Author: Mr. SM\
Source: www.cnblogs.com com/king0/p/14176609. html
1, Map
Map 1.1 interface
In Java, Map provides key value mapping. The mapping cannot contain duplicate keys, and each key can only be mapped to one value.
Based on Map key value mapping, Java Util provides HashMap (the most commonly used), TreeMap, Hashtble, LinkedHashMap and other data structures.
Main features of several derived maps:
- HashMap: the most commonly used data structure. The mapping relationship between key and value is realized by Hash function. When the traversal key is unordered
- TreeMap: the data structure constructed by using red black tree. Because the principle of red black tree can sort the keys naturally, the keys of TreeMap are arranged in natural order (ascending order) by default.
- LinkedHashMap: saved the insertion order. The records obtained by traversal are in the insertion order.
1.2 Hash function
Hash (hash function) is to transform the input of any length into the output of fixed length through hash algorithm. The return value of the hash function is also called hash value, hash code digest or hash. The function of hash is shown in the following figure:

Hash function can achieve a better balance in time and space by selecting an appropriate function.
There are two ways to solve Hash: zipper method and linear detection method
1.3 implementation of key value relationship
interface Entry<K,V>
Implementation based on linked list in HashMap
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}It is implemented in the form of tree:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}1.4 API agreed in map
1.4.1 basic API agreed in map
Basic addition, deletion, modification and query:
int size(); // Return size boolean isEmpty(); // Is it empty boolean containsKey(Object key); // Include a key boolean containsValue(Object value); // Include a value V get(Object key); // Get the value corresponding to a key V put(K key, V value); // Stored data V remove(Object key); // Remove a key void putAll(Map<? extends K, ? extends V> m); //Insert another set into the set void clear(); // eliminate Set<K> keySet(); //Get all the keys of the Map and return to the Set collection Collection<V> values(); //Returns all values as a Collection Set<Map.Entry<K, V>> entrySet(); // Map key value pairs to map The internal class Entry implements the mapping relationship. And return all key values mapped to Set set Set. boolean equals(Object o); int hashCode(); // Return Hash value default boolean replace(K key, V oldValue, V newValue); // Alternative operation default V replace(K key, V value);
1.4.2 advanced API of map agreement
default V getOrDefault(Object key, V defaultValue); //When the acquisition fails, use defaultValue instead.
default void forEach(BiConsumer<? super K, ? super V> action) // lambda expressions can be used for faster traversal
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function);
default V putIfAbsent(K key, V value);
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction);
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction);
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction)
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction)1.4.3 use of map advanced API
- getOrDefault() returns the default value when the value is obtained through the key and the corresponding key or value does not exist, so as to avoid null and program exceptions during use.
- ForEach() passes in BiConsumer functional interface. The meaning of ForEach() is actually the same as that of Consumer. BiConsumer has an accept method, but BiConsumer has an additional andThen() method. It receives a BiConsumer interface and executes the accept method of this interface first, and then the passed in parameters.
Map<String, String> map = new HashMap<>();
map.put("a", "1");
map.put("b", "2");
map.put("c", "3");
map.put("d", "4");
map.forEach((k, v) -> {
System.out.println(k+"-"+v);
});
}More function usage:
https://www.cnblogs.com/king0...
1.5 from Map to HashMap
HashMap is an implementation class of Map and the most commonly used implementation class of Map.
1.5.1 inheritance relationship of HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, SerializableIn the implementation of HashMap, the method to solve Hash conflict is zipper method. Therefore, in principle, the implementation of HashMap is array + linked list (the entry for the array to save the linked list). When the linked list is too long, in order to optimize the query rate, HashMap converts the linked list into a red black tree (the root node of the array storage tree), so that the query rate is log(n), not O(n) of the linked list.
2, HashMap
/* * @author Doug Lea * @author Josh Bloch * @author Arthur van Hoff * @author Neal Gafter * @see Object#hashCode() * @see Collection * @see Map * @see TreeMap * @see Hashtable * @since 1.2 */
Firstly, HashMap is participated by Doug Lea and Josh Bloch. At the same time, Java's Collections collection system and concurrent framework Doug Lea have also made a lot of contributions.
