background
We have a regular task in a single project, which will query and calculate the scores and rankings of different users from each business table every other hour. It is realized by Quartz; This encountered a problem in the later horizontal expansion to multi instance cluster deployment: the scheduled task is repeatedly executed in multiple application instances. Obviously, this is not the result we expect. At the same time, it is also a waste of computing resources. What's more, it will lead to the inconsistency of data in a period of time, At this time, the idempotency of timed tasks in cluster environment is involved.
Scheduled task
The implementation of scheduled tasks can be realized through various schemes such as Spring's @ enableshcheduling, quartz, XXL job, elastic job and so on. At the beginning, we chose quartz to implement timing tasks. The following mainly introduces the construction of quartz timing task distributed cluster service.
Distributed cluster task scheduling
How to solve the idempotent problem of distributed task scheduling? There are generally the following options:
- Configuration file, switch identification, flag; Single point
- Distributed lock, ZooKeeper, Redis; complex
- Timing task decoupling and independent deployment; A single point shall be executed in a load balancing manner
At this time, we need a simple, direct and effective way, which can be solved through Quartz cluster, so that no matter how many application instances there are in the cluster, the scheduled task will only be triggered once.
Although a single Quartz instance has good task scheduling ability, it can not meet the typical enterprise needs, such as scalability and high availability. If you need the ability of failover and can run more and more tasks, Quartz cluster is bound to become a part of your application.
Using Quartz's clustering capability can better support your business needs, and even if one of the machines crashes at the worst time, it can ensure that all tasks are executed.
Note: unlike many application service clusters, independent Quartz nodes do not communicate with other nodes or management nodes. A Quartz application perceives another application through a database table.
data sheet
Quartz officially provides 11 data tables (we use InnoDB's SQL file here), and the table structure information can be found in the external dependencies in the IDEA (Tip: you can also directly double-click Shift in the IDEA and enter tables_mysql_innodb to quickly locate the SQL file; you can also copy SQL directly from the end of the article):
.m2\repository\org\quartz-scheduler\quartz\2.3.2\quartz-2.3.2.jar!\org\quartz\impl\jdbcjobstore\tables_mysql_innodb.sql
- 11 table names
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS; DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS; DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE; DROP TABLE IF EXISTS QRTZ_LOCKS; DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS; DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS; DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS; DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS; DROP TABLE IF EXISTS QRTZ_TRIGGERS; DROP TABLE IF EXISTS QRTZ_JOB_DETAILS; DROP TABLE IF EXISTS QRTZ_CALENDARS;
- Description of 11 tables
| Serial number | Table name | explain |
|---|---|---|
| 1 | QRTZ_CALENDARS | Store Quartz calendar information |
| 2 | QRTZ_CRON_TRIGGERS | Store Cron type Trigger, including Cron expression and time zone information |
| 3 | QRTZ_FIRED_TRIGGERS | Store the status information related to the triggered Trigger and the execution information of the associated Job |
| 4 | QRTZ_PAUSED_TRIGGER_GRPS | Stores information about the paused Trigger group |
| 5 | QRTZ_SCHEDULER_STATE | Store a small amount of Scheduler related status information |
| 6 | QRTZ_LOCKS | Store lock information, provide distributed locks for multiple node scheduling, and realize distributed scheduling. There are two locks by default: STATE_ACCESS, TRIGGER_ACCESS |
| 7 | QRTZ_JOB_DETAILS | Store each configured JobDetail information |
| 8 | QRTZ_SIMPLE_TRIGGERS | Store Simple type Trigger, including the number of repetitions, interval, and the number of times it has been touched |
| 9 | QRTZ_BLOG_TRIGGERS | Trigger stored in Blob type |
| 10 | QRTZ_TRIGGERS | Store the basic information of the configured Trigger |
| 11 | QRTZ_SIMPROP_TRIGGERS | Store two types of triggers: CalendarIntervalTrigger and DailyTimeIntervalTrigger |
For details of 11 tables, refer to: https://blog.csdn.net/xiaoniu_888/article/details/83181078
Note: 4 data sheets required for cron mode: QRTZ_TRIGGERS,QRTZ_CRON_TRIGGERS,QRTZ_FIRED_TRIGGERS,QRTZ_JOB_DETAILS.
configuration file
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
url: jdbc:mysql://192.168.100.114:3306/quartz_task?serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&useSSL=false
username: root
password: root
quartz:
job-store-type: jdbc
properties:
org:
quartz:
jobStore:
class: org.quartz.impl.jdbcjobstore.JobStoreTX
clusterCheckinInterval: 10000
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
isClustered: true
tablePrefix: QRTZ_
useProperties: false
scheduler:
instanceId: AUTO
instanceName: clusteredScheduler
threadPool:
class: org.quartz.simpl.SimpleThreadPool
threadCount: 10
threadPriority: 5
threadsInheritContextClassLoaderOfInitializingThread: true
Description of main configuration items:
- org. quartz. scheduler. The InstanceName attribute can be any value and is used in JDBC JobStore to uniquely identify the instance, but it must be the same in all cluster nodes.
- org. quartz. scheduler. The instanceid attribute is AUTO, and the instance ID is generated based on the host name and timestamp.
- org. Quartz. jobStore. The class attribute is JobStoreTX, which persistes the task into the data. Because the nodes in the cluster depend on the database to propagate the status of the Scheduler instance, you can only apply Quartz cluster when using JDBC JobStore. This means that you must use JobStoreTX or JobStoreCMT as Job storage; You cannot use RAMJobStore in a cluster.
- org. quartz. jobStore. If the isclustered attribute is true, you tell the Scheduler instance to participate in a cluster. This attribute runs through the scheduling framework and is used to modify the default behavior of operations in the cluster environment.
- org. quartz. jobStore. The clusterCheckinInterval property defines how often the Scheduler instance is checked into the database (in milliseconds). The Scheduler checks whether other instances are not checked in when they should be checked in; This can indicate a failed Scheduler instance, and the current Scheduler will take over any failed and recoverable jobs. Through the check-in operation, the Scheduler will also update its own status record. The smaller the clusterCheckinInterval, the more frequently the Scheduler node fails to check the Scheduler instance. The default value is 15000 (i.e. 15 seconds).
task management
In order to realize Quartz timed task distributed cluster service, the core data table and configuration file are enough; In addition, in order to facilitate task management, we also implemented a RESTful task management interface in the project:
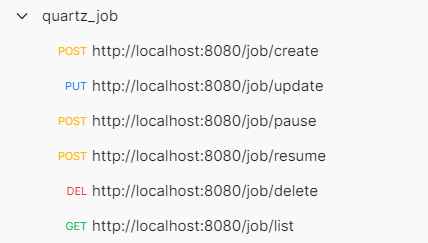
- Add task: http://localhost:8080/job/create
- Modify task: http://localhost:8080/job/update
- Suspend task: http://localhost:8080/job/pause
- Recovery task: http://localhost:8080/job/resume
- Delete task: http://localhost:8080/job/delete
- Get task list: http://localhost:8080/job/list
Service layer core code
- Add task
/**
* Add cron expression task
*
* @param info
*/
public void addCronJob(TaskInfo info) {
String jobName = info.getJobName();
String jobClassName = info.getJobClassName();
String jobGroupName = info.getJobGroupName();
String jobDescription = info.getJobDescription();
String cronExpression = info.getCronExpression();
Date createTime = new Date();
JobDataMap dataMap = new JobDataMap();
if (info.getData() != null) {
dataMap.putAll(info.getData());
}
dataMap.put("createTime", createTime);
try {
if (checkExists(jobName, jobGroupName)) {
throw new CustomException(String.format("Task already exists, jobName:[%s],jobGroup:[%s]", jobName, jobGroupName));
}
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroupName);
JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);
CronScheduleBuilder schedBuilder = CronScheduleBuilder
.cronSchedule(cronExpression)
.withMisfireHandlingInstructionDoNothing();
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey)
.withSchedule(schedBuilder).build();
Class<? extends Job> clazz = (Class<? extends Job>) Class
.forName(jobClassName);
JobDetail jobDetail = JobBuilder.newJob(clazz).withIdentity(jobKey)
.withDescription(jobDescription).usingJobData(dataMap).build();
scheduler.scheduleJob(jobDetail, trigger);
log.info("task: {} Added successfully", jobName);
} catch (SchedulerException | ClassNotFoundException e) {
throw new CustomException("Failed to add task");
}
}
- Modify task
/**
* Modify scheduled task
*
* @param info
*/
public void editCronJob(TaskInfo info) {
String jobName = info.getJobName();
String jobGroupName = info.getJobGroupName();
String jobDescription = info.getJobDescription();
String cronExpression = info.getCronExpression();
JobDataMap dataMap = new JobDataMap();
if (info.getData() != null) {
dataMap.putAll(info.getData());
}
try {
if (!checkExists(jobName, jobGroupName)) {
throw new CustomException(
String.format("Job non-existent, jobName:{%s},jobGroup:{%s}", jobName, jobGroupName));
}
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroupName);
JobKey jobKey = new JobKey(jobName, jobGroupName);
CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder
.cronSchedule(cronExpression)
.withMisfireHandlingInstructionDoNothing();
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey)
.withSchedule(cronScheduleBuilder).build();
JobDetail jobDetail = scheduler.getJobDetail(jobKey);
jobDetail = jobDetail.getJobBuilder().withDescription(jobDescription).usingJobData(dataMap).build();
HashSet<Trigger> triggerSet = new HashSet<>();
triggerSet.add(cronTrigger);
scheduler.scheduleJob(jobDetail, triggerSet, true);
} catch (SchedulerException e) {
throw new CustomException("Class name does not exist or expression execution error");
}
}
- Suspend task
/**
* Pause scheduled tasks
*
* @param jobName
* @param jobGroup
*/
public void pauseJob(String jobName, String jobGroup) {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);
try {
if (checkExists(jobName, jobGroup)) {
scheduler.pauseTrigger(triggerKey);
log.info("task: {} Pause successful", jobName);
} else {
log.warn("Task not found:{}", jobName);
}
} catch (SchedulerException e) {
throw new CustomException(e.getMessage());
}
}
- Recovery task
/**
* Resume suspended tasks
*
* @param jobName
* @param jobGroup
*/
public void resumeJob(String jobName, String jobGroup) {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);
try {
if (checkExists(jobName, jobGroup)) {
scheduler.resumeTrigger(triggerKey);
log.info("task: {} recovery was successful", jobName);
} else {
log.warn("Task not found:{}", jobName);
}
} catch (SchedulerException e) {
throw new CustomException(e.getMessage());
}
}
- Delete task
/**
* Delete scheduled task
*
* @param jobName
* @param jobGroup
*/
public void deleteJob(String jobName, String jobGroup) {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);
try {
if (checkExists(jobName, jobGroup)) {
scheduler.pauseTrigger(triggerKey);
scheduler.unscheduleJob(triggerKey);
log.info("task: {} Deleted successfully", jobName);
} else {
log.warn("Task not found:{}", jobName);
}
} catch (SchedulerException e) {
throw new CustomException(e.getMessage());
}
}
- Get task list
/**
* Get task list
*
* @return
*/
public List<TaskInfo> getJobList() {
List<TaskInfo> list = new ArrayList<>();
try {
for (String groupJob : getJobGroupNames()) {
for (JobKey jobKey : scheduler.getJobKeys(GroupMatcher.<JobKey>groupEquals(groupJob))) {
List<? extends Trigger> triggers = scheduler.getTriggersOfJob(jobKey);
for (Trigger trigger : triggers) {
Trigger.TriggerState triggerState = scheduler.getTriggerState(trigger.getKey());
JobDetail jobDetail = scheduler.getJobDetail(jobKey);
String cronExpression = "";
Date createTime = null;
long repeatInterval = 0L;
int repeatCount = 0;
Date startDate = null;
Date endDate = null;
if (trigger instanceof CronTrigger) {
CronTrigger cronTrigger = (CronTrigger) trigger;
cronExpression = cronTrigger.getCronExpression();
} else if (trigger instanceof SimpleTrigger) {
SimpleTrigger simpleTrigger = (SimpleTrigger) trigger;
repeatInterval = simpleTrigger.getRepeatInterval();
repeatCount = simpleTrigger.getRepeatCount();
startDate = simpleTrigger.getStartTime();
endDate = simpleTrigger.getEndTime();
}
TaskInfo info = new TaskInfo();
info.setData(jobDetail.getJobDataMap());
info.setJobName(jobKey.getName());
info.setJobTrigger(trigger.getClass().getName());
info.setJobGroupName(jobKey.getGroup());
info.setJobClassName(jobDetail.getJobClass().getName());
info.setJobDescription(jobDetail.getDescription());
info.setJobStatus(triggerState.name());
info.setCronExpression(cronExpression);
info.setCreateTime(createTime);
info.setRepeatInterval(repeatInterval);
info.setRepeatCount(repeatCount);
info.setStartDate(startDate);
info.setEndDate(endDate);
list.add(info);
}
}
}
} catch (SchedulerException e) {
e.printStackTrace();
}
return list;
}
Test Job
Here, taking a test task as an example, we regularly (every 30s) request poetry from an open interface to demonstrate the execution of the timed task.
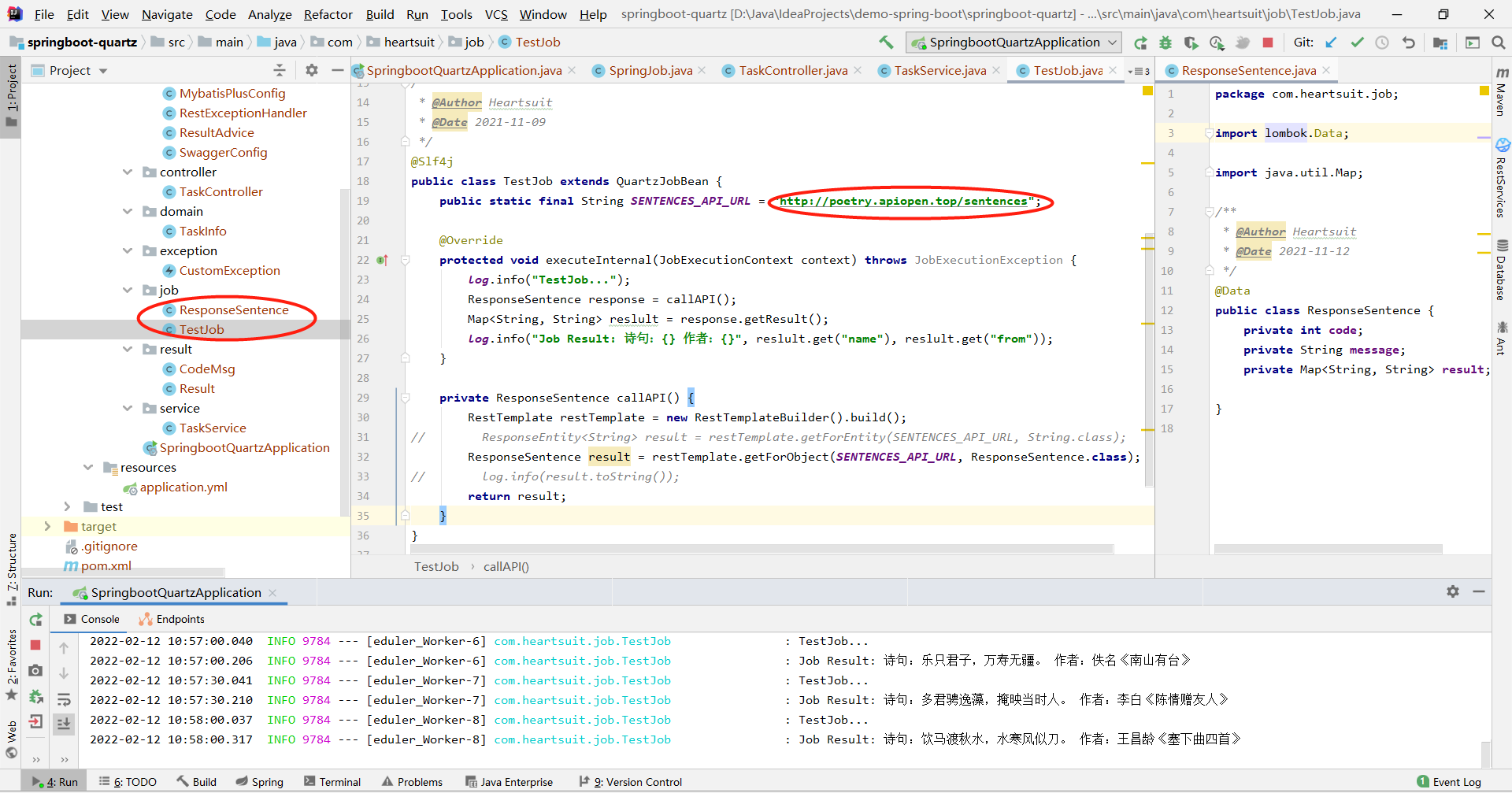
Non business processing
The following non business functions: unified response encapsulation, global exception interception, paging query, Swagger3 interface document.
