preface
In the last article, the core technology of lexical analysis, finite automata (DFA), and the use and working principle of two common lexical analyzers were introduced. On this basis, it will be much easier to see the lexical analysis source code of Go
This paper mainly includes the following contents:
- Go compiled entry file and what has been done in the compiled entry file
- Where is lexical analysis in Go compilation and what is the detailed process
- Write a test go source file, perform lexical analysis on this source file, and obtain the results of lexical analysis
Source code analysis
Compilation entry of Go
In order to better understand how the compilation process of Go comes to lexical analysis, here we first introduce where the compilation entry file of Go is and what has been done
Go The compiled entry file for is in: src/cmd/compile/main.go -> gc.Main(archInit)
Go to GC Main (archinit) is a long function. What it does in the front part is to obtain the parameters passed in from the command line and update the compilation options and configuration. Then you'll see the line below
lines := parseFiles(flag.Args())
The syntax of the text will be analyzed and shared in the syntax tree, and then the syntax of the text will be analyzed. After that, the syntax of the text will be analyzed and shared
Open the parseFiles(flag.Args()) file and you can see the following contents (I have omitted the code in the later part and mainly focus on the content of lexical analysis):
func parseFiles(filenames []string) uint {
noders := make([]*noder, 0, len(filenames))
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
for _, filename := range filenames {
p := &noder{
basemap: make(map[*syntax.PosBase]*src.PosBase),
err: make(chan syntax.Error),
}
noders = append(noders, p)
go func(filename string) {
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
base := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Msg: err.Error()})
return
}
defer f.Close()
p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches) // errors are tracked via p.error
}(filename)
}
......
}
We know that in the compilation process of Go, each source file will eventually be parsed into a syntax tree. As can be seen from the first few lines of the above code, it will first create multiple collaborations to compile the source files, but there is a limit on the number of open source files each time
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
Then traverse the source file and perform lexical and syntactic analysis on the file from multiple processes, mainly reflected in the for loop and go func. As you can see in go func, it will initialize the information of the source file first, mainly recording the name, row and column information of the source file. The purpose is to report the location of the error if an error is encountered in the process of lexical and syntax analysis. It mainly includes the following structures
type PosBase struct {
pos Pos
filename string
line, col uint32
}
type Pos struct {
base *PosBase
line, col uint32
}
Later, open the source file and start initializing the parser. The reason why the parser is initialized is that you will find that lexical analysis and parsing are put together during the compilation of Go. During the initialization of the parser, the lexical analyzer is also initialized. We can enter syntax in go fun Parse function
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
p.init(base, src, errh, pragh, mode) //Initialization operation
p.next() // The lexical parser parses the source file and converts it into a source file composed of all token s
return p.fileOrNil(), p.first //The syntax parser parses the token file above
}
You can see that the initialization operation of syntax analysis is called:
p.init(base, src, errh, pragh, mode)
Go to p.init and you will see a line of code that initializes the lexical analyzer
p.scanner.init(...Here are the parameters to initialize the lexical analyzer)
You can see that the parser uses p.scanner to call the init method of the lexical analyzer. Just look at the structure of the parser. The structure of the lexical analyzer is embedded in the structure of the parser (this article mainly introduces the lexical analyzer, so the meaning of each structure field of the parser will not be introduced here, but will be introduced in detail in the article introducing syntax analysis)
//Parsing structure
type parser struct {
file *PosBase
errh ErrorHandler
mode Mode
pragh PragmaHandler
scanner //Embedded lexical analyzer
base *PosBase
first error
errcnt int
pragma Pragma
fnest int
xnest int
indent []byte
}
After understanding the relationship between grammatical analysis and lexical analysis, we will start to see the specific process of lexical analysis
Lexical analysis process
The code location of lexical analysis is:
src/cmd/compile/internal/syntax/scanner.go
The lexical analyzer is implemented through a structure. Its structure is as follows:
type scanner struct {
source //Source is also a structure. It mainly records the information of the source file for lexical analysis, such as the byte array of the content, the currently scanned characters and positions, etc. (because we know that the lexical analysis process scans the source file character by character from left to right)
