Map interface description (double column set)
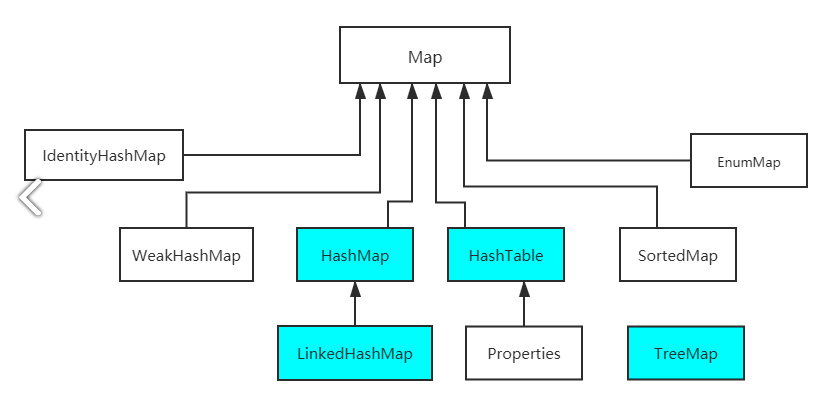
JavaApi gives a partial overview of the Map interface
An object that maps keys to values. A mapping cannot contain duplicate keys; Each key can be mapped to at most one value.
The Map interface provides three collection views that allow you to view the contents of a Map in the form of key set, value set or key value mapping relationship set. The mapping order is defined as the order in which the iterator returns its elements on the mapped collection view. Some mapping implementations can explicitly guarantee their order, such as TreeMap class; For example, some HashMap classes do not implement HashMap in order.
The complete interface definition is:
public interface Map<K,V>
Many interfaces define some unimplemented methods. Before jdk8, interfaces cannot write implementation methods, but later versions can be implemented. And some methods that are not implemented are defined for later implementation classes.
Usually, the interface defines some methods.
After jdk8, the default modifier is used, so that the interface can implement methods.
The Map set is a two column set, which is of course relative to the Collection. The remarkable feature is that the Collection is single column and can only store values directly. There can be keys and values on the Map Collection
The API specifies the relationship between the key and value. According to the mapping, it is actually a single shot relationship.
The basic methods provided are as follows
The Map interface mainly provides methods
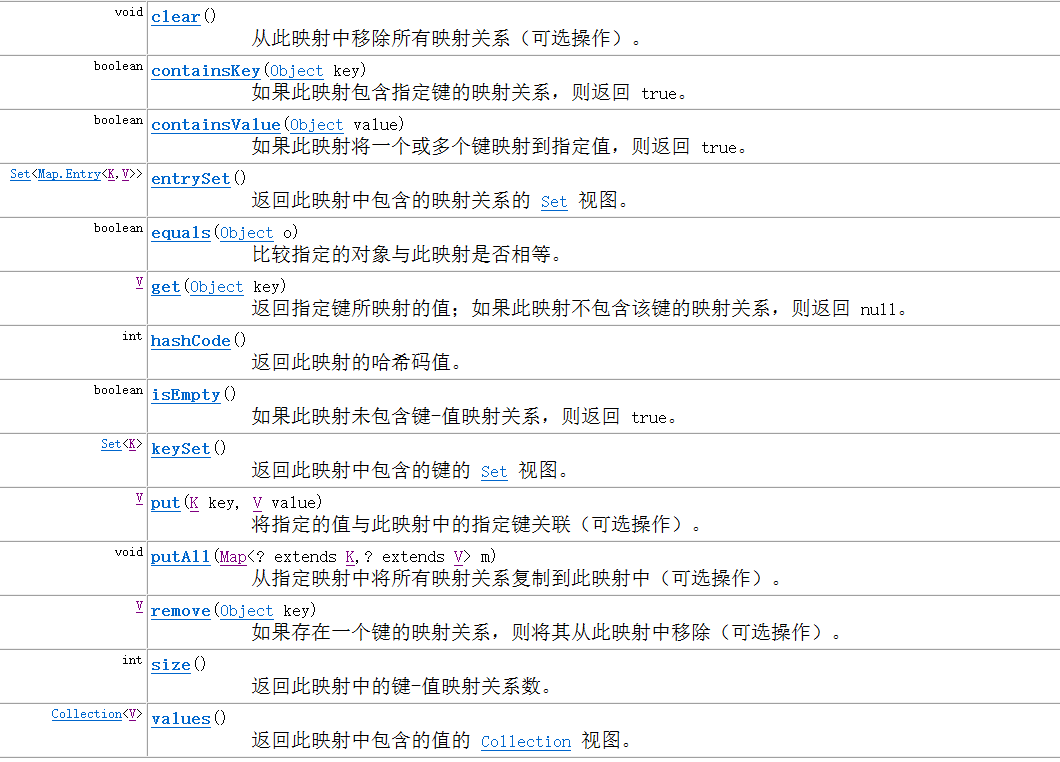
Explain the entrySet() method
The first thing you need to know is that Entry is an internal class in Map. You can find it by looking at the Map source code.
