Introduction to Parquet
Parquet is an open source file format for processing flat columnar storage data formats that can be used by any project in the Hadoop ecosystem. Parquet can handle large amounts of complex data well. It is famous for its high-performance data compression and the ability to deal with various coding types. Compared with row based files such as CSV or TSV files, Apache Parquet aims to achieve an efficient and high-performance flat column data storage format.
Parquet uses a record shredding and assembly algorithm, which is superior to the simple flattening of nested namespaces. Parquet is optimized to process complex data in batches, and has different ways to achieve efficient data compression and coding types. This method is most suitable for queries that need to read some columns from large tables. Parquet only needs to read the required columns, thus greatly reducing IO. Some of parquet's benefits include:
- Compared with row based files such as CSV, columnar storage such as Apache Parquet is designed to improve efficiency. When querying, columnar storage can skip irrelevant data very quickly. Therefore, aggregate queries take less time than row oriented databases. This storage method has been transformed into saving hardware and minimizing the delay of accessing data.
- Apache Parquet was built from scratch. Therefore, it can support advanced nested data structures. The layout of Parquet data files is optimized for queries that handle large amounts of data, with each file in the Gigabyte range.
- Parquet is designed to support flexible compression options and efficient coding schemes. Since the data types of each column are very similar, the compression of each column is simple (which makes the query faster). One of several available codecs can be used to compress data; Therefore, different data files can be compressed differently.
- Apache Parquet is best suited for interactive and serverless technologies such as AWS Athena, Amazon Redshift Spectrum, Google BigQuery and Google Dataproc.
The difference between Parquet and CSV
CSV is a simple and widely used format, which is used by many tools such as Excel and Google table. Many other tools can generate CSV files. Even though CSV file is the default format of data processing pipeline, it has some disadvantages:
- Amazon Athena and Spectrum will charge based on the amount of data scanned per query.
- Google and Amazon will charge you based on the amount of data stored on GS/S3.
- Google Dataproc charges are time-based.
Parquet helps its users reduce the storage requirements of large data sets by at least one third. In addition, it greatly reduces the scanning and deserialization time, thus reducing the overall cost.
Spark reading and writing parquet file
Spark SQL supports the mode of reading and writing Parquet files and automatically capturing raw data. It also reduces data storage by an average of 75%. Spark supports Parquet in its library by default, so we don't need to add any dependent libraries. Here's how to pass spark Read and write parquet files.
In this paper, spark version 3.0.3 is used. Run the following command to enter the local mode:
bin/spark-shell
Data writing
First, create a DataFrame through Seq. The column names are "firstname", "middlename", "lastname", "dob", "gender", "salary"
val data = Seq(("James ","","Smith","36636","M",3000),
("Michael ","Rose","","40288","M",4000),
("Robert ","","Williams","42114","M",4000),
("Maria ","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1))
val columns = Seq("firstname","middlename","lastname","dob","gender","salary")
import spark.sqlContext.implicits._
val df = data.toDF(columns:_*)Using the parquet() function of DataFrameWriter class, we can write Spark DataFrame to parquet file. In this example, we write the DataFrame to the "people.parquet" file.
df.write.parquet("/tmp/output/people.parquet")see file

data fetch
val parqDF = spark.read.parquet("/tmp/output/people.parquet")
parqDF.createOrReplaceTempView("ParquetTable")
spark.sql("select * from ParquetTable where salary >= 4000").explain()
val parkSQL = spark.sql("select * from ParquetTable where salary >= 4000 ")
parkSQL.show()
Write partition data
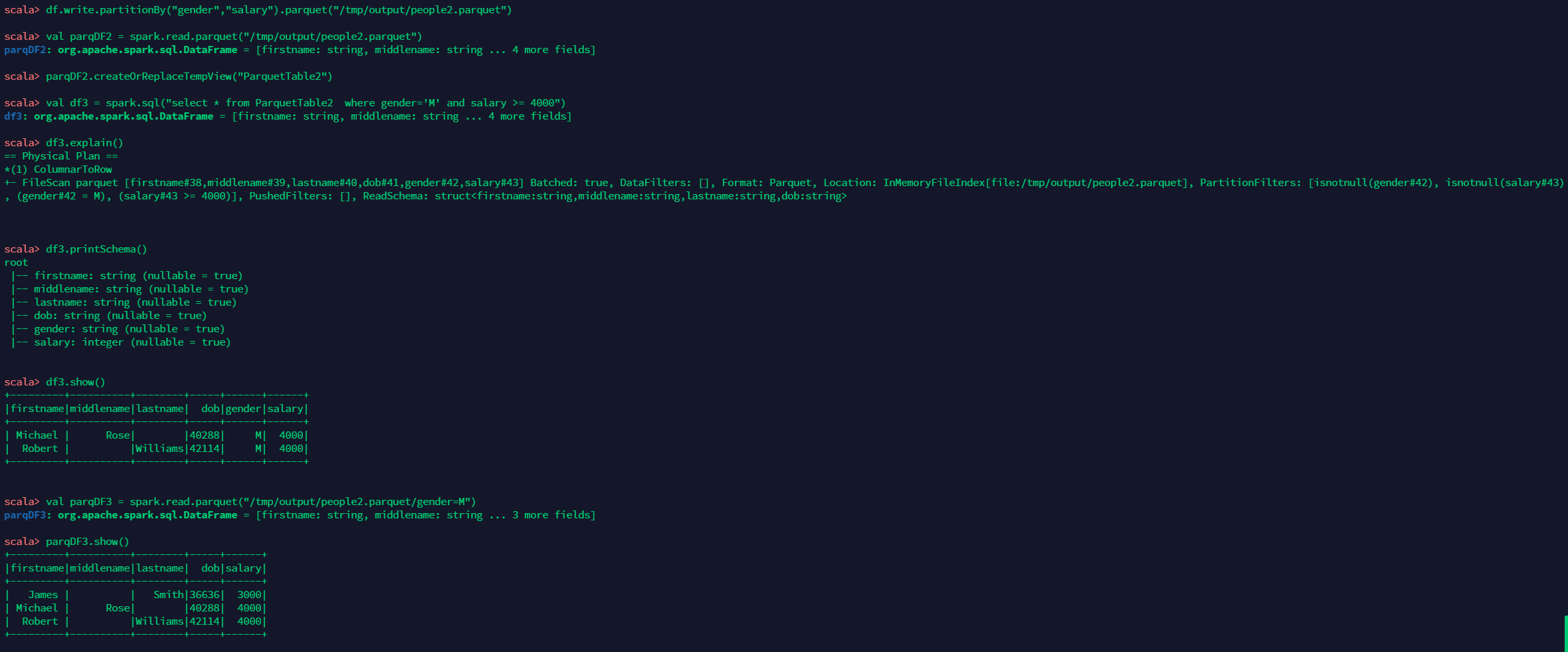
df.write.partitionBy("gender","salary").parquet("/tmp/output/people2.parquet")
val parqDF2 = spark.read.parquet("/tmp/output/people2.parquet")
