preface
This night is destined to be a sleepless night. The dialogue between Xiaobai and cangls has become white hot. Xiaobai tirelessly consulted about git and became more and more interested in indexing. The versions of Xiaobai's previously saved small movie files can be compared to explore which version has better picture quality.
Xiaobai: cangls, I'm a little confused recently.
cangls: what are the specific aspects?
Xiaobai: Recently, there are some requirements. I need to manage and control the version of documents, but some problems are beyond my comprehension.
cangls: I'm familiar with version management. I've been summarizing a series of articles recently. After reading it, I believe it will help you.
Linus Torvalds said in Git mailing list that you can't fully understand the power of GIT without understanding the purpose of indexing first.
This article is the second bullet of personal git series articles, the file management and indexing that git has to understand. Git's index does not contain any file content. It only tracks what you want to submit. When the git commit command is executed, GIT will find the submitted content by checking the index instead of the working directory. Although git handles a lot of things for us at the bottom, it is also important to remember the index and its state. At any time, you can query the status of the index through the git status command.

text
One of the classic problems of VCS is that file renaming will cause them to lose tracking of file history. Git can retain historical information even after renaming. In actual work, it seems that git system handles file renaming a little better. Because git has many ways to rename a file (for example, using git rm with git add and git mv), but the previous level is not enough to ensure that SVN knows all the information. However, there is no file system that can handle renaming perfectly.
1, git file classification
1. git file classification
git divides all files into three categories: tracked, ignored and untracked, as shown in the figure below.
graph git File classification in --> Tracked Tracked git File classification in --> Ignored Ignored git File classification in --> Untraceable Untracked
1.1 Tracked
Tracked files refer to files already in the version library or files that have been temporarily stored in the index. If you want to add a new file newfile to a tracked file, execute the git add newfile command. For example, temporary index HTML file.
git add index.html
1.2. Ignored
The ignored file must be explicitly declared invisible or ignored in the version library, even if it may appear in your working directory. A software project usually has many times ignored files (small partners who have used SVN to develop Java are familiar with it. We can choose which fixed files to ignore and not submit when submitting). Commonly ignored files include temporary files, personal notes, compiler output files, and most files automatically generated during the construction of the project. Git maintains a list of files that are ignored by default. You can also configure the version library to identify other files.
1.3 Untracked
Untraceable files are those that are not in the first two categories. Git takes all files in the working directory as a collection, subtracts the tracked files and ignored files, and the rest is the Untracked files.
Here, a repository named test directory is initialized, which originally contains a demo-1-0.0.1-snapshot Jar file. But I didn't temporarily store it or add it to the version library. As you can see below, Untracked files are displayed.
$ git status
HEAD detached at bd156ab
Untracked files:
(use "git add <file>..." to include in what will be committed)
demo-1-0.0.1-SNAPSHOT.jar
nothing added to commit but untracked files present (use "git add" to track)
For demonstration purposes, a sky working directory is reinitialized. Test and verify these different categories of files by creating a new working directory and version library and processing some files.
#Initial warehouse sky
$ git init
Initialized empty Git repository in D:/work/sky/.git/
#View status
$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
#Input data into the sky file in the sky warehouse
echo "new data" >> sky
#Check the status again and display an untraceable file sky
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
sky
nothing added to commit but untracked files present (use "git add" to track)
At first, there are no files in the directory. The tracked files and ignored files are empty, so the untracked files are also empty. Once a sky file is created, git status reports an untraceable file.
Editors and build environments often leave temporary files around source files. In the version library, these files should not be tracked as source files. In order for Git to ignore files in the directory, just add the file name to a special file Gitignore. Manually create a test garbage file test o. Then put it in Maintain in gitignore file. The following is an example of the demonstration process:
#Manually create a test garbage file
$ touch test.o
#View the status. It is not added to the ignore file for maintenance at this time
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
sky
test.o
nothing added to commit but untracked files present (use "git add" to track)
#Add to ignore file gitignore, then check the status and compare it with the previous one
$ echo test.o > .gitignore
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
sky
nothing added to commit but untracked files present (use "git add" to track)
Through the above series of operations, test O has been ignored, but git status now shows a new untraceable file gitignore. Although Gitignore files have special meaning for Git, but they are managed in the same way as any other common files in the version library. Unless you will Gitignore file is added to the index, otherwise Git will still treat her as an untraceable file. The following shows different ways to change the tracking status of a file and how to add or remove it from the index.
