background
My girlfriend complained two days ago that a big V made a video with many popular expressions. Say the big V said he was crawled directly by someone in the team. Ask me when to give her a crawl? After many days of nagging, I finally took action.
Target Site Analysis
First I found a website with popular emoticons.
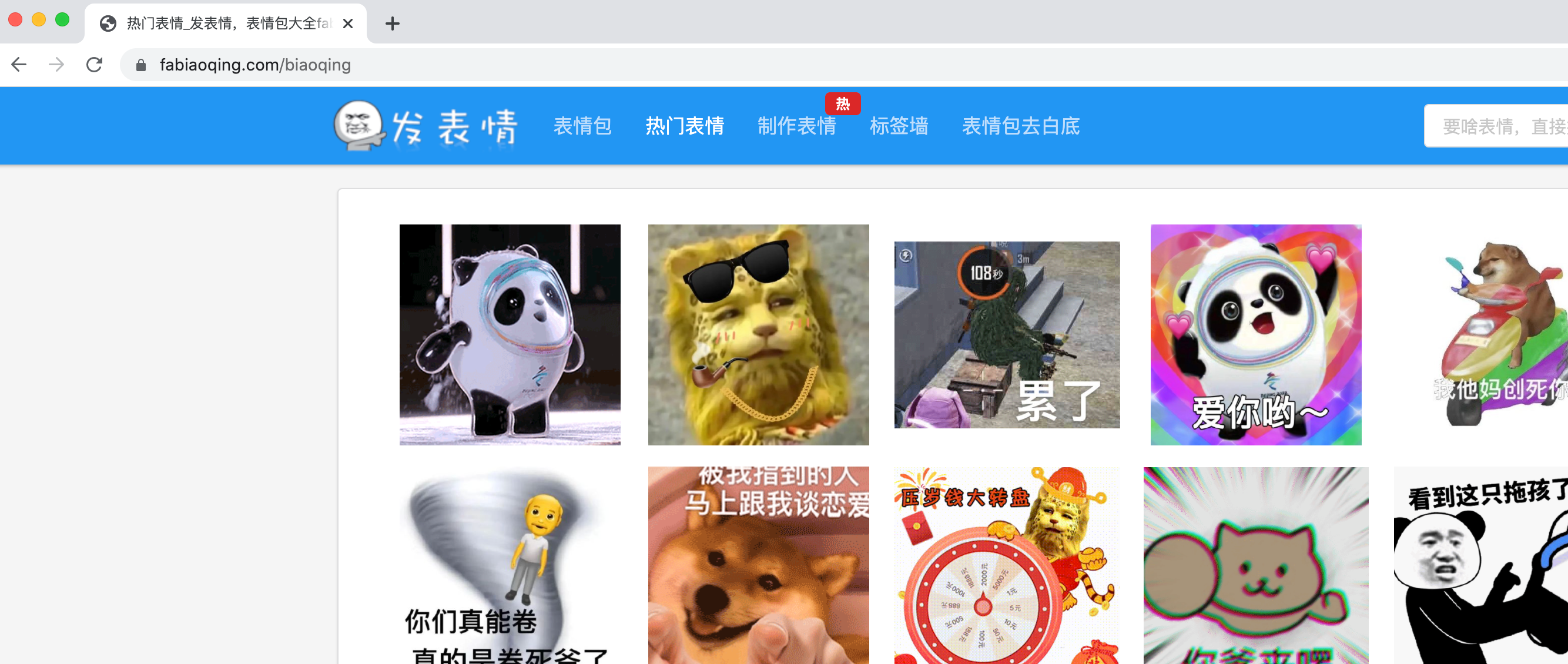
Let's have fun with this. There's a category of hot emoticons right inside. It is paginated. Let's look at the page breaks. Go to page 2.
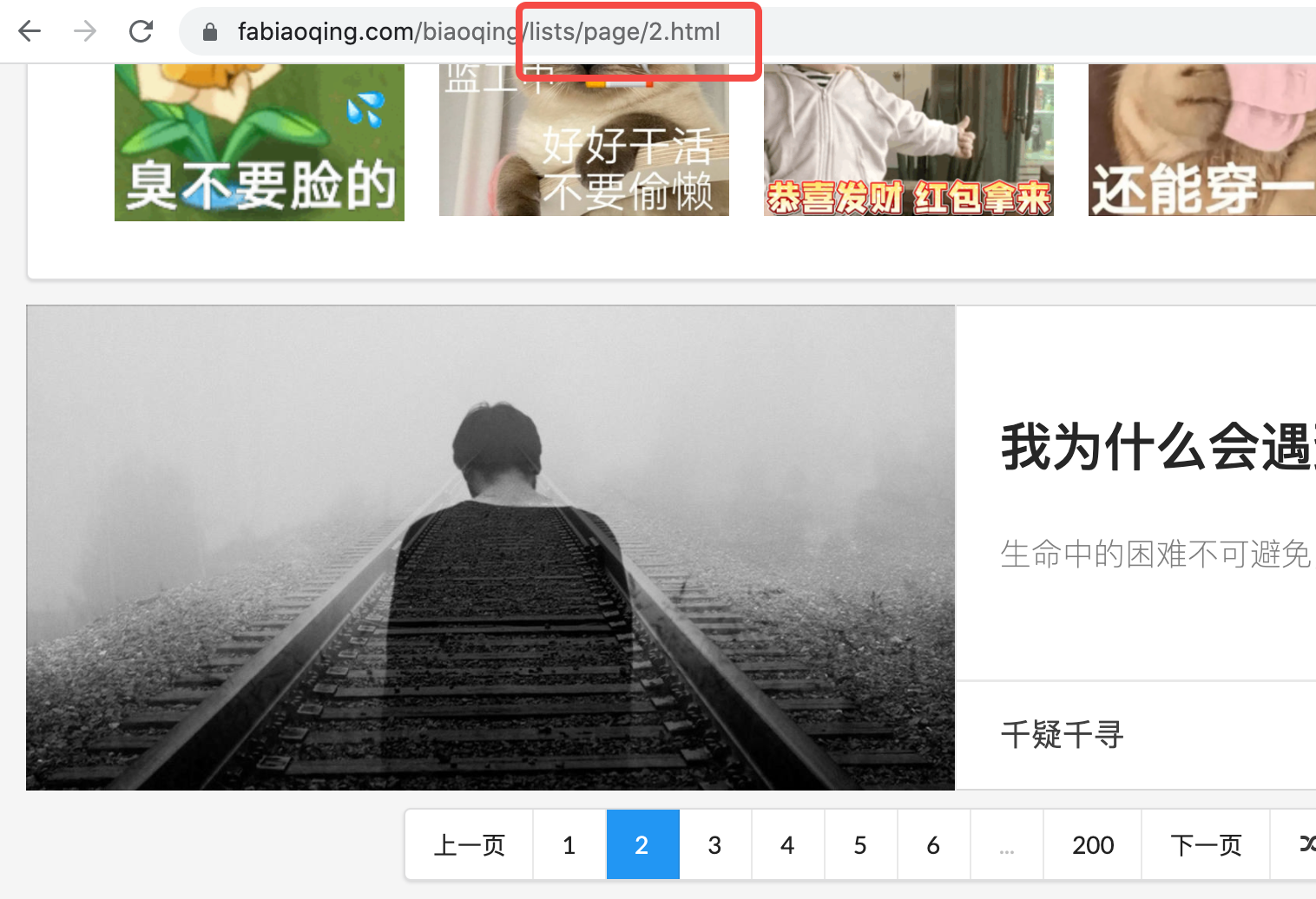
With many years of programmer intuition, every page, including the first page, can be
https://www.fabiaoqing.com/biaoqing/lists/page/ ${Number of Pages}. html
Form access. Give it a try, it's true, and intuitively every page must have the same html format.
F12 Take a look.