Task scheduling effect display
After implementing the Quartz timed task cluster service, we need to verify whether it can achieve this effect: no matter how many application instances there are in the cluster, the timed task will only be triggered once.
Here, I use three service instances (one service number A in the local development environment and one service on each of the two servers on the virtual machine, numbered B and C respectively) for verification.
- Compile and package: mvn clean package
- Upload the compiled jar package to the virtual machine
- Start the three instances respectively: Java - jar springboot-quartz-0.0.1-snapshot jar
After the three instances are started, the changes in the data in the database table are mainly qrtz_scheduler_state table: with three running service instances, other tables can be observed by themselves, so the diagram is not displayed..
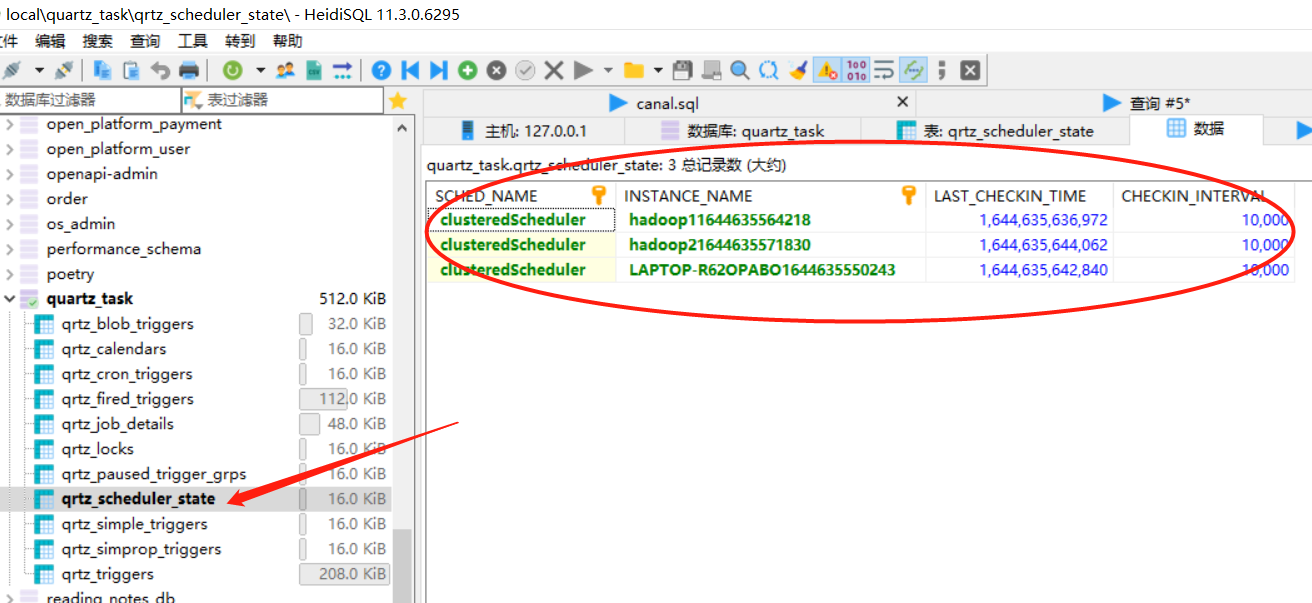
- Start 3 instances
After starting the three instances, we found that the implementation of Quartz cluster does not balance the load between different instances in the cluster like other middleware, but continuously executes on one of them (instance A). So when a service hangs up, how to achieve failover? Don't worry, let's try to hang up a service.
