Let's answer the questions before moving on. Two days ago, a little partner asked a question privately and said:
What should I do if some tables have sub database and sub table, and the other tables have no sub database and sub table? How can I access normally?
This is a typical problem. We know that sub database and sub table are for some tables with continuous and significant growth in data volume, such as user table and order table, rather than splitting all tables across the board. There are generally two solutions to how to divide non fragmented tables and fragmented tables.
- Strictly divide the function libraries, separate the partitioned libraries from the non partitioned libraries, and switch the data source access in the business code as needed
- Set the default data source. Take sharding JDBC as an example. If you do not set sharding rules for non sharding tables, they will not be executed because the routing rules cannot be found. At this time, we set a default data source and access the default library when the rules cannot be found.
# Configure data source ds-0 spring.shardingsphere.datasource.ds-0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.ds-0.driverClassName=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds-0.url=jdbc:mysql://47.94.6.5:3306/ds-0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT spring.shardingsphere.datasource.ds-0.username=root spring.shardingsphere.datasource.ds-0.password=root # Default data source, default execution library for non fragmented tables spring.shardingsphere.sharding.default-data-source-name=ds-0
In this article, we will practice the usage of four fragmentation strategies for specific SQL usage scenarios, and make some preparations before starting.
- Standard fragmentation strategy
- Composite fragmentation strategy
- Row expression slicing strategy
- Hint fragmentation strategy
preparation
First create two databases ds-0 and ds-1, and create tables t in the two databases_ order_ 0,t_order_1,t_order_2 ,t_order_item_0,t_order_item_1,t_ order_ item_ There are 26 tables. Let's see how to apply the four sharding strategies of sharding JDBC in different scenarios.
t_order_n table structure is as follows:
CREATE TABLE `t_order_0` ( `order_id` bigint(200) NOT NULL, `order_no` varchar(100) DEFAULT NULL, `user_id` bigint(200) NOT NULL, `create_name` varchar(50) DEFAULT NULL, `price` decimal(10,2) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
t_order_item_n table structure is as follows:
CREATE TABLE `t_order_item_0` ( `item_id` bigint(100) NOT NULL, `order_id` bigint(200) NOT NULL, `order_no` varchar(200) NOT NULL, `item_name` varchar(50) DEFAULT NULL, `price` decimal(10,2) DEFAULT NULL, PRIMARY KEY (`item_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
The partition strategy is divided into table partition strategy and database partition strategy. They basically implement the partition algorithm in the same way. The difference is that one pair of databases ds-0, ds-1 and one pair of tables t_order_0 ··· t_order_n wait for processing.
Standard fragmentation strategy
Usage scenario: there are >, > =, < =, < =, <, =, IN and BETWEEN AND operators IN the SQL statement. This fragmentation strategy can be applied.
The standard sharding strategy only supports database and table splitting based on a single sharding key (field), and provides two sharding algorithms, precision sharding algorithm and range sharding algorithm.
When using the standard sharding strategy, the accurate sharding algorithm must be implemented for sharding processing with SQL = and IN; The processing range containing the tween algorithm is a non mandatory partition.
Once we do not configure the range slicing algorithm and use BETWEEN AND or like in SQL, the SQL will be executed one by one in the way of full database and table routing, and the query performance will be very poor, which needs special attention.
Next, we customize the accurate segmentation algorithm and range segmentation algorithm.
1. Accurate segmentation algorithm
1.1 accurate database sorting algorithm
The way to implement custom accurate database and table splitting algorithms is roughly the same. We need to implement the PreciseShardingAlgorithm interface and rewrite the doSharding() method, but the configuration is slightly different, and it is only an empty method. We have to deal with the database and table splitting logic ourselves. The same is true for other segmentation strategies.
SELECT * FROM t_order where order_id = 1 or order_id in (1,2,3);
Next, we realize the accurate database distribution strategy by setting the order by dividing the pieces_ The ID module (how to implement it depends on your preference) calculates which database the SQL should be routed to, and the calculated fragment library information will be stored in the fragment context for easy use in subsequent fragment tables.
