Today's content
- GIL global interpreter lock (important theory)
- Verify the existence and function of GIL
- Verify whether python multithreading is useful
- Deadlock phenomenon
- Process pool and thread pool (frequently used)
- IO model
Detailed reference: https://www.bilibili.com/video/BV1QE41147hU?p=500
Detailed content
1, GIL global interpreter lock
1. Introduction
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython's memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
''' 1,python There are many versions of the interpreter, but the default is Cpython Cpython,Jpython,pypython stay Cpython in GIL The global interpreter lock is also a mutex lock, which is mainly used to prevent multiple threads from being executed at the same time in the same process python Multithreading cannot use the multi-core advantage, and threads cannot be parallel) GIL Must exist in Cpython Yes, because Cpython The interpreter's memory management is not linear safe. 2,Memory management is the garbage collection mechanism Reference count Clearly marked Generation recycling '''
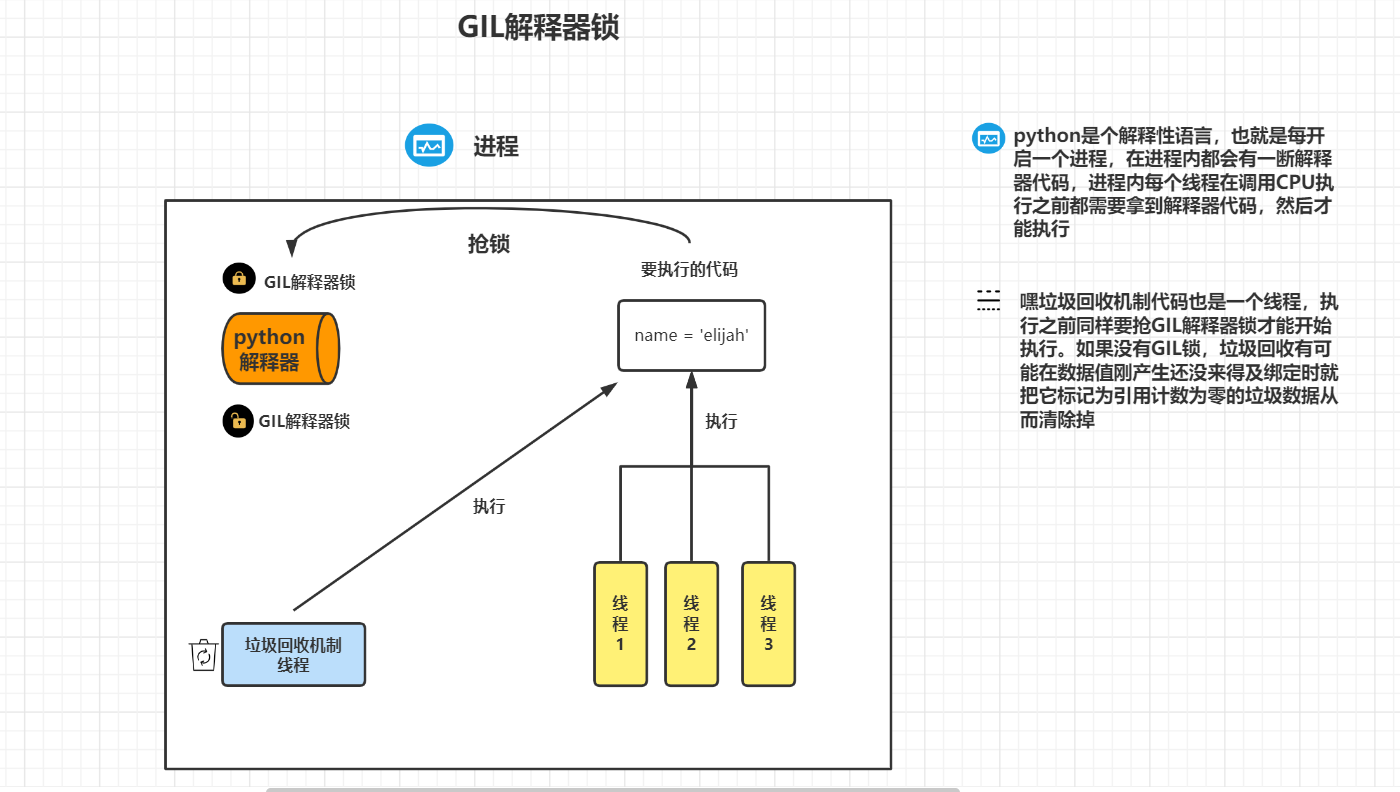
1. GIL is a feature of Cpython interpreter
2. python multiple threads in the same process cannot use the multi-core advantage (cannot be parallel but can be concurrent)
3. If multiple threads in the same process want to run, they must grab the GIL lock first
4. Almost all interpretative languages cannot run multiple threads in the same process at the same time
2. Verify the existence of GIL
If there is no IO operation for multiple threads in the same process, there will be no parallel effect due to the existence of GIL
However, if there are IO operations in the thread, the data will still be disordered. At this time, we need to add additional mutexes
# No IO
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3)
print(m)
# Result 0
# IO operation occurred: time sleep(1)
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
time.sleep(1) < -- IO
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3)
print(m)
# Results print in 4 seconds 99
2, Deadlock phenomenon
Mutexes cannot be used at will, otherwise they are prone to deadlock:
After thread 1 finishes executing fun1 function, it starts to execute func2 function and grabs the B lock,
But at this time, thread 2 also starts to execute func1 and grabs the A lock,
At this time, thread 1 cannot grab lock A and stop in place, and thread 2 cannot grab lock B and stop in place
from threading import Thread, Lock
import time
A = Lock()
B = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A.acquire()
print('%s Got it A lock' % self.name) # current_thread().name get thread name
B.acquire()
print('%s Got it B lock' % self.name)
time.sleep(1)
B.release()
print('%s Released B lock' % self.name)
A.release()
print('%s Released A lock' % self.name)
def func2(self):
B.acquire()
print('%s Got it B lock' % self.name)
A.acquire()
print('%s Got it A lock' % self.name)
A.release()
print('%s Released A lock' % self.name)
B.release()
print('%s Released B lock' % self.name)
for i in range(10):
obj = MyThread()
obj.start()
"""Even if you know the characteristics and usage of the lock, don't use it easily, because it is easy to cause deadlock"""
3, Is python multithreading useless?
Is python multithreading useless?
(python's multi-process can take advantage of multi-core, and multi threads in the same process cannot take advantage of multi-core because of the existence of GIL)
This depends on the situation. It mainly depends on whether the code is IO intensive or computing intensive
-
IO intensive:
There are a large number of IO operations in the code. In case of IO operations, the CPU will switch to other threads to run according to multi-channel technology
-
Compute intensive:
There is no IO operation in the code, and the running speed is fast and the time is short. The CPU will not switch, so the multi-core advantage cannot be used
# Whether it is useful depends on the situation (type of program)
# IO intensive
eg:Four tasks, each taking 10 minutes s
Opening multiple processes does not have much advantage 10s+
encounter IO You need to switch and set up the process. You also need to apply for memory space and copy code
Multithreading has advantages
No need to consume additional resources 10 s+
# Compute intensive
eg:Four tasks Each task takes 10 minutes s
Multi process can take advantage of multi-core 10s+
Setting up multithreading can not take advantage of multi-core 40 s+
"""
Multi process and multi thread
"""
"""IO Intensive"""
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #This machine is 4-core
start=time.time()
for i in range(400):
p=Process(target=work) #It takes more than 22.31s, and most of the time is spent on the creation process
# p=Thread(target=work) #It takes more than 2.08s
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
"""Compute intensive"""
(Using multiple threads in the same process will run longer)
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) # This machine is 6-core
start=time.time()
for i in range(6):
# p=Process(target=work) #It takes more than 5.35s
p=Thread(target=work) #It takes more than 23.37s
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
4, Process pool and thread pool
The appearance of process pool and thread pool reduces the execution efficiency of code, but ensures the safety of computer hardware
reflection:Can I open processes or threads without restrictions???
