2021SC@SDUSC
We continue to analyze the remaining key code of the evaluate() function.
final_scores = self.score(ref, hypo)
Final here_ Scores saves the final evaluation score according to the three evaluation methods mentioned in the previous blog. Here, the score function is called, which is the class function of Evaluate. The code is as follows:
def score(self, ref, hypo):
final_scores = {}
for scorer, method in self.scorers:
score, scores = scorer.compute_score(ref, hypo)
if type(score) == list:
for m, s in zip(method, score):
final_scores[m] = s
else:
final_scores[method] = score
return final_scoresThe parameters ref and hypo are two sets, which are evaluated and scored circularly, and compute is called_ The score function has compute in all three evaluation methods_ Score, let's look at BLEU first:
def compute_score(self, gts, res):
bleu_scorer = BleuScorer(n=self._n)
for id in sorted(gts.keys()):
hypo = res[id]
ref = gts[id]
assert(type(hypo) is list)
assert(len(hypo) == 1)
assert(type(ref) is list)
assert(len(ref) >= 1)
bleu_scorer += (hypo[0], ref)
score, scores = bleu_scorer.compute_score(option='closest', verbose=0)
return score, scoresBleuScorer is a class with complex parameters and functions. After a general understanding, it is the implementation of BLEU evaluation method, and finally BLEUn is obtained.
For a sentence to be translated, the candidate translation (i.e. machine translation) can be expressed as Ci, and the corresponding reference translation can be expressed as Si={Si1, Si2, Si3,...} (multiple sets of reference answers). The calculation method of BLEU is as follows:

Reference blog:
Summary of machine translation evaluation criteria - Zhihu
Rouge's compute_ The code of score function is as follows:
def compute_score(self, gts, res):
score = []
for id in sorted(gts.keys()):
hypo = res[id]
ref = gts[id]
score.append(self.calc_score(hypo, ref))
assert(type(hypo) is list)
assert(len(hypo) == 1)
assert(type(ref) is list)
assert(len(ref) > 0)
average_score = np.mean(np.array(score))
return 100*average_score, np.array(score)The final return is a percentage. Simply put, ROUGE-L mainly calculates the F-measure of the longest common subsequence (LCS). The following figure is the calculation method of ROUGE-L. 10. Y represents the model generated sentences and reference translations. m. n represents their length respectively. When there are multiple reference translations, the highest score is selected as the final evaluation score.
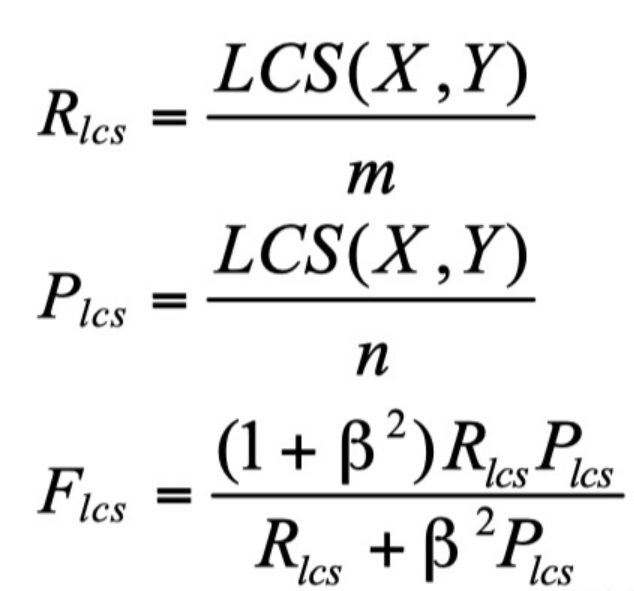
Reference paper: [1] Rouge: a package for automatic evaluation of summaries chin yew Lin Information Sciences Institute University of Southern California 4676 Admiralty way Marina del Rey, CA 90292 cyl@isi.edu https://aclanthology.org/W04-1013.pdf https://aclanthology.org/W04-1013.pdf
https://aclanthology.org/W04-1013.pdf
Meteor's compute_ The score code is as follows:
def compute_score(self, gts, res):
imgIds = sorted(list(gts.keys()))
scores = []
eval_line = 'EVAL'
self.lock.acquire()
for i in imgIds:
assert(len(res[i]) == 1)
hypothesis_str = res[i][0].replace('|||', '').replace(' ', ' ')
score_line = ' ||| '.join(('SCORE', ' ||| '.join(gts[i]), hypothesis_str))
self.meteor_p.stdin.write(score_line + '\n')
stat = self.meteor_p.stdout.readline().strip()
eval_line += ' ||| {}'.format(stat)
self.meteor_p.stdin.write(eval_line + '\n')
for i in range(len(imgIds)):
score = float(self.meteor_p.stdout.readline().strip())
scores.append(score)
final_score = 100*float(self.meteor_p.stdout.readline().strip())
self.lock.release()
return final_score, scoresHere, we mainly use the meteor method to score. It involves many class functions in the meteor class. It is not the key code of evaluate itself. It is mainly the code completed according to the meteor method. We make word to word mapping in model generated sentences and reference answer sentences. There are three mapping criteria: same word mapping, stem mapping and synonym mapping.
We take any criterion for mapping, but list all the mapping results. If the word "computer" appears once in the model generated sentence and twice in the reference sentence, we need to connect two lines. After obtaining all the mapping results, we need to select the mapping results of a combination method, that is, we only allow one word to be connected by at most one line (this is a bit like bipartite graph matching in the algorithm to find the maximum matching). When there are several schemes with the same maximum matching number, we choose the scheme with the smallest number of line crossings in this bipartite graph. METEOR establishes mapping relationships in stages. By default, it is divided into three stages: the first stage uses the same word mapping (exact) to connect, the second stage uses the stem mapping (porter stem), and the third stage uses the synonym mapping (WN synonymy). The latter stage only complements the mapping of the previous stage and does not modify the mapping decision of the previous stage. It can also be seen from the default phase order here that the mapping establishment conditions in the later phase are always more relaxed than those in the previous phase.
Reference paper: [2] meteor: an automatic metric for MT evaluation with improved correlation with human judgments satanjeev Banerjee alon Lavie Language Technologies Institute Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213 Pittsburgh, PA 15213 Banerjee + @ CS cmu. edu alavie@cs.cmu.edu
After the evaluation of the three methods, the final score is obtained_ Score, the evaluation of the generated text is completed.