Original link: https://mp.weixin.qq.com/s/ZqfN8UlWRpoGhznGH-L1mw
introduce
I came across an article written in 15 years. To be honest, the title really attracted me.
I won't translate this article directly. I put the original address at the end of the article.
The requirement of the project is very simple. The client sends the request and the server receives the request processing data (the original text is to upload the resources to Amazon S3 resources). In essence,
I slightly changed the original business code, but it did not affect the core module. In the first version, every time a Request is received, a G is started for processing, which is a very routine operation.
First edition
package main
import (
"fmt"
"log"
"net/http"
"time"
)
type Payload struct {
// It doesn't matter what you pass
}
func (p *Payload) UpdateToS3() error {
//Storage logic, simulation operation time-consuming
time.Sleep(500 * time.Millisecond)
fmt.Println("Upload successful")
return nil
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
// Business filtering
// Request body resolution
var p Payload
go p.UpdateToS3()
w.Write([]byte("Operation successful"))
}
func main() {
http.HandleFunc("/payload", payloadHandler)
log.Fatal(http.ListenAndServe(":8099", nil))
}
What are the problems with this operation? Generally, no problem. But if you don't control G in the high concurrency scenario, your CPU utilization will soar and your memory usage will soar... Until the program runs out.
If this operation is applied to the database, for example, mysql. Accordingly, the disk IO, network bandwidth, CPU load and memory consumption of your database server will reach a very high level and collapse at the same time. Therefore, once something uncontrollable appears in the program, it is often a dangerous signal.
Chinese version
package main
import (
"fmt"
"log"
"net/http"
"time"
)
const MaxQueue = 400
var Queue chan Payload
func init() {
Queue = make(chan Payload, MaxQueue)
}
type Payload struct {
// It doesn't matter what you pass
}
func (p *Payload) UpdateToS3() error {
//Storage logic, simulation operation time-consuming
time.Sleep(500 * time.Millisecond)
fmt.Println("Upload successful")
return nil
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
// Business filtering
// Request body resolution
var p Payload
//go p.UpdateToS3()
Queue <- p
w.Write([]byte("Operation successful"))
}
// Processing tasks
func StartProcessor() {
for {
select {
case payload := <-Queue:
payload.UpdateToS3()
}
}
}
func main() {
http.HandleFunc("/payload", payloadHandler)
//Separate a g receiving and processing task
go StartProcessor()
log.Fatal(http.ListenAndServe(":8099", nil))
}
This version uses the buffered channel to complete this function, which controls the unlimited G, but still does not solve the problem.
The reason is that processing a request is a synchronous operation, and only one task will be processed at a time. However, the speed of sending a request will far exceed the speed of processing. In this case, once the channel is full, subsequent requests will be blocked and wait. Then you will find that the response time will start to increase significantly, or even no longer have any response.
Final edition
package main
import (
"fmt"
"log"
"net/http"
"time"
)
const (
MaxWorker = 100 //Set the value casually
MaxQueue = 200 // Set the value casually
)
// A buffered channel that can send work requests
var JobQueue chan Job
func init() {
JobQueue = make(chan Job, MaxQueue)
}
type Payload struct{}
type Job struct {
PayLoad Payload
}
type Worker struct {
WorkerPool chan chan Job //WorkerPoll is a channel, and the tuple in it is also a channel. The data type in this ancestor is Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool),
}
}
// The Start method starts a worker loop, listens to exit the channel, and stops the loop as needed
func (w Worker) Start() {
go func() {
for {
// Register the current worker in the worker queue
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// Real business place
// Time consuming simulation operation
time.Sleep(500 * time.Millisecond)
fmt.Printf("Upload successful:%v\n", job)
case <-w.quit:
return
}
}
}()
}
func (w Worker) stop() {
go func() {
w.quit <- true
}()
}
// Initialization operation
type Dispatcher struct {
// Register with the dispatcher's worker channel pool
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// Start running n worker s
for i := 0; i < MaxWorker; i++ {
worker := NewWorker(d.WorkerPool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
go func(job Job) {
// Try to get an available worker job channel and block until there are available workers
jobChannel := <-d.WorkerPool
// Distribute tasks to the worker job channel
jobChannel <- job
}(job)
}
}
}
// Receive the request and screen the task into JobQueue.
