We usually export word through poi. POI is best at the operation of EXCEL. The style control of word operation is too cumbersome. Today we will introduce how to export word templates through FREEMARK.
[TOC]
Development preparation
- The implementation of this paper is based on springboot, so all the products used in the project are derived from springboot. First, we introduce the freemark coordinates into maven project.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-freemarker</artifactId> </dependency>
- Just import the above jar package. The premise is to inherit the springboot coordinates. You can export word through freemark.
Template preparation
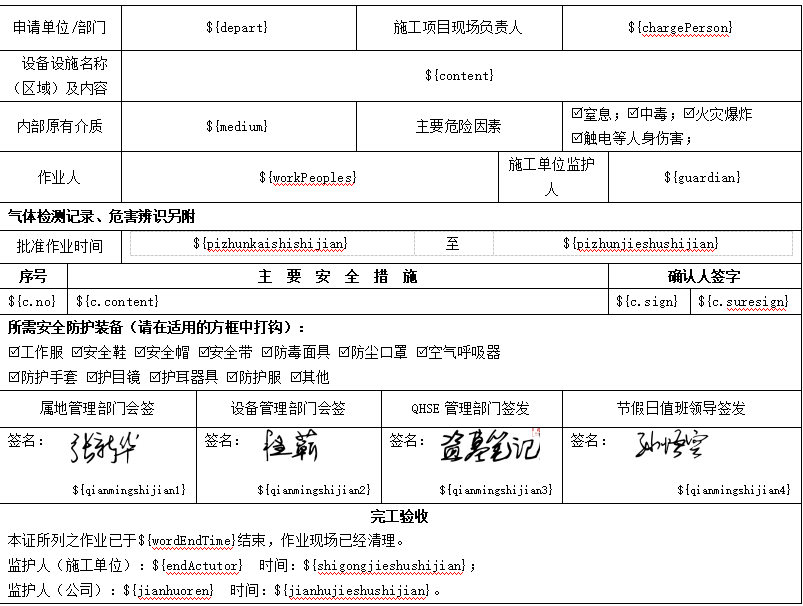
- Above is a template we exported. The rules are also simple. We just need to prepare a sample document in advance, and then use ${} to occupy the space that needs dynamic modification. We need to provide the corresponding data when exporting. Note here that ${c.no} is actually a format we use later for collection traversal. Ignore it here. We will focus on it later.
Development testing
-
At this stage, it shows that our preparatory work has been completed. We can use freemark to call and export methods.
-
First, we build the freemark load path. Just set the freemark template path. The template path stores the template we wrote above. But the template here is not strictly word. It is saved as an xml file through word.
- Configure load path
//Create configuration instance Configuration configuration = new Configuration(); //Set encoding configuration.setDefaultEncoding("UTF-8"); //ftl template file configuration.setClassForTemplateLoading(OfficeUtils.class, "/template");
- Get template class
Template template = configuration.getTemplate(templateName);
- Building output objects
Writer out = new BufferedWriter(new OutputStreamWriter(outputStream, "UTF-8"));
- Export data to out
template.process(dataMap, out);
- In the above four steps, we can implement the export. We can put the load configuration path into the global once. We have three lines of code left to finish the export. Of course, we need to do exception capture. Click me to get the source code
Result detection
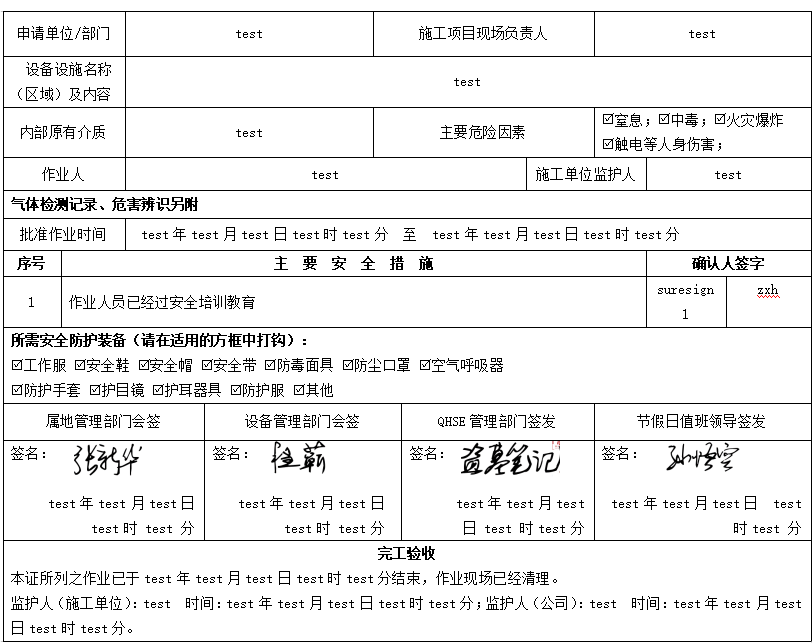
Thinking about function generalization
- We just briefly introduced the process of freemark exporting word. We didn't go into the details.
- Careful friends will find that the picture above is not set dynamically. This subfunction is definitely indescribable. Pictures we want to generate pictures of our own settings.
- Another detail is about the check box. If you look closely, you will find that the check box has no fields to control. There must be no way to check dynamically.
- Finally, we mentioned the main security measures. That's our aggregate data. We can't control through templates.
- The above problem is that our freemark word template cannot be implemented. It's a good thing to have problems. So that we can make progress. In fact, freemark exports files based on ftl format. But xml and ftl syntax are very similar, so we said above that the export template is xml. Actually we need the ftl file. If it is an ftl file, the check boxes and collections of the above problems are well solved. One through the if tag and one through the list tag. We still need to replace the pictures artificially
<#if checkbox ??&& checkbox?seq_contains('Suffocation;')?string('true','false')=='true'>0052<#else>00A3</#if> <#list c as c> dosomethings() </#list>
- The above two pieces of code are if and list syntax
Intelligent Implementation of Dom4j
- Although the above ftl solves the function problem of export. But it still can't realize intelligence. What we want to do is to automatically generate ftl files according to our word configuration through programs. After Baidu finally found the corresponding method. Dom4j is our final approach. We can do special writing in word. Then the program modifies the nodes through Dom4j. Through Dom4j, our picture problem is solved. Here are the details of the above three issues
check box

- First, we need to write in {} format before we agree on the same type of check box. Inside is the field name of the control check box.
- Then we parse the xml through dom4j. Let's take a look at the original format of checkboxes in xml
<w:sym w:font="Wingdings 2" w:char="0052"/>
- Then we only need to get the w:sym tag through dom4j. After getting the label, the corresponding text content is suffocated; this content.
- Match out the field name to control the content of if label
<#if checkbox ??&& checkbox?seq_contains('asphyxia')?string('true',false')=='true'>0052<#else>00A3</#if>
Partial source code
Element root = document.getRootElement(); List<Element> checkList = root.selectNodes("//w:sym"); List<String> nameList = new ArrayList<>(); Integer indext = 1; for (Element element : checkList) { Attribute aChar = element.attribute("char"); String checkBoxName = selectCheckBoxNameBySymElement(element.getParent()); aChar.setData(chooicedCheckBox(checkBoxName)); }
aggregate

- In the same way, we can get the tags that need to be changed. The collection is not the same as the check box. In fact, set is a format that we think is prescribed. There is no special label in word. So our agreed format is ${a_b}. First of all, we verify whether the text in word conforms to the set specification through regular traversal. Match we get the current row and add the "list" label before the row label. Then ${a_b} Change to ${a.b} as to why you didn't set the a.b format at first. I just want to say that it's the company culture. I suggest that the a.b format is the best way to implement this set of functions.
Partial source code
Element root = document.getRootElement(); //All label contents need to be obtained to judge whether they are in conformity List<Element> trList = root.selectNodes("//w:t"); //rowlist is used to process the whole row of data, because there will be multiple columns that meet the standard, and multiple columns in the same row only need to be processed once. List<Element> rowList = new ArrayList<>(); if (CollectionUtils.isEmpty(trList)) { return; } for (Element element : trList) { boolean matches = Pattern.matches(REGEX, element.getTextTrim()); if (!matches) { continue; } //That's where the set format is //Extract tableId and columnId Pattern compile = Pattern.compile(REGEX); Matcher matcher = compile.matcher(element.getTextTrim()); String tableName = ""; String colName = ""; while (matcher.find()) { tableName = matcher.group(1); colName = matcher.group(2); } //At this time, what we get is the content in w:t. what we really need to loop is the w:tr where w:t is. At this time, we need to get the current w:tr List<Element> ancestorTrList = element.selectNodes("ancestor::w:tr[1]"); /*List<Element> tableList = element.selectNodes("ancestor::w:tbl[1]"); System.out.println(tableList);*/ Element ancestorTr = null; if (!ancestorTrList.isEmpty()) { ancestorTr = ancestorTrList.get(0); //Get header information Element titleAncestorTr = DomUtils.getInstance().selectPreElement(ancestorTr); if (!rowList.contains(ancestorTr)) { rowList.add(ancestorTr); List<Element> foreachList = ancestorTr.getParent().elements(); if (!foreachList.isEmpty()) { Integer ino = 0; Element foreach = null; for (Element elemento : foreachList) { if (ancestorTr.equals(elemento)) { //At this time, the ancestor TR is the row to be traversed, because we need to expand the label to the cyclic label pool foreach = DocumentHelper.createElement("#list"); foreach.addAttribute("name", tableName+" as "+tableName); Element copy = ancestorTr.createCopy(); replaceLineWithPointForeach(copy); mergeCellBaseOnTableNameMap(titleAncestorTr,copy,tableName); foreach.add(copy); break; } ino++; } if (foreach != null) { foreachList.set(ino, foreach); } } } else { continue; } } }
picture

- The picture is similar to the check box. Because in the xml of word, it is processed by special tags. But our placeholders can't be occupied by the above placeholders. A real picture is needed to occupy the space. Because only a picture word has a picture label. We can use @ {imgField} to occupy the space after the picture. Then the base64 bytecode of the picture is occupied by ${imgField} through dom4j.
Partial source code
//Picture index table below Integer index = 1; //Get root path Element root = document.getRootElement(); //Get picture labels List<Element> imgTagList = root.selectNodes("//w:binData"); for (Element element : imgTagList) { element.setText(String.format("${img%s}",index++)); //Get the wp label of the current picture List<Element> wpList = element.selectNodes("ancestor::w:p"); if (CollectionUtils.isEmpty(wpList)) { throw new DomException("Unknown exception"); } Element imgWpElement = wpList.get(0); while (imgWpElement != null) { try { imgWpElement = DomUtils.getInstance().selectNextElement(imgWpElement); } catch (DomException de) { break; } //Get corresponding picture field List<Element> imgFiledList = imgWpElement.selectNodes("w:r/w:t"); if (CollectionUtils.isEmpty(imgFiledList)) { continue; } String imgFiled = getImgFiledTrimStr(imgFiledList); Pattern compile = Pattern.compile(REGEX); Matcher matcher = compile.matcher(imgFiled); String imgFiledStr = ""; while (matcher.find()) { imgFiledStr = matcher.group(1); boolean remove = imgWpElement.getParent().elements().remove(imgWpElement); System.out.println(remove); } if (StringUtils.isNotEmpty(imgFiledStr)) { element.setText(String.format("${%s}",imgFiledStr)); break; } } }
Automatic export based on word (including source code)
- The above is our export process. Through the above logic, we can finally reuse a set of code. Source download address: https://gitee.com/zxhTom/office-multip.git
Refer to Internet articles
dom operation xml dom generates xml httpclient get reaction flow Get jar path itext implementation of template printing ftl common syntax freemark official website ftl judgment is not empty freemark custom function freemark custom function java Escape of freemark special characters java implementation of various formats from word to xml
#< span id = "addme" > join the team</span>
WeChat official account