/**
* @author xiaofu Official account [programmer]
* @description Custom standard sub Library Policy
* @date 2020/10/30 13:48
*/
public class MyDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {
/**
* databaseNames Collection of all fragment libraries
* shardingValue Is the partition attribute, where logicTableName is the logical table, columnName is the partition key (field), and value is the value of the partition key parsed from SQL
*/
for (String databaseName : databaseNames) {
String value = shardingValue.getValue() % databaseNames.size() + "";
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
The collection < string > parameter is used consistently in several partition strategies. In database partition, the value is the set databaseNames of all partition libraries, and in table partition, it is the set tablesNames of all partition tables in the corresponding partition library; PreciseShardingValue is the partition attribute, where logicTableName is the logical table, columnName is the partition key (field), and value is the value of the partition key parsed from SQL.
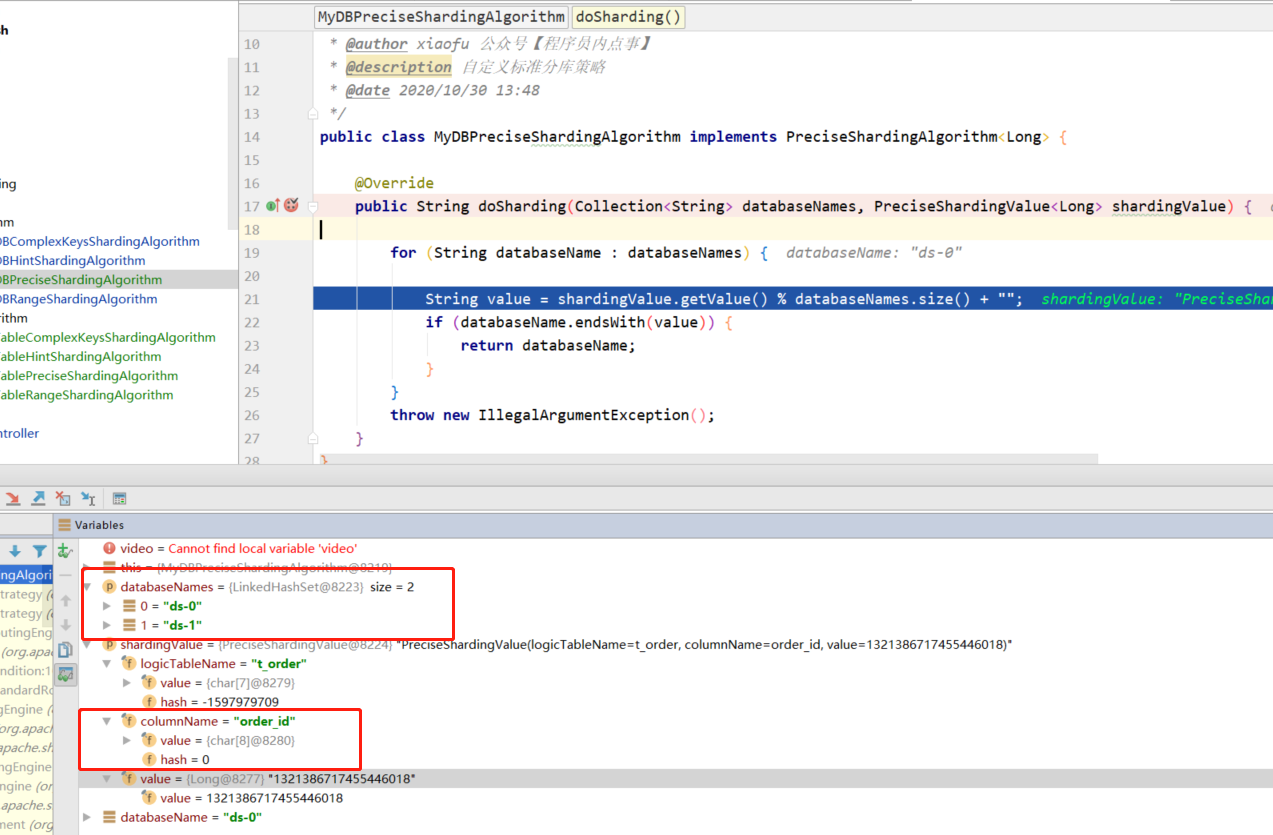
And application In the properties configuration file, you only need to modify the database strategy name to standard mode and the fragmentation algorithm standard Precision algorithm class name is the customized class path of accurate database sorting algorithm.
### Sub database strategy # Database and slice health spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id # Partition algorithm spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBPreciseShardingAlgorithm
1.2 accurate table splitting algorithm
The precise table splitting algorithm also implements the PreciseShardingAlgorithm interface and rewrites the doSharding() method.
/**
* @author xiaofu Official account [programmer]
* @description Custom standard table splitting policy
* @date 2020/10/30 13:48
*/
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue) {
/**
* tableNames Corresponding to the set of all shard tables in the shard library
* shardingValue Is the partition attribute, where logicTableName is the logical table, columnName is the partition key (field), and value is the value of the partition key parsed from SQL
*/
for (String tableName : tableNames) {
/**
* Modular algorithm, number of partition key% tables
*/
String value = shardingValue.getValue() % tableNames.size() + "";
if (tableName.endsWith(value)) {
return tableName;
}
}
throw new IllegalArgumentException();
}
}
When splitting tables, the collection < string > parameter is the partition library calculated above, and the set tablesNames of all corresponding partition tables; PreciseShardingValue is the partition attribute, where logicTableName is the logical table, columnName is the partition key (field), and value is the value of the partition key parsed from SQL.
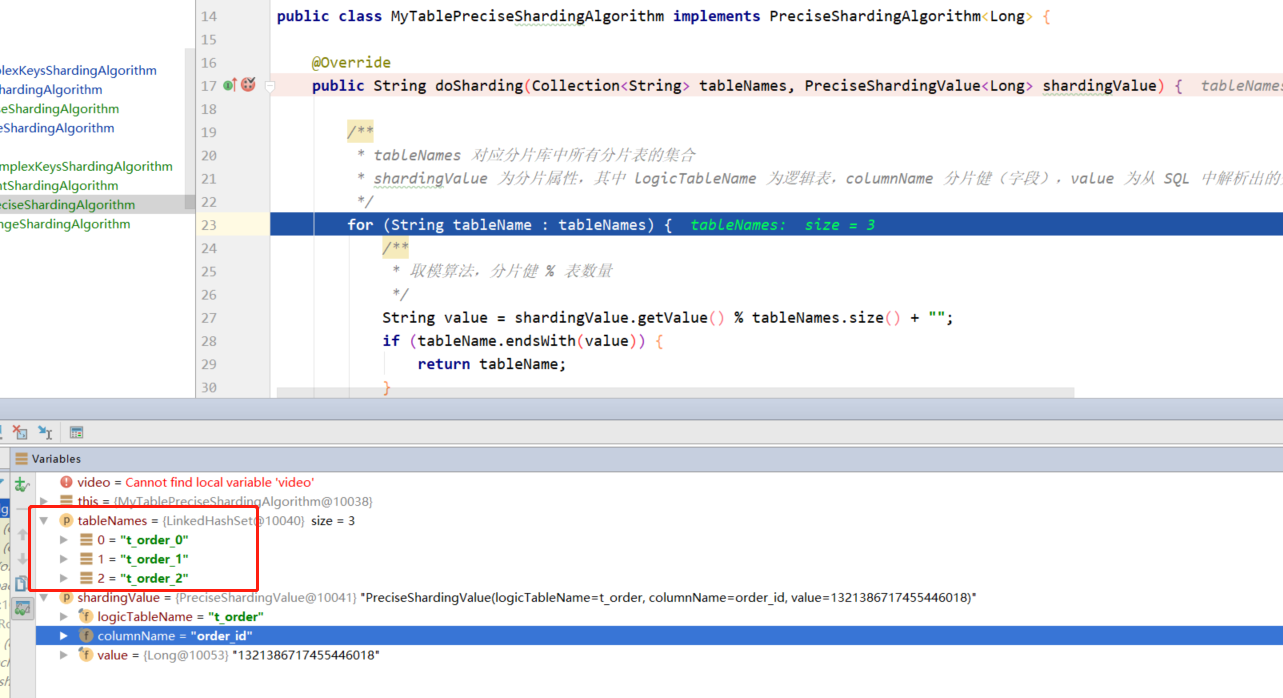
application. In the properties configuration file, you only need to modify the table splitting policy name database strategy to standard mode and fragmentation algorithm standard Precision algorithm class name is the customized class path of accurate table splitting algorithm.
