
introduce
data has become a new commodity, and the price is expensive. As people create unlimited content online, the amount of data on different websites has increased, and many start-ups have come up with the idea of needing this data. Unfortunately, due to time and money constraints, they can't always produce by themselves.
a popular solution to this problem is network crawling and crawling. With the increasing demand for data in machine learning applications, web crawlers have become very popular. The web crawler reads the source code of the website so that it can easily find the content to be extracted.
however, crawlers are inefficient because they grab all the content in HTML tags, and then developers must verify and clean up the data. That's where tools like scripy come in. Scrapy is a web crawler, not a simple crawler, because it is more picky about the type of data to be collected.
in the following sections, you will learn about scripy, Python's most popular crawling framework, and how to use it.
Introduction to Scrapy
Scrapy Is a fast and advanced web crawler framework written in Python. It is free and open source for large-scale network crawling.
Scrapy uses spiders, which determines how to grab a site (or a group of sites) to get the information you want. Spiders are classes that define how you want to crawl a site and extract structured data from a set of pages.
introduction
like any other Python project, it's best to create a separate virtual environment so that the library won't mess up the existing base environment. This article assumes that you have Python 3.3 or later installed.
1. Create a virtual environment
this article will use a virtual environment called. venv. You are free to change it, but be sure to use the same name throughout the project.
mkdir web-scraper cd web-scraper python3 -m venv .venv
2. Activate the virtual environment
For Windows, use the following command:
.venv\Scripts\activate
For Linux and OSX:
source .venv/bin/activate
This command enables the new virtual environment. It is new and therefore does not contain anything, so you must install all necessary libraries.
3. Set scripy
Because scratch is a framework, it will automatically install other required libraries:
pip install scrapy
To install slapy, follow Official documents.
Grab LogRocket articles
Note: LogRocket is just a website. You can change it to other websites, such as https://blog.csdn.net/low5252 ; https://weibo.com/
The best way to understand any framework is to learn by doing. Having said that, let's grab LogRocket's featured articles and their respective comments.
Basic settings
Let's start by creating a blank project:
scrapy startproject logrocket
Next, create your first spider with the following:
cd logrocket scrapy genspider feature_article blog.logrocket.com
Let's look at the directory structure:
web-scraper
├── .venv
└── logrocket
├── logrocket
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── feature_article.py
└── scrapy.cfg
Write the first spiders crawler
now that the project has been successfully set up, let's create our first spider, which will start from LogRocket Grab all featured articles in the blog.
Open spiders / feature_ The article.py file.
Let's step by step, first get the featured articles from the blog page:
class FeatureArticleSpider(scrapy.Spider):
name = 'feature_article'
allowed_domains = ['blog.logrocket.com']
start_urls = ['http://blog.logrocket.com']
