"The value of the container itself is very limited. What is really valuable is the container arrangement."
Containers and processes
docker uses the Namespace mechanism to modify the process space of isolated applications. The system call to create a thread in Linux is clone()
int pid = clone(main_function, stack_size, SINCHLD, NULL);
This system call will create a new process for us and return its PID.
When we use the clone system to call a to create a new process, we can specify clone in the parameter_ NEWPID(PID namespaces).
int pid = clone(main_function, stack_size, CLONE_NEWPID, NULL)
Open up a new process space, PID is 1. But the real PID still hasn't changed.
In fact, when you create a container process, you specify a set of Namespace parameters that the process needs to enable.
Therefore, the container is actually a special process.
Isolation and limitation
docker's isolation technology is the technical means of the Linux kernel, Namespace.
Compared with docker, the hypervisor is responsible for the isolation environment of the application process and will not create any entity "container". What is really responsible for the isolation environment is the operating system of the host. Docker is more of a bypass type of auxiliary and management work.
However, the problem of container isolation still exists. Multiple containers share an operating system kernel. It is also not feasible for a lower version Linux host to run a higher version Linux container.
In the Linux kernel, there are many resources and objects that cannot be Namespace, such as system time. When we modify the time in the container, the system time also changes. So when we use containers, we must consider "what we can do and what we can't do".
Therefore, in the production environment, no one exposes the container to the public network.
docker's restriction technology is Linux Cgroups, which is an important function used to set resource restrictions for processes. The resources restricted by Cgroups include CPU, memory, disk, bandwidth, etc.
Cgroup can also set priority, audit, suspend and resume processes.
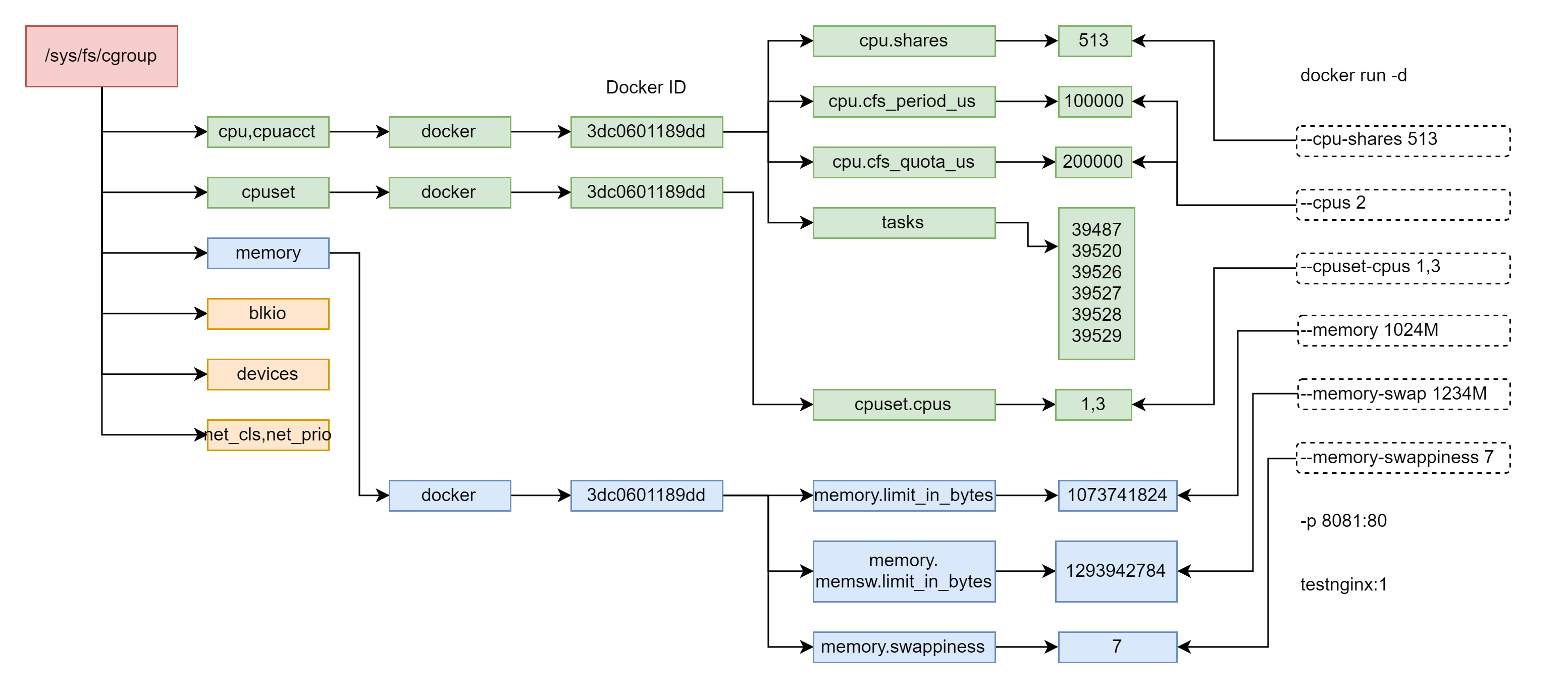
In Linux, the operating interface exposed by Cgroup to users is the file system, that is, it is organized in the path of / sys/fs/cgroup of the operating system in the form of files and directories.
CPU subsystem, which mainly limits the CPU utilization of processes.
- cpuacct subsystem can count the CPU usage reports of processes in cgroup.
- cpuset subsystem can allocate separate CPU nodes or memory nodes for processes in cgroup.
- Memory subsystem, which can limit the memory usage of processes.
- blkio subsystem, which can limit the block device IO of the process.
- Devices subsystem, which can control processes and access some devices. net_cls subsystem can mark the network packets of processes in cgroups, and then use tc module (traffic control) to control the packets.
- freezer subsystem, which can suspend or restore processes in cgroup.
The following is the directory of cgroup:
[root@jenkins test2]# ls /sys/fs/cgroup/ blkio/ cpu,cpuacct/ freezer/ net_cls/ perf_event/ cpu/ cpuset/ hugetlb/ net_cls,net_prio/ pids/ cpuacct/ devices/ memory/ net_prio/ systemd/
File system directory:
[root@jenkins test2]# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
Configuration file of CPU subsystem:
[qtec@localhost ~]$ ls /sys/fs/cgroup/cpu cgroup.clone_children cpuacct.usage_percpu cpu.stat cgroup.event_control cpu.cfs_period_us notify_on_release cgroup.procs cpu.cfs_quota_us release_agent cgroup.sane_behavior cpu.rt_period_us tasks cpuacct.stat cpu.rt_runtime_us cpuacct.usage cpu.shares
There's a CPU cfs_quota_ Us and CPU rt_ period_ us. The two need to be used in combination, which can limit the length of the process to CFS_ During a period of time, it can only be allocated to CFS in total_ CPU time of quota. CPU utilization ratio: cfs_quota/cfs_period.
Simply put: CPU cfs_ period_ Us is the running cycle, CPU cfs_ quota_ Us is how much time these processes take in the cycle.
The relevant control of CPU is in cpuacct Directory:
[qtec@localhost ~]$ ls /sys/fs/cgroup/cpuacct/ cgroup.clone_children cpuacct.usage_percpu cpu.stat cgroup.event_control cpu.cfs_period_us notify_on_release cgroup.procs cpu.cfs_quota_us release_agent cgroup.sane_behavior cpu.rt_period_us tasks cpuacct.stat cpu.rt_runtime_us cpuacct.usage cpu.shares
The restrictions of cgroup on Docker and the performance of user status: