The title is well chosen, and gentlemen are indispensable. A good title can bring more readers. The title is the first thing a potential audience sees before deciding whether to read an article. As a data scientist, I decided to make a model to help me generate these titles using GPT2.
data
I made a csv file that contains my in medium The best data science articles in various tags captured by Parsehub on the. Com website. The csv file contains information about the title of the article, the tags used, the author, the number of points, the number of replies, and so on. This dataset is available on Kaggle and is called medium search dataset.
task
My task is to make a text generator to generate coherent article titles. I will use the Transformers library for preprocessing and model building, and then I will use PyTorch Lightning to fine tune the model.
Installing Transformers
Use the following command to install Transformers.
pip install transformers
You can view the complete code on Kaggle and Github (the link is provided at the end). I recommend running this notebook on Kaggle instead of the local machine, because Kaggle has installed most of the dependencies in the environment. Python lightning will be used as a wrapper class to speed up model construction.
Run the cells below to ensure that all required packages are installed. If you don't install all the packages, it will throw an error.
from transformers import GPT2LMHeadModel, GPT2Tokenizer,AdamW import pandas as pd from torch.utils.data import Dataset , DataLoader import pytorch_lightning as pl from sklearn.model_selection import train_test_split
data
df = pd.read_csv("../input/mediumsearchdataset/Train.csv")
df

I will download gpt2 large. Its size is 3 GB, which is why I recommend using a remote notebook like Kaggle.
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-large")
gpt2 = GPT2LMHeadModel.from_pretrained("gpt2-large")

Before fine tuning, you can test the GPT2 model
tokenizer.pad_token = tokenizer.eos_token
prompt = tokenizer.encode("machine learning", max_length = 30 , padding = "max_length" , truncation = True , return_tensors = "pt")
output = gpt2.generate(prompt,do_sample = True, max_length = 100,top_k = 10, temperature = 0.8)
tokenizer.decode(output[0] , skip_special_tokens = True)
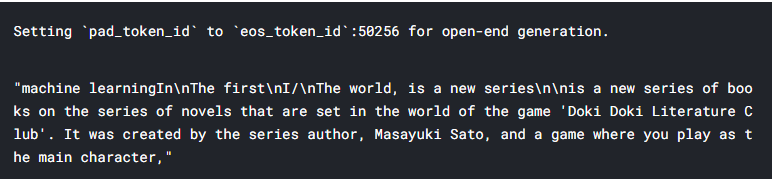
As we can see, the model does generate text on the "machine learning" we enter, but it generates too much worse than the title. In the following sections, we will fine tune the model to produce better text.
Next, we will customize a dataset, which will create a tokenized title and send it to the dataset.
class TitleDataset(Dataset):
def __init__(self,titles):
self.tokenizer = tokenizer
self.titles = titles
def __len__(self):
return len(self.titles)
def __getitem__(self,index):
title = self.titles[index]
title_token = tokenizer.encode(title , max_length = 30 , padding = "max_length" , truncation = True, return_tensors = "pt").reshape(-1)
return title_token
#sanity check
dset = TitleDataset(df["post_name"].values)
title = next(iter(DataLoader(dset , batch_size = 1,shuffle = True)))
display(title)

class Quadratic_Module(pl.LightningDataModule):
def __init__(self):
super().__init__()
self.train_dataset = Quadratic_Dataset(path = train_df["id"].values , targets = train_df[["a_","b_", "c_"]].values)
self.test_dataset = Quadratic_Dataset(path = test_df["id"].values , targets = test_df[["a_","b_" , "c_"]].values)
self.val_dataset = Quadratic_Dataset(path = val_df["id"].values , targets = val_df[["a_","b_" , "c_"]].values)
self.predictions = Quadratic_Dataset(path = test_df["id"].values , targets = None)def prepare_data(self) :
pass
def train_dataloader(self):
return DataLoader(self.train_dataset , batch_size = 32 , shuffle = True)def test_dataloader(self):
return DataLoader(self.test_dataset , batch_size = 32 , shuffle = False)def val_dataloader(self):
return DataLoader(self.val_dataset , batch_size = 32 , shuffle = False)
def predict_dataloader(self):
return DataLoader(self.predictions , batch_size = 1 , shuffle = False)
The above are some auxiliary functions for data reading to help us generate dataloader
When the text is passed to GPT2, it will return the loss of output logits and model, because this is required by pytorch lighting.
class TitleGenerator(pl.LightningModule):
def __init__(self):
super().__init__()
self.neural_net = gpt2_model
def forward(self,x):
return self.neural_net(x , labels = x)
def configure_optimizers(self):
return AdamW(self.parameters(), 1e-4)
def training_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
def test_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
def validation_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
train
Fine tuning the GPT2 model takes a long time. I recommend using GPU (if available). Lightning allows us to declare the GPU in the trainer while processing the rest. 6 rounds of training should take about 30 minutes.
from pytorch_lightning import Trainer model = TitleGenerator() module = TitleDataModule() trainer = Trainer(max_epochs = 6,gpus = 1) trainer.fit(model,module)

After the training, it can be tested and predicted
If you plan to deploy your code to production, I don't recommend doing so because it may lead to errors. The following code is a quick way to change the weight of the original model, but she will have some problems.
raw_text = ["The" ,"machine Learning" , "A" , "Data science" , "AI" , "A" , "The" , "Why" , "how"]
for x in raw_text:
prompts = tokenizer.encode(x , return_tensors = "pt")
outputs = gpt2.generate(prompt,do_sample = True, max_length = 32,top_k = 10, temperature = 0.8)
display(tokenizer.decode(outputs[0] , skip_special_tokens = True))

Final description
I will deploy the model as an API, but the model is over 3 GB, so it really doesn't make sense to host it on the website. You can also try to upload the model to the Huggingface hub after fine-tuning.
The code address is here: https://github.com/Aristotle609/Medium-Title-Generator
Or directly fork the kaggle Code: https://www.kaggle.com/aristotle609/medium-titles-generator
To the Huggingface hub.
The code address is here: https://github.com/Aristotle609/Medium-Title-Generator
Or directly fork the kaggle Code: https://www.kaggle.com/aristotle609/medium-titles-generator
Author: Aristotle Fernandes