1, Create project
(1) Go to https://aistudio.baidu.com/aistudio/projectoverview/public
(2) Create project
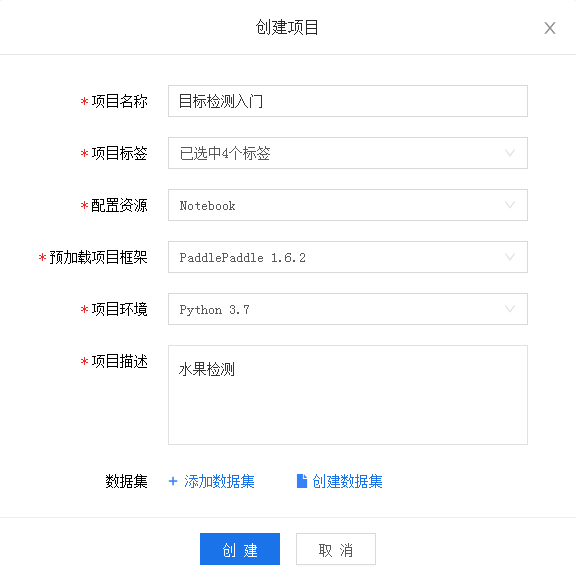
Click Add dataset: find these two
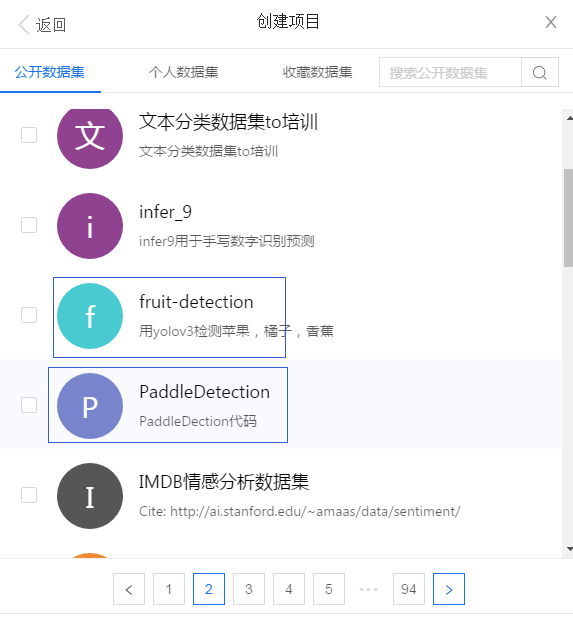
Then create it.
The following projects are generated:
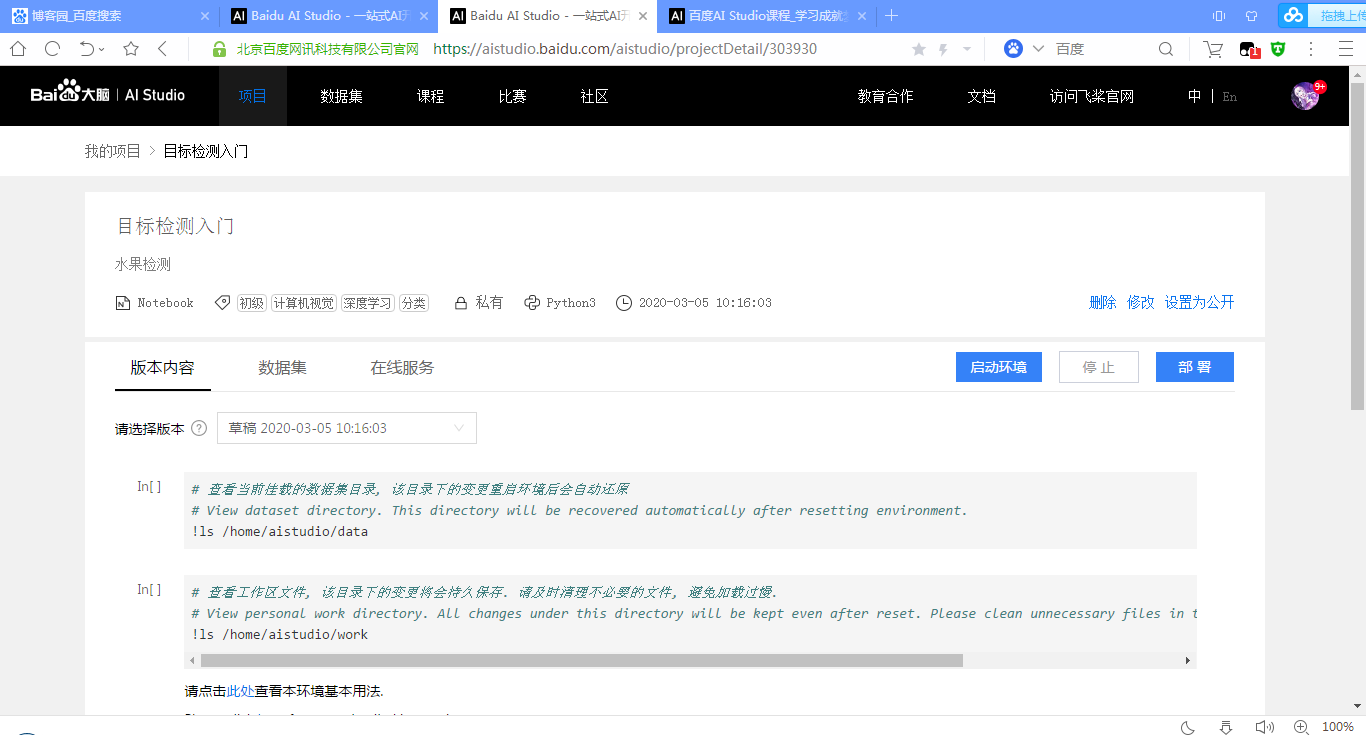
2, Boot environment, select GPU version
Then you will enter the following interface
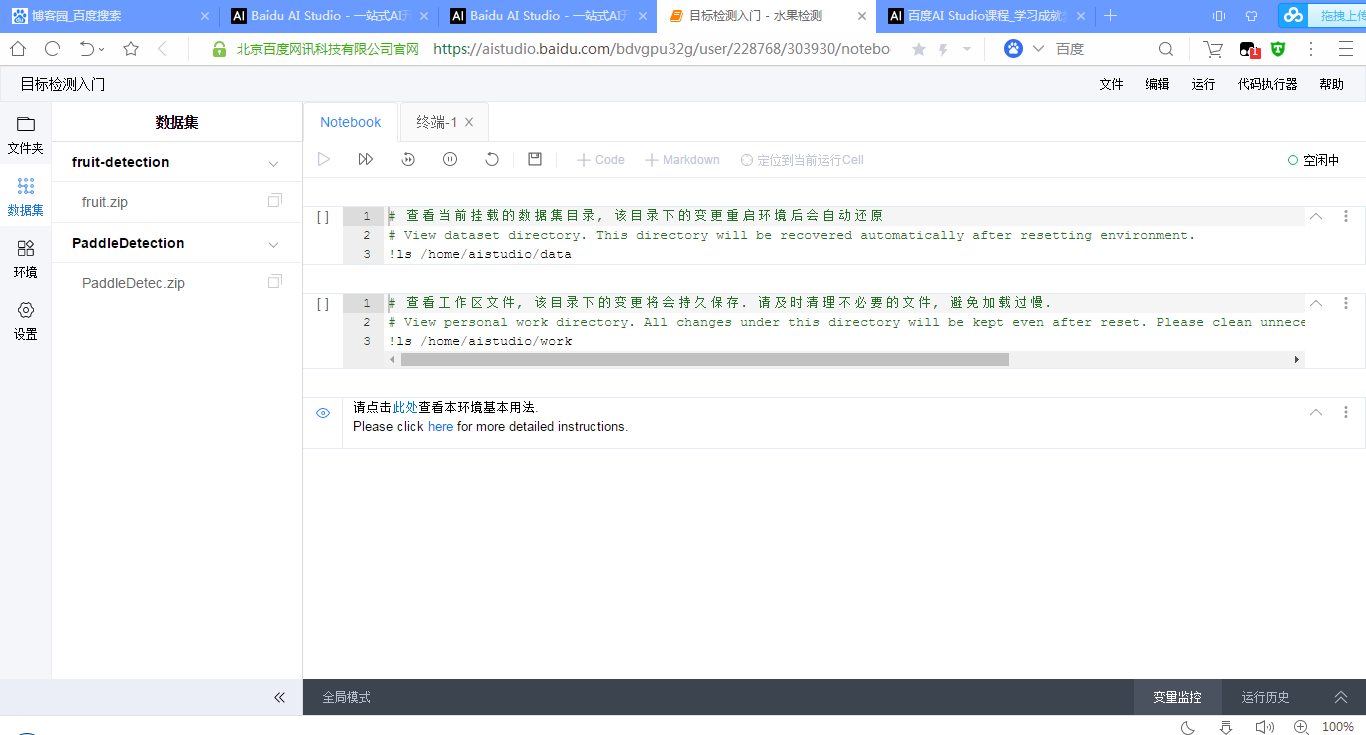
Under / home/aistudio/data /, the two selected compression packages are decompressed first:
!unzip /home/aistudio/data/data15067/fruit.zip !unzip /home/aistudio/data/data15072/PaddleDetec.zip
Then you can see the extracted content in the left folder:
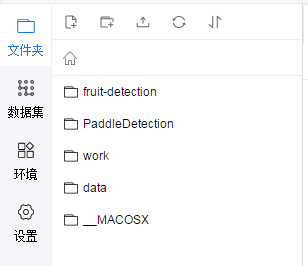
3, To see what's in fruit detection:
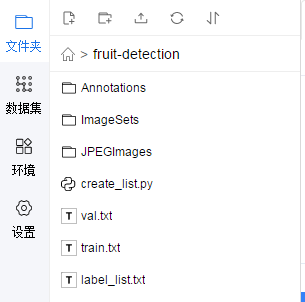
In fact, it is similar to the format of pascal voc target detection data set
(1) Annotations
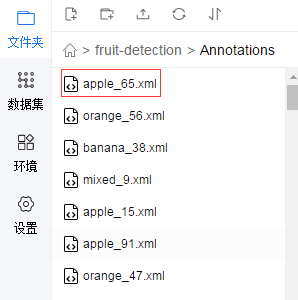
Take the first apple_65.xml as an example:
Folder: folder name
filename: picture name
path: file address
Size: the size of the picture