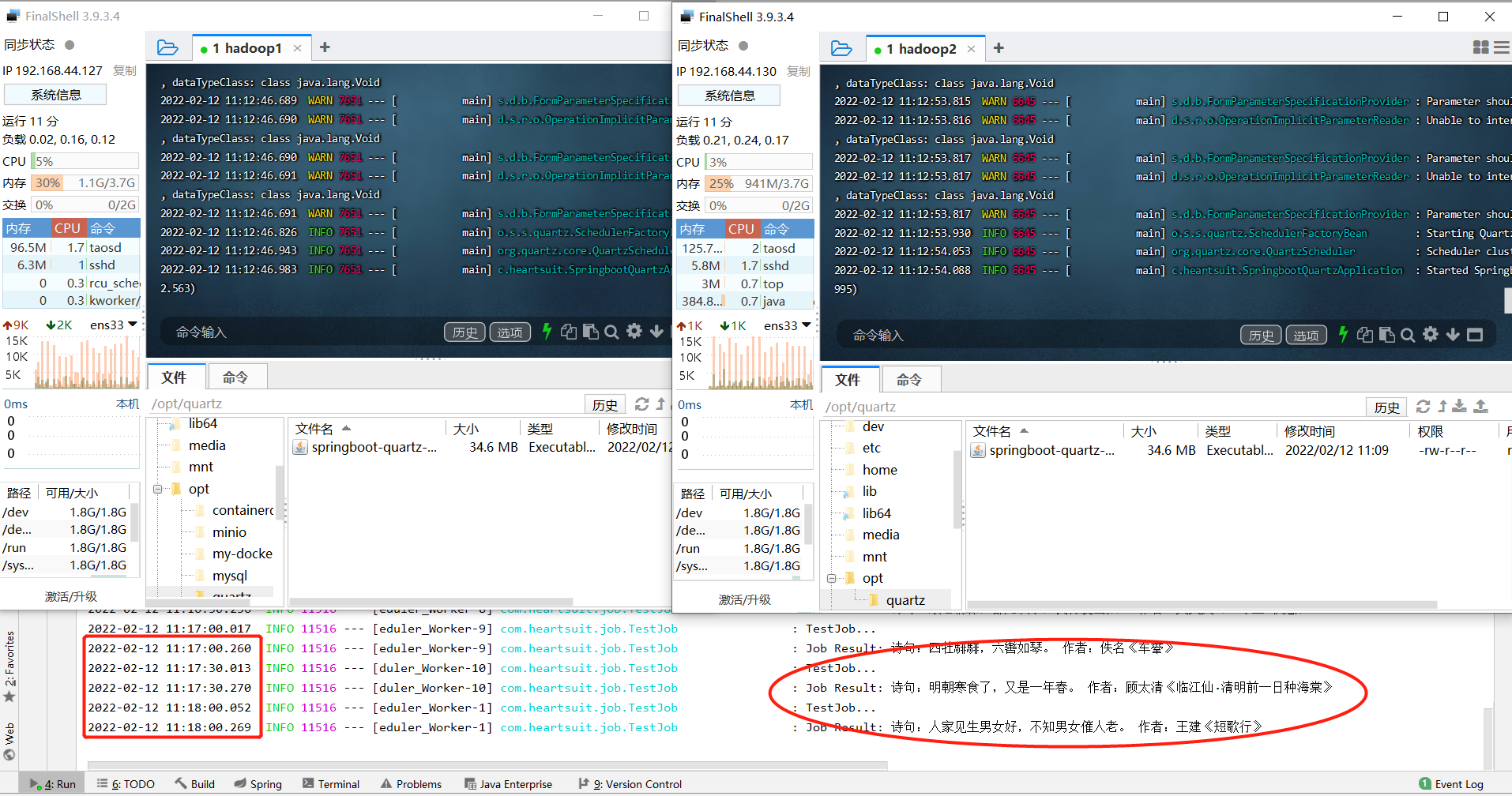
- Close the service instance that performs the task
After closing the service instance executing the task (here is instance A in the development environment), through Quartz cluster scheduling, we find that one of the remaining two instances (instance C) has detected the suspended instance. The log is as follows, and then the task switches to instance C for continuous execution.
2022-02-12 11:19:54.322 INFO 6645 --- [_ClusterManager] o.s.s.quartz.LocalDataSourceJobStore : ClusterManager: detected 1 failed or restarted instances. 2022-02-12 11:19:54.322 INFO 6645 --- [_ClusterManager] o.s.s.quartz.LocalDataSourceJobStore : ClusterManager: Scanning for instance "LAPTOP-R62OPABO1644635550243"'s failed in-progress jobs.