parqDF2.createOrReplaceTempView("ParquetTable2")
val df3 = spark.sql("select * from ParquetTable2 where gender='M' and salary >= 4000")
df3.explain()
df3.printSchema()
df3.show()
val parqDF3 = spark.read.parquet("/tmp/output/people2.parquet/gender=M")
parqDF3.show()The following results are obtained
Flink reads and writes parquet files
By default, the Flink package does not contain the jar package related to parquet, so it needs to be downloaded for a specific version flink -parquet file. Taking flink-1.13.3 as an example, this paper downloads the file to the lib directory of Flink
cd lib/ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-parquet_2.12/1.13.3/flink-sql-parquet_2.12-1.13.3.jar
Before completing the following tests, start a flink standalone cluster environment locally.
bin/start-cluster.sh
Execute the following command to enter Flink SQL Client
bin/sql-client.sh
Read the parquet file written by spark
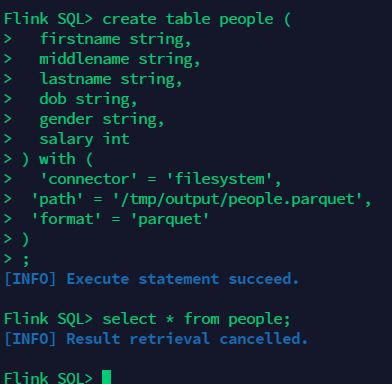
In the previous section, we wrote the people data into the parquet file through spark. Now we create a table in flink to read the parquet file data we just wrote in spark
create table people ( firstname string, middlename string, lastname string, dob string, gender string, salary int ) with ( 'connector' = 'filesystem', 'path' = '/tmp/output/people.parquet', 'format' = 'parquet' ) select * from people;
The results are as follows:

Write data to parquet file using Flink
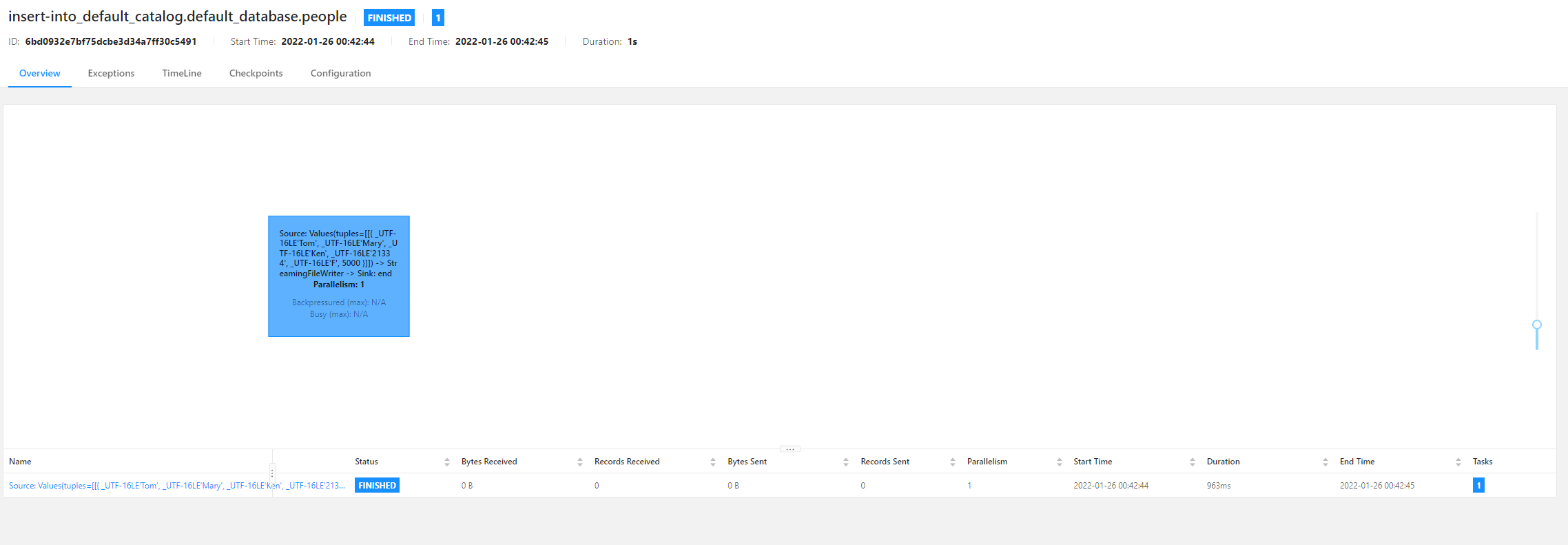
Then use flick to write data to the table just created:
insert into people values('Tom', 'Mary', 'Ken', '21334', 'F', 5000);View execution results in Flink UI
Query data again
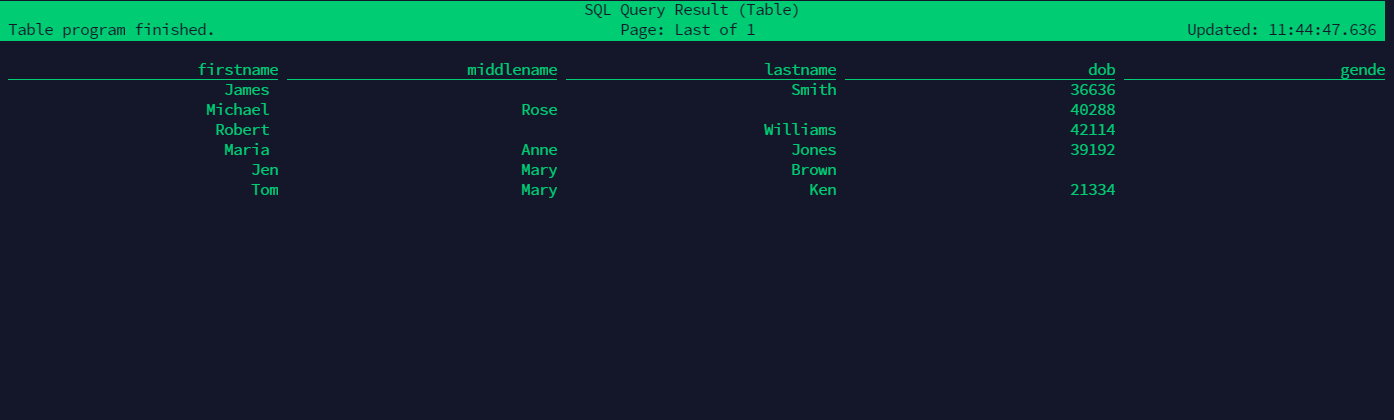
You can find the data we just inserted.
reference:
- https://databricks.com/glossary/what-is-parquet
- https://sparkbyexamples.com/spark/spark-read-write-dataframe-parquet-example/
- https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/formats/parquet/
This article is an original article from big data to artificial intelligence blogger "xiaozhch5", which follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement for reprint.
Original link: https://lrting.top/backend/3575/