mode uint //Controls whether comments are resolved
nlsemi bool // if set '\n' and EOF translate to ';'
// current token, valid after calling next()
line, col uint //The initial value of the position of the currently scanned character is 0
blank bool // line is blank up to col
tok token // Token corresponding to the currently matched string (records all token types supported in Go)
lit string // The source code text representation of the token. For example, if is recognized from the source file, its token is_ If, its lit is if
bad bool // If there is a syntax error, the obtained lit may be incorrect
kind LitKind // If the matched string is a value type, this variable identifies which value type it belongs to, such as INT, FLOAT or run
op Operator // Similar to kind, it identifies the recognized TOKEN (if it is an operator, what kind of operator it is)
prec int // valid if tok is _Operator, _AssignOp, or _IncOp
}
type source struct {
in io.Reader
errh func(line, col uint, msg string)
buf []byte // Byte array of source file contents
ioerr error // Error message read from file
b, r, e int // buffer indices (see comment above)
line, col uint // Position information of the currently scanned character
ch rune // Currently scanned characters
chw int // width of ch
}
After knowing the meaning of each field in the structure of the lexical parser, let's learn what types of tokens are in Go
Token
Token is the smallest lexical unit with independent meaning in programming language. Token mainly includes keywords, user-defined identifiers, operators, separators, comments, etc., which can be found in Src / CMD / compile / internal / syntax / tokens Go, I intercepted a part below (these tokens exist in the form of constants)
const (
_ token = iota
_EOF // EOF
// names and literals
_Name // name
_Literal // literal
// operators and operations
// _Operator is excluding '*' (_Star)
_Operator // op
_AssignOp // op=
_IncOp // opop
_Assign // =
......
// delimiters
_Lparen // (
_Lbrack // [
_Lbrace // {
_Rparen // )
_Rbrack // ]
_Rbrace // }
......
// keywords
_Break // break
_Case // case
_Chan // chan
_Const // const
_Continue // continue
_Default // default
_Defer // defer
......
// empty line comment to exclude it from .String
tokenCount //
)
The three most important attributes of the lexical unit corresponding to each lexical Token are: the type of lexical unit, the text form of the Token in the source code, and the location of the Token. Comments and semicolons are two special tokens. Ordinary comments generally do not affect the semantics of the program, so comments can be ignored many times (the mode field in the scanner structure is to identify whether to resolve comments)
All tokens are divided into four categories:
- Special type Token. For example:_ EOF
- The Token corresponding to the basic face value. For example: IntLit, FloatLit, imagelit, etc
- Operator. For example: Add * / / +, Sub * / / -, * Mul * / /*
- keyword. For example:_ Break* // break,_ Case* // case
Lexical analysis implementation
In the lexical analysis part, there are two core methods, one is nextch() and the other is next()
As we know, the lexical analysis process is to read the source file character by character, and the nextch() function is to continuously read the contents of the source file character by character from left to right
The following is part of the code of the nextch() function, which mainly obtains the next unprocessed character and updates the scanned position information
func (s *source) nextch() {
redo:
s.col += uint(s.chw)
if s.ch == '\n' {
s.line++
s.col = 0
}
// fast common case: at least one ASCII character
if s.ch = rune(s.buf[s.r]); s.ch < sentinel {
s.r++
s.chw = 1
if s.ch == 0 {
s.error("invalid NUL character")
goto redo
}
return
}
// slower general case: add more bytes to buffer if we don't have a full rune
for s.e-s.r < utf8.UTFMax && !utf8.FullRune(s.buf[s.r:s.e]) && s.ioerr == nil {
s.fill()
}
// EOF
if s.r == s.e {
if s.ioerr != io.EOF {
// ensure we never start with a '/' (e.g., rooted path) in the error message
s.error("I/O error: " + s.ioerr.Error())
s.ioerr = nil
}
s.ch = -1
s.chw = 0
return
}
......
}
The next () function is to segment the string and match the corresponding token according to the scanned characters through the idea of determining the finite automata introduced in the previous article. Some core codes of the next() function are as follows:
func (s *scanner) next() {
nlsemi := s.nlsemi
s.nlsemi = false
redo:
// skip white space
s.stop()
startLine, startCol := s.pos()
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
// token start
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()
return
}
switch s.ch {
case -1:
if nlsemi {
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF
case '\n':
s.nextch()
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
case '"':
s.stdString()
......
}
A complete description of what these two methods do is:
- The lexical analyzer uses the nextch() function to get the latest unresolved characters each time
- According to the characters scanned, the next() function will determine which type of characters are currently scanned. For example, when scanning a a character, it will try to match an identifier type, that is, the s.ident() method called in the next() function, and it will determine if the identifier is a keyword.
- If the scanned character is a numeric character, it will try to match a basic face value type (such as * IntLit, FloatLit, imagelit *)
- After next () recognizes a token, it will be passed to the parser, and then the parser will call the next () function of the lexical analyzer, Continue to obtain the next token (so you will find that the lexical analyzer does not translate the entire source file into tokens at one time and then provide them to the parser, but the parser needs one by itself and obtains one through the next() function of the lexical analyzer)
We can see this line of code in the next() function
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
It filters out spaces, tabs, line breaks, etc. in the source file
For how to identify whether a string is a basic face value or a string, you can see the internal implementation of ident(), number(), stdString() methods inside. There is no code sticking here. In fact, the idea is the deterministic finite automata introduced in the previous article
Next, I'll start from the entrance of the Go compiler and draw the flow chart of lexical analysis to facilitate the introduction
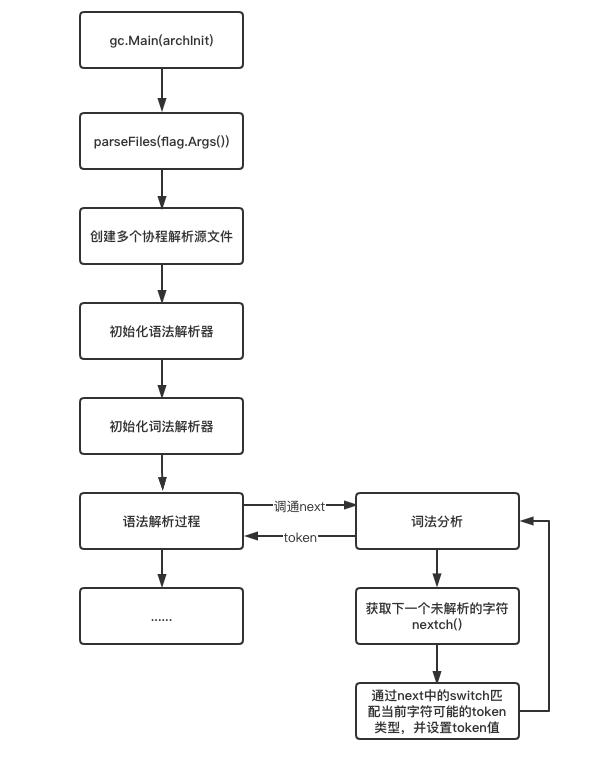
Maybe after reading the source code, I still don't have a clear understanding of the lexical parser. Next, we'll actually use the lexical analyzer through the test files or standard library provided by Go to see how it works
Test lexical analysis process
There are two ways to test lexical analysis. You can directly compile and execute the lexical analyzer test file provided by Go or the standard library provided by Go
Lexical analyzer test file address: src/cmd/compile/internal/syntax/scanner_test.go Go Address of lexical analyzer standard library provided: src/go/scanner/scanner.go
Next, I will write a source file myself and pass it to the lexical analyzer to see how it parses and what the parsing result is
Test lexical analyzer through test file
We can directly compile and execute Src / CMD / compile / internal / syntax / scanner_ test. The TestScanner method in go. The source code of this method is as follows (there are comments in the code):
func TestScanner(t *testing.T) {
if testing.Short() {
t.Skip("skipping test in short mode")
}
filename := *src_ // can be changed via -src flag
//Here you can choose an absolute path to the source file you want to parse
src, err := os.Open("/Users/shulv/studySpace/GolangProject/src/data_structure_algorithm/SourceCode/Token/aa.go")
if err != nil {
t.Fatal(err)
}
defer src.Close()
var s scanner
s.init(src, errh, 0) //Initialize lexical parser
for {
s.next() //Get the token (the next function will call the nextch() method to continuously get the next character until a token is matched)
if s.tok == _EOF {
break
}
if !testing.Verbose() {
continue
}
switch s.tok { //Obtained token value
case _Name, _Literal: //Identifier or underlying face value
//Print out the file name, row, column, token and the text in the source file corresponding to token
fmt.Printf("%s:%d:%d: %s => %s\n", filename, s.line, s.col, s.tok, s.lit)
case _Operator:
fmt.Printf("%s:%d:%d: %s => %s (prec = %d)\n", filename, s.line, s.col, s.tok, s.op, s.prec)
default:
fmt.Printf("%s:%d:%d: %s\n", filename, s.line, s.col, s.tok)
}
}
}
The test function will first open your source file and pass the contents of the source file to the initialization function of the lexical analyzer. Then, through an endless loop, continue to call the next() function to obtain the token until the terminator is encountered_ EOF, jump out of the loop