2.1 basic principles
For an insert operation, first convert the key into the subscript of the array through the Hash function. If the array is empty, directly create nodes and put them into the array. If there are nodes in the array subscript, that is, Hash conflict, use the zipper method to generate a linked list insertion.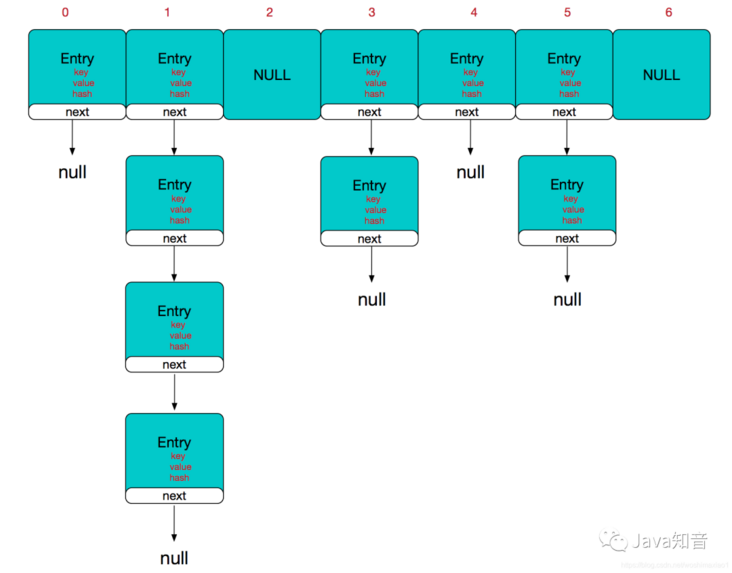
Reference picture from https://blog.csdn.net/woshima...
If there is a Hash conflict, use the zipper method to insert. We can insert it at the head of the linked list or at the tail of the linked list. Therefore, the head insertion method is used in JDK 1.7 and the tail insertion method is used in subsequent versions of JDK 1.8.
JDK 1.7 may use header insertion based on the fact that the recently inserted data is the most commonly used, but one of the problems caused by header insertion is that there will be an endless loop in the copy of multi-threaded linked list. Therefore, the tail insertion method adopted after JDK 1.8.
In HashMap, the definition of array + linked list array mentioned earlier
transient Node<K,V>[] table;
Definition of linked list:
static class Node<K,V> implements Map.Entry<K,V>
2.1.2 constructor provided
public HashMap() { // Empty parameter
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) { //With the initial size, in general, we need to plan the size of HashMap, because the cost of a capacity expansion operation is very large
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor); // You can customize the load factor public HashMap(int initialCapacity, float loadFactor)// You can customize the load factorThe three constructors do not fully initialize the HashMap. When we insert data for the first time, we allocate heap memory, which improves the response speed of the code.
2.2 definition of Hash function in HashMap
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // XOR the h upper 16 bits and the lower 16 bits.
}
// The reason why XOR is used: when two bits are operated, only the probability of 0 and 1 of XOR is the same in and or XOR, and both & and | will bias the result to 0 or 1.Here you can see that the key of Map can be null, and the hash is a specific value of 0.
The purpose of Hash is to get the subscript of the array table. The goal of Hash function is to evenly distribute the data in the table.
Let's first look at how to get the corresponding array subscript through hash value. The first method: hash% table length(). However, the execution of division operation in CPU is much slower than addition, subtraction and multiplication, and the efficiency is low. The second method, table [(table. Length - 1) & hash], is a subtraction with an operation, which is still faster than division. The constraint here is table length = 2^N.
table.length =16 table.length -1 = 15 1111 1111 //Any number and operation obtains the lower 8 bits of the number, and the other bits are 0
The above example allows us to obtain the corresponding subscript, and (H = key. hashCode()) ^ (H > > > 16) allows Gao 16 to participate in the operation and make full use of the data. Generally, the index of table will not exceed 216, so we directly discard the high-order information, ^ (H > > > 16) allows us to use the high-order information when the amount of data is small. If the index of the table exceeds 216, the Hash obtained by XOR of the high 16 of hashcode () and 16 zeros is also fair.
2.3 HashMap insertion
As we know above, if we get the corresponding table subscript through Hash, so we add the corresponding node to the linked list to complete a Map mapping, indeed jdk1 This is the implementation of HashMap in 7. Let's take a look at the JDK to implement the actual put operation.
Navigate to the put() operation.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}You can see that the put operation is handed over to putVal for general implementation.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict); //onlyIfAbsent if a value already exists in the current position, whether to replace it. false means to replace it, and true means not to replace it evict // The parameters of the hook function are used in LinkedHashMap and have no meaning in HashMap.
2.3.1 process analysis of putval
In fact, the function of putVal() process is very clear. Here are some key steps to guide.
true calls resizer() to adjust whether to insert for the first time. In fact, at this time, resizer() is fully initialized and then directly assigned to the position of the corresponding index.
if ((tab = table) == null || (n = tab.length) == 0) // For the first put operation, the tab does not allocate memory. Allocate memory through the resize () method and start working.
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);If the linked list has been converted to a tree, the insertion of the tree is used.
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);Traverse each Node in the way of traversal. If the key is the same, or reach the next pointer of the tail Node, insert the data, record the Node position and exit the loop. If the length of the linked list after insertion is 8, call treeifyBin() to check whether to convert the tree.
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}Repeat operation for key: the old value is returned after update, and it also depends on onlyIfAbsent. It is generally true in normal operation and can be ignored.
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //Hook function for subsequent operations. HashMap is empty without any operation.
return oldValue;
}~
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;Subsequent data maintenance.
2.3.2 meaning of modcount
Fail fast mechanism is an error mechanism in java collection. When multiple threads operate on the contents of the same collection, a fail fast event may be generated. For example, when a thread a traverses a set through the iterator, if the content of the set is changed by other threads; When thread a accesses the collection, it will throw a ConcurrentModificationException and generate a fail fast event. A multi-threaded error checking method to reduce the occurrence of exceptions.
In general, we use ConcurrentHashMap instead of HashMap in multithreaded environment.
2.4 resize() function
HashMap expansion features: the default table size is 16 and the threshold is 12. Load factor LoadFactor. 75, which can be constructed or changed. In the future, the capacity expansion will be doubled.
As for why it is 0.75 code, the reason is also written in the comment. The Poisson distribution model of Hash function is constructed and analyzed.
2.4.1 some predefined parameters of HashMap
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // Aka 16 default size of HashMap. Why use 1 < < 4 static final int MAXIMUM_CAPACITY = 1 << 30; // Maximum capacity static final float DEFAULT_LOAD_FACTOR = 0.75f; // Loading factor, expansion use static final int UNTREEIFY_THRESHOLD = 6;// Threshold value of transforming tree structure into linked list static final int TREEIFY_THRESHOLD = 8; // Threshold value of transforming linked list into tree structure static final int MIN_TREEIFY_CAPACITY = 64; // If the length of the linked list is greater than 64, the conversion will occur only once before it is converted into an array. This is to avoid unnecessary conversion caused by multiple key value pairs being put into the same linked list at the initial stage of hash table establishment. // Relevant variables defined int threshold; // Threshold indicates that the resize operation will be performed when the size of HashMap is greater than threshold
These variables are related to the capacity expansion mechanism of HashMap and will be used below.
2.4.2 parse of resize() method
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0; // The old table length, old table threshold, new table length and new table threshold are defined if (oldCap > 0) { // Data has been inserted, and the parameter is not initialized
if (oldCap >= MAXIMUM_CAPACITY) { // If the length of the old table is greater than 1 < < 30;
threshold = Integer.MAX_VALUE; // threshold sets the maximum value of Integer. That is, we can insert Integer MAX_ Value data
return oldTab; // Directly return the length of the old table, because the subscript index of the table cannot be expanded.
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && //
oldCap >= DEFAULT_INITIAL_CAPACITY) //The length of the new table is twice that of the old table.
newThr = oldThr << 1; // double threshold the threshold of the new table is twice that of the old table at the same time
}
else if (oldThr > 0) // This in public HashMap(int initialCapacity, float loadFactor) threshold = tableSizeFor(initialCapacity); Give the right position
newCap = oldThr;
else { // Zero initial threshold signatures using defaults. If the other two constructors are called, the following code initializes. Because they have not set their threshold, which is 0 by default,
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { // Correct the threshold. For example, the else if (oldthreshold > 0) section above is not set.
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})When some parameters are set correctly, capacity expansion starts.
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
When the expansion is completed, the data in the original table will naturally be moved to the new table. The following code completes the task.
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
....
}
}How to correctly and quickly expand and adjust the subscript corresponding to each key node? The first method: traverse the node and add it again with put(). This method is implemented, but it is inefficient. Second, we manually assemble the linked list and add it to the corresponding position. Obviously, the second is more efficient than the first, because the first put() has other judgments that do not belong to this situation, such as the judgment of repeated keys.
So JDK 1.8 also uses the second method. We can continue to use e.hash & (newCap - 1) to find the corresponding subscript position. For the old linked list, the operation of e.hash & (newCap - 1) can only produce two different indexes. One keeps the original index unchanged, and the other becomes the original index + oldcap (because the addition of newCap leads to an increase of 1 bit in the number of digits of the index, that is, the leftmost one, and the result of this bit is 1, so it is equivalent to the original index + oldCap). Therefore, if ((e.hash & oldCap) = = 0) can be used to determine whether the index changes.
Therefore, in this way, we can split the original linked list into two new linked lists, and then add them to the corresponding positions. In order to be efficient, we manually assemble the linked list and store it in the corresponding subscript position.
oldCap = 16 newCap = 32 hash : 0001 1011 oldCap-1 : 0000 1111 The result is : 0000 1011 Corresponding index 11 ------------------------- e.hash & oldCap Then set at 1,The index needs to be adjusted oldCap = 16 hash : 0001 1011 newCap-1 : 0001 1111 The result is : 0001 1011 Equivalent to 1011 + 1 0000 Original index + newCap
for (int j = 0; j < oldCap; ++j) // Process each linked list
Handling of special conditions
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) // If the linked list has only one node, it is copied directly to the corresponding location, and the subscript is determined by E. hash & (newcap - 1)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // If it is a tree, it should be given to the handler of the tree
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);General handling:
else { // preserve order
Node<K,V> loHead = null, loTail = null; // To build a linked list of the original index position, you need a pointer
Node<K,V> hiHead = null, hiTail = null; // Pointer required to build the linked list of the original index + oldCap position
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null); // Divide the original linked list into two linked lists
if (loTail != null) { // Write the linked list to the corresponding position
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}This completes the logic of the resize() method. In general, resizer() completes the complete initialization, memory allocation and subsequent capacity expansion and maintenance of HashMap.
2.5 remove parsing
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}Leave the remove deletion to the internal function removeNode().
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) { // Get index,
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // Determine whether the value at the index is the desired result
node = p;
else if ((e = p.next) != null) { // Search algorithm given to tree
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do { // Traversal search
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) //Tree deletion
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) // Repair the linked list and delete the linked list
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}3, Transformation of HashMap from linked list to red black tree
If the length of the linked list (the number of conflicting nodes) has reached 8, treeifyBin() will be called. treeifyBin() will first judge the length of the table of the current hashMap. If it is less than 64, only resize and expand the table. If it reaches 64, the conflicting storage structure will be a red black tree. There is such a field in the source code.
static final int UNTREEIFY_THRESHOLD = 6; // This shows that the threshold for converting from red black tree to linked list is 6. Why is it not 8? //If the insertion and deletion are around 8, converting them into each other will waste a lot of time and affect its performance. //If the operation of the transformation between the two is unbalanced and biased to one side, such effects can be avoided.
3.1 data structure of red black tree
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // After deletion, you need to unlink and point to the previous node (the previous node in the original linked list)
boolean red;
}Because it inherits LinkedHashMap Entry < K, V >, so the stored data is still in the entry:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}3.2 treeifyBin()
Treeifybin () determines when a linked list is transformed into a red black tree. treeifyBin() has two formats:
final void treeifyBin(Node<K,V>[] tab, int hash); final void treeify(Node<K,V>[] tab);
final void treeifyBin(Node<K,V>[] tab, int hash) { // The simple Node is modified to TreeNode, and the prev attribute is maintained at the same time.
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab); // Really generate red and black trees
}
} TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
} // Realize the transformation from Node linked list Node to TreeNode Node.The following function really realizes the transformation of the red and black tree of the linked list. First, a standard query two fork tree is constructed, then the two fork tree is querying in a standard way and then adjusted to a red black tree. The balanceInsertion() implements the adjustment.
/**
* Forms tree of the nodes linked from this node.
*/
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) { // In the first conversion process, the head node of the linked list is taken as the root node.
x.parent = null;
x.red = false; // The definition root node of red black tree must be black
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) ////The insertion order is determined by the size of the Hash
dir = -1; // Identification of dir size order
else if (ph < h)
dir = 1;
else if ((kc == null && //When the values of two hashes are the same, a special method is used to determine the size.
(kc = comparableClassFor(k)) == null) || // Returns x's Class if it is of the form "class C implements Comparable ", else null. If the source code writing format of the key class is C implementation comparable < C >, the type C of this class will be returned. If it is implemented indirectly, it will not work. If it is a String type, directly return String class
(dir = compareComparables(kc, k, pk)) == 0) // ((Comparable)k).compareTo(pk)); Compare after forced conversion. If dir == 0, tiebreakhorder() will continue arbitration
dir = tieBreakOrder(k, pk); // First, compare the class types of the two. If they are equal, use (system. Identityhashcode (a) < = system Identityhashcode (b) uses the original hashcode, not rewritten in comparison.
TreeNode<K,V> xp = p; // Traversal, previous node
if ((p = (dir <= 0) ? p.left : p.right) == null) { //Through dir, look down p until p is null and find an insertion time
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x); //Adjust the binary tree
break;
}
}
}
}
moveRootToFront(tab, root);
}3.3 operation of transforming a binary tree into a red black tree - balanceInsertion()
When adding new nodes in the red black tree, you need to call the balanceInsertion method to ensure the characteristics of the red black tree.
If you want to understand the insertion process of red black tree, you must have a clear understanding of the nature of red black tree.
Properties of red black tree:
- Each node is either red or black
- The root node is black
- Each leaf node (NIL) is black
- If a node is red, its two sons are black.
- For each node, the number of black nodes on all paths from this node to its leaf node is the same.
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true; // The inserted child node must be red
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) { ////x current processing node xp parent node xpp grandfather node xppl grandfather left node xppr grandfather right node
if ((xp = x.parent) == null) { // If the current processing node is the root node and meets the nature of red black tree, the cycle is ended
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
return root;
if (xp == (xppl = xpp.left)) {
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}TreeNode red black tree summary
TreeNode completely implements a set of rules for adding, deleting, modifying and querying red and black trees. The implementation refers to the introduction to algorithm
/* ------------------------------------------------------------ */ // Red-black tree methods, all adapted from CLR
Here we recommend a red and black tree animation demonstration website https://rbtree.phpisfuture.com/
Red black tree is a non strict balanced binary search tree, which is highly similar to log(N).
4, Extension of HashMap
A property of key in Map is that key cannot be repeated, while the meaning of Java Set: there cannot be repeated elements in the Set. The implementation of HashMap is excellent enough. So can we use the property of key to implement Set? Indeed, HashSet in JDK does just that.
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
}PRESENT is the value stored in the Map, and key is the implementation of Set semantics. Moreover, it can be judged that Null values are allowed to be stored in HashSet.
Recent hot article recommendations:
1.1000 + Java interview questions and answers (2022 latest version)
2.Hot! The Java collaboration is coming...
3.Spring Boot 2.x tutorial, too complete!
4.20w programmer red envelope cover, get it quickly...
5.Java development manual (Songshan version) is the latest release. Download it quickly!
Feel good, don't forget to like + forward!