2, git add command
Review git add usage
#Add a new working directory test $ mkdir test #Initialize a warehouse git init #Temporary test MD file git add test.md
Note: in the process of temporary storage, you will find the command git diff very useful. This command can show two different sets of differences. Git diff shows the changes that remain in the working directory and are not temporarily stored; git diff --cached shows the changes that have been staged and therefore need to be helpful for the next submission.
1. git add usage, explore the principle
The meaning of the git add command is to temporarily store a file. In terms of Git file classification, if a file is not tracked, git add will convert the file status to tracked status. If git add acts on a directory, all files in the directory will be recursively stored in the tracked state. Continue with the previous example.
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
sky
nothing added to commit but untracked files present (use "git add" to track)
#Put sky and gitignore files are temporarily stored to view the status comparison
$ git add sky .gitignore
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitignore
new file: sky
The first git status directory shows that there are two untraceable files, and friendly reminds you to track a file, just use git add < File > Command. After using git add command, temporarily store and track sky and gitignore file and prepare to add it to the version at the next submission.
In the object model of Git, when issuing the git add command, all the contents of each file will be copied to the object library and indexed by the SHA1 name of the file. Staging a file is also called caching a file, or putting a file into the index. In fact, you have seen the prompt - cached above. You can use the Git LS files command to view the files hidden under the object model, and you can find the SHA1 values of those temporary files.
$ git ls-files --stage 100644 85c292ca0717bb097b55af3b961c493190d1a4aa 0 .gitignore 100644 116c7ee1423b9a469b3b0e122952cdedc3ed28fc 0 sky
Most of the day-to-day changes in the repository may be simple editing. However, after any editing and before submitting changes, please execute the git add command to update the index with the latest version file. If you don't, you will get two different versions of the file: one is indexed in the object library and the other is in your working directory. Continuing with the previous example, change the sky file to make it different from the file in the index, and then use the invincible escape skill of Han Tianzun from the mysterious East. Just kidding, it's actually the command git hash object file (you hardly call her directly) to directly and output the new version of SHA1 hash value.
$ git ls-files --stage 100644 85c292ca0717bb097b55af3b961c493190d1a4aa 0 .gitignore 100644 116c7ee1423b9a469b3b0e122952cdedc3ed28fc 0 sky #Through vim modification, add new some data now is added $ cat sky new data add new some data now #Use the command to calculate SHA1 hash values $ git hash-object sky e24bcd708d232113f9012a5ece0a64eb97f3921e
After a little modification, you will find that the SHA1 value of the previous version of the file saved in the object library and index is 116c7ee1423b9a469b3b0e122952cdedc3ed28fc. However, after updating the sky file, the SHA1 value of the version becomes e24bcd708d232113f9012a5ece0a64eb97f3921e. Next, update the index to include the latest version of the file.
$ git add sky $ git ls-files --stage 100644 85c292ca0717bb097b55af3b961c493190d1a4aa 0 .gitignore 100644 e24bcd708d232113f9012a5ece0a64eb97f3921e 0 sky
Now the index has an updated file version. To sum up, the file has been temporarily stored, or the sky file is in the index. In the file index, this statement is not very accurate, because in fact, the file exists in the object library, and the index only points to her. The seemingly useless processing of SHA1 hash values and indexes brings a key point: git add is regarded as adding this content rather than adding this file.
In any case, the most important thing to remember is that the file version in the working directory and the file version temporarily stored in the index may not be synchronized. When submitting, git uses the file version in the index.
3, git rm command
Review simple usage, such as deleting test MD file (if staged)
#Delete test MD file git rm test.md
1. Usage of git rm command
The git rm command is naturally the opposite of git add. She will delete the files in both the version library and the working directory. However, because deleting files has more problems than adding files (if errors occur), git pays more attention to removing files.
Git can delete a file from the index or from both the index and the working directory. Git does not delete only one file from the working directory, and the normal rm command can be used for this purpose.