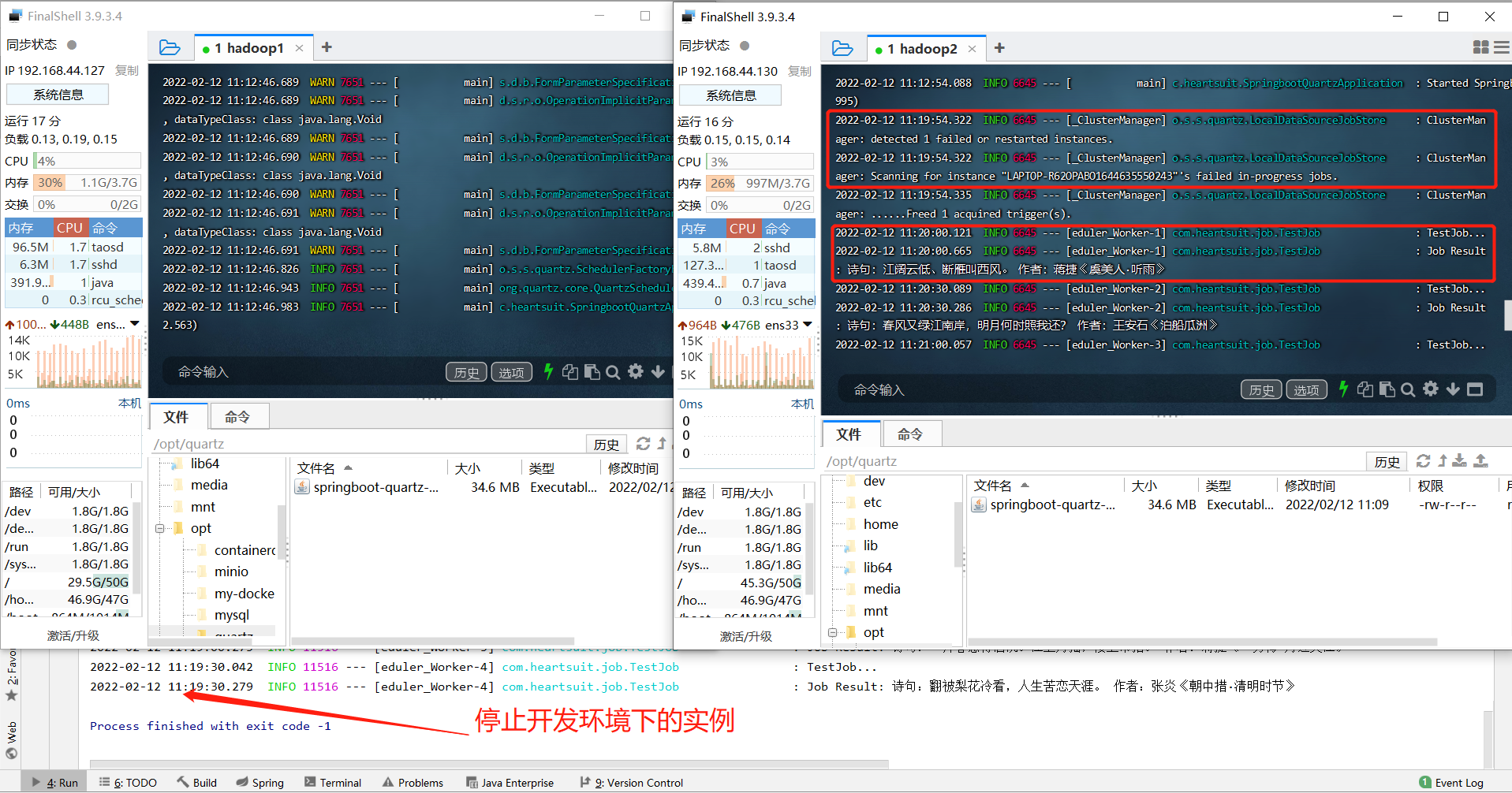
- Close the service instance that executes the task again
After we close the service instance that executes the task again (here is instance C), through Quartz cluster scheduling, we find that the task will automatically switch to the remaining instance B to continue execution.
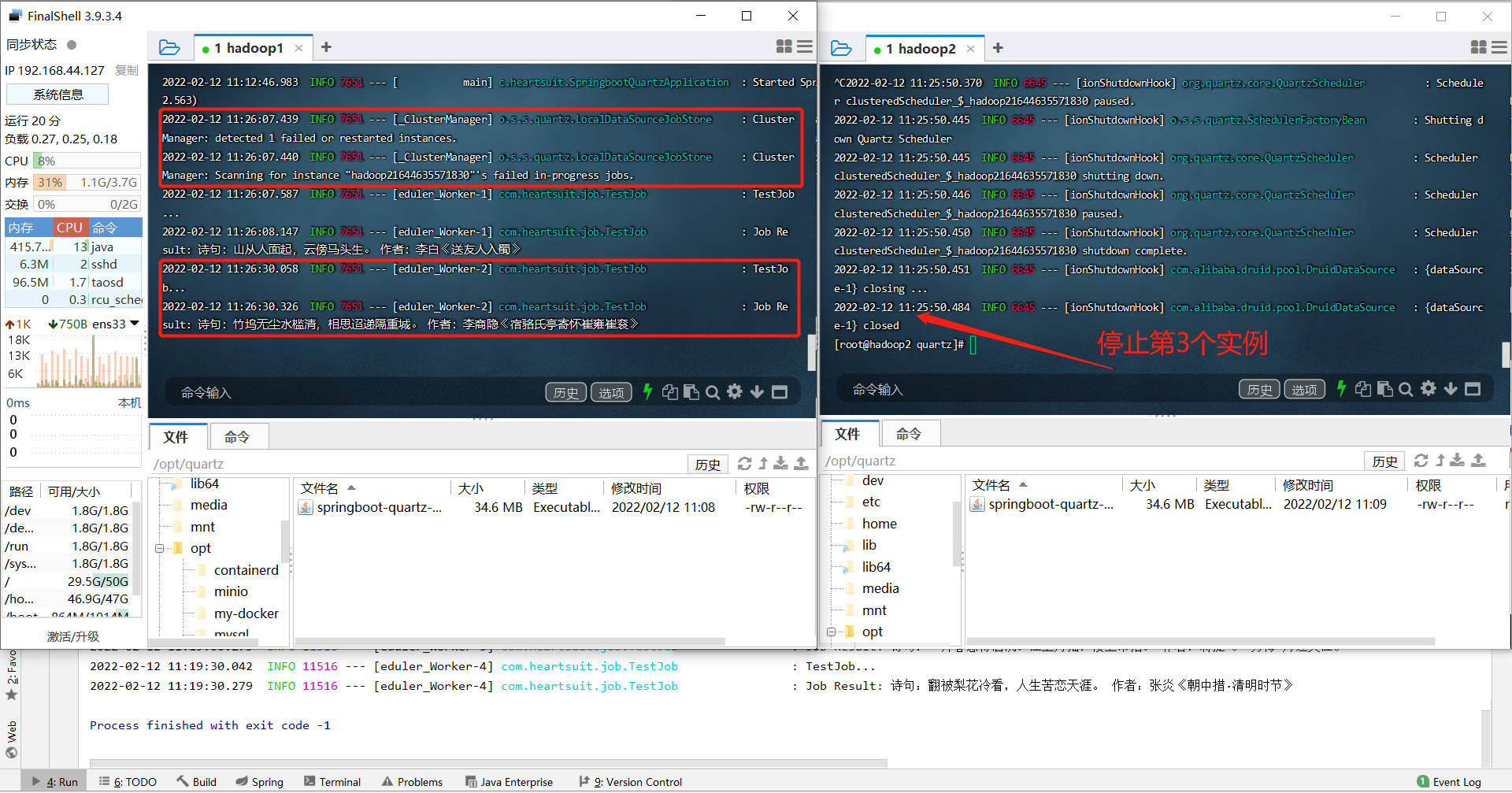
So far, we can draw a conclusion:
- Quartz timed task cluster service scheduling does not balance the load between different instances in the cluster like other middleware, but is continuously executed on one of them;
- Once it is detected that a service instance stops running, the task will switch to the normally running service instance to continue execution, which realizes the effect that no matter how many application instances there are in the cluster, the scheduled task will only be triggered once. At the same time, we have a distributed task scheduling cluster with failover.
Structure of official data sheet
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
#
# By: Ron Cordell - roncordell
# I didn't see this anywhere, so I thought I'd post it here. This is the script from Quartz to create the tables in a MySQL database, modified to use INNODB instead of MYISAM.
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(190) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_BLOB_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_CALENDARS (
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(190) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME))
ENGINE=InnoDB;
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_FIRED_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(190) NULL,
JOB_GROUP VARCHAR(190) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB;
CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB;
CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
commit;
If you have any questions or any bugs are found, please feel free to contact me.
Your comments and suggestions are welcome!