# Table splitting strategy # Table and slice health spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id # Split table algorithm spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.xiaofu.sharding.algorithm.tableAlgorithm.MyTablePreciseShardingAlgorithm
It is not difficult to see that the implementation of custom sub database and sub table algorithm is basically the same, so we only demonstrate sub database later
2. Range slicing algorithm
Usage scenario: when the BETWEEN AND operator is used in the partition key field in SQL, this algorithm will be used, and the database and table logic will be processed according to the partition key value range given in SQL.
SELECT * FROM t_order where order_id BETWEEN 1 AND 100;
The user-defined range slicing algorithm needs to implement the RangeShardingAlgorithm interface and rewrite the doSharding() method. Next, I calculate the logic of each sub database and sub table by traversing the partition key value interval.
/**
* @author xinzhifu
* @description Range sorting algorithm
* @date 2020/11/2 12:06
*/
public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> databaseNames, RangeShardingValue<Integer> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
// Starting value of between and
int lower = rangeShardingValue.getValueRange().lowerEndpoint();
int upper = rangeShardingValue.getValueRange().upperEndpoint();
// Cycle range calculation sub database logic
for (int i = lower; i <= upper; i++) {
for (String databaseName : databaseNames) {
if (databaseName.endsWith(i % databaseNames.size() + "")) {
result.add(databaseName);
}
}
}
return result;
}
}
Like the above, collection < string > represents the partition library name and table name collection respectively when dividing the database and table. RangeShardingValue has a slightly different value method here. Lowerentpoint represents the start value and upperEndpoint represents the end value.