Deleting a file from both the working directory and the index does not delete the file's history in the version library. Any version of a file, as long as it is part of the history submitted to the version library, will remain in the object library and save the history. Continue with the above example, introduce an unexpected file that should not be temporarily stored, and see how to delete it.
#An unexpected file rdms has been added $ echo "random file data" > rdms #Tip: git rm cannot be performed on files that Git considers to be other #Should just use rm rdms $ git rm rdms fatal: pathspec 'rdms' did not match any files
Because git rm is also a command to operate on the index, it has no effect on files not added to the version library or index. Git must recognize the file first, so the following accidental temporary rdms file.
#Unexpected staging of rdms file
$ git add rdms
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitignore
new file: rdms
new file: sky
If you want to convert a file from staged to non staged, you can use the git rm --cached command.
#Viewing SHA1 hash values $ git ls-files --stage 100644 85c292ca0717bb097b55af3b961c493190d1a4aa 0 .gitignore 100644 087d758bdee282174e3ba5905a5e463d3d7a88dc 0 rdms 100644 e24bcd708d232113f9012a5ece0a64eb97f3921e 0 sky #delete $ git rm --cached rdms rm 'rdms' #By comparing the contents before deletion, it is found that the rdms file no longer exists $ git ls-files --stage 100644 85c292ca0717bb097b55af3b961c493190d1a4aa 0 .gitignore 100644 e24bcd708d232113f9012a5ece0a64eb97f3921e 0 sky #It can be seen that adding the -- cached parameter does not delete files in the working directory $ ls rdms sky test.o
git rm --cached deletes the files in the index and keeps them in the working directory, while git rm deletes the files from both the index and the working directory. Therefore, I added additional precautions at the end of the text and explained them.
If you want to remove a submitted file, use the simple git rm filename command to stage the request.
#Submit temporary files
$ git commit -m "add some files"
[master (root-commit) 82e23d4] add some files
2 files changed, 3 insertions(+)
create mode 100644 .gitignore
create mode 100644 sky
#Remove previously staged files sky from staging
$ git rm sky
rm 'sky'
#View status
$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
deleted: sky
Untracked files:
(use "git add <file>..." to include in what will be committed)
rdms
Before Git deletes a file, she will check to ensure that the version of the file in the working directory matches the latest version in the current branch (the version of Git command calling HEAD). This verification will prevent accidental loss of file modifications (due to your edits).
tips: you can also use git rm -f to force the deletion of files. Compulsion is clear authorization, which gives you permission to delete it safely and boldly. Even if you have modified the file since the last submission, it will be deleted.
In case you really want to leave the accidentally deleted file, just add it back.
$ git add sky $ git checkout HEAD--sky #Or after submitting, take the following command to find the corresponding hash value and restore it. The Rev list command is very practical. Please pick up a small notebook and remember her $ git rev-list master 82e23d40959116ae55ca82ced231e0069d8fc229 $ git checkout 82e23d40959116ae55ca82ced231e0069d8fc229 Warning: you are leaving 1 commit behind, not connected to any of your branches: 40eac09 delete some files If you want to keep it by creating a new branch, this may be a good time to do so with: git branch <new-branch-name> 40eac09 HEAD is now at 82e23d4 add some files
Note: the Rev list command is very practical. Please pick up the small book and remember her.
This is just a passing mention. When we delete a file and want to go back to the historical version, we can use git checkout to connect the ID of the master branch (SHA1). How do I find the ID value? Here is just a brief introduction to the usage of GIT Rev list. I believe you will fall in love with her. Of course, you can also add the parameter - before, and then query the branch on the specified date.
#Query my historical version to see hash value $ git rev-list master 988df9ddbeb6b30d0bf5138f36219a8593df75e0 bd156ab27fc96e78e5515c39c05d4ecd6c36b9f0 #Check out the historical version and restore the root hash value to the previous version $ git checkout bd156ab27fc96e78e5515c39c05d4ecd6c36b9f0
Version systems are good at restoring older versions of files. So much about the git rm command.
4, git mv command
1. Simple description and use
For example, use the git mv command to set test Rename the MD file to readme MD, as shown in the following command.
