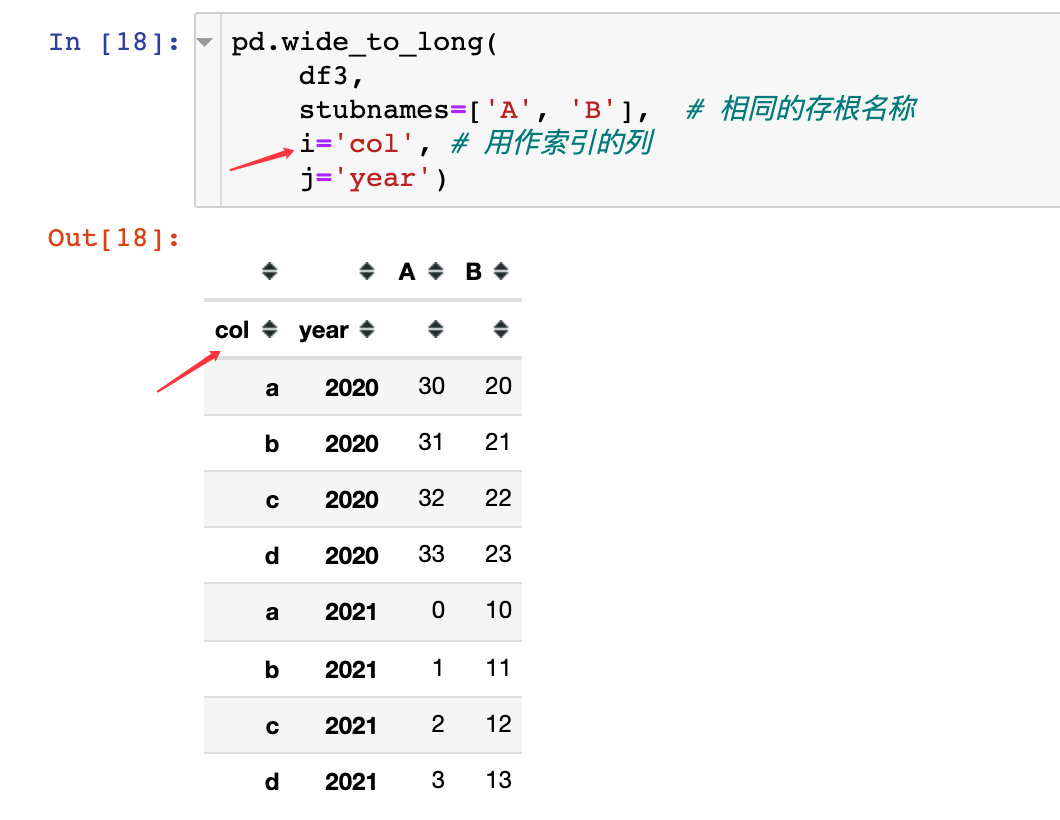
Conversion process
Use functions to implement transformations:
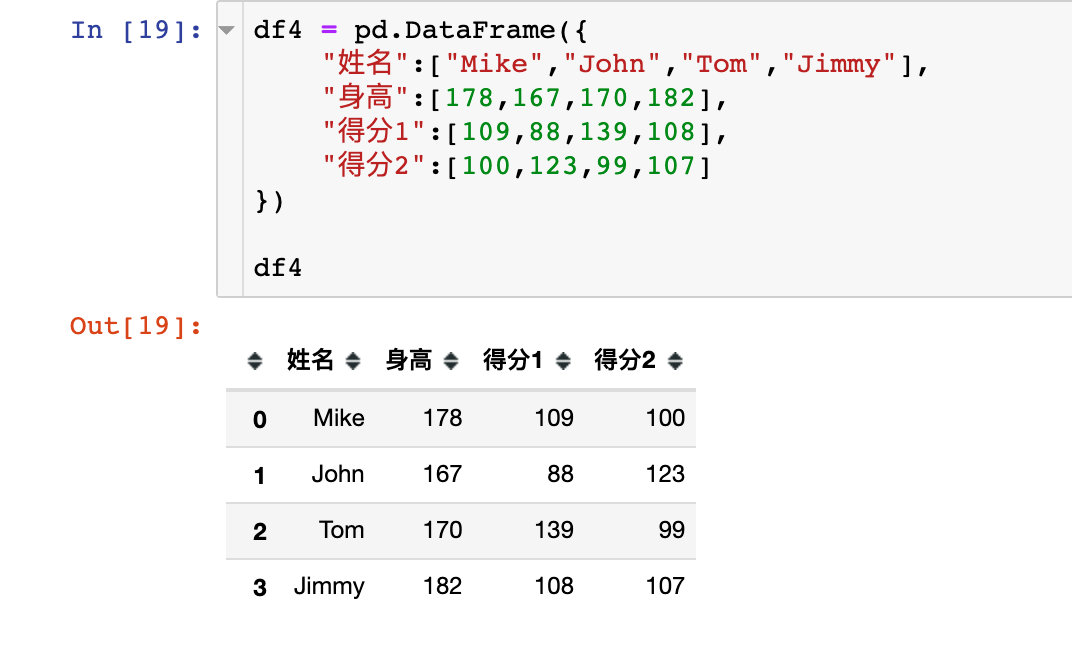
Set multi-level index
First simulate a data:

If you are not used to multi-layer indexes, you can convert them to the following format:
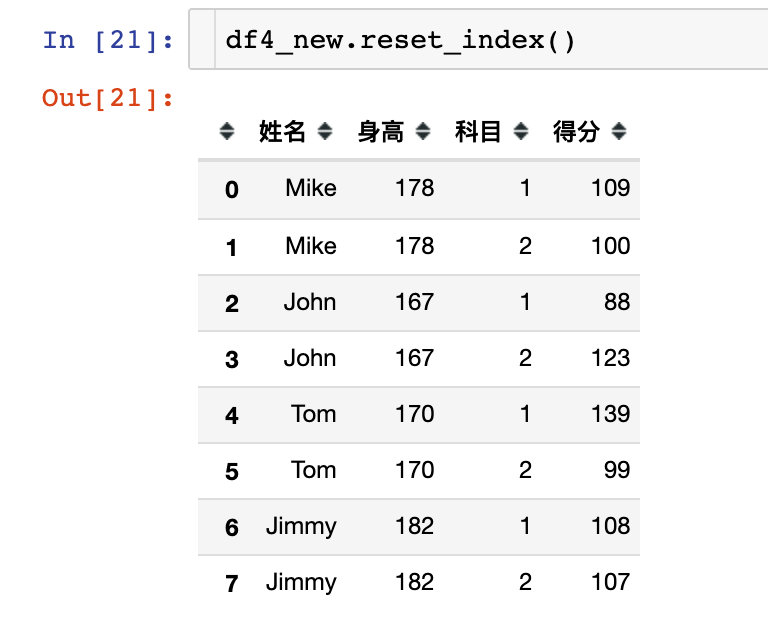
