PyTorch Lightning is windy recently. Let's see why it's so hot 🔥
This article is mainly about what pytorch lighting is, what its advantages are, and the main structure of the code. Specific details and cases are given later.
1 what is pytorch lighting

PyTorch lighting (pl for short) is actually a lightweight PyTorch library and a lightweight PyTorch wrapper for high-performance artificial intelligence research. Scale your model, not the template.
It clearly abstracts and automates all the everyday boilerplate code that comes with the ML model, allowing you to focus on the actual ml parts (which are often the most interesting). In addition to automation template code, Lightning can also be used as a style guide to build a clean and reproducible ml system.
Pytorch and pl are essentially the same code. However, pytorch needs to build its own wheels (such as model, dataloader, loss, train, test, checkpoint, save model, etc.), and pl has structured these modules (similar to keras).
See the difference between the two from the picture below

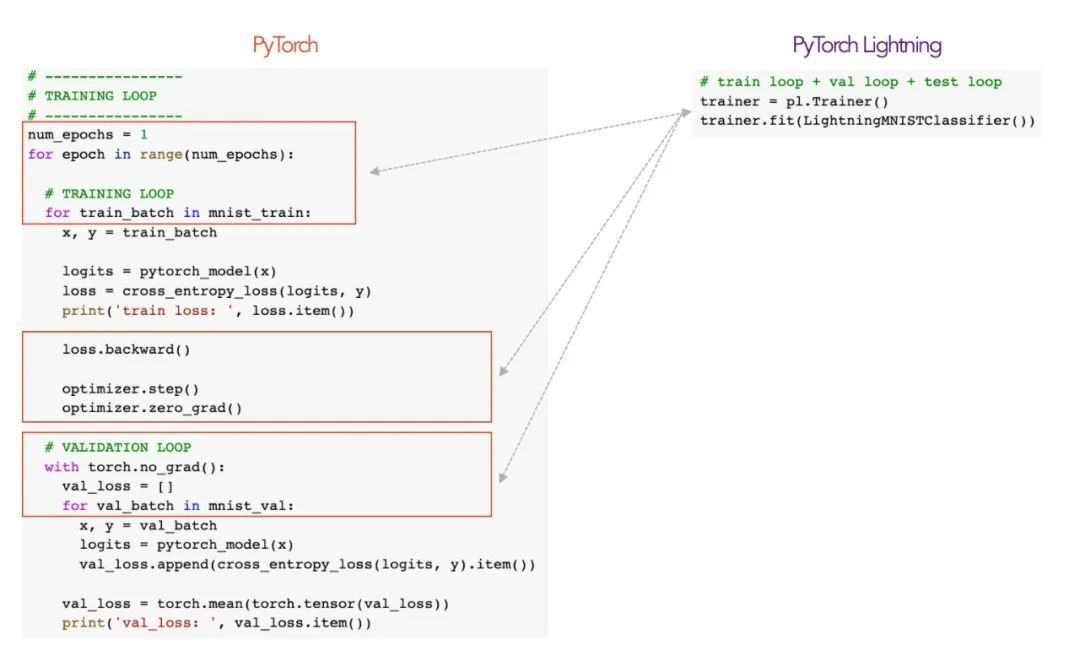
From the above, we can find three advantages of pl
- By abstracting the template engineering code, it is easier to identify and understand the ML code.
- Lightning's unified structure makes it easy to build and understand on the basis of existing projects.
- Lightning automated code is built from high-quality code that has been fully tested, regularly maintained, and follows ML best practices.
Conclusion: Python lightning can build deep learning code very succinctly. But in fact, most people don't use many complex functions. And PL sometimes the packaging is too deep, and it is a little inflexible when using. Generally speaking, after your model is built, most of the functions will be encapsulated in a class called trainer. Some troublesome but required functions are usually as follows, which can be well realized through pl:
- Save checkpoints
- Output log information
- resume training means heavy load training. We hope we can continue training after the last epoch
- Record the process of model training (usually using tensorboard)
- Set seed to ensure that the training process can be copied
2 how to organize PyTorch code into Lightning
Use PyTorch Lightning to organize your code 1:
- Retain all flexibility (this is all pure PyTorch), but remove a large number of templates
- Decouple the research code from the project, which is more readable
- Easier to copy
- By automating most training cycles and tricky engineering design, error prone situations are reduced
- Scalable to hardware model without any changes
The official website provides a 3-minute comparison video of python code to pl code, which introduces the corresponding relationship between each module in detail. Detail stamp link
The screenshot of the video is as follows:


2.1 installation of PyTorch Lightning
Installation via pip
pip install pytorch-lightning
Install via conda
conda install pytorch-lightning -c conda-forge
Installed in the specified conda environment
conda activate my_env pip install pytorch-lightning
Import related packages after installation
import os import torch from torch import nn import torch.nn.functional as F from torchvision import transforms from torchvision.datasets import MNIST from torch.utils.data import DataLoader, random_split import pytorch_lightning as pl
2.1 definition of LightningModule
class LitAutoEncoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28*28)
)
def forward(self, x):
# in lightning, forward defines the prediction/inference actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defined the train loop.
# It is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
# Logging to TensorBoard by default
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
Define init (self): define the network architecture (model); def forward(self, x): defines the forward propagation of reasoning and prediction; def training_step(self, batch, batch_idx): define train loop; def configure_optimizers(self): defines the optimizer
Therefore, lightning module defines a system rather than a simple network architecture.
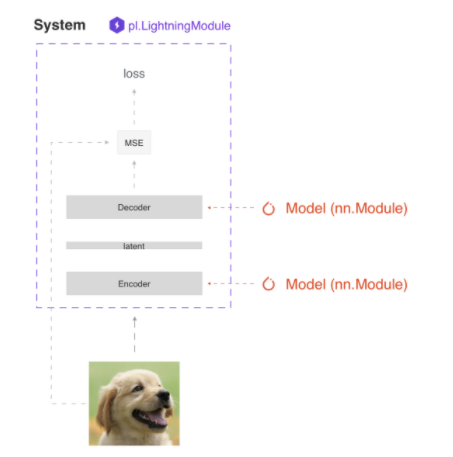
As for how to write specific tasks in this system (such as Autoencoder, BERT, DQN, GAN, Image classifier, Seq2seq, SimCLR, VAE), the official website gives different cases. ( https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html )
2.2 Fit with Lightning Trainer
I don't know how to translate the corresponding Chinese properly. It means to feed the parameters required by the Trainer to it.
# init model autoencoder = LitAutoEncoder() # most basic trainer, uses good defaults (auto-tensorboard, checkpoints, logs, and more) # trainer = pl.Trainer(gpus=8) (if you have GPUs) trainer = pl.Trainer() trainer.fit(autoencoder, train_loader)
Here's the trainer Fit receives two parameters, including model and dataloader Then it began to train itself~~~~
trainer is automated and includes:
- Epoch and batch iteration
- Automatically call optimizer step(), backward, zero_ grad()
- Automatic call eval(), enabling/disabling grads
- Weight loading
- Save log to tensorboard
- Support multi GPU
- TPU
- Support AMP
Some reference links
https://cloud.tencent.com/developer/article/1593703
https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html
https://github.com/PyTorchLightning/pytorch-lightning

https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html ↩︎