#Rename a file git mv test.md Readme.md
Another function of git mv command is to move the file location. It will certainly be familiar to small partners familiar with Linux commands. Test The MD file is moved from the github directory to the gitee directory.
#Move the location of a file git mv /github/test.md /gitee/
2. git mv detailed usage introduction
Suppose you need to move or rename a file. You can use the git rm command for old files and then use the git add command to add new files, or use the git mv command directly. Given a version library with a test file, you want to rename it to newtest. The following series of commands are equivalent Git operations.
$ mv test newtest $ git rm test $ git add newtest #The above three steps are equivalent to the following operations $ git mv test newtest
In either case, Git will delete the pathname of test in the index and add the pathname of newtest. As for the original content of test, it remains in the object library before it is re associated with newtest. It looks a little windy. In fact, just think about it carefully.
Retrieve the test file in the sample version library, rename it as follows, and then submit the changes.
$ git mv test newtest $ git add newtest $ git commit newtest -m "moved test to newtest" [detached HEAD adc778e] moved test to newtest 1 file changed, 1 insertion(+) create mode 100644 newtest
If you happen to check the history of this file, you may be uneasy to see that Git obviously lost the history of the original test file, only remembering that she renamed it from test to the current file name.
$ git log newtest
commit adc778e58db37977b39a541da4498607f12bc80b (HEAD)
Author: dywangk <example@xx.com>
Date: Mon Jan 17 20:35:56 2022 +0800
moved test to newtest
In fact, Git remembers all the history, but the display should be limited to the file name specified in the command-- The follow option allows Git to trace back in the log and find the entire history associated with the content. The code record is not posted here. The length is too long. You can modify the test by yourself.
$ git log --follow sky
One of the classic problems of VCS is that file renaming will cause them to lose tracking of file history. Git can retain historical information even after renaming.
5, Trace rename annotation
Xiaobai: cangls, I have used svn before, but not Git. Is there any difference between them in renaming?
cangls: of course, I'll give you some popular science. The content is very long. Although it is boring, please read it patiently.

1. Introduction to tracing and renaming annotations
As a typical example of a traditional version control system, SVN does a lot of tracking work on file renaming and movement. Why? This is because it only tracks differences between files. For example, if you move a file, this is essentially equivalent to deleting all rows from the old file and then adding it to the new file. However, at any time, even if you make a simple rename, you need to transfer and store all the contents of the file again, which will become very inefficient; Imagine renaming a subdirectory with thousands of files.
To alleviate this situation, SVN shows tracking every rename. If you want to test Txt to subdir / test Txt, you must use svn mv for files, not svn rm and svn add. Otherwise, SVN will not recognize that this is a rename, and can only perform inefficient deletion and addition steps as just described.
Then, in order to have the special function of tracking and renaming, the SVN server needs a special protocol to tell her client, please put test Txt to subdir / test txt. In addition, each SVN client must ensure that the operation (relatively rare) is performed correctly.
Git, on the other hand, does not track renames. You can text Txt is moved or copied anywhere, which will only affect the tree object (remember that the tree object saves the relationship between the contents, and the content itself is saved in the blob). Looking at the difference between the two trees, we can easily find that the blob called a30af53... Has moved to another new place. Even if you don't explicitly check the differences, every part of the system knows that she already has a blob and doesn't need another copy of her anymore.
In this case, as in many other places, Git's hash based simple storage system simplifies many other things that RCS is difficult or choose to avoid.
6, A gitignore file
When this article introduces the temporary file, we have simply used the gitignore file to ignore irrelevant test O documentation. In that example, you can ignore any file, just add the file name you want to ignore to the file in the same directory Gitignore file. In addition, you can add the file name to the top directory of the version library Ignore her in gitignore file.
But git also supports a richer mechanism. One The gitignore file can contain a list of file name patterns to specify which files to ignore The gitignore file format is as follows:
- Empty lines are ignored, only lines beginning with a pound (#) can be used for comments. However, if it # follows other text, it does not represent a comment.
- A simple literal configuration file name matches a file with the same name in any directory.
- The directory name is marked by a backslash (/) at the end. This matches directories and subdirectories with the same name, but not files or symbolic links.
- Including shell wildcards, such as asterisk (*), this mode can be extended to shell wildcard mode.