func payloadHandler(w http.ResponseWriter, r *http.Request) {
work := Job{PayLoad: Payload{}}
JobQueue <- work
_, _ = w.Write([]byte("Operation successful"))
}
func main() {
// Create a worker through the scheduler and listen for tasks from JobQueue
d := NewDispatcher(MaxWorker)
d.Run()
http.HandleFunc("/payload", payloadHandler)
log.Fatal(http.ListenAndServe(":8099", nil))
}
Finally, a two-level channel is adopted. The first level is to put the user request data into the channel job, which is equivalent to the task queue to be processed.
The other level is used to store the work cache queue that can process tasks. The type is Chan job. The scheduler puts the tasks to be processed into an idle cache queue, and work will always process its cache queue. In this way, a worker pool is implemented. Draw a rough picture to help understand,
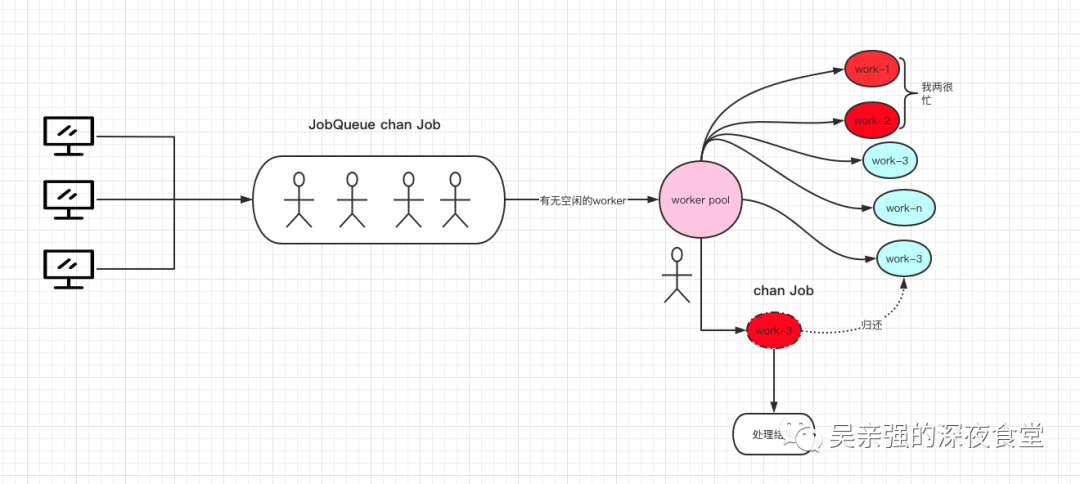
First, after receiving a request, we create a Job task and put it into the task queue for processing by the work pool.
func payloadHandler(w http.ResponseWriter, r *http.Request) {
job := Job{PayLoad: Payload{}}
JobQueue <- job
_, _ = w.Write([]byte("Operation successful"))
}
After the scheduler initializes the work pool, in the dispatch, once we receive the JobQueue task, we will try to obtain an available worker and distribute the task to the worker's job channel. Note that this process is not synchronous, but every time a job is received, a G is started for processing. This can ensure that the JobQueue does not need to be blocked, and the corresponding write task to the JobQueue does not need to be blocked in theory.
func (d *Dispatcher) Run() {
// Start running n worker s
for i := 0; i < MaxWorker; i++ {
worker := NewWorker(d.WorkerPool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
go func(job Job) {
// Try to get an available worker job channel and block until there are available workers
jobChannel := <-d.WorkerPool
// Distribute tasks to the worker job channel
jobChannel <- job
}(job)
}
}
}
The "uncontrollable" G here is different from the above. It is only in the blocking read Chan state for a very short time. When an idle worker is awakened and then distributes tasks, the whole life cycle is much shorter than the above operations.
Finally, it is strongly recommended to take a look at the original text. The original address is [1]
appendix
[1]http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang/