First, what is XML?
XML:Extensible Markup Language Extensible Markup Language
XML can separate data from HTML format.
For example, to display dynamic data in HTML, it takes time to edit various tag elements in HTML whenever the data changes.
Through the XML file, the data can be stored in a separate XML file, which can ensure that when modifying the underlying data, there is no need to make any changes to the HTML file.
External XML files can also be read through JS, and then update the data content in HTML.
Different computer systems, different applications, different clients, etc. may store information in different formats, while XML data is stored in plain text format.
So XML data can be used to share data in different environments (unlike JavaScript Object Notation).
So XML data provides a way of data storage independent of software and hardware.
2. Nodes in XML
Node object is the node in the XML file. There are many nodes in the XML file. There are three kinds of commonly used nodes: elements (tags), attributes (attributes in tags), and text (text content in start and end tags).
It should be noted that unlike HTML files, XML files do not ignore blank characters. In XML, blank characters such as spaces, tabs, newline characters are recognized. 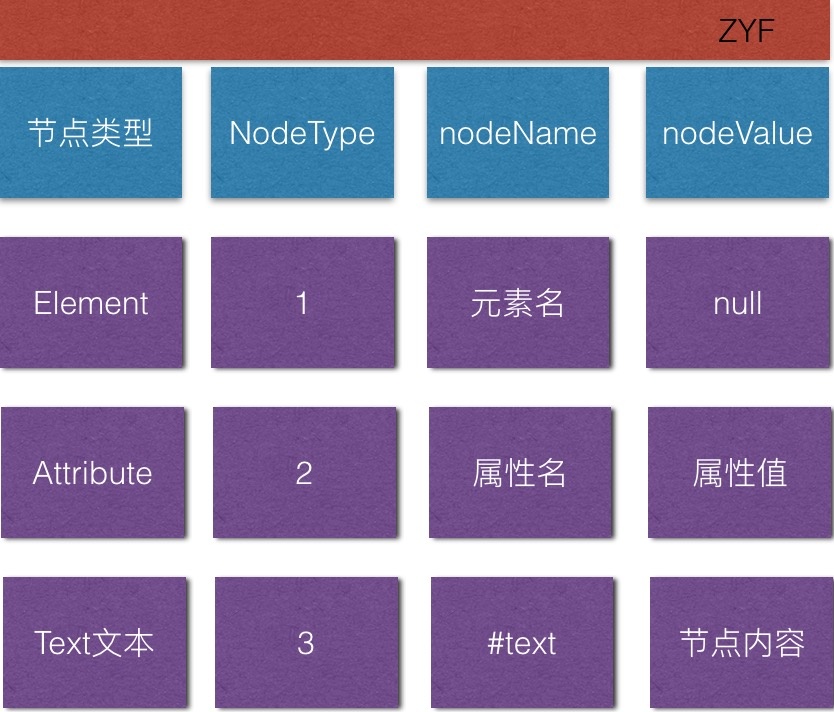
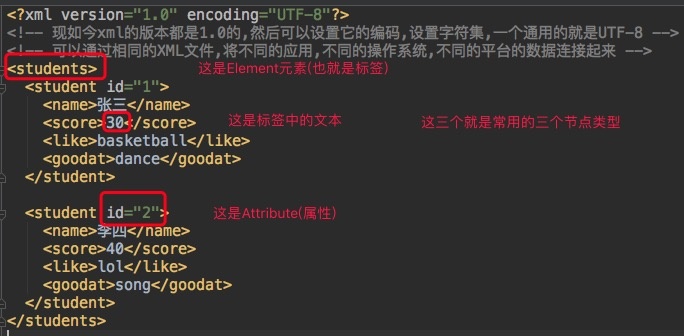
Level with src file, create a test.xml file, the contents of which are as follows.
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1">
<name>Zhang San</name>
<score>30</score>
<like>basketball</like>
<goodat>dance</goodat>
</student>
<student id="2">
<name>Li Si</name>
<score>40</score>
<like>lol</like>
<goodat>song</goodat>
</student>
</students>
3. DOM parsing
DOM parsing will load all the contents of the XML file into memory for parsing at one time. 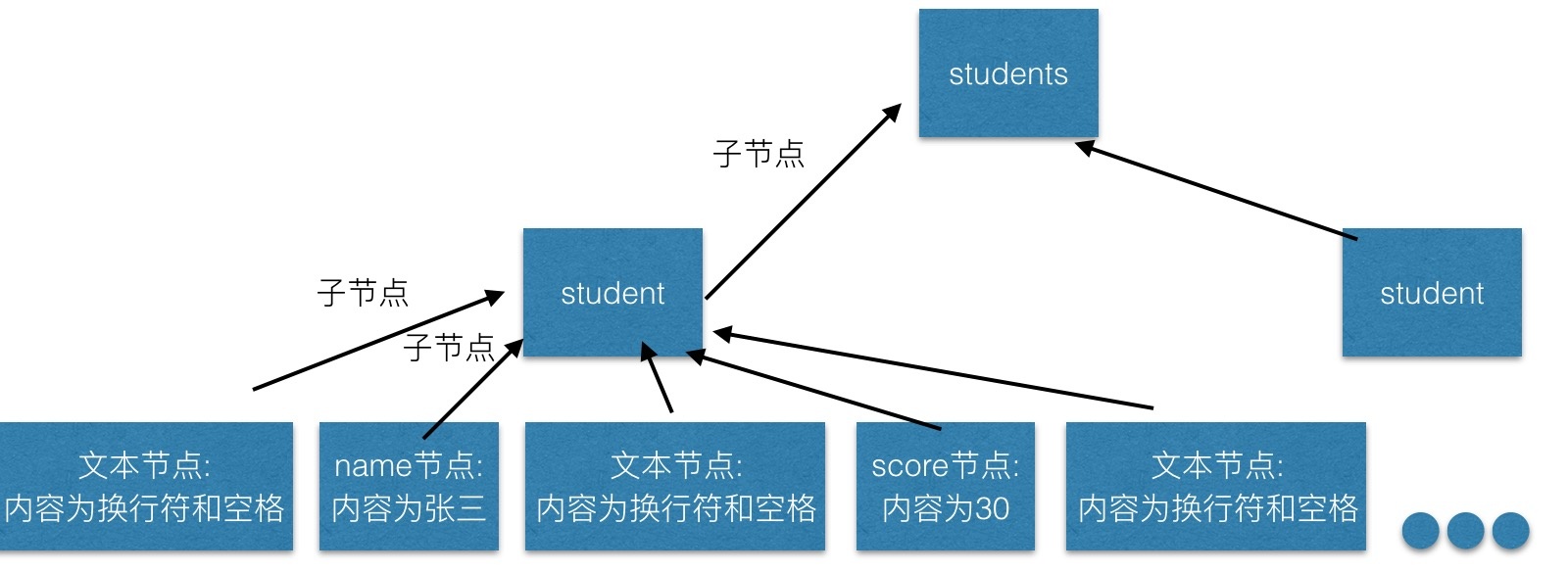
Get the data in the XML file first
//To parse the data in xml, you need to get the content first, which is equivalent to the process of network pulling.
//The first step is to create an object of DocumentBuilderFactory
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
//The second step is to create an object for DocumentBuilder
DocumentBuilder documentBuilder = dbf.newDocumentBuilder();
//The third step: (can pass in absolute path or relative path)
//Loading test by parse method.xmlFiles to the current directory(This loads the data information in the file document On the object)
//Get the document object. Note that: org.w3c Unwrapped
org.w3c.dom.Document document = documentBuilder.parse("test.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
}Get all student nodes
//Here are the steps for parsing
//The first step is to get the label by the label name (which is a collection of all student nodes)
NodeList studentList = document.getElementsByTagName("student");
//test.xmlDocumentation,There are two. student Label,Output from the set obtained here length that is2
System.out.println("Total: " + studentList.getLength());Get the properties of the student node
1. The attributes of a known node (for example, the node's attribute is known to be ID here)
for (int i = 0;i<studentList.getLength() ;i++ ) {
//Gets the element at position i in the collection
Element element = (Element)studentList.item(i);
//Get the attribute value of the element by the attribute name
String id = element.getAttribute("id");
}2. I don't know how many values a node's attributes have.