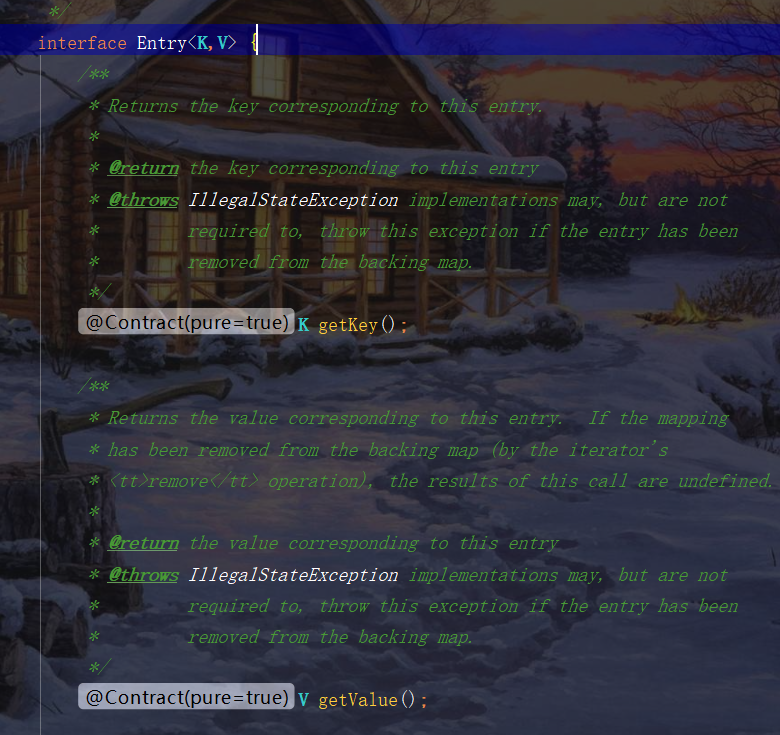
You can see that it is actually mapped to key and value. So in fact, you can think of map There are getKey() and getValue () methods in the entry.
Use of entrySet
Take a look at the entrySet() method in the Map. The information we get is as follows:
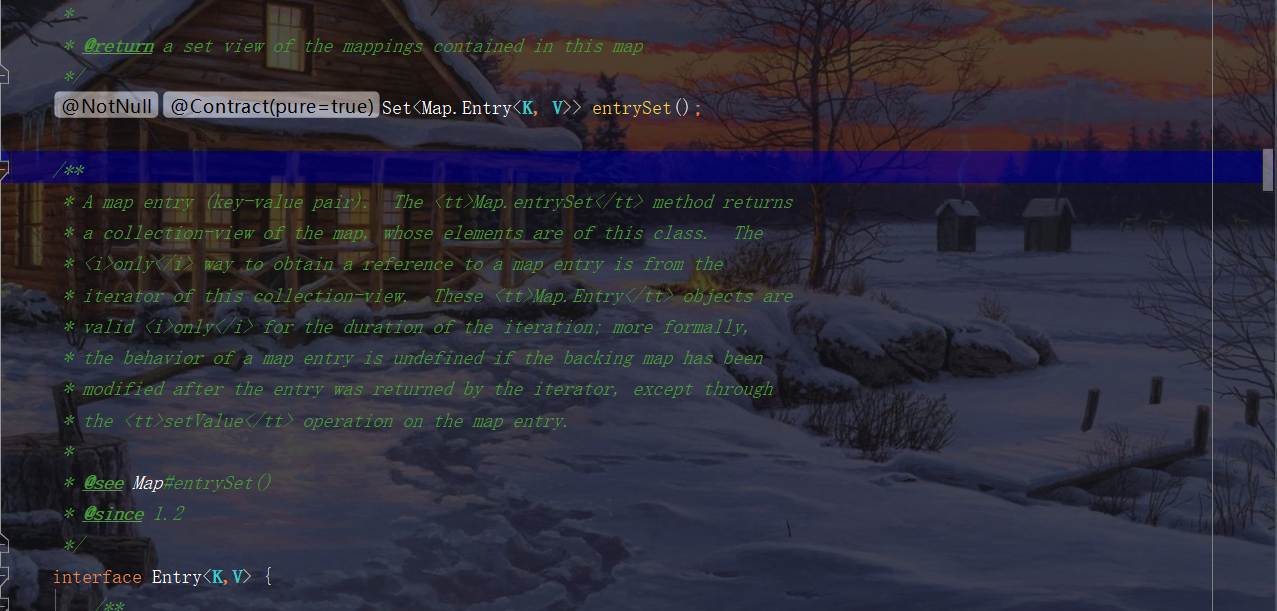
It shows that the entrySet is of course composed of key values, and the type of package inside is map Entry.
At the same time, we can conclude that entrySet implements the Set interface.
Since the entrySet contains map Entry type, and entry provides a method to get the key value. In fact, we can use entrySet to traverse the map.
We can do this (demonstrate how to use it)
package java_practice;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Map_demo {
public static void main(String args[])
{
Map<String, String> map = new HashMap<String,String>();
map.put("Hello","world");
map.put("let","go");
map.put("all","right");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while(it.hasNext())
{
// System.out.println(it.next());
Map.Entry<String, String> entry = it.next();
System.out.println(entry.getKey()+entry.getValue());
}
}
}
Implement traversal map set
The first is to iterate with the iterator. In addition, we can also use the enhanced for loop
package java_practice;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Map_demo {
public static void main(String args[]) {
Map<String, String> map = new HashMap<String, String>();
map.put("Hello", "world");
map.put("let", "go");
map.put("all", "right");
// Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
// while(it.hasNext())
// {
// // System.out.println(it.next());
// Map.Entry<String, String> entry = it.next();
// System.out.println(entry.getKey()+entry.getValue());
// }
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey() + entry.getValue());
}
}
}
Another way is to get the key through keyset(), and then use map Get () gets the value corresponding to the key, which is very simple and convenient.
package java_practice;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Map_demo {
public static void main(String args[]) {
Map<String, String> map = new HashMap<String, String>();
map.put("Hello", "world");
map.put("let", "go");
map.put("all", "right");
// Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
// while(it.hasNext())
// {
// // System.out.println(it.next());
// Map.Entry<String, String> entry = it.next();
// System.out.println(entry.getKey()+entry.getValue());
// }
// Set<Map.Entry<String, String>> entries = map.entrySet();
// for (Map.Entry<String, String> entry : entries) {
// System.out.println(entry.getKey() + entry.getValue());
// }
for(String key:map.keySet())
{
System.out.println(key+map.get(key));
}
}
}
Of course, you can also go directly to map Values() to traverse the values
Implementation class HashMap
explain
The parts of Java API are as follows
Implementation of Map interface based on hash table. This implementation provides all optional mapping operations and allows the use of null values and null keys. (the HashMap class is roughly the same as Hashtable except that it is asynchronous and null is allowed.) This class does not guarantee the order of the mapping, in particular, it does not guarantee that the order is constant
Thread synchronization is also described above
Note that this implementation is not synchronous. If multiple threads access a hash map at the same time, and at least one of them structurally modifies the map, it must maintain external synchronization.
HashMap is an implementation class. Let's see its complete definition
public class HashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable
data structure
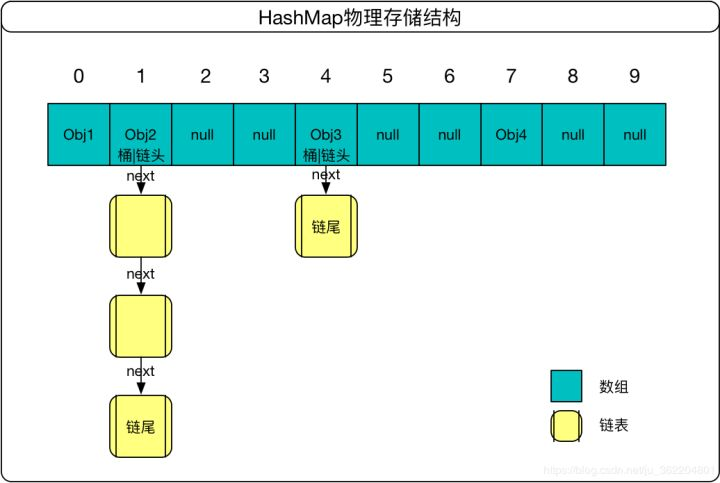
The underlying data structure of HashMap is array plus linked list, which can also be regarded as a list hash.
This data structure determines some characteristics of HashMap
For example, the speed of obtaining and adding key values is relatively fast, that is, it is convenient to store and find. The description of hash has been partially summarized in the Collection collection, so I won't repeat it.
At the same time, HashMap is an unordered hash table, that is, it does not record the insertion order. Briefly demonstrate the instructions.
package java_practice;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Map_demo {
public static void main(String args[]) {
// Map<String, String> map = new HashMap<String, String>();
// map.put("Hello", "world");
// map.put("let", "go");
// map.put("all", "right");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while(it.hasNext())
{
// System.out.println(it.next());
Map.Entry<String, String> entry = it.next();
System.out.println(entry.getKey()+entry.getValue());
}
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey() + entry.getValue());
}
// for(String key:map.keySet())
// {
// System.out.println(key+map.get(key));
// }
HashMap<String, String> hm = new HashMap<String,String>();
hm.put("Hello","world");
hm.put("blos","jgdabc");
hm.put("java","javase");
System.out.println(hm);
}
}

You can see that it will not record the order of your insertion.
The same traversal method will not be repeated. Same as above.
I couldn't help looking at a little source code
From the keySet method alone, we can find that the key of HashMap is Set type, and one feature of Set type is that duplication is not allowed.
Therefore, duplicate keys are not allowed.
These are the main methods. entrySet() has been described in map. HashMap implements all the methods of map. Of course, you can also use entrySet to traverse.
Therefore, the corresponding Key class must override the hashCode and equals methods.
Implementation class Hashtable
Description (comparison of some differences between HashMap and Hashtable)
Complete class definition
// An highlighted block public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, Serializable
Excerpt api section
This class implements a hash table that maps keys to corresponding values. Any non null object can be used as a key or value.
In order to successfully store and retrieve objects in the hash table, the objects used as keys must implement the hashCode method and the equals method.
Implementation of data structure
It is also composed of array and linked list, which is the same as HashMap.
Then it must be similar to HashMap in some features. It is also convenient to add, delete, modify and check.
Of course, there are some differences compared with HashMap. For example, on the issue of thread synchronization. HashMap is not secure because the put(), get() methods it provides are not protected at all. In the case of multiple threads, data inconsistency is easy to occur. Well understood. But Hashtable is different. Its threads are synchronized and locked on reading and writing.
In addition, HashMap is allowed to store null values, but Hashtable is absolutely not allowed to do so.
Look at the source code
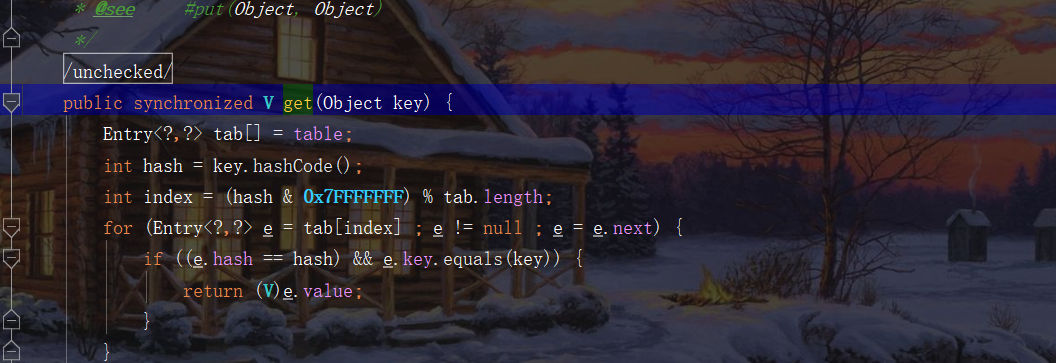
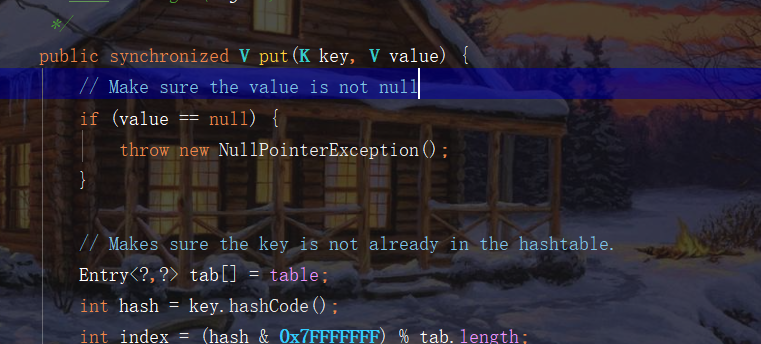
You can see that both put and set are locked.

In addition, there are differences in concurrent modification exceptions. The iterator of hashtable will also have concurrent modification exceptions. The concurrent modification exceptions have been described in detail in the introduction Collection collection. In fact, this mechanism is also called fail fast mechanism, which is an error mechanism in the set. HashMap will appear because its iterator is such an iterator. This exception also occurs in hashtables that appear to be locked and secure.
Concurrent modification exception of HashMap
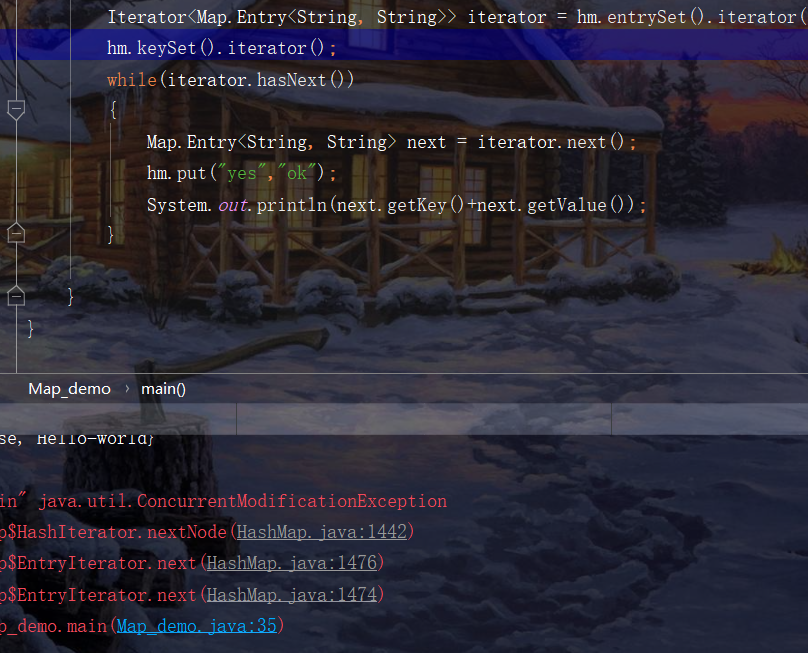
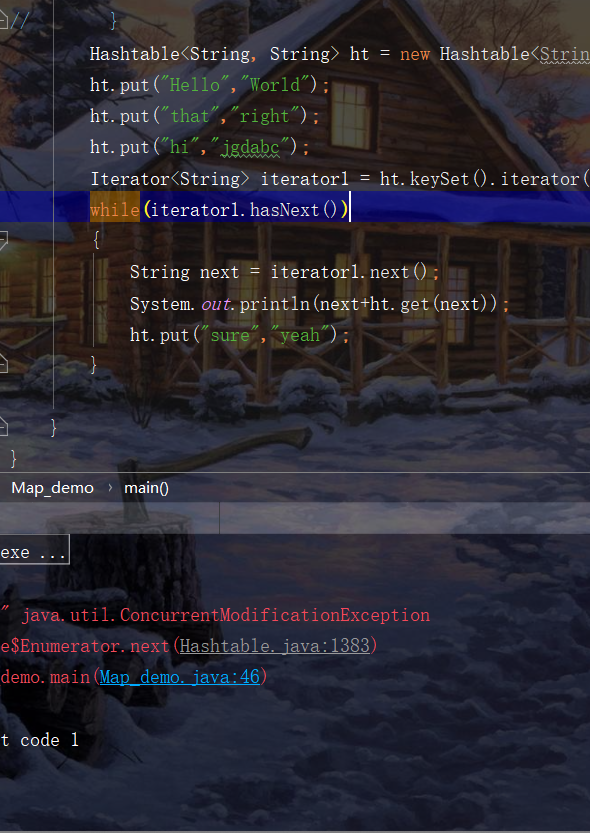
There is usually a problem about hash collision
Hash collision is that two different values may get the same hash value after hash calculation, which may lead to the conflict of data location in the array. This is called collision.
Hashtable uses linked list to solve this conflict, which is called separated link method. HashMap will hang a linked list where there is a conflict. If the linked list is too long, it will be converted into a red black tree. Red black trees reduce time complexity. This article does not explain the red and black trees in detail.
The inheritance classes of Hashtable and HashMap are different.
AbstractMap abstract class inherited by HashMap and Dictionay abstract class inherited by Hashtable
The hash table expansion algorithm is different: the capacity expansion of HashMap is based on the original capacity of 2, while the capacity expansion of Hashtable is based on the original capacity of 2 + 1
The default value of capacity is different: the default value of HashMap is 16, while the default value of Hashtable is 11
In the put method, HashMap inserts the node into the tail of the linked list, while Hashtable inserts the node into the head of the linked list
At the same time, considering the principle of the bottom layer, HashMap adopts array + linked list + red black tree, while Hashtable adopts array + linked list. The introduction of red black tree is related to the version.
This play can be obtained by analyzing the source code. If you have energy, you will continue to refine it later.
Do you want to solve the Hashtable table? Here is a reference article
Analytic text
Implementation class LinkedHashMap
explain
Complete definition of Java API
public class LinkedHashMap<K,V>extends HashMap<K,V>implements Map<K,V>
##Explain
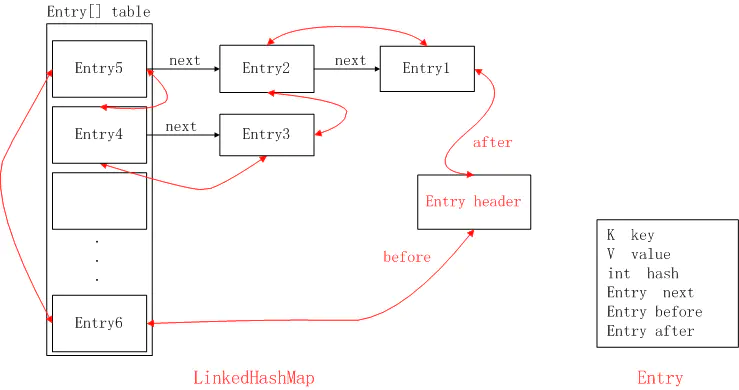
The implementation of hash table and link list of Map interface has predictable iterative order. This implementation differs from HashMap in that it maintains a double linked list that runs on all entries. This linked list defines the iterative order, which is usually the order in which keys are inserted into the Map (insertion order). Note that if you reinsert keys in the Map, the insertion order is not affected. (if m.containsKey(k) returns true before calling m.put(k, v), the key K will be reinserted into Map m during the call.)
This implementation allows customers to avoid unspecified, usually messy sorting provided by HashMap (and Hashtable), without increasing the cost associated with TreeMap. Using it, you can generate a copy of the mapping in the same order as the original mapping, regardless of the implementation of the original mapping:
In addition, it also explains the operation of thread synchronization and concurrency
Note that this implementation is not synchronous. If multiple threads access the linked hash map at the same time, and at least one thread has structurally modified the map, it must maintain external synchronization. This is generally accomplished by synchronizing the objects that naturally encapsulate the mapping. If such an object does not exist, you should use collections The synchronizedmap method to "wrap" the map. It is best to do this at creation time to prevent accidental asynchronous access to the mapping:
Map m = Collections.synchronizedMap(new LinkedHashMap(…)); Structure modification refers to the addition or deletion of one or more mapping relationships, or any operation that affects the iterative order in the hash mapping linked by access order. In a hash map linked in insertion order, changing only the value associated with the key already contained in the map is not a structural modification. In the hash mapping linked by access order, only get query mapping is used, not structure modification.)
The iterators returned by the iterator method of collection (returned by all collection view methods of this class) are fast failures: after the iterator is created, if the mapping is structurally modified, the iterator will throw a ConcurrentModificationException at any time and in any way except through the remove method of the iterator itself. Therefore, in the face of concurrent modifications, the iterator will soon fail completely without risking any uncertain behavior at an uncertain time in the future.
LinkedHashMap inherits from HashMap and has the characteristics of HashMap in many aspects. In fact, it has all the open functions of HashMap. On the source code before and after 1.8, the underlying source code of LinkedHashMap is very different.
Data structure characteristics
In terms of data structure, LinkedHashMap adopts the structure of two-way linked list, which is above key and value. Make it orderly. The iterative order of map is maintained.
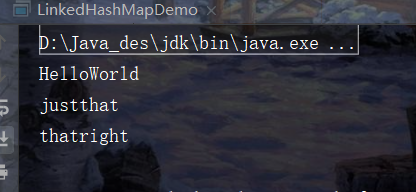
package java_practice;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapDemo {
public static void main(String args[]) {
LinkedHashMap<String, String> lhm = new LinkedHashMap<>();
lhm.put("Hello", "World");
lhm.put("just", "that");
lhm.put("that", "right");
Iterator<Map.Entry<String, String>> iterator = lhm.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey() + next.getValue());
}
}
}
Now this structure is not recommended.

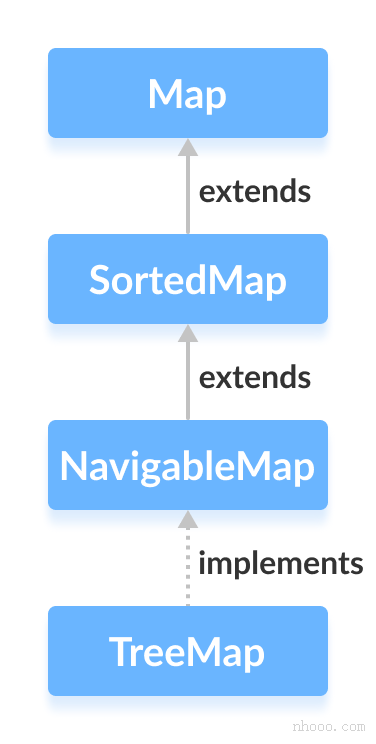
Implementation class TreeMap
explain
The complete class is defined as follows
public class TreeMap<K,V>extends AbstractMap<K,V>implements NavigableMap<K,V>, Cloneable, Serializable
Implementation of NavigableMap based on red black tree. The map is sorted according to the natural order of its keys, or according to the Comparator provided when creating the map, depending on the construction method used.
On thread synchronization
Note that this implementation is not synchronous. If multiple threads access a map at the same time and at least one of them structurally modifies the map, it must be externally synchronized. (structural modification refers to the operation of adding or deleting one or more mapping relationships; changing only the values associated with existing keys is not structural modification.) This is generally done by performing synchronization operations on the objects that naturally encapsulate the mapping. If such an object does not exist, you should use collections The synchronizedsortedmap method to "wrap" the map.
Same concurrency exception
Note that the fast failure behavior of iterators cannot be guaranteed. Generally speaking, when there are asynchronous concurrent modifications, it is impossible to make any positive guarantee. The fast failure iterator does its best to throw a ConcurrentModificationException. Therefore, it is wrong to write a program that depends on this exception. The correct way is that the fast failure behavior of the iterator should only be used to detect bug s.
Underlying data structure
TreeMap is a tree structure that uses red black tree to store data. Red black tree is a binary search tree with some characteristics. It is also explained in the JAVAAPI that TreeMap has the function of sorting. Similarly, it can be found in the inheritance and implementation relationship that it implements the SortedMap interface, so it will sort the elements in the Map according to the Key size. The default is natural sorting, which is very similar to the TreeSet of a single column set.
