You have to work very hard to look effortless!
WeChat search official account [Coding road], together with From Zero To Hero!
preface
Last article Go bufio.Reader structure + detailed source code I , we introduced bufio The basic structure and operation principle of reader, and introduces the following important methods:
- Reset: reset the whole structure, which is equivalent to discarding all data in the buffer and using the new file reader as io Reader rd
- Fill: first compress the invalid data in the buffer, and then try to fill the buffer
- Peek: view some data without changing the state of the structure
- Discard: discard data
- Read: read the data. At the same time, it is optimized for one case where the buffer is empty. It is read directly from the underlying file without going through the buffer
- ReadByte: read a byte
In this article, we will continue to study bufio The remaining key source code of reader is mainly reading related operations.
ReadRune
The ReadRune method reads a rune and returns the rune, the number of bytes and the error generated during the reading process.
If the valid data in the buffer cannot form a rune and the buffer is not full, the fill method will be called to fill the data. After filling the data, first check whether the first byte is a rune. If not, try to use the subsequent bytes again, and finally update the read count and return the data.
func (b *Reader) ReadRune() (r rune, size int, err error) {
// b.r + utf8. Utfmax > B.w, i.e. B.w - b.R < utf8 Utfmax, the effective data length is less than the maximum possible length of Rune (but may meet the rune with smaller length)
// Data starting with b.r cannot be grouped into a complete rune (there is no rune with smaller length)
// b.err == nil no error
// b. W-b.r < len (b.buf): the valid data in the buffer is less than the length of the buffer, that is, the buffer is not full
// If the group does not form a complete run and the buffer is not full, fill will be called continuously to fill the data. If fill generates error, then b.err= Nil, it will jump out of the for loop
for b.r+utf8.UTFMax > b.w && !utf8.FullRune(b.buf[b.r:b.w]) && b.err == nil && b.w-b.r < len(b.buf) {
b.fill()
}
b.lastRuneSize = -1
// Valid data is empty (not filled in data), return
if b.r == b.w {
return 0, 0, b.readErr()
}
// Convert a byte of b.r position to run, if it is less than utf8 Runeself indicates that the byte corresponding to b.r is a rune
r, size = rune(b.buf[b.r]), 1
// r >= utf8. A byte after rune self is not required
if r >= utf8.RuneSelf {
// Starting from b.r, form a rune and return the rune and the corresponding number of bytes
r, size = utf8.DecodeRune(b.buf[b.r:b.w])
}
// Update read count and fallback related data
b.r += size
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = size
// Return data
return r, size, nil
}
UnreadRune
The UnreadRune method is used to fallback a rune. The requirements of UnreadRune are stricter than UnreadByte. If the previous reading method is not readrun, an error will be reported when calling UnreadRune. For UnreadByte, as long as the above method is a read operation (including readrun), you can also fallback
func (b *Reader) UnreadRune() error {
// The last operation is not readrun or there is insufficient fallback data
if b.lastRuneSize < 0 || b.r < b.lastRuneSize {
return ErrInvalidUnreadRune
}
// Back off
b.r -= b.lastRuneSize
// You cannot go back any more. The field is set to an invalid value
b.lastByte = -1
b.lastRuneSize = -1
return nil
}
ReadSlice
The ReadSlice method is used to find the delimiter and then return the data traversed during the search. For example, if we want to process data line by line, our input parameter can be a newline character, and ReadSlice will return one line of data at a time.
The ReadSlice method will first look for the separator in the unread part of its buffer. If it is not found and the buffer is not full, the method will first call the fill method to fill the buffer, and then look for it again. Once the ReadSlice method finds the delimiter, it cuts out the corresponding byte slice containing the delimiter on the buffer and returns the slice as the result value. Even if the delimiter is not found or an error is encountered during the search, the ReadSlice method will return all the data traversed during the search and update the read count. It can be seen that ReadSlice is a halfway method. If the buffer is full, it will not continue to look for it.
Since ReadSlice returns slices for buffer slices, there is a risk of data leakage; Secondly, the data has a validity period and will be overwritten by the next read operation. Therefore, try to use ReadBytes or ReadString instead of this method.
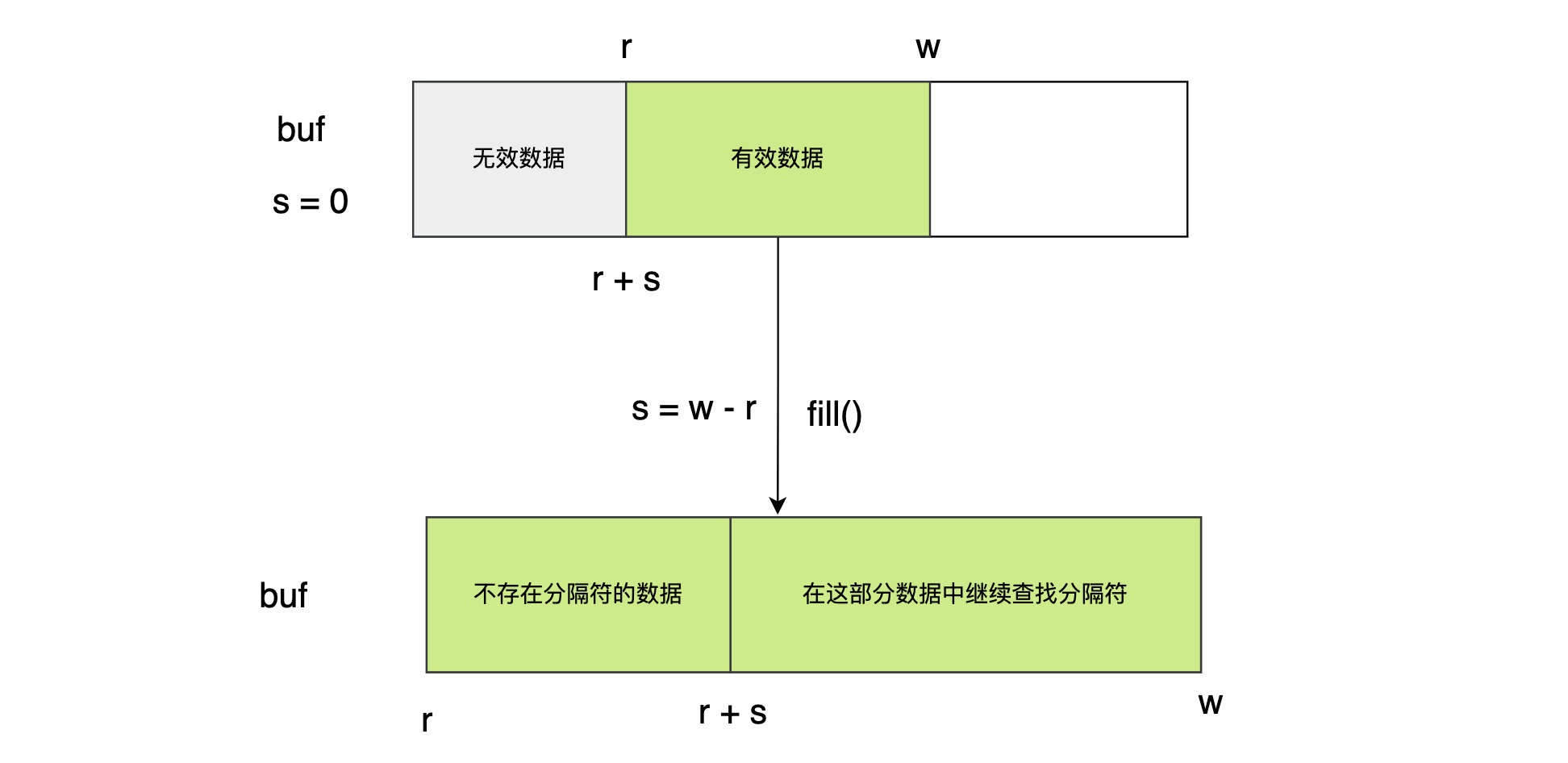
func (b *Reader) ReadSlice(delim byte) (line []byte, err error) {
s := 0 // The offset from the position of the read count from which the delimiter is looked up
// Keep trying to find the separator in a loop until an error occurs or the buffer is full
for {
// Find the separator in the range of [b.R + s: B.w]. i > = 0 indicates finding, and i is the offset from the starting position
if i := bytes.IndexByte(b.buf[b.r+s:b.w], delim); i >= 0 {
i += s
// Data to be returned
line = b.buf[b.r : b.r+i+1]
// Update read count
b.r += i + 1
// Found it, jump out of the loop
break
}
// error occurred
if b.err != nil {
// line is all the data traversed in the search process
line = b.buf[b.r:b.w]
// Update read count
b.r = b.w
// error returned
err = b.readErr()
break
}
// No delimiter and no error were found, but the buffer is full and all valid data
if b.Buffered() >= len(b.buf) {
// Update read count
b.r = b.w
// At this time, there are valid counts in the buffer. All buffer data are returned, and err is fixed to ErrBufferFull
line = b.buf
err = ErrBufferFull
break
}
// There is no separator in the current [b.R: B.w] data, so there is no need to scan this part of data again next time
s = b.w - b.r
// The buffer is not full. Fill in the data and look it up again
b.fill()
}
// If len (line) > = 1 indicates that it is found, update lastByte for fallback operation
if i := len(line) - 1; i >= 0 {
b.lastByte = int(line[i])
b.lastRuneSize = -1
}
return
}
ReadLine
The ReadLine method is used to read a line of data and does not contain carriage returns and line breaks ("\ r\n" or "\ n"). This method is low-level. If you want to read a row of data, you should try to use ReadBytes('\ n') or ReadString('\ n') instead of this method.