sep and suffix
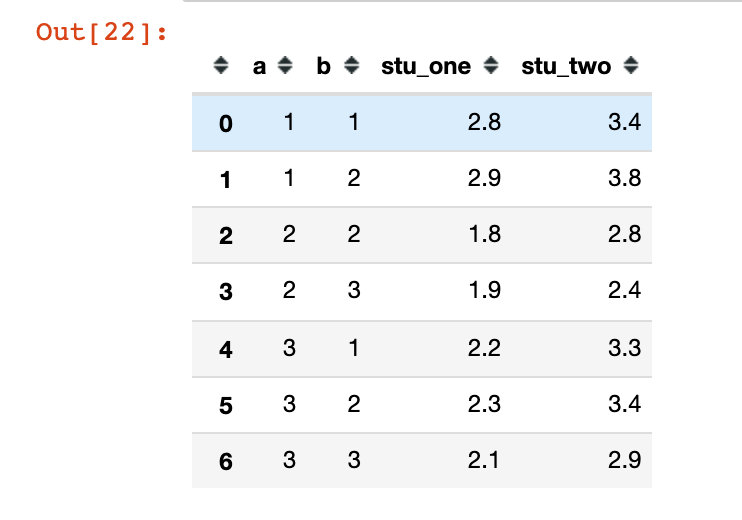
df5 = pd.DataFrame({
'a': [1, 1, 2, 2, 3, 3, 3],
'b': [1, 2, 2, 3, 1, 2, 3],
'stu_one': [2.8, 2.9, 1.8, 1.9, 2.2, 2.3, 2.1],
'stu_two': [3.4, 3.8, 2.8, 2.4, 3.3, 3.4, 2.9]
})
df5
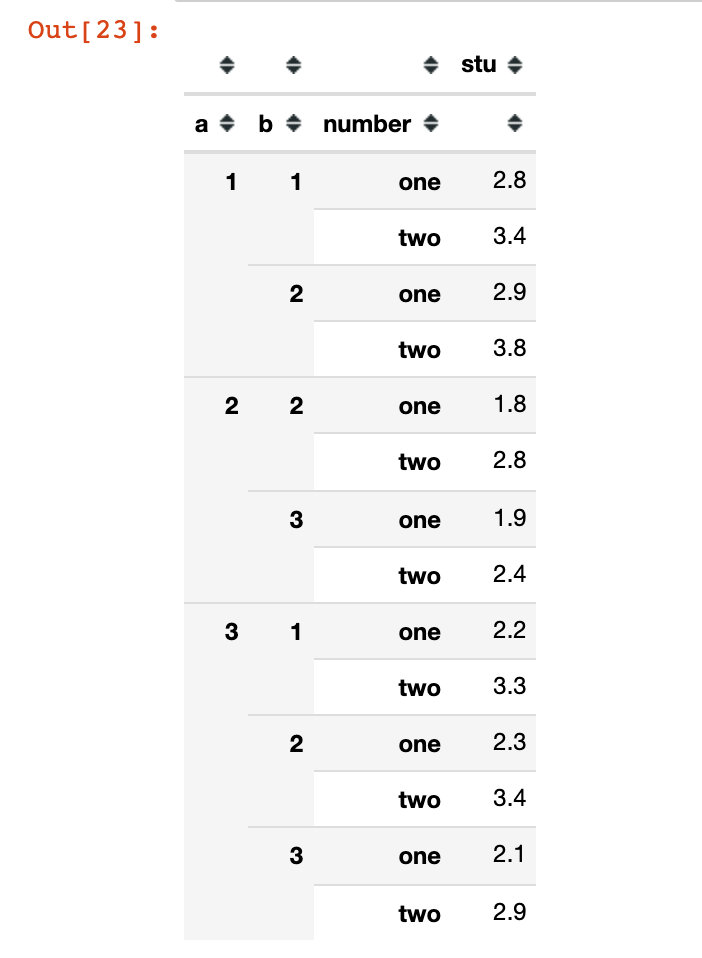
pd.wide_to_long(
df5,
stubnames='stu',
i=['a', 'b'],