- Initial exclamation mark (!) The mode of the rest of the line will be reversed. In addition, files excluded by the previous pattern but matched by the reversal rule are included. The negation pattern overrides low priority rules.
Git allows any directory in the version library gitignore file. Each file affects only that directory and all its subdirectories gitignore's rules are also cascaded: you can override the rules in the high-level directory as long as you include a negation pattern in its subdirectory (using the initial "!").
In order to solve the problem, bring multiple The hierarchy of gitignore directory. In order to allow the command line to add the ignored file list, Git follows the following finite order from top to bottom:
- The mode specified on the command line;
- From the same directory Mode read from gitignore file;
- The mode in the upper directory is upward. Therefore, the mode of the current directory can overthrow the mode of the upper directory, and the mode of the upper directory closest to the current directory is better than the mode of the higher directory;
- come from. git/info/exclude file mode;
- From the configuration variable core The schema in the file specified by excludefile.
Because in the version library gitignore is considered a normal file, so it will be copied during the copy operation and apply to all copies of your version library. In general, entries should be placed under version control only if the schema is generally applicable to derived version libraries gitignore file.
Of course, there is another special case. I need to ignore a class of files, but I need to track some of them. At this time, I can use inversion (!).
7, Object models and files in Git
By now, you should have the basic ability to manage documents. Still, it's confusing where to track what files: in the working directory, index, or version library. Distinguish the difference between them through graphics. In the initial state, the working directory contains file1 and file2 files, which are "foo" and "bar" respectively.
The 4 drawings are a little rough and will be optimized later.
1. Example Figure 1
In addition to file1 and file2 in the working directory, the master branch also has a commit, which records the "foo" and "bar" trees with exactly the same contents as file1 and file2. In addition, the index records two HSA1 values 257cc5 and 5716ca, corresponding to those two files respectively. The working directory, index and object library are synchronized and consistent, and nothing is dirty.
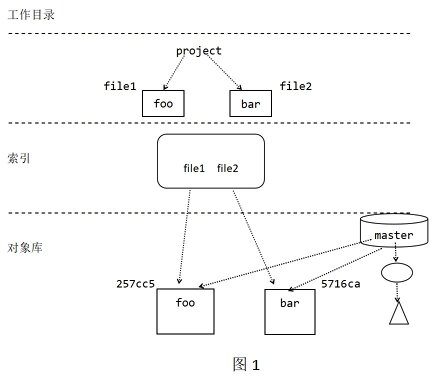
2. Example Figure 2
Figure 2 shows the changes after editing file1 in the work record. Now its content contains "git". There are no changes in the index and object library, but the working directory is now dirty.
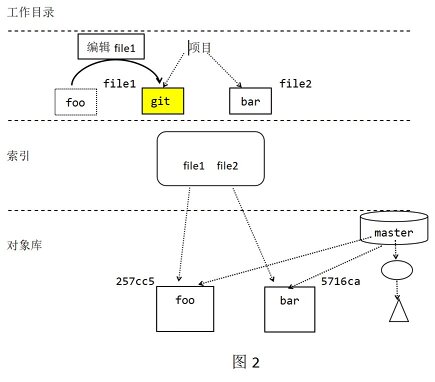
When git add file1 is used to temporarily edit file1, some interesting changes have taken place. As shown in Figure 3.
3. Example Figure 3
Git first selects the version of file1 in the working directory, calculates a SHA1 hash ID (04848c) for its content, and then saves that ID in the object library. Next, GIT will update the file1 pathname recorded in the index to the new (04848c) SHA1 value.
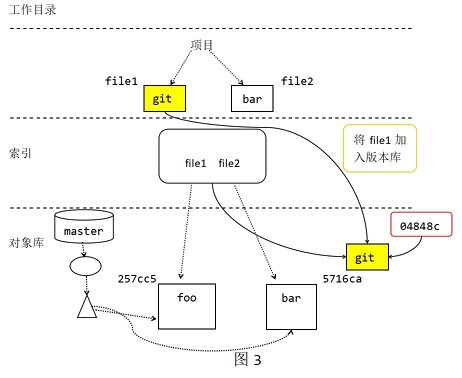
4. Example Figure 4
Since the contents of the file2 file have not changed and there is no git add to temporarily stage file2, the index continues to point to the original blob object. At this point, you have temporarily stored the file1 file in the index, and the working directory is consistent with the index. However, as far as HEAD is concerned, the index is dirty because the tree in the index is different from the tree submitted by HEAD in the master branch in the object library. Finally, when all changes are temporarily stored in the version library, the role of git commit is shown in Figure 4. Figure 4 the process looks the most complex, so you need to draw your own picture.