Object: the name of the object in the picture and the coordinates of its lower left and upper right corners.
<annotation> <folder>train</folder> <filename>apple_65.jpg</filename> <path>C:\tensorflow1\models\research\object_detection\images\train\apple_65.jpg</path> <source> <database>Unknown</database> </source> <size> <width>800</width> <height>600</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>70</xmin> <ymin>25</ymin> <xmax>290</xmax> <ymax>226</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>35</xmin> <ymin>217</ymin> <xmax>253</xmax> <ymax>453</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>183</xmin> <ymin>177</ymin> <xmax>382</xmax> <ymax>411</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>605</xmin> <ymin>298</ymin> <xmax>787</xmax> <ymax>513</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>498</xmin> <ymin>370</ymin> <xmax>675</xmax> <ymax>567</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>333</xmin> <ymin>239</ymin> <xmax>574</xmax> <ymax>463</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>191</xmin> <ymin>350</ymin> <xmax>373</xmax> <ymax>543</ymax> </bndbox> </object> <object> <name>apple</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>443</xmin> <ymin>425</ymin> <xmax>655</xmax> <ymax>598</ymax> </bndbox> </object> </annotation>
(2)ImageSets
There is only one folder in Main, which includes:
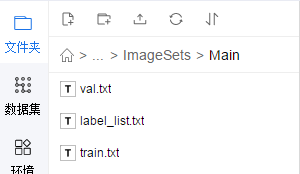
Look at what it is:
val.txt: name of validation set picture
orange_92
banana_79
apple_94
apple_93
banana_81
banana_94
orange_77
mixed_23
orange_78
banana_85
apple_92
apple_79
apple_84
orange_83
apple_85
mixed_21
orange_91
orange_89
banana_80
apple_78
banana_93
mixed_22
orange_94
apple_83
banana_90
apple_77
orange_79
apple_81
orange_86
orange_95
banana_88
orange_85
orange_80
apple_80
apple_82
mixed_25
apple_88
banana_83
banana_77
banana_84
banana_92
banana_86
apple_87
orange_84
banana_78
orange_93
orange_90
banana_89
orange_82
apple_90
apple_95
banana_82
banana_91
mixed_24
banana_87
apple_91
orange_81
apple_89
apple_86
orange_87
train.txt: the name of the training set picture. It's not pasted here. It's a bit long. It's similar to the verification set
label_list.txt: category name
apple
banana
orange
That is to say, fruit classification detection is only to identify three categories.
(3) JPEGImages: the actual pictures are stored
Look for Apple Ku 65.jpg

That's what it looks like
(4) create_list.py,label_list.txt,train.txt,val.txt
import os import os.path as osp import re import random devkit_dir = './' years = ['2007', '2012'] def get_dir(devkit_dir, type): return osp.join(devkit_dir, type) def walk_dir(devkit_dir): filelist_dir = get_dir(devkit_dir, 'ImageSets/Main') annotation_dir = get_dir(devkit_dir, 'Annotations') img_dir = get_dir(devkit_dir, 'JPEGImages') trainval_list = [] test_list = [] added = set() for _, _, files in os.walk(filelist_dir): for fname in files: img_ann_list = [] if re.match('train\.txt', fname): img_ann_list = trainval_list elif re.match('val\.txt', fname): img_ann_list = test_list else: continue fpath = osp.join(filelist_dir, fname) for line in open(fpath): name_prefix = line.strip().split()[0] if name_prefix in added: continue added.add(name_prefix) ann_path = osp.join(annotation_dir, name_prefix + '.xml') img_path = osp.join(img_dir, name_prefix + '.jpg') assert os.path.isfile(ann_path), 'file %s not found.' % ann_path assert os.path.isfile(img_path), 'file %s not found.' % img_path img_ann_list.append((img_path, ann_path)) return trainval_list, test_list def prepare_filelist(devkit_dir, output_dir): trainval_list = [] test_list = [] trainval, test = walk_dir(devkit_dir) trainval_list.extend(trainval) test_list.extend(test) random.shuffle(trainval_list) with open(osp.join(output_dir, 'train.txt'), 'w') as ftrainval: for item in trainval_list: ftrainval.write(item[0] + ' ' + item[1] + '\n') with open(osp.join(output_dir, 'val.txt'), 'w') as ftest: for item in test_list: ftest.write(item[0] + ' ' + item[1] + '\n') if __name__ == '__main__': prepare_filelist(devkit_dir, '.')
Converts dimension information to a list for storage.
label_list.txt: or the three categories
train.txt: a series of paths such as. / jpegimages / mixed_20.jpg. / annotations / mixed_20.xml
val.txt:. / jpegimages / orange Θ. Jpg. / annotations / orange Θ. XML and other paths
That's all there is to it.
4, View content in PaddleDetection
(1) configs
Profiles for various networks
Find yolov3 ﹣ mobilenet ﹣ V1 ﹣ fruit.yml
architecture: YOLOv3 train_feed: YoloTrainFeed eval_feed: YoloEvalFeed test_feed: YoloTestFeed use_gpu: true max_iters: 20000 log_smooth_window: 20 save_dir: output snapshot_iter: 200 metric: VOC map_type: 11point pretrain_weights: https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1.tar weights: output/yolov3_mobilenet_v1_fruit/best_model num_classes: 3 finetune_exclude_pretrained_params: ['yolo_output'] YOLOv3: backbone: MobileNet yolo_head: YOLOv3Head MobileNet: norm_type: sync_bn norm_decay: 0. conv_group_scale: 1 with_extra_blocks: false YOLOv3Head: anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]] anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]] norm_decay: 0. ignore_thresh: 0.7 label_smooth: true nms: background_label: -1 keep_top_k: 100 nms_threshold: 0.45 nms_top_k: 1000 normalized: false score_threshold: 0.01 LearningRate: base_lr: 0.00001 schedulers: - !PiecewiseDecay gamma: 0.1 milestones: - 15000 - 18000 - !LinearWarmup start_factor: 0. steps: 100 OptimizerBuilder: optimizer: momentum: 0.9 type: Momentum regularizer: factor: 0.0005 type: L2 YoloTrainFeed: batch_size: 1 dataset: dataset_dir: dataset/fruit annotation: fruit-detection/train.txt use_default_label: false num_workers: 16 bufsize: 128 use_process: true mixup_epoch: -1 sample_transforms: - !DecodeImage to_rgb: true with_mixup: false - !NormalizeBox {} - !ExpandImage max_ratio: 4.0 mean: [123.675, 116.28, 103.53] prob: 0.5 - !RandomInterpImage max_size: 0 target_size: 608 - !RandomFlipImage is_mask_flip: false is_normalized: true prob: 0.5 - !NormalizeImage is_channel_first: false is_scale: true mean: - 0.485 - 0.456 - 0.406 std: - 0.229 - 0.224 - 0.225 - !Permute channel_first: true to_bgr: false batch_transforms: - !RandomShape sizes: [608] with_background: false YoloEvalFeed: batch_size: 1 image_shape: [3, 608, 608] dataset: dataset_dir: dataset/fruit annotation: fruit-detection/val.txt use_default_label: false YoloTestFeed: batch_size: 1 image_shape: [3, 608, 608] dataset: dataset_dir: dataset/fruit
annotation: fruit-detection/label_list.txt use_default_label: false
Pay attention to the red mark.