During reading, if a line of data is too long and exceeds the buffer length, only all data in the buffer array will be returned, isPrefix will be set to true, and the remaining data will only be returned by calling ReadLine method again later. If a row of data is returned correctly, isPrefix=false.
For the returned data, line and err will not be non empty at the same time (err!=nil and line!=nil do not exist). Because the ReadSlice called by the bottom layer, line is always not nil, so when err= Nil, but when line has no data, you need to set line to nil.
The ReadLine method may cause content disclosure because it directly returns the slice of buf. Users can modify the data in buf according to the address.
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) {
// Call 'ReadSlice('\n ')' to get data. At this time, the read count has been updated
line, err = b.ReadSlice('\n')
// The buffer is full, but the separator is not read. In this case, line = all data in the buffer
if err == ErrBufferFull {
// The special case handled here is: if the last character of the current buffer is' \ r ', the next character is' \ n', but '\ n' is not in the buffer, '/ r' will be left in the buffer
if len(line) > 0 && line[len(line)-1] == '\r' {
// Should not happen, b.r = b.w
if b.r == 0 {
panic("bufio: tried to rewind past start of buffer")
}
// b.r minus one, leaving '\ r' in the buffer
b.r--
// The returned data does not contain '\ r'
line = line[:len(line)-1]
}
return line, true, nil
}
// In the returned data, ensure that err does not exist= Nil and line= Nil (line must be non empty. When there is no data in line and err!=nil, set line to nil)
if len(line) == 0 {
if err != nil {
line = nil
}
return
}
// line!=nil and Len (line)= 0,, then make err=nil
err = nil
// Remove carriage returns and line breaks ("\ r\n" or "\ n")
if line[len(line)-1] == '\n' {
drop := 1
if len(line) > 1 && line[len(line)-2] == '\r' {
drop = 2
}
line = line[:len(line)-drop]
}
return
}
ReadBytes
The ReadBytes method reads data from the buffer again and again by calling the ReadSlice method until the delimiter is found. Compared with the halfway of ReadSlice, the ReadBytes method is quite persistent.
During this process, the ReadSlice method may return all read bytes and ErrBufferFull errors because the buffer is full, but the ReadBytes method will always ignore such errors and call the ReadSlice method again to refill the buffer and find the separator in it. The process ends only if the error returned by the ReadSlice method is not a buffer full error, or if it finds a delimiter.
If the search process is over, no matter whether the separator is found or not, the ReadBytes method will assemble all bytes read in this process into a byte slice according to the reading order, and take it as the first result value. If the process ends because of an error, it will also take the error value as the second result value.
func (b *Reader) ReadBytes(delim byte) ([]byte, error) {
// Save the data returned from each search
var frag []byte
// Save the data returned from multiple searches
var full [][]byte
var err error
// Sum of bytes traversed during lookup
n := 0
// Loop until a delimiter is found or a non buffer full error is encountered
for {
var e error
// Call ReadSlice to find separator
frag, e = b.ReadSlice(delim)
// e==nil indicates that you have found it. End the search
if e == nil {
break
}
// A non ErrBufferFull error has occurred. End the search
if e != ErrBufferFull {
err = e
break
}
// It is explained here that it is not found, but because the buffer is full, an ErrBufferFull error is generated. Ignore the error, and then save the returned data to full,
// Call ReadSlice again to fill the buffer lookup
buf := make([]byte, len(frag))
copy(buf, frag)
full = append(full, buf)
// Increase the number of bytes traversed
n += len(buf)
}
// In the previous step, break jumps out of the loop. The number of bytes traversed has not been accumulated. It is accumulated here
n += len(frag)
// The total number of bytes traversed is n. create a new byte slice buf and copy all traversed data into buf
buf := make([]byte, n)
n = 0
// Copy data in full
for i := range full {
n += copy(buf[n:], full[i])
}
// When break jumps out of the loop, the data obtained by traversal is also copied
copy(buf[n:], frag)
return buf, err
}
ReadString
The ReadString method is the same as the ReadBytes method. It only converts the data into a string, and its bottom layer is the called ReadBytes.
func (b *Reader) ReadString(delim byte) (string, error) {
// Call ReadBytes directly and convert the result to string
bytes, err := b.ReadBytes(delim)
return string(bytes), err
}
WriteTo
The WriteTo method writes all the data in the cache buf and the remaining data in the underlying data reader rd into the incoming Writer.
If the underlying data reader rd implements the WriterTo interface, write the underlying data directly to the Writer; If the incoming Writer implements the ReaderFrom interface, it can directly read data from the underlying data reader rd; If the above conditions are not met, you can only continuously fill the buffer with the underlying data reader rd each time, and then write the buffer data to the incoming Writer.
func (b *Reader) WriteTo(w io.Writer) (n int64, err error) {
// First, write the data in the buffer into the Writer
n, err = b.writeBuf(w)
if err != nil {
return
}
// If the underlying data reader rd implements the WriterTo interface, write the underlying data directly to the writer
if r, ok := b.rd.(io.WriterTo); ok {
m, err := r.WriteTo(w)
n += m
return n, err
}
// If the incoming Writer implements the ReaderFrom interface, it can directly read data from the underlying data reader rd
if w, ok := w.(io.ReaderFrom); ok {
m, err := w.ReadFrom(b.rd)
n += m
return n, err
}
// If the above conditions are not met, you can only continuously fill the buffer with the underlying data reader rd each time, and then write the buffer data to the incoming Writer
// Fill buffer first
if b.w-b.r < len(b.buf) {
b.fill()
}
// b. R < B.w = > there is data in the buffer, which is not empty.
// If the buffer is not empty, the data is written to the Writer and the buffer is filled again.
// If the underlying data is read out, the data cannot be filled, and the buffer is empty. b.r == b.w, the loop will end
for b.r < b.w {
m, err := b.writeBuf(w)
n += m
if err != nil {
return n, err
}
// No error is generated. The data is written to the Writer. At this time, the buffer is empty and continue to fill
b.fill()
}
// The buffer is empty. Go to this step if b.err = = io EOF indicates that the underlying data has been read and the task has been completed. error should not be returned
if b.err == io.EOF {
b.err = nil
}
return n, b.readErr()
}
var errNegativeWrite = errors.New("bufio: writer returned negative count from Write")
// Write the data in the buffer into the Writer
func (b *Reader) writeBuf(w io.Writer) (int64, error) {
n, err := w.Write(b.buf[b.r:b.w])
if n < 0 {
panic(errNegativeWrite)
}
b.r += n
return int64(n), err
}
summary
In this article, we introduce bufio Key reading methods of Reader:
- ReadRune: read a rune and return the rune, the number of bytes and the error generated during reading
- UnreadRune: fallback a rune
- ReadSlice: find the separator and return the data traversed in the search process. It is a halfway method
- ReadLine: used to read a line of data. It is recommended to use ReadBytes('\ n') or ReadString('\ n') instead
- ReadBytes: find the separator and return the data traversed during the search. It is a persistent method
- ReadString: similar to the ReadBytes method, it only converts the data into a string
- WriteTo: write all the data in the cache buf and the remaining data in the underlying data reader rd into the incoming Writer
more
Personal blog: https://lifelmy.github.io/
WeChat official account: long Coding Road