//Get the attribute name attribute value and traverse each student node
for (int i = 0; i < studentList.getLength(); i++) {
//Get a student's node information by item(i) method (the index starts from zero)
//An object of the Node class represents a node object that contains information about that node.
Node student = studentList.item(i);
//Get a collection of all attributes of the student node
NamedNodeMap attrs = student.getAttributes();
for (int j = 0; j < attrs.getLength(); j++) {
Node attr = attrs.item(j);//get attribute
System.out.printf(attr.getNodeName());//Get the property name
System.out.println(attr.getNodeValue());//Get attribute values
}
}Get the child nodes of the student node
The child nodes of the student node are: text, name element, text, score, text, like, text, goodat, text.
So there are nine child nodes in the student. Next, get the name and value of the node and print them out.
NodeList nodeList = student.getChildNodes();
System.out.println("The first"+(i + 1)+"individual student Number of child nodes of a node:"+nodeList.getLength());
//The output is found to be 9
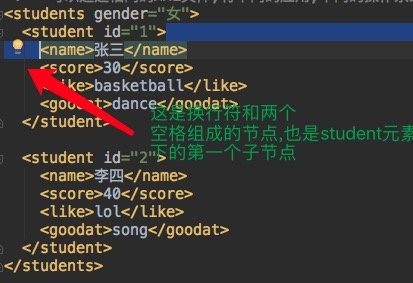
//Because there are spaces and newline characters around < name > nodes. The first and last two are two text nodes.
//Text node + name node + text node = 9
for (int j = 0; j < nodeList.getLength(); j++) {
//Get each child node object
Node node = nodeList.item(j);
//Output attributes and attribute values for each child node
System.out.println("The first"+(j+1)+"Each node is named:"+node.getNodeName()+"---The value is:"+node.getNodeValue()+"---");
//So when you can see the console output, when the property is # text, the value is a space plus a newline character
//The node name of the text is: # text
//Element Node Name: That's the element name in angle brackets
//The nodeValue value of the element is the text content between the start tag and the end tag.
}

In the same way, sub-nodes of sub-nodes can be retrieved.
Here is the complete code for DOM parsing
public class ResolveXMLDemo {
private static List<Student> data ;
public static void main(String[] args) {
blogDocumentDemo();
showData();
}
private static void showData() {
for (int i = 0; i < data.size(); i++) {
Student student = data.get(i);
System.out.println("student---id:"+student.getId()+"--name:"+student.getName());
}
}
private static void blogDocumentDemo() {
data = new ArrayList<>();
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
//The second step is to create an object for DocumentBuilder
DocumentBuilder documentBuilder = dbf.newDocumentBuilder();
//The third step: (can pass in absolute path or relative path)
//Load the test.xml file into the current directory through the parse method (so that the data information in the file is loaded onto the document object)
//Get the document object. Note that under the org.w3c package
org.w3c.dom.Document document = documentBuilder.parse("test.xml");
//Here are the steps for parsing
//The first step is to get the label by the label name (which is a collection of all student nodes)
NodeList studentList = document.getElementsByTagName("student");
//The second step is to get the attribute value of the attribute name and traverse each student node.
for (int i = 0; i < studentList.getLength(); i++) {
//Get a student's node information by item(i) method (the index starts from zero)
Node student = studentList.item(i);
Student studentEntity = new Student();
//Traversing properties in student nodes
//Get the set of all attributes of the student node first
NamedNodeMap attrs = student.getAttributes();
for (int j = 0; j < attrs.getLength(); j++) {
Node attr = attrs.item(j);//Get the j th attribute
if(attr.getNodeName().equals("id")){
studentEntity.setId(attr.getNodeValue());
}
}
//Get the contents of the child nodes of the student node
for (int j = 0; j < student.getChildNodes().getLength(); j++) {
//Get each child node object
Node node = student.getChildNodes().item(j);
//Output attributes and attribute values for each child node
String nodeName = node.getNodeName();
String nodeValue = node.getNodeValue();
switch (nodeName){
case "name":
studentEntity.setName(nodeValue);
break;
case "score":
studentEntity.setScore(nodeValue);
break;
case "like":
studentEntity.setLike(nodeValue);
break;
case "goodat":
studentEntity.setGoodAt(nodeValue);
break;
}
}
data.add(studentEntity);
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}