(2)contrib
Pedestrian detection and vehicle detection? Not for the moment
(3) Dataset: there are py files in each folder for downloading the dataset
(4) demo: a sample image for the test results.
(5)docs:
(6) Information: the '' used for inference?
(7) ppdet:paddlepaddle detection related documents
(8) requirements.txt: some required dependencies
tqdm docstring_parser @ http://github.com/willthefrog/docstring_parser/tarball/master typeguard ; python_version >= '3.4' tb-paddle tb-nightly
(9) slim: should be used to compress the model
(10) tools: tools
V. training
The training code is in train.py in tools
Enter the paddeledecision directory
Input at the terminal: Python - U tools / train. Py - C configs / yolov3 ﹣ mobilenet ﹣ V1 ﹣ fruit. YML -- use ﹣ TB = true -- Eval
If No module named ppdet is found, add it to train.py
import sys
sys.path.append("/home/aistudio/PaddleDetection")
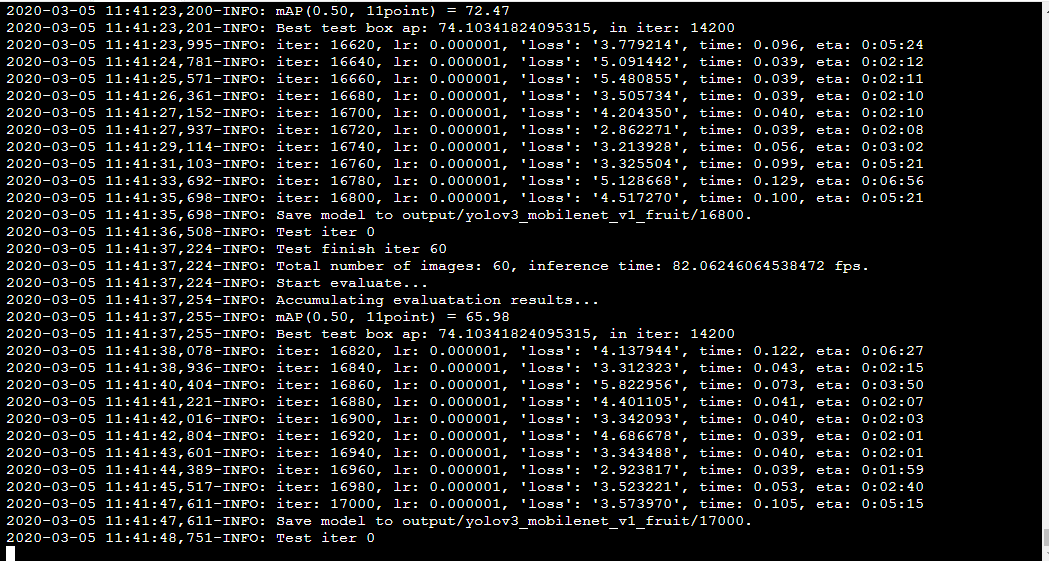
At last, it is stuck here, but it should be the end of the training. You can see the output folder in the paddledecision Directory:
There is a weight information generated during iteration:
6, Test a picture
python -u tools/infer.py -c configs/yolov3_mobilenet_v1_fruit.yml -o weights=/home/aistudio/PaddleDetection/output/yolov3_mobilenet_v1_fruit/model_final --infer_img=demo/orange_71.jpg
An error will be reported that there is no related package. Enter the following command to install:
pip install docstring_parser
pip install pycocotools
After that:

Go to output to see orange_71.jpg:

orange was detected with an accuracy of 94%.
If you know the whole process of detection training, you can manually mark the data in postal VOC format, and then you can detect what you want. Then you can also go to see the relevant target detection papers, understand the principle, see the source code and so on.