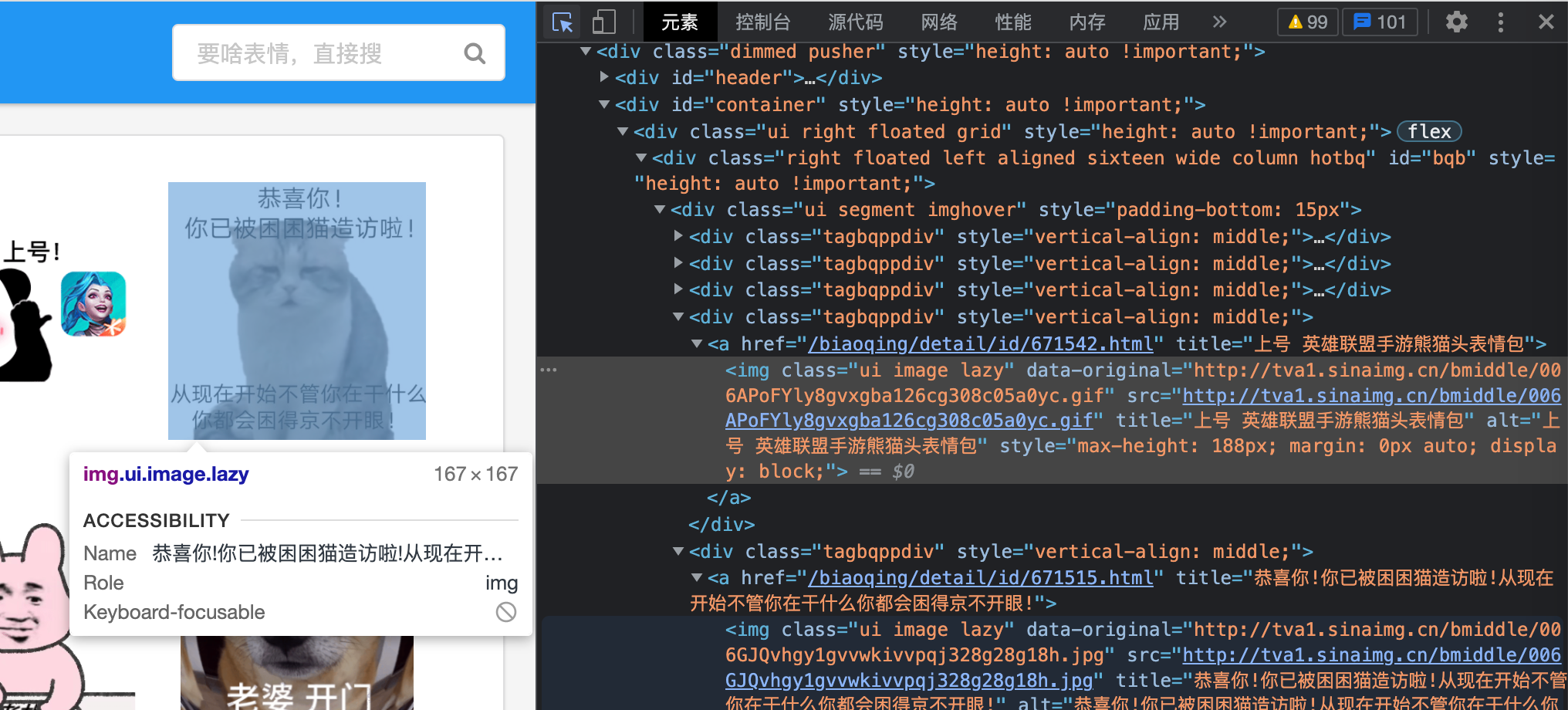
Each picture is in a deterministic form, with this class="xxxx" xxx, SRC
Then I just take the download link of the picture from src and download it. Look at the title s and alt s, which you can use as file names to label for easy searching.
Let's take a look at the web page.
func main() {
resp, _ := http.Get("https://www.fabiaoqing.com/biaoqing/lists/page/2.html")
buf, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("%s\n", buf)
}
$ go run main.go
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
......
<a href="/biaoqing/detail/id/671775.html" title="Jumping calves up GIF Motion Map">
<img class="ui image lazy" data-original="http://Tva1. Sinaimg. Cn/bmiddle/006APoFYly8gw2hau44pdg306o06o74u. Gif "src="/Public/lazyload/img/transparent. Gif "title=" skipping leg skipping GIF motion map "alt=" skipping leg skipping GIF motion map "style=" max-height:188; Margin: 0 auto'/> </a>
......
Ah, it seems a little different. The format of pull html is:
<img class="ui image lazy" data-original="http://Tva1. Sinaimg. Cn/bmiddle/006APoFYly8gw2hau44pdg306o06o74u. Gif "src="/Public/lazyload/img/transparent. Gif "title=" skipping leg skipping GIF motion map "alt=" skipping leg skipping GIF motion map "style=" max-height:188; Margin: 0 auto'/>
That is, js dynamically fills in the src with values from data-original after approximately startup instead of the default basemap. All right. Just take data-original instead.
Code
Framework for Concurrent Downloads
Our entire producer-consumer model uses channel communication to open five goroutine s for concurrent downloads.
Task is defined as follows:
package model
type Task struct {
URL string
FileName string
}
The entire crawler's code framework is almost like this.
package main
import (
"....../crapper/fabiaoqing"
"....../crapper/model"
"fmt"
"io"
"net/http"
"os"
"sync"
)
func main() {
taskCh := make(chan *model.Task, 1000)
wg := sync.WaitGroup{}
for i := 0; i < 5; i++ {
wg.Add(1)
go func(tasks <-chan *model.Task, wg *sync.WaitGroup) {
defer wg.Done()
for t := range tasks {
err := downloadFile(t.URL, t.FileName)
if err != nil {
fmt.Printf("fail to download %q to %q, err: %v", t.URL, t.FileName, err)
}
}
}(taskCh, &wg)
}
fabiaoqing.Crap(taskCh) // Producer Code
close(taskCh)
wg.Wait()
}
func downloadFile(URL, fileName string) error {
//Get the resp bytes from the url
resp, err := http.Get(URL)
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code %v", resp.StatusCode)
}
//Create a empty file
file, err := os.Create(fileName)
if err != nil {
return err
}
defer file.Close()
//Write the bytes to the fiel
_, err = io.Copy(file, resp.Body)
if err != nil {
return err
}
return nil
}
The only difference is the producer's line of code. Producers can complete the entire production process by continuing the task in taskCh and switching off the channel after completion of production.
Producer Code
The code in the producer section is the core of crawling web pages. Let's see how to design it.
First, the outermost layer should have a loop through all 200 pages.
func Crap(taskCh chan *model.Task) {
for i := 1; i <= 200; i++ {
url := fmt.Sprintf("https://www.fabiaoqing.com/biaoqing/lists/page/%d.html", i)
err := produceForPage(url, taskCh)
if err != nil {
fmt.Sprintf("produce for %q fail, err: %v", url, err)
continue
}
}
}
Then with url s, the most critical thing is http. How to extract the URLs of all the pictures you need from the html file on the web page after Get. You don't need to analyze html documents here, you can do it with regular expressions. The regular expression is written as follows:
<img class="ui image lazy" data-original="([^"]*)".*?title="([^"]*)"
This allows you to directly match the picture address to the title. Tile is used as stitching file name.
Thus, the entire producer code is as follows:
package fabiaoqing
import (
"....../crapper/model"
"fmt"
"io/ioutil"
"net/http"
"path"
"regexp"
"strings"
)
var regex = regexp.MustCompile(`<img class="ui image lazy" data-original="([^"]*)".*?title="([^"]*)"`)
func produceForPage(url string, taskCh chan *model.Task) error {
resp, err := http.Get(url)
if err != nil {
return fmt.Errorf("fail to get page: %v", err)
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code: %v", resp.StatusCode)
}
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
return fmt.Errorf("read body err: %v", err)
}
content := string(buf)
matches := regex.FindAllStringSubmatch(content, -1)
for _, match := range matches {
url := match[1]
title := match[2]
fileNameOfUrl := path.Base(url)
idx := strings.LastIndex(fileNameOfUrl, ".")
if idx < 0 {
fmt.Printf("can't resolve url filename %q", url)
continue
}
firstPart := fileNameOfUrl[:idx]
extPart := fileNameOfUrl[idx:]
fileName := fmt.Sprintf("%s%s%s", title, firstPart, extPart)
taskCh <- &model.Task{
URL: url,
FileName: "images/"+fileName, // Add the path prefix to save the file
}
}
return nil
}
func Crap(taskCh chan *model.Task) {
for i := 1; i <= 200; i++ {
url := fmt.Sprintf("https://www.fabiaoqing.com/biaoqing/lists/page/%d.html", i)
err := produceForPage(url, taskCh)
if err != nil {
fmt.Sprintf("produce for %q fail, err: %v", url, err)
continue
}
}
}
Function
And then we'll be in the home directory
go run main.go
After a while, it cracked. Some title s do not conform to filename naming, and some errors that are too long to exceed the filename limit.