It must not be opened without restrictions
If only from the technical level, unlimited opening is certainly possible and the most efficient
But from the hardware level, it is impossible to achieve(The development of hardware can never catch up with the development of software)
pool
On the premise of ensuring that the computer hardware does not collapse, multi process and multi thread are set up
It reduces the running efficiency of the program, but ensures the safety of computer hardware
Process pool and thread pool
Process pool:Set up a fixed number of processes in advance, and then call these processes repeatedly to complete the work(No new business will be opened in the future)
Thread pool:Set up a fixed number of threads in advance, and then call these threads repeatedly to complete the work(No new business will be opened in the future)
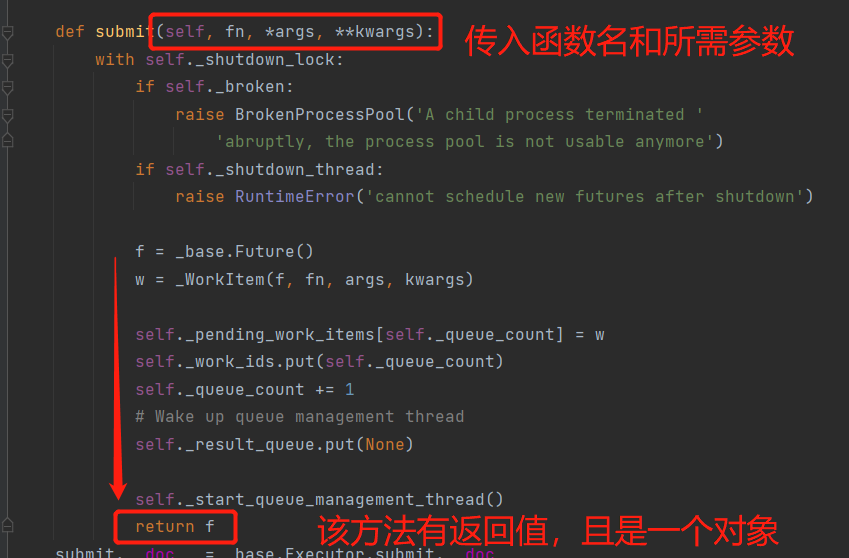
Create thread pool
Note: when starting multithreading and multiprocessing, if you encounter the operation of synchronous task submission, such as join and With resutl, you can start all processes (threads) first, and then call their synchronization operations one by one
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import time
import os
def run():
print('Start operation')
index = 10
time.sleep(0.3)
for i in range(10):
index += i
return 'The result is: %s' % index
if __name__ == '__main__':
print('Local machine CPU quantity: %s' % os.cpu_count())
# Start 10 threads, first submit all tasks to the thread pool (asynchronous submission), and then put the obtained operation objects into the list for subsequent calls result() method (synchronous submission)
t_list = []
# p = ProcessPoolExecutor() creates a process pool. The default number of processes is the number of CPU s of the machine
t_pool = ThreadPoolExecutor() # Create a thread pool. The default number of threads is the number of native CPU s multiplied by 5
for i in range(10):
# After creating the thread, you need to submit the function
t = t_pool.submit(run) # The asynchronous submit() method returns a thread object
t_list.append(t)
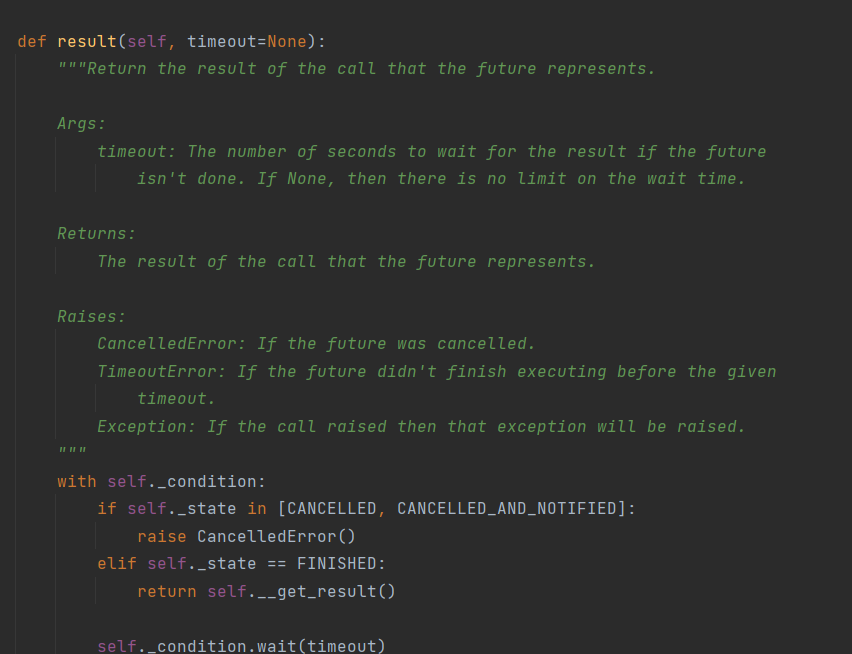
for t in t_list:
ret = t.result() # The task submitted synchronously needs to have a return value
print(ret)
# Operation results
Local machine CPU quantity: 4
Start operation
Start operation
Start operation
Start operation
Start operation
Start operation
Start operation
Start operation
Start operation
Start operation
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55
The result is: 55