Reference articles for understanding the underlying data structure and red black tree
Data structure: the underlying implementation of TreeMap - red black tree (I)
It is also asynchronous. If you want to synchronize, you can synchronize manually. The Java API is clear. The method used is SortedMap M = collections synchronizedSortedMap(new TreeMap(…));
**It's actually locked**
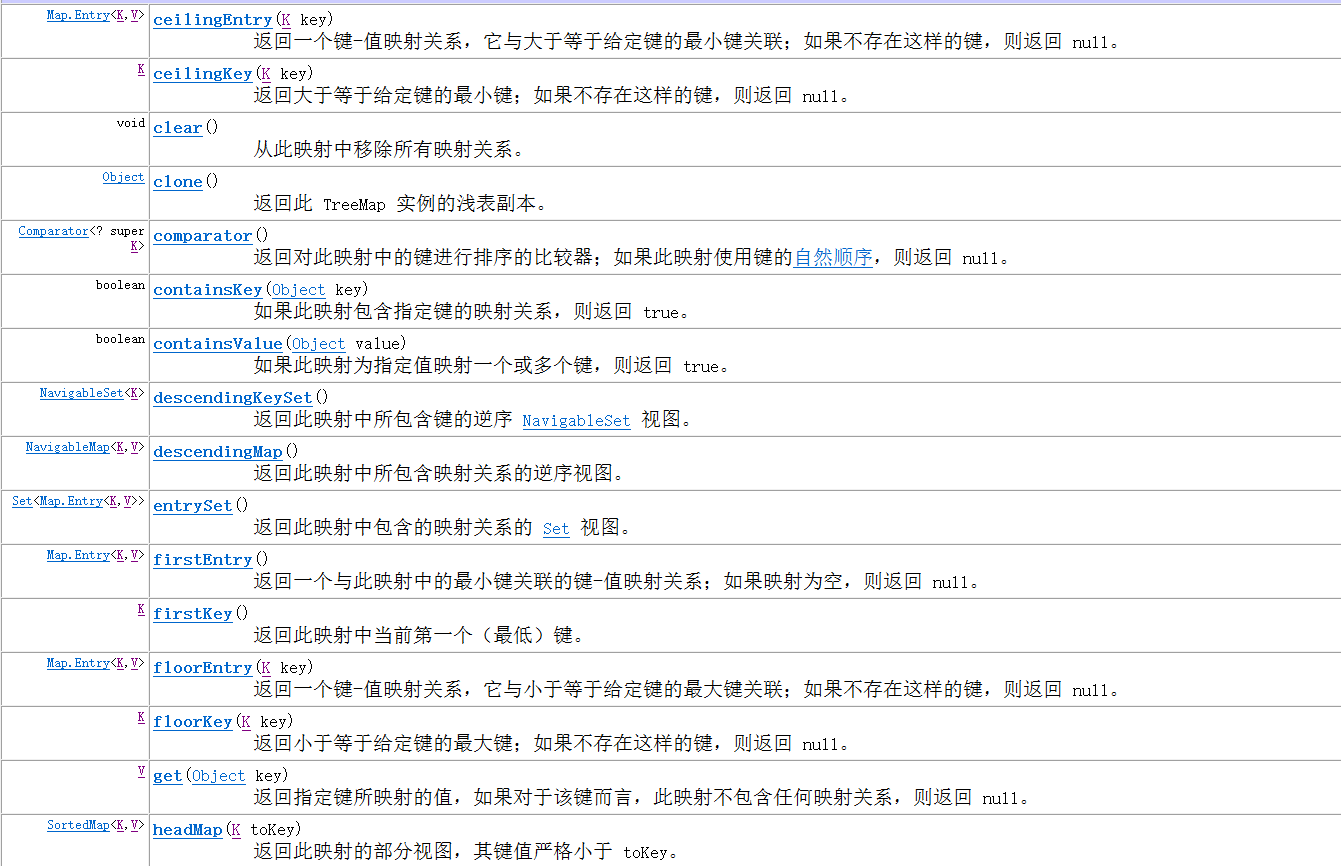
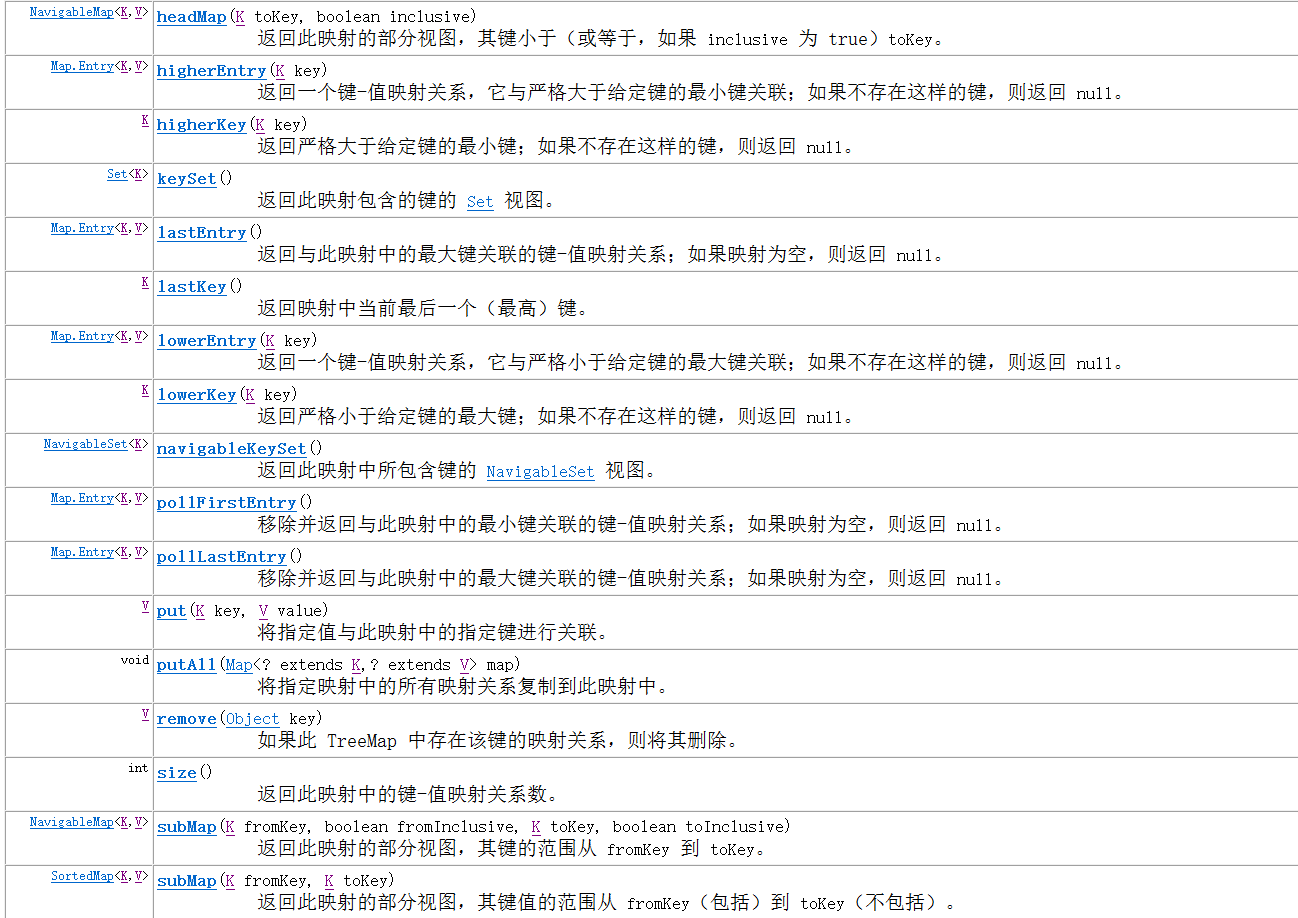

There are still many methods.
Briefly explain the method you have never seen before
putIfAbsent() - if the specified key does not exist in the map, insert the specified key / value map into the map
Similarly, you can also use the methods commonly used in the previous iteration
entrySet() - returns the collection of all key / value mappings (entries) of TreeMap (the method here is the same as the above)
keySet() - returns the collection of all keys of TreeMap (obtained keys)
values() - returns the collection of all the graphs of the TreeMap (obtained values)
JDK API also has some description methods, which are clearly described below
HigherKey() - returns the smallest of those keys larger than the specified key.
HigherEntry() - returns an entry related to the smallest of all keys larger than the specified key.
lowerKey() - returns the maximum number of keys smaller than the specified key.
lowerEntry() - returns the entry associated with the largest of all keys smaller than the specified key.
ceilingKey() - returns the smallest of those keys larger than the specified key. Pass the key as an argument in the mapping, if it exists.
ceilingEntry() - returns an entry related to the smallest of those keys larger than the specified key. If there is an entry associated with the key passed to the argument in the mapping, the entry associated with the key is returned.
floorKey() - returns the largest of those keys smaller than the specified key. If there is a key passed as an argument, it returns it.
floorEntry() - returns an entry related to the largest of those keys smaller than the specified key. If there is a key passed as an argument, it returns it
pollFirstEntry() - returns and deletes the entry associated with the first key of the map
pollLastEntry() - returns and deletes the entry associated with the last key of the map
For specific applications, you can directly find the api.
Since it is a tree, tree, its sorting method is often used. This is similar to the default natural sorting of previous articles with single column sets.
The sorting method defined by yourself is also introduced in the description of single column set. Let's explain it again.
So I made a self sorting of sb (generics can't be passed casually.)
I wrote such a program. Simply compare yourself to sort, which realizes self sorting. After writing part of the following, I found that the above can no longer be new.
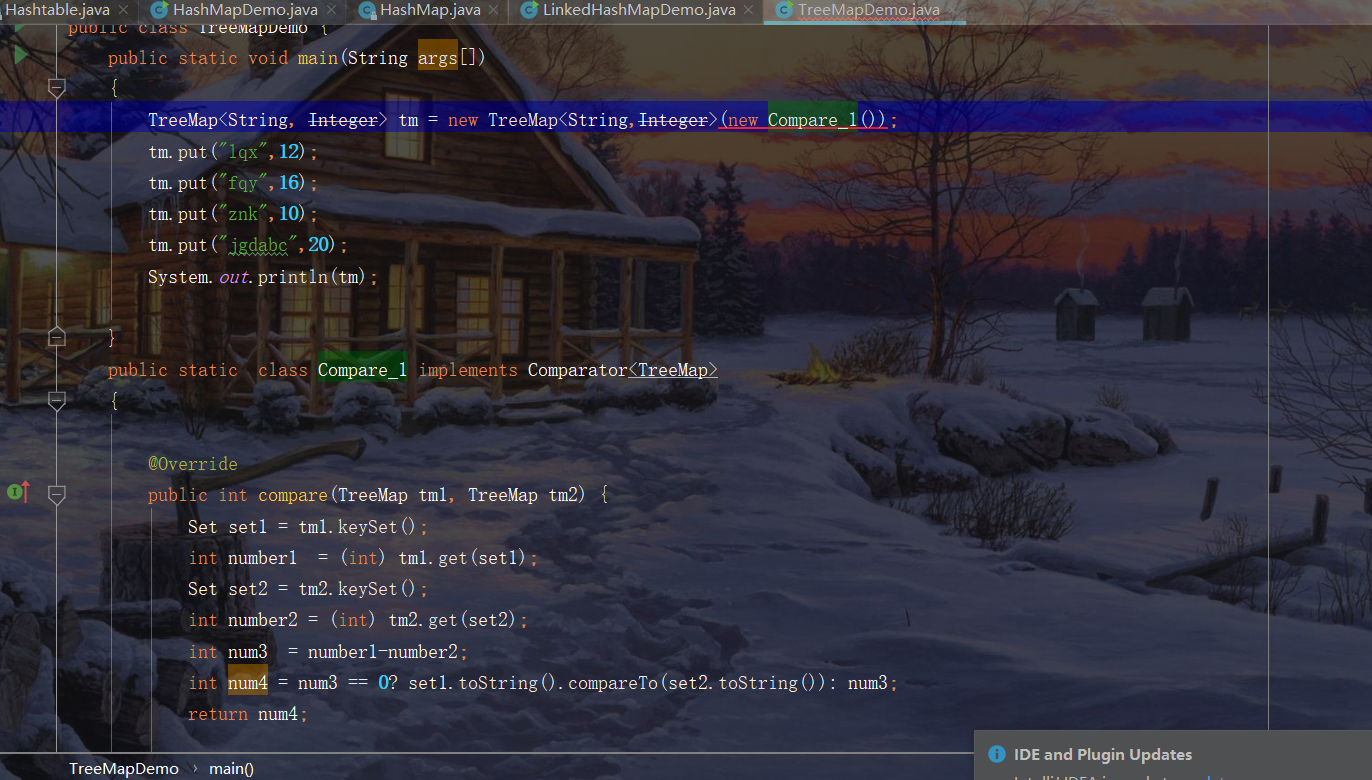
I may be lazy. I didn't look at the source code carefully this time. Later, a big man proposed a solution for me
Why is that?