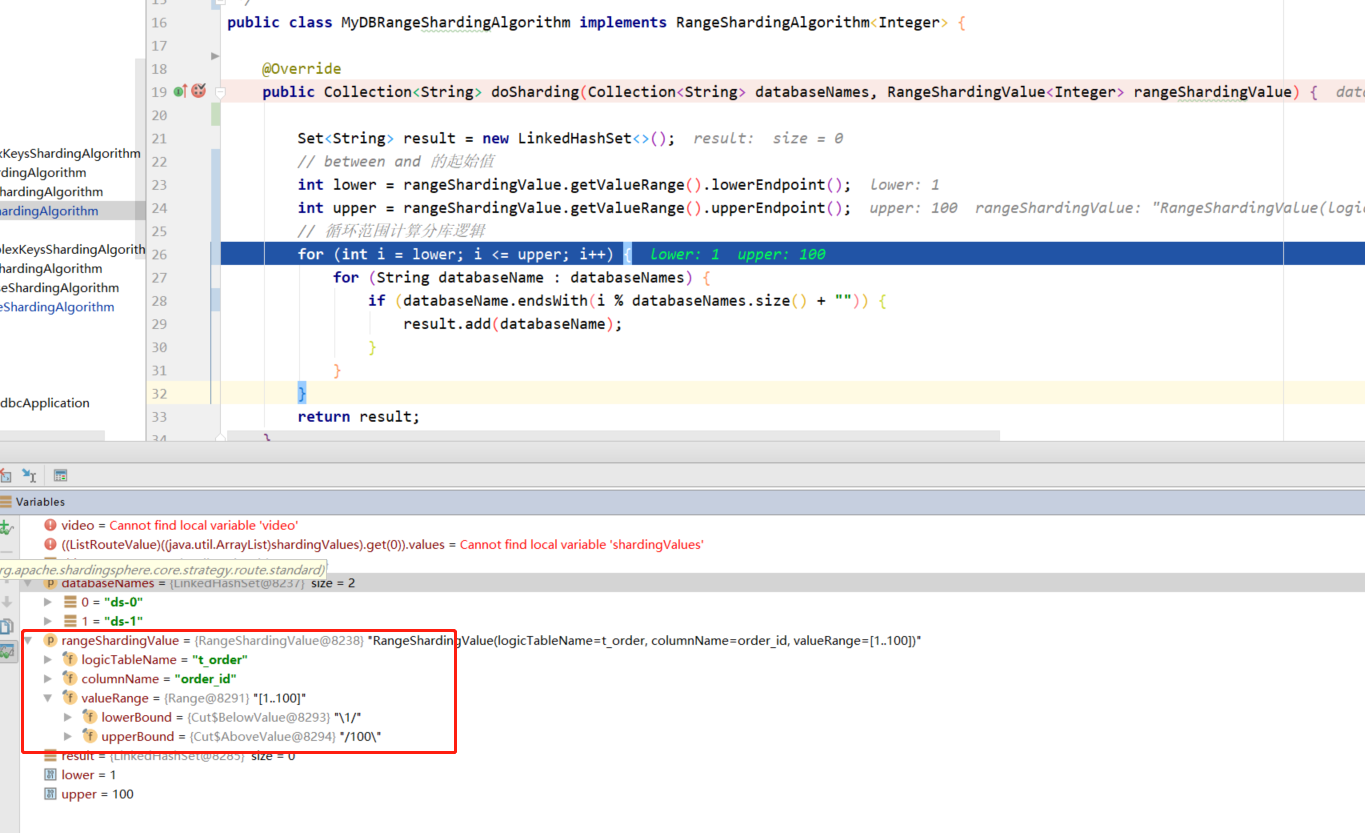
In terms of configuration, since the range slicing algorithm and precision slicing algorithm are used under the standard slicing strategy, you only need to add the range algorithm class name custom range slicing algorithm class path.
# Accurate segmentation algorithm spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBPreciseShardingAlgorithm # Range slicing algorithm spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBRangeShardingAlgorithm
Composite fragmentation strategy
Usage scenario: SQL statements have operators such as >, > =, < =, <, =, IN and BETWEEN AND. The difference is that the composite sharding strategy supports mu lt iple sharding operations.
We also implement the following order_id,user_id fields are used as partition keys to customize the composite partition strategy.
SELECT * FROM t_order where user_id =0 and order_id = 1;
Let's modify the original configuration, complex Switch sharding column to complex Sharding columns complex, with a user added to the fragment key_ ID, the partition policy name is changed to complex, complex Algorithm class name is replaced by our custom composite sharding algorithm.
### Sub database strategy # order_id,user_id is also used as the database and slice key spring.shardingsphere.sharding.tables.t_order.database-strategy.complex.sharding-column=order_id,user_id # Composite slicing algorithm spring.shardingsphere.sharding.tables.t_order.database-strategy.complex.algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBComplexKeysShardingAlgorithm
To customize the composite sharding strategy, implement the complexkeyshardingalgorithm interface and re the doSharding() method.
/**
* @author xiaofu Official account [programmer]
* @description Custom composite sub database policy
* @date 2020/10/30 13:48
*/
public class MyDBComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> databaseNames, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
// Get the corresponding value of each partition key
Collection<Integer> orderIdValues = this.getShardingValue(complexKeysShardingValue, "order_id");
Collection<Integer> userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id");
List<String> shardingSuffix = new ArrayList<>();
// The way of taking the mold of two partition keys at the same time is to divide the database
for (Integer userId : userIdValues) {
for (Integer orderId : orderIdValues) {
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : databaseNames) {
if (databaseName.endsWith(suffix)) {
shardingSuffix.add(databaseName);
}
}
}
}
return shardingSuffix;
}
private Collection<Integer> getShardingValue(ComplexKeysShardingValue<Integer> shardingValues, final String key) {
Collection<Integer> valueSet = new ArrayList<>();
Map<String, Collection<Integer>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
}
The usage of collection < string > is the same as before. Because it supports multiple partition keys, ComplexKeysShardingValue, a map with partition key as key and partition key value as value is used in the partition attribute to store the partition key attribute.
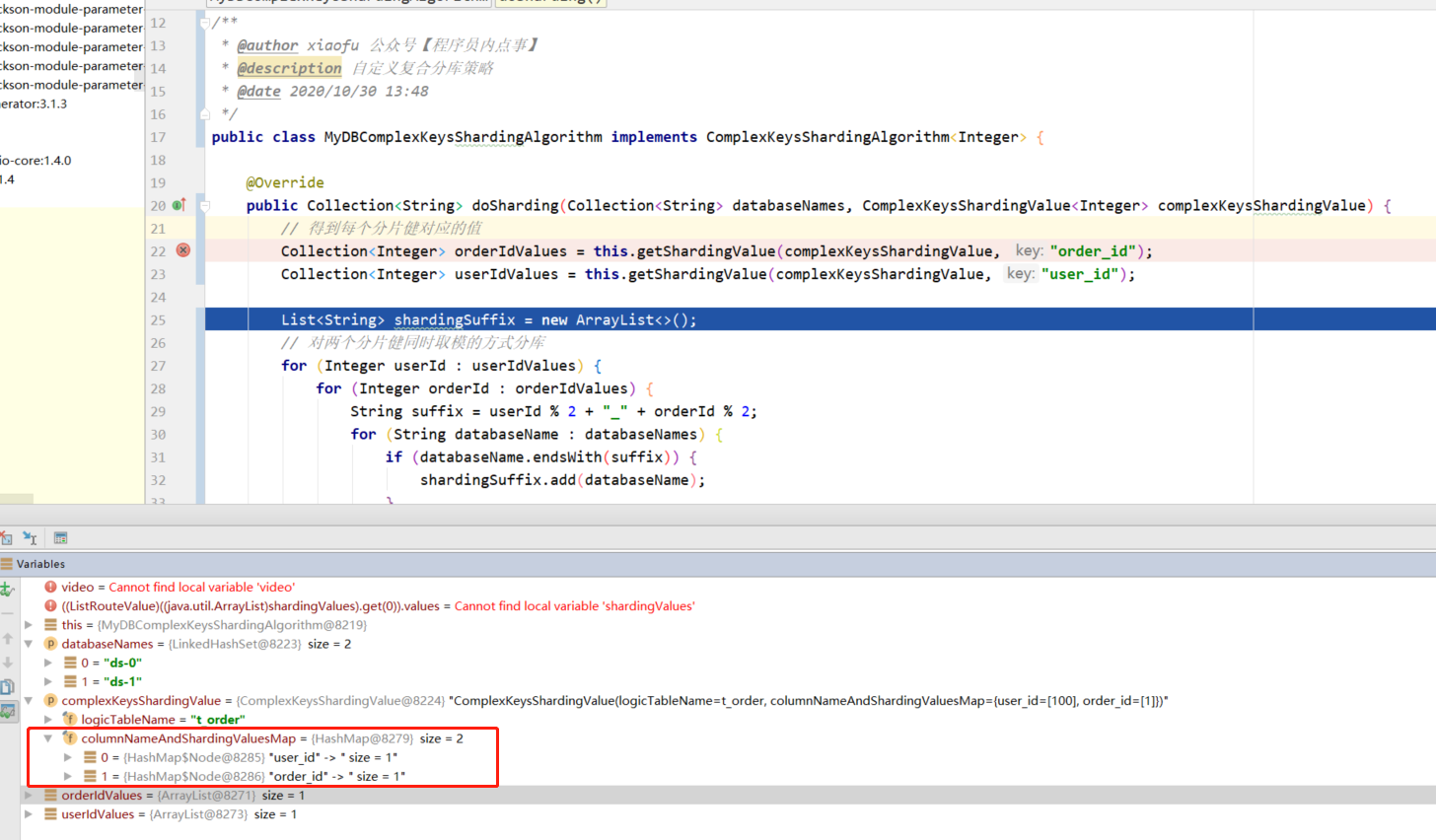
Row expression slicing strategy
The inline sharding strategy uses Groovy expressions IN the configuration and supports the sharding operations of = and IN in SQL statements. It only supports single sharding keys.