Press. There is no current limit. If it's possible to limit the flow, add a speed limit to the consumer.
Achievements
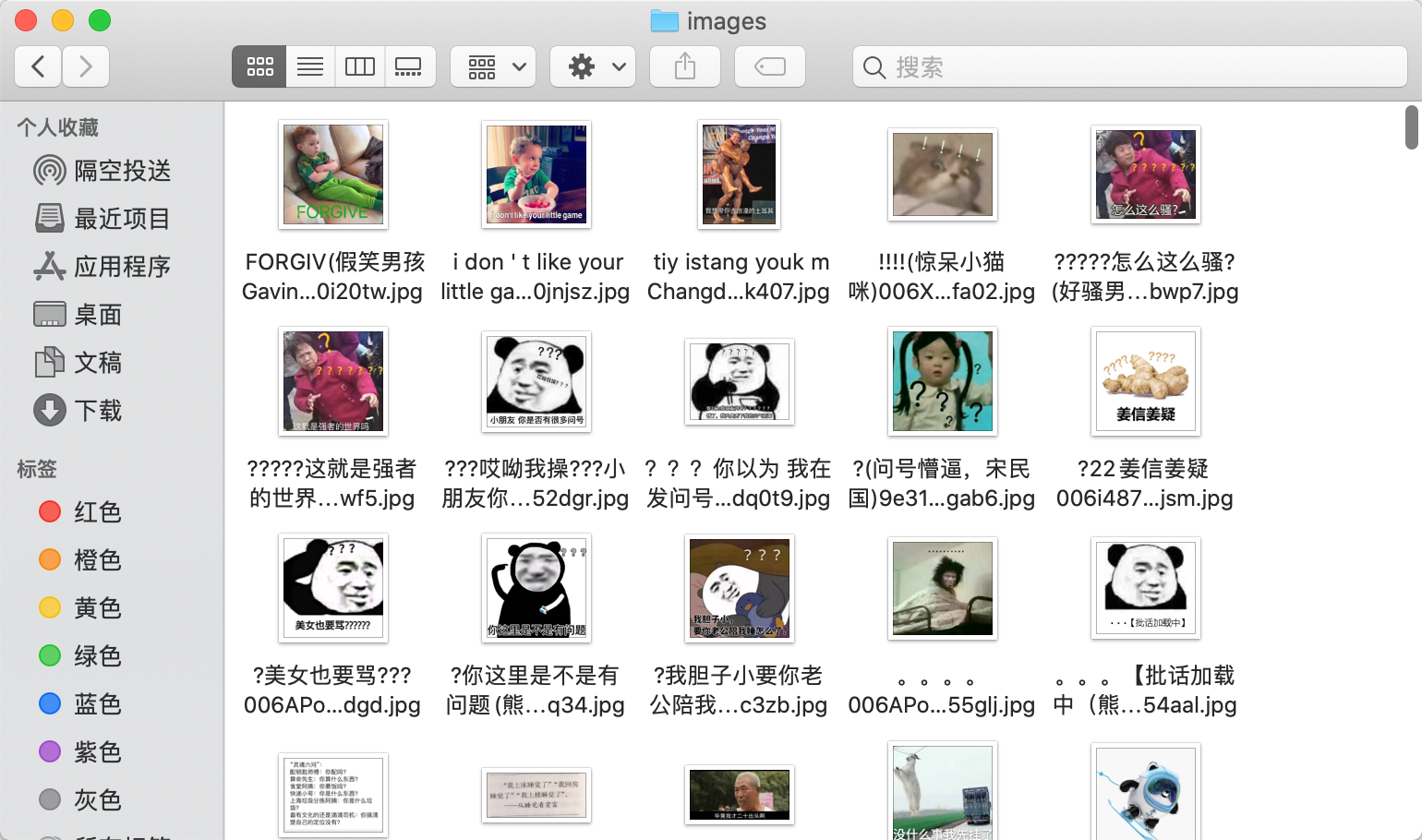





epilogue
Writing crawlers is easy. For this simple website.
We had a good time.