def parse(self, response):
feature_articles = response.css("section.featured-posts div.card")
for article in feature_articles:
article_dict = {
"heading": article.css("h2.card-title a::text").extract_first().strip(),
"url": article.css("h2.card-title a::attr(href)").extract_first(),
"author": article.css("span.author-meta span.post-name a::text").extract_first(),
"published_on": article.css("span.author-meta span.post-date::text").extract_first(),
"read_time": article.css("span.readingtime::text").extract_first(),
}
yield article_dict
as you can see in the above code, the script.spider defines some properties and methods, which are:
- Name, which defines the spiders name and must be unique in the project
- allowed_domains, which allows us to grab a list of domains
- start_urls, we started crawling the list of URLs
- parse(), which is called to process the response to the request. It usually parses the response, extracts the data, and generates a dict in the following form
Select the correct CSS element
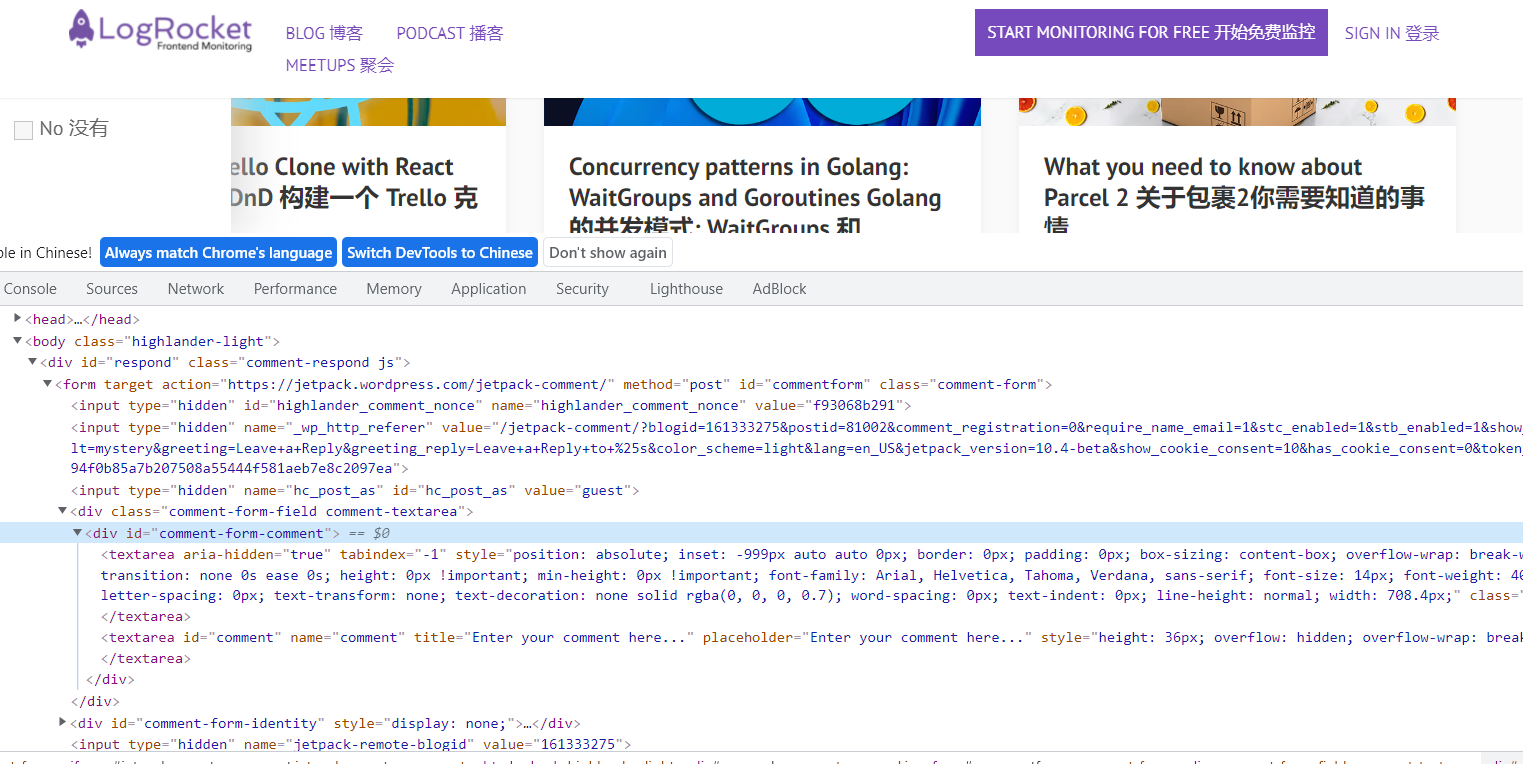
in the process of fetching, it is important to know the best way to uniquely identify the element to be fetched.
the best way is to check elements in the browser. You can easily view the HTML structure in the developer tools (right-click to check it out) menu.
* * recommended xpath **A plug-in that quickly locates a specific element.
Run the first spider
Run the above spider with the following command:
scrapy crawl feature_article
It should include all featured articles, such as:
...
...
{'heading': 'Understanding React's ', 'url': 'https://blog.logrocket.com/understanding-react-useeffect-cleanup-function/', 'author': 'Chimezie Innocent', 'published_on': 'Oct 27, 2021', 'read_time': '6 min read'}
2021-11-09 19:00:18 [scrapy.core.scraper] DEBUG: Scraped from <200 https://blog.logrocket.com/>
...
...
Introduce project
The main goal of crawling is to extract unstructured data and transform it into meaningful structured data. Items provides a dict like API and some great additional features. You can here Read more about the project.
Let's create the first item to specify the article through its properties. Here we use dataclass to define it.
Edit with the following: items.py
from dataclasses import dataclass
@dataclass
class LogrocketArticleItem:
_id: str
heading: str
url: str
author: str
published_on: str
read_time: str
Then, update the spider / feature_ The article.py file is as follows:
import scrapy
from ..items import LogrocketArticleItem
class FeatureArticleSpider(scrapy.Spider):
name = 'feature_article'
allowed_domains = ['blog.logrocket.com']
start_urls = ['http://blog.logrocket.com']
def parse(self, response):
feature_articles = response.css("section.featured-posts div.card")
for article in feature_articles:
article_obj = LogrocketArticleItem(
_id = article.css("::attr('id')").extract_first(),
heading = article.css("h2.card-title a::text").extract_first(),
url = article.css("h2.card-title a::attr(href)").extract_first(),
author = article.css("span.author-meta span.post-name a::text").extract_first(),
published_on = article.css("span.author-meta span.post-date::text").extract_first(),
read_time = article.css("span.readingtime::text").extract_first(),
)
yield article_obj
Get comments for each post
Let's delve into creating spiders. To get comments for each article, you need to request the url of each article, and then get the comments.
To do this, let's first create an entry (item.py) for comments:
@dataclass
class LogrocketArticleCommentItem:
_id: str
author: str
content: str
published: str
Now that the annotation item is ready, let's edit the spider / feature_ Article.py, as follows:
import scrapy
from ..items import (
LogrocketArticleItem,
LogrocketArticleCommentItem
)
class FeatureArticleSpider(scrapy.Spider):
name = 'feature_article'
allowed_domains = ['blog.logrocket.com']
start_urls = ['http://blog.logrocket.com']
def get_comments(self, response):
"""
The callback method gets the response from each article url.
It fetches the article comment obj, creates a list of comments, and returns dict with the list of comments and article id.
"""
article_comments = response.css("ol.comment-list li")
comments = list()
for comment in article_comments:
comment_obj = LogrocketArticleCommentItem(
_id = comment.css("::attr('id')").extract_first(),
# special case: author can be inside `a` or `b` tag, so using xpath
author = comment.xpath("string(//div[@class='comment-author vcard']//b)").get(),
# special case: there can be multiple p tags, so for fetching all p tag inside content, xpath is used.
content = comment.xpath("string(//div[@class='comment-content']//p)").get(),
published = comment.css("div.comment-metadata a time::text").extract_first(),
)
comments.append(comment_obj)
yield {"comments": comments, "article_id": response.meta.get("article_id")}
def get_article_obj(self, article):
"""
Creates an ArticleItem by populating the item values.
"""
article_obj = LogrocketArticleItem(
_id = article.css("::attr('id')").extract_first(),
heading = article.css("h2.card-title a::text").extract_first(),
url = article.css("h2.card-title a::attr(href)").extract_first(),
author = article.css("span.author-meta span.post-name a::text").extract_first(),
published_on = article.css("span.author-meta span.post-date::text").extract_first(),
read_time = article.css("span.readingtime::text").extract_first(),
)
return article_obj
def parse(self, response):
"""
Main Method: loop through each article and yield the article.
Also raises a request with the article url and yields the same.
"""
feature_articles = response.css("section.featured-posts div.card")
for article in feature_articles:
article_obj = self.get_article_obj(article)
# yield the article object
yield article_obj
# yield the comments for the article
yield scrapy.Request(
url = article_obj.url,
callback = self.get_comments,
meta={
"article_id": article_obj._id,
}
)
Now run the above spider with the same command:
scrapy crawl feature_article
Save data in MongoDB
Now that we have the correct data, let's save the same data in the database. We will use MongoDB to store the captured items.
Initial steps
take MongoDB After installing to your system, use pip to install PyMongo. PyMongo is a Python library that contains tools for interacting with MongoDB.
pip3 install pymongo
Next, add new Mongo related settings in settings.py:
# MONGO DB SETTINGS MONGO_HOST="localhost" MONGO_PORT=27017 MONGO_DB_NAME="logrocket" MONGO_COLLECTION_NAME="featured_articles"
Pipeline management
Now you have set up a crawler to grab and parse HTML, and set up database settings.
Next, we must connect the two through a pipe: pipelines.py.
from itemadapter import ItemAdapter
import pymongo
from scrapy.utils.project import get_project_settings
from .items import (
LogrocketArticleCommentItem,
LogrocketArticleItem
)
from dataclasses import asdict
settings = get_project_settings()
class MongoDBPipeline:
def __init__(self):
conn = pymongo.MongoClient(
settings.get('MONGO_HOST'),
settings.get('MONGO_PORT')
)
db = conn[settings.get('MONGO_DB_NAME')]
self.collection = db[settings['MONGO_COLLECTION_NAME']]
def process_item(self, item, spider):
if isinstance(item, LogrocketArticleItem): # article item
self.collection.update({"_id": item._id}, asdict(item), upsert = True)
else:
comments = []
for comment in item.get("comments"):
comments.append(asdict(comment))
self.collection.update({"_id": item.get("article_id")}, {"$set": {"comments": comments} }, upsert=True)
return item
Add this pipe in settings.py:
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
ITEM_PIPELINES = {'logrocket.pipelines.MongoDBPipeline': 100}
Final test
Run the grab command again to check whether the item is correctly pushed to the database:
scrapy crawl feature_article
summary
in this guide, you have learned how to write a basic spider in scripy and persist the crawled data to the database (MongoDB). You just learned the tip of the iceberg of Scrapy as a web capture tool. In addition to what we introduced here, there are still a lot to learn.
I hope that through this article, you understand the basic knowledge of scripy and have the motivation to use this wonderful crawler framework tool for further research.