The line expression slicing strategy is suitable for making simple slicing algorithms without customizing the slicing algorithm, eliminating cumbersome code development. It is the simplest of several slicing strategies.
Its configuration is quite simple. This fragmentation strategy uses inline Algorithm expression writes an expression.
For example, DS - $- > {order_id% 2} indicates that you are satisfied with order_ ID is used to calculate the module, and $is a wildcard to undertake the module results. Finally, the sub database ds-0 ···· ds-n is calculated, which is relatively simple on the whole.
# Row expression fragment key
sharding.jdbc.config.sharding.tables.t_order.database-strategy.inline.sharding-column=order_id
# Expression algorithm
sharding.jdbc.config.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds-$->{order_id % 2}
Hint fragmentation strategy
Hint sharding strategy is slightly different from the above sharding strategies. This sharding strategy does not need to configure the sharding key, and the sharding key value is no longer parsed from SQL. Instead, the sharding information is specified externally to allow SQL to execute in the specified sub database and sub table. ShardingSphere implements the specified operation through the Hint API, which is actually changing the fragmentation rules tablerule and databaserule from centralized configuration to personalized configuration.
For example, if we want the order form t_ User for order_ ID is used as the partition key to divide the database and table, but t_ There is no user in the order table_ ID, you can manually specify the partition key or partition library externally through the Hint API.
Next, let's give an SQL without fragmentation conditions to see how to specify the fragmentation key to route it to the specified database table.
SELECT * FROM t_order;
Using the Hint sharding strategy also requires customization, implementing the HintShardingAlgorithm interface and overriding the dosharing () method.
/**
* @author xinzhifu
* @description hit Split table algorithm
* @date 2020/11/2 12:06
*/
public class MyTableHintShardingAlgorithm implements HintShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<String> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String tableName : tableNames) {
for (String shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(Long.valueOf(shardingValue) % tableNames.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
The customized algorithm is only partially implemented. You also need to specify the sub database and sub table information through HintManager before calling SQL. Since the rules added each time are placed in ThreadLocal, you should first execute clear() to clear the last rule, otherwise an error will be reported; addDatabaseShardingValue sets the key value of database segmentation, and addTableShardingValue sets the key value of table segmentation. setMasterRouteOnly read-write separation forces the reading of the master database to avoid the delay caused by master-slave replication.
// Clear the last rule, otherwise an error will be reported
HintManager.clear();
// HintManager API tool class instance
HintManager hintManager = HintManager.getInstance();
// Directly specify the corresponding specific database
hintManager.addDatabaseShardingValue("ds",0);
// Set the partition key of the table
hintManager.addTableShardingValue("t_order" , 0);
hintManager.addTableShardingValue("t_order" , 1);
hintManager.addTableShardingValue("t_order" , 2);
// In the read-write separation database, Hint can force the primary database to be read
hintManager.setMasterRouteOnly();
debug debugging shows that we are right about t_ The order table sets the key value of table segmentation, which can be successfully obtained in the HintShardingValue parameter of the user-defined algorithm.