j='number',
sep='_', # Used when there is a connector in the column name; The default is empty
suffix=r'\w+') # Suffix based on regular expression; The default is number \ d +; It's changed here to \ w +, which means letters
Explosion function
explode(column, ignore_index=False)
This function has only two parameters:
- column: element to explode
- ignore_index: whether to ignore the index; The default is False and the original index is maintained
Analog data

Single field explosion
Perform an explosion process on a single field and transfer the wide table to the long table:

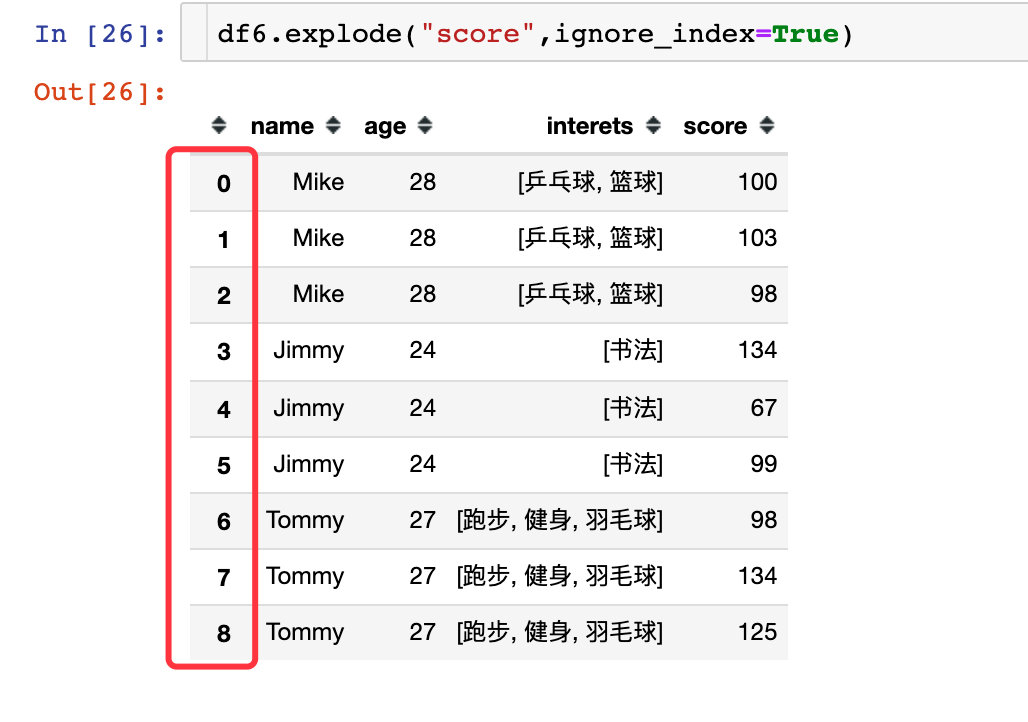
Parameter ignore_index
Multiple field explosion
The process of continuously exploding multiple fields:

Readers' doubts
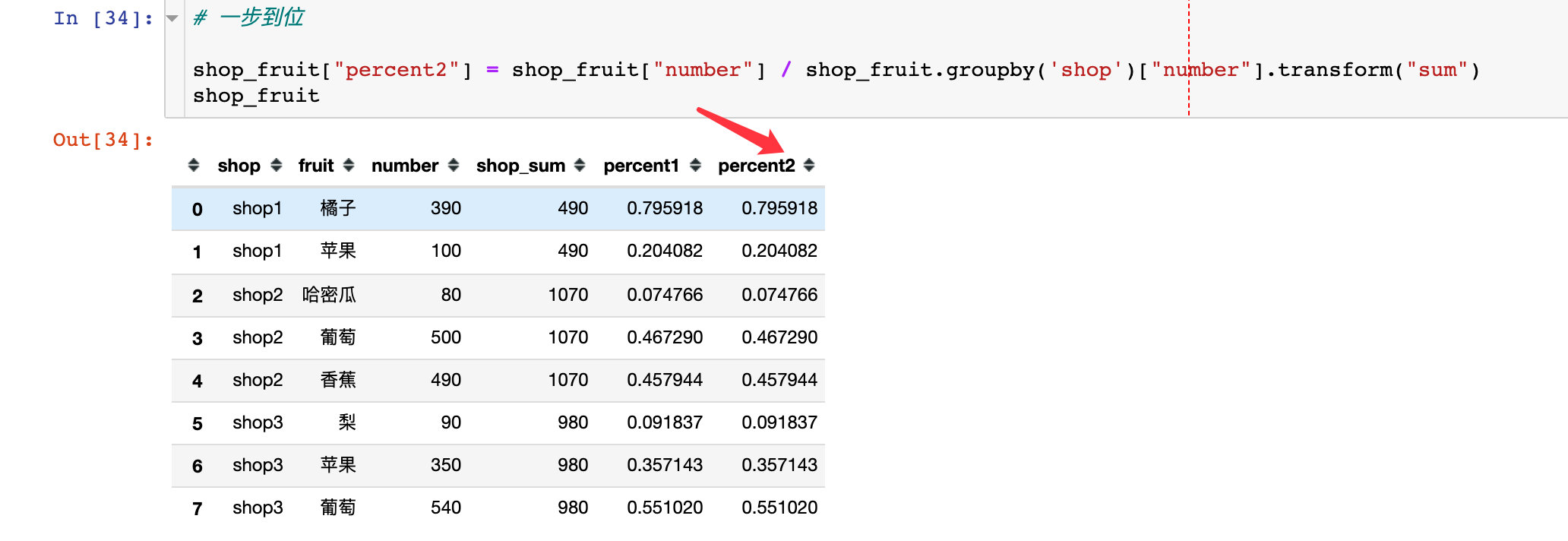
Here to answer a reader's question, the data is in the form of simulation. The following data is required:
Proportion of each fruit in each shop
fruit = pd.DataFrame({
"shop":["shop1","shop3","shop2","shop3",
"shop2","shop1","shop3","shop2",
"shop3","shop2","shop3","shop2","shop1"],
"fruit":["Apple","Grape","Banana","Apple",
"Grape","a mandarin orange","Pear","Hami melon",
"Grape","Banana","Apple","Grape","a mandarin orange"],
"number":[100,200,340,150,
200,300,90,80,340,
150,200,300,90]})
fruit

First, we need to count the sales of each shop and each fruit
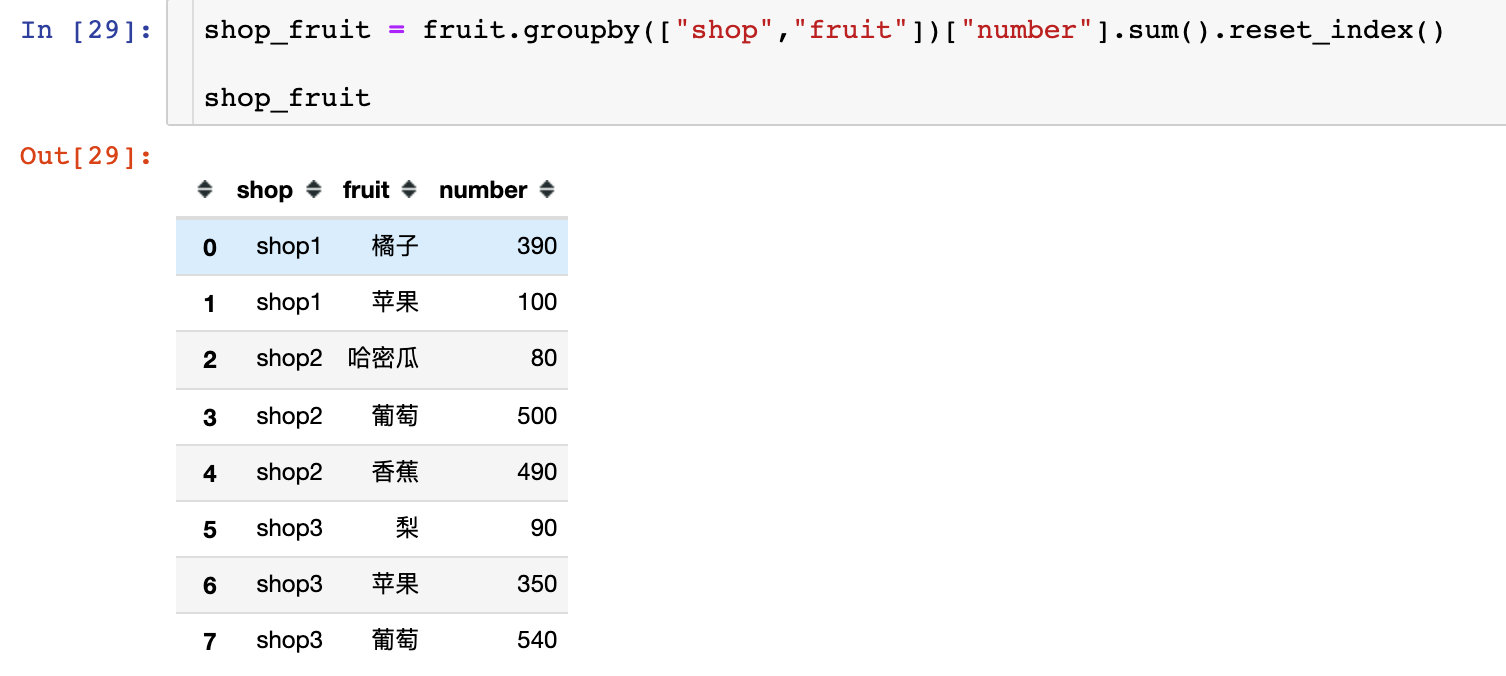
Method 1: multi step
Method 1 uses a multi-step solution:
1. Total sales per shop

2. Add total shop_sum column
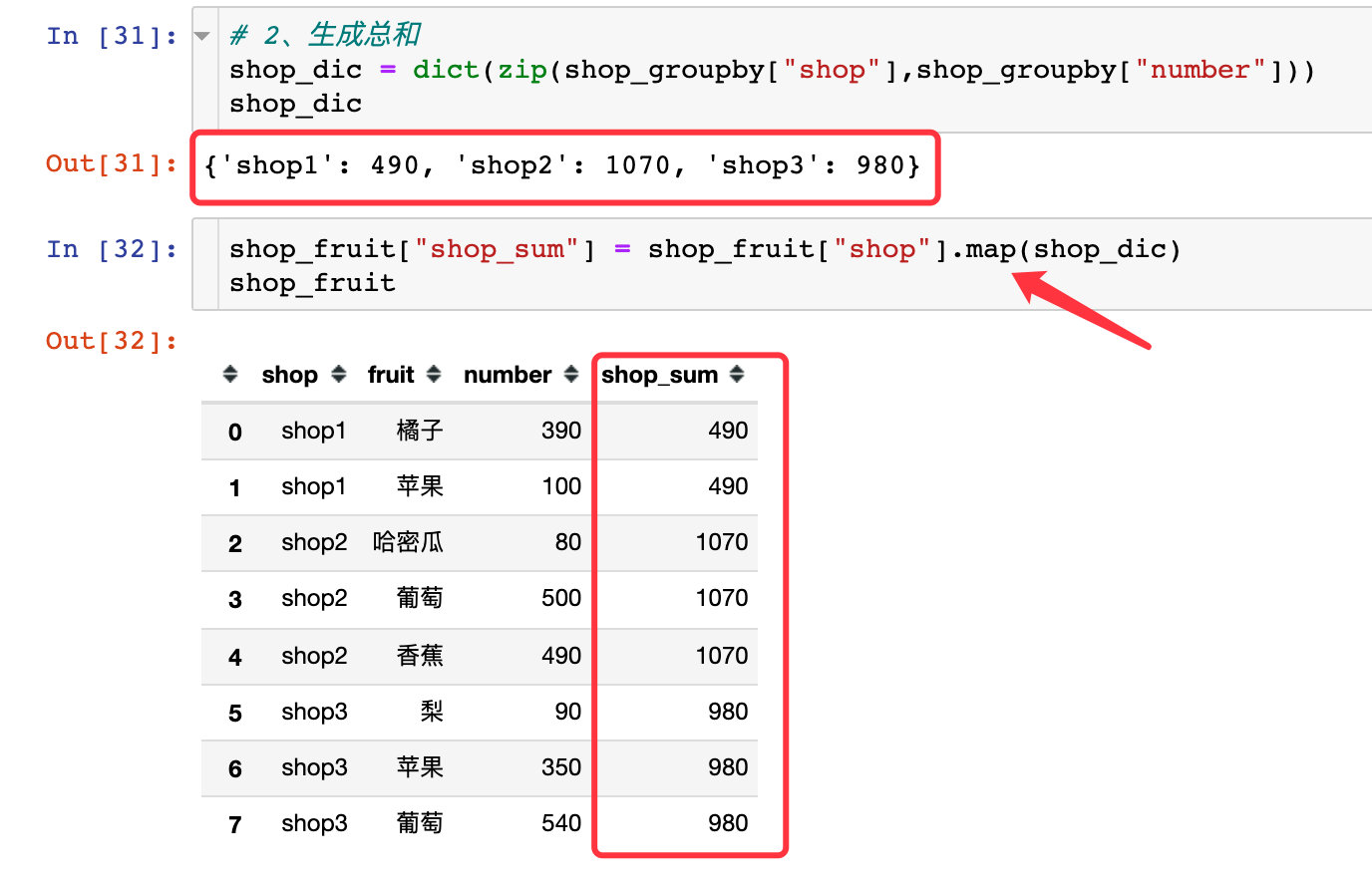
3. Generation proportion
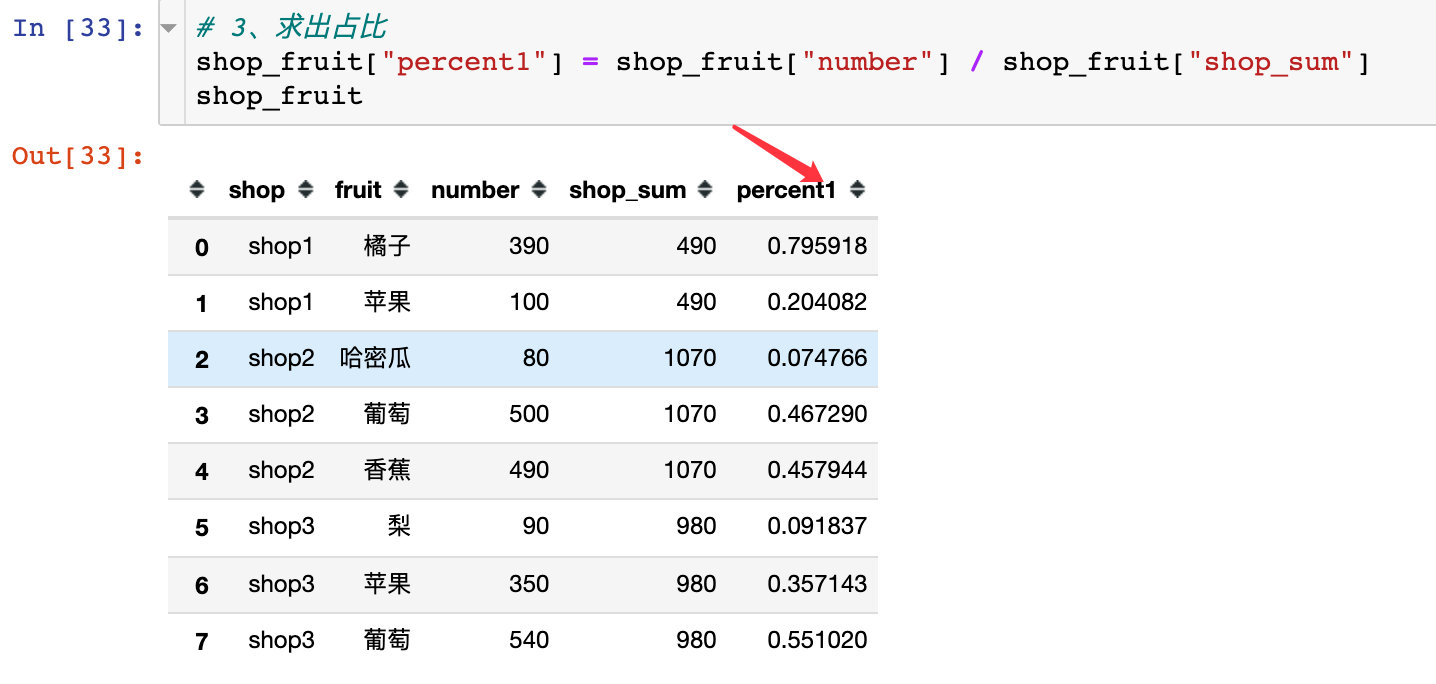
Method 2: use the transform function