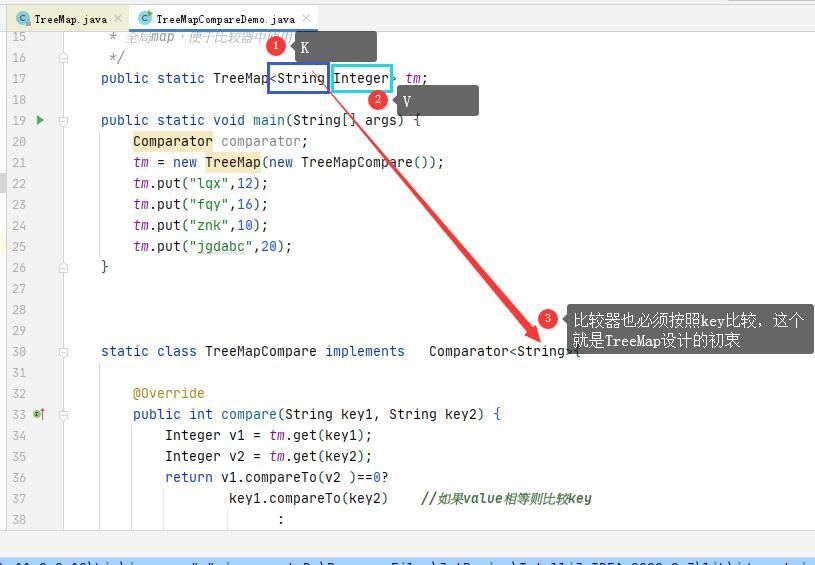
It can only be String! I also define its generic Key as the TreeMap type. ok I'm still too good.
How to customize, if the key is the same, and then sort by value, is actually very simple, which is the solution given by the boss, but it is actually wrong. Big guys are not big guys.
His solution is like this
package java_practice;
import java.util.Collection;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapDemo {
public static TreeMap<String,Integer> tm;
public static void main(String[] args) {
//Comparator comparator;
tm = new TreeMap(new TreeMapCompare());
tm.put("lqx",12);
tm.put("fqy",16);
tm.put("znk",10);
tm.put("jgdabc",20);
}
public static class TreeMapCompare implements Comparator<String>{
@Override
public int compare(String key1, String key2) {
Integer v1 = tm.get(key1);
Integer v2 = tm.get(key2);
return v1.compareTo(v2 )==0?
key1.compareTo(key2) //If value s are equal, compare key s
:
v1.compareTo(v2 ); //If the values are not equal, compare according to the value
}
}
}
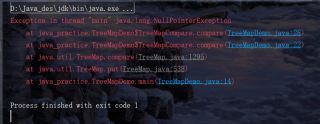
But in the end, the null pointer exception was reported. Later, it was found that it was not reasonable to add it in this way. I don't know what good methods readers have.
I did some research myself
If you want to follow the value, you must get the value. I checked the information. Can be combined with collections Method of sort(). Instructions are given in the API.


Then trace the comparator interface

In fact, you can understand the methods of this interface through understanding
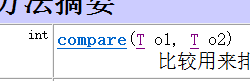
It should be noted that if you customize the constructor, you generally need to rewrite this method yourself.
Here's an example of sorting by value. The code is simple, but it really contains rich content.
package java_practice;
import java.util.*;
public class TreeMapDemo {
public static void main(String[] args) {
//Comparator comparator;
TreeMap<String, Integer> tm;
tm = new TreeMap<>();
tm.put("lqx",12);
tm.put("fqy",16);
tm.put("znk",10);
tm.put("jgdabc",20);
ArrayList<Map.Entry<String, Integer>> list = new ArrayList<>(tm.entrySet());
System.out.println(tm);
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
System.out.println(list);
}
}
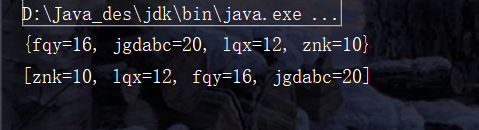
As mentioned above, this Entry encapsulates the key value. The inside provides getValue() and getKey () methods. In this way, we can customize the comparison constructor. Think about it this way. In fact, if you want to thoroughly understand it, you still have to look at the source code more. And if the jdk is new, the source code may also change, so you still have to learn more. Sometimes it's really necessary to look at the source code.
In fact, I will think that many times we will still compare the attributes of objects. A single column comparator seems a little easier than a double column comparator. It's not that hard to understand. Now the dual column comparator also understands a lot. I hope to write it down. In the future, you should supplement it yourself. Only by constantly understanding can we really learn.
In fact, when I think of this, I know there are still many things that are not involved. But in fact, I write my own code and check the information in this article. Looking at the source code, I spent two whole days. It's not that simple. Simple use is different from understanding. Think of here, is another mouthful of old blood.
Just write so much! Add content when you encounter problems later.