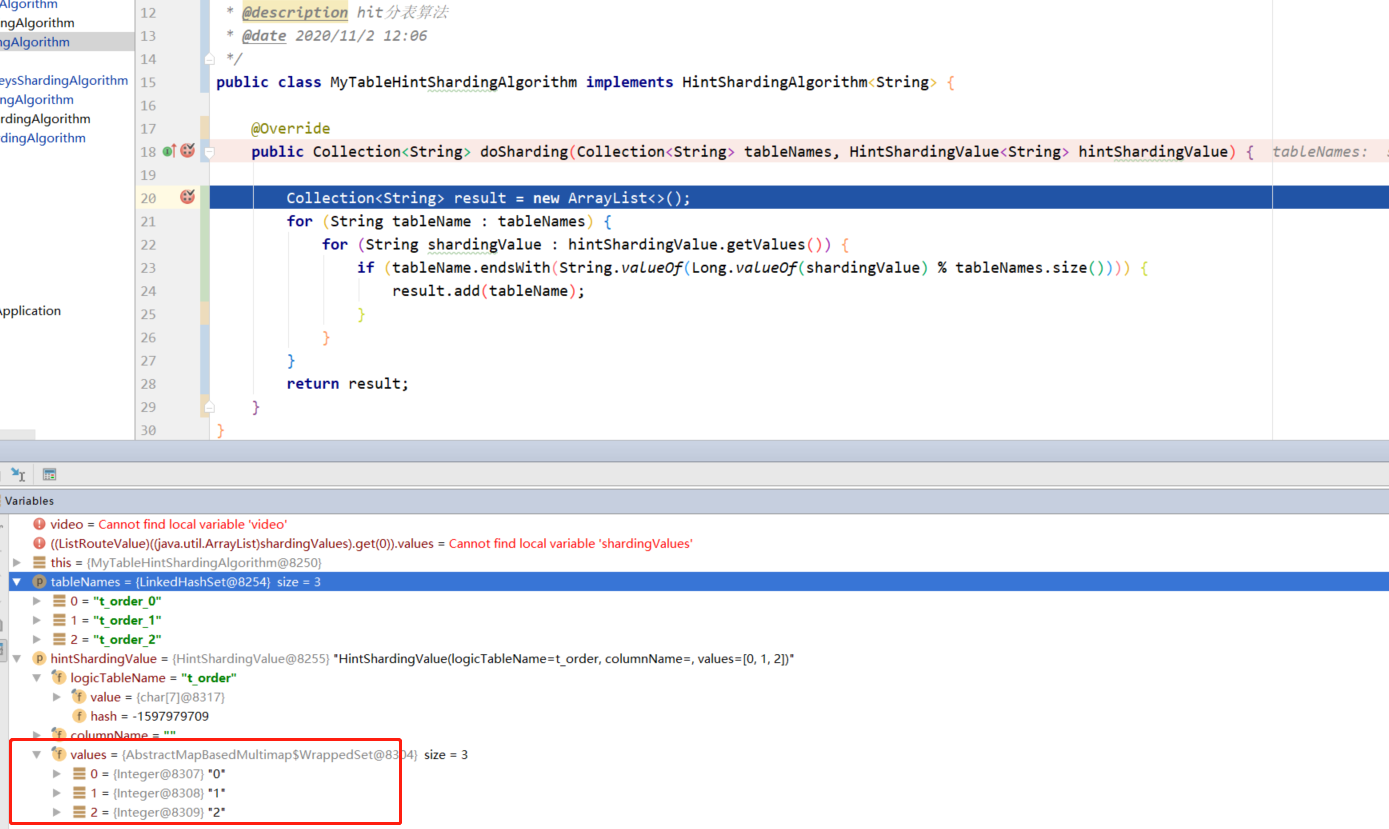
The configuration in the properties file does not need to specify the partition key, but only the custom Hint partition algorithm class path.
# Hint slicing algorithm spring.shardingsphere.sharding.tables.t_order.table-strategy.hint.algorithm-class-name=com.xiaofu.sharding.algorithm.tableAlgorithm.MyTableHintShardingAlgorithm