The contents of the file I want to parse for the lexical parser are as follows:
package Token
import "fmt"
func testScanner() {
a := 666
if a == 666 {
fmt.Println("Learning Scanner")
}
}
Then run the test method through the following command (you can print more information, and you can print out the fields of the sacner structure):
# cd /usr/local/go/src/cmd/compile/internal/syntax
# go test -v -run="TestScanner"
Print results:
=== RUN TestScanner
parser.go:1:1: package
parser.go:1:9: name => Token
parser.go:1:14: ;
parser.go:3:1: import
parser.go:3:8: literal => "fmt"
parser.go:3:13: ;
parser.go:5:1: func
parser.go:5:6: name => testScanner
parser.go:5:17: (
parser.go:5:18: )
parser.go:5:21: {
parser.go:6:2: name => a
parser.go:6:4: :=
parser.go:6:7: literal => 666
parser.go:6:10: ;
parser.go:7:2: if
parser.go:7:5: name => a
parser.go:7:7: op => == (prec = 3)
parser.go:7:10: literal => 666
parser.go:7:14: {
parser.go:8:3: name => fmt
parser.go:8:6: .
parser.go:8:7: name => Println
parser.go:8:14: (
parser.go:8:15: literal => "Learning Scanner"
parser.go:8:33: )
parser.go:8:34: ;
parser.go:9:2: }
parser.go:9:3: ;
parser.go:10:1: }
parser.go:10:2: ;
--- PASS: TestScanner (0.00s)
PASS
ok cmd/compile/internal/syntax 0.007s
Thesaurus test passed
Another test method is through the standard library provided by Go. Here I demonstrate how to test the lexical analyzer with the methods in the standard library
You need to write a piece of code to call the methods in the standard library to implement a lexical analysis process. An example is as follows:
package Token
import (
"fmt"
"go/scanner"
"go/token"
)
func TestScanner1() {
src := []byte("cos(x)+2i*sin(x) //Comment ") / / the content I want to parse (of course, you can also use a byte array of the file content)
//Initialize scanner
var s scanner.Scanner
fset := token.NewFileSet() //Initialize a file set (I'll explain this below)
file := fset.AddFile("", fset.Base(), len(src)) //Adds a file to the character set
s.Init(file, src, nil, scanner.ScanComments) //The third parameter is mode. I passed ScanComments, which means that the annotation needs to be parsed. Generally, the annotation can not be parsed
//scanning
for {
pos, tok, lit := s.Scan() //This is equivalent to the next() function
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit) //fset.Position(pos): get position information
}
}
Execute the above code to obtain the following results:
1:1 IDENT "cos" 1:4 ( "" 1:5 IDENT "x" 1:6 ) "" 1:7 + "" 1:8 IMAG "2i" 1:10 * "" 1:11 IDENT "sin" 1:14 ( "" 1:15 IDENT "x" 1:16 ) "" 1:18 ; "\n" 1:18 COMMENT "//Comment"
You will find that the methods used in the standard library are completely different from those in the test file. This is because a set of lexical analyzer is implemented separately in the standard library without reusing the code of lexical analyzer in go compiler. I understand this is because the code in go compiler cannot be used externally as a public method. For security reasons, the methods in it must be kept private
If you look at the implementation of lexical analyzer in the standard library, you will find that it is different from the implementation in go compilation, but the core idea is the same (such as character scanning and token recognition). The difference lies in the processing of the files to be parsed. We know that in go language, multiple files form a package, and then multiple packages are linked into an executable File. Therefore, multiple files corresponding to a single package can be regarded as the basic compilation unit of go language. Therefore, the lexical parser provided by go also defines FileSet and File objects to describe filesets and files
type FileSet struct {
mutex sync.RWMutex // protects the file set
base int // base offset for the next file
files []*File // list of files in the order added to the set
last *File // cache of last file looked up
}
type File struct {
set *FileSet
name string // file name as provided to AddFile
base int // Pos value range for this file is [base...base+size]
size int // file size as provided to AddFile
// lines and infos are protected by mutex
mutex sync.Mutex
lines []int // Lines contain the offset of the first character for each line (the first entry is always 0)
infos []lineInfo
}
The function is actually to record the information of the parsed file, which is similar to the function of the source structure in the scanner structure of the lexical parser. The difference is that we know that the go compiler creates multiple collaborations and compiles multiple files concurrently, while the standard library stores multiple files to be parsed through the file set, You will find that there is a one-dimensional array of files to be parsed in the structure of FileSet
The following is a brief introduction to the relationship between FileSet and File, and how it calculates the location information of Token
FileSet and File
The corresponding relationship between FileSet and File is shown in the figure:
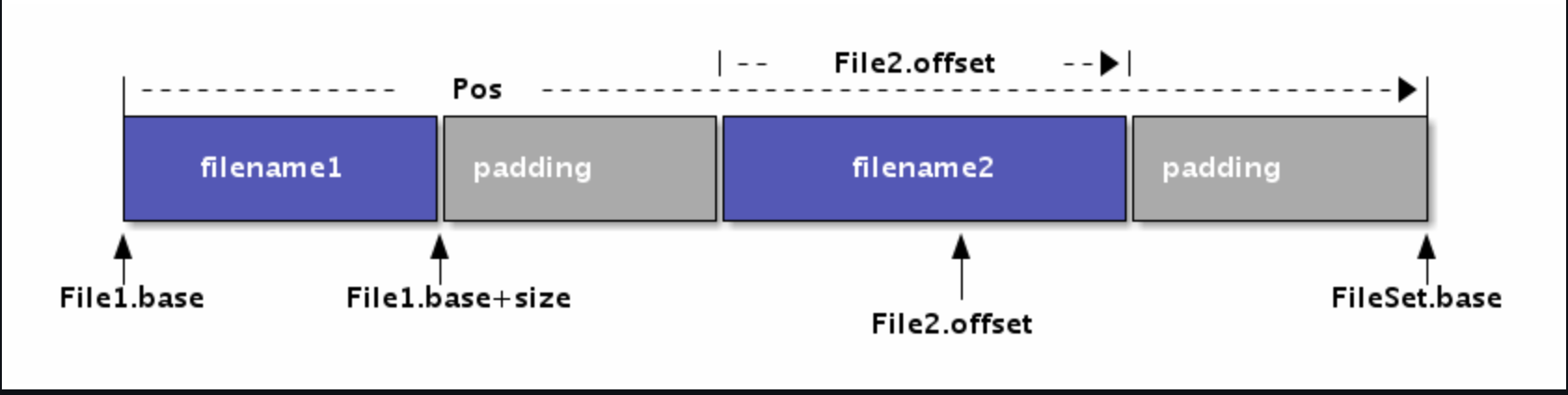
Image source: go-ast-book
The Pos type in the figure represents the subscript position of the array. Each File element in the FileSet corresponds to an interval of the underlying array. There is no intersection between different files, and there may be filling space between adjacent files
Each File is mainly composed of File name, base and size. Where base corresponds to the Pos index position of File in FileSet, so base and base+size define the start and end positions of File in FileSet array. Within each File, you can use offset to locate the subscript index, and use offset + File Base can convert the offset inside File to Pos position. Because Pos is the global offset of FileSet, on the contrary, you can also query the corresponding File and the offset within the corresponding File through Pos
The location information of each Token in lexical analysis is defined by Pos, and the corresponding File can be easily queried through Pos and the corresponding FileSet. Then calculate the corresponding line number and column number through the source File and offset corresponding to File (in the implementation, File only saves the starting position of each line and does not contain the original source code data). The bottom layer of Pos is int type, which is similar to the semantics of pointer. Therefore, 0 is also similar to null pointer. Null pointer is defined as NoPos, indicating invalid Pos
Source: go-ast-book
It can be seen from the relationship between FileSet and File that the lexical analyzer in the Go standard library can parse multiple source files through File set
summary
This paper mainly starts from the entry file compiled by go, gradually introduces the implementation of the source code of lexical analysis in go compilation, and tests and uses the lexical analyzer through the test file and the lexical analyzer standard library provided by go. I believe I can have a clear understanding of go's lexical analysis process after reading it
The lexical analysis part is relatively simple and involves less core content. The really difficult part is the later part of syntax analysis and abstract syntax tree. Interested partners, please continue to pay attention