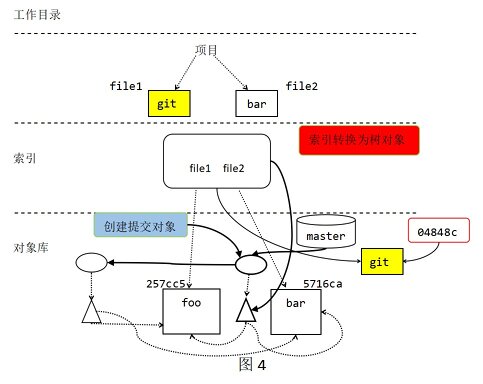
As shown in Figure 4, commit initiates three steps. First, after the virtual tree object (i.e. index) is converted into a real tree object, it will be named SHA1 and then stored in the object library. Second, create a new submission object with your log message. The new submission will point to the newly created tree object and the previous or parent submission. Finally, the reference of the master branch is moved from the latest submission to the newly created submission object and becomes the new master HEAD.
Finally, an interesting detail is that the working directory, index and object library (represented by the HEAD of the master branch) are synchronized again and become consistent, as shown in Figure 1.
8, Precautions (key points)
1. git commit --all considerations
1.1 review the submission order
There are three cases: unspecified parameter, specified -a parameter and specified single file.
#No parameters specified git commit -m "notes" #Specify a single file to submit git commit /github/test.md -m "Initial submission test.md file" #Or submit all (Note: temporary and untraceable files will be changed) git commit -a -m "Submit all"
Here, a commonly used git command git diff is added to view the submission differences. Use the two full ID names submitted before and execute git diff to view the ID value through the git log command.
$ git diff 988df9ddbeb6b30d0bf5138f36219a8593df75e0 bd156ab27fc96e78e5515c39c05d4ecd6c36b9f0 diff --git a/README.md b/README.md new file mode 100644 index 0000000..2b64487 --- /dev/null +++ b/README.md @@ -0,0 +1 @@ +initialization
1.2 precautions
In the past, it was only used for writing without much thought. At most, it wrote a comment and directly commit ted and push ed to the remote warehouse. Originally, I thought about the impact of not adding parameters or specifying the submitted documents when I submit. At first, I was curious. I looked through some books and found that there were many doorways.
Later, I noticed the precautions about git commit --all. The commit -a or - all parameter will cause the automatic staging of all non staged and untraceable files before execution, including the deletion of tracked files from the working copy.
Note: if you do not provide log messages directly from the command line, Git will start the editor and prompt you to write one.
2. git rm --cached considerations
2.1. Review the delete command
#Both index and working directory are deleted git rm test.md #Delete test directory recursively git rm -r test #Mark the file as untraceable, but still keep a copy in the working directory (use with caution) git rm --cached test.md
2.2 precautions
git add adds a file for temporary storage. On the contrary, GIT rm removes a file from the temporary storage state, and rm deletes the file from the index and working directory. Using the git rm --cached command will mark the file as untraceable, but still keep a copy in the working directory, which is very dangerous. Because you may forget what you have done before. In other words, you will forget that the file is no longer tracked. Git needs to check that the content in the working file is up-to-date. Using this method ignores this check, which increases the hidden danger. Use git rm --cached command with caution.
summary
The above is all the content of this article. I hope it can be helpful to your work. Feel well written, take out your one button three times. If I feel that the summary is not in place, I hope I can leave your valuable opinions. I will adjust and optimize it in the article.
The original is not easy, please indicate the source for reprint. Don't change your face, please respect the original. This article will be uploaded to gitee or github from time to time and published to wechat public platform. My WeChat official account is the same as other platform nicknames, Longteng Wan sky.