JanusGraph - generation strategy of distributed id
Hello, I'm Yang Zi, JanusGraph graphic series articles, updated in real time~
Figure general directory of database articles:
- To sort out all articles related to graphs, please move (hyperlink): Figure database series - General Catalog of articles
- Address: https://liyangyang.blog.csdn.net/article/details/111031257
For source code analysis, see github (for star ~ ~): https://github.com/YYDreamer/janusgraph
Address of the following process HD large map: https://www.processon.com/view/link/5f471b2e7d9c086b9903b629
Version: janusgraph-0.5 two
Please keep the following statement when reprinting the article:
Author: Yangzi chat programming
WeChat official account: originality Java
Original address: https://liyangyang.blog.csdn.net/
text
Before introducing JanusGraph's distributed ID generation strategy, let's briefly analyze what characteristics should distributed IDS meet?
- Globally unique: the ID must be globally unique in the distributed environment, which is the basic requirement
- High performance: high availability, low delay, fast ID generation response; Otherwise, it may become a business bottleneck
- High availability: the service that prov id es the generation of Distributed IDS should be highly available. It should not be hung up casually, which will have an impact on the business
- Increasing trend: it mainly depends on the business scenario. Similar to the unique id of the node in the graph storage, keep increasing trend as much as possible; However, if it is similar to E-Commerce orders, try not to increase the trend, because the increasing trend will maliciously estimate the order volume and trading volume of the day and disclose the company's information
- Convenient access: if it is a middleware, it should adhere to the design principle of use and use, and the system design and implementation should be as simple as possible
1: Common distributed id generation strategies
Currently, there are four commonly used strategies for generating distributed IDS:
- UUID
- Database + segment mode (optimization: database + segment + double buffer)
- Redis based implementation
- Snow flake algorithm (SnowFlake)
There are others, such as self incrementing id based on database, multi master database mode, etc. These can be used in the case of small concurrency, but not in the case of large concurrency
There are some open source components for generating distributed IDS on the market, including TinyID based on database + segment, Baidu Uidgenerator based on SnowFlake, meituan support segment and Leaf of SnowFlake
So, what is the method of generating distributed IDS in JanusGraph?
2: Distributed id policy of JanusGraph
In JanusGraph, the distributed id generation adopts the mode of database + number segment + double buffer optimization; Let's analyze it in detail:
The database used for distributed id generation is the third-party storage backend currently used by JanusGraph. Here, we take the storage backend Hbase used as an example;
Metadata storage location required for JanusGraph distributed id generation:
There is the concept of column family in Hbase; When initializing the Hbase table, JanusGraph creates 9 column families by default to store different data. For details, see the graphic library JanusGraph series - an article on the underlying storage structure of graphic data;
There is a column family janusgraph_ids is abbreviated as i, which mainly stores the metadata required for JanusGraph distributed id generation!
The composition structure of JanusGraph's distributed id:
// There is a sentence in the source code
/* --- JanusGraphElement id bit format ---
* [ 0 | count | partition | ID padding (if any) ]
*/
It is mainly divided into four parts: 0, count, partition and ID padding (each type is a fixed value);
In fact, the order of these four parts will change when serialized into binary data; Here is only the component of id!
partition + count of the above part to ensure the uniqueness of distributed nodes;
- Partition id: partition id value. JanusGraph is divided into 32 logical partitions by default; The partition to which the node is assigned adopts random allocation;
- Count: each partition has a corresponding count range: the 55th power of 0-2; JanusGraph pulls a part of the range each time as the count value of the node; JanusGraph ensures that the same count value will not be obtained repeatedly for the same partition!
To ensure the global uniqueness of count in the partition dimension ensures the global uniqueness of the generated final id!!
The uniqueness of the distributed id is guaranteed by the uniqueness of the count based on the partition dimension! Our analysis below also focuses on the acquisition of count!
The main logic flow of JanusGraph distributed id generation is shown in the following figure: (it is recommended to view it in combination with source code analysis!)
During analysis, there is a concept called id block: it refers to the currently acquired number range
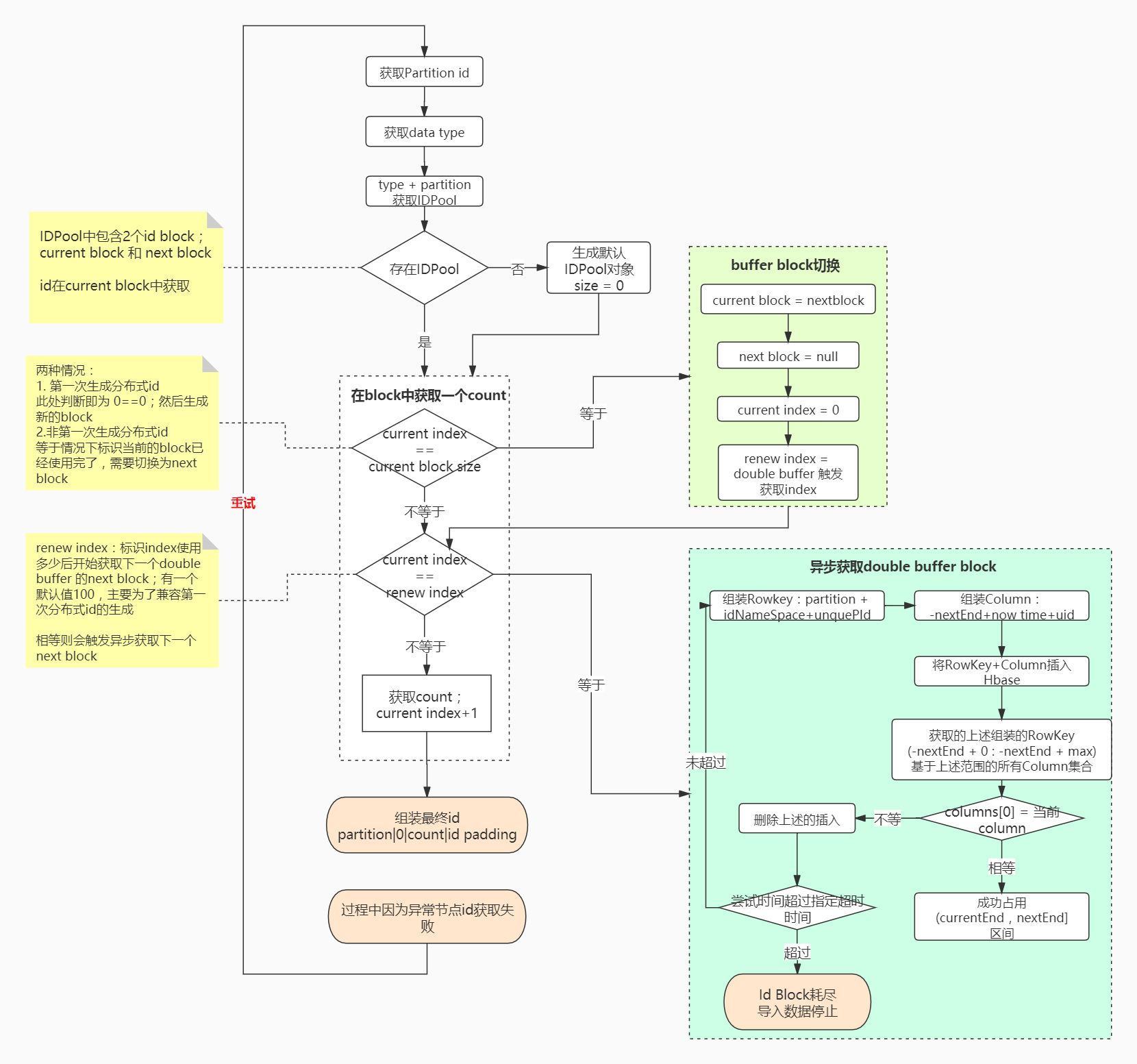
JanusGraph mainly uses the ` ` PartitionIDPool class to store different types of standardidpools; The StandardIDPool ` mainly contains two ID blocks:
- current block: the block used by the current generated id
- next block: another prepared block in the double buffer
Why two block s?
Mainly, if there is only one block, when we use the current block, we need to block the waiting area to obtain the next block, which will cause the distributed id to generate a long-time block to wait for the acquisition of the block;
How to optimize the above problems? double buffer;
In addition to the currently used block, we store another next block; When the block in use is assumed to have been used by 50%, the asynchronous acquisition of the next block is triggered, as shown in the blue part of the above figure;
In this way, when the current block is used, you can directly switch to the next block without delay, as shown in the green part in the above figure;
During execution, some exceptions may cause node id acquisition failure, and retry will be performed; The number of retries is 1000 by default;
private static final int MAX_PARTITION_RENEW_ATTEMPTS = 1000;
for (int attempt = 0; attempt < MAX_PARTITION_RENEW_ATTEMPTS; attempt++) {
// Process of getting id
}
ps: IDPool and block mentioned above are shared based on the instance dimension of the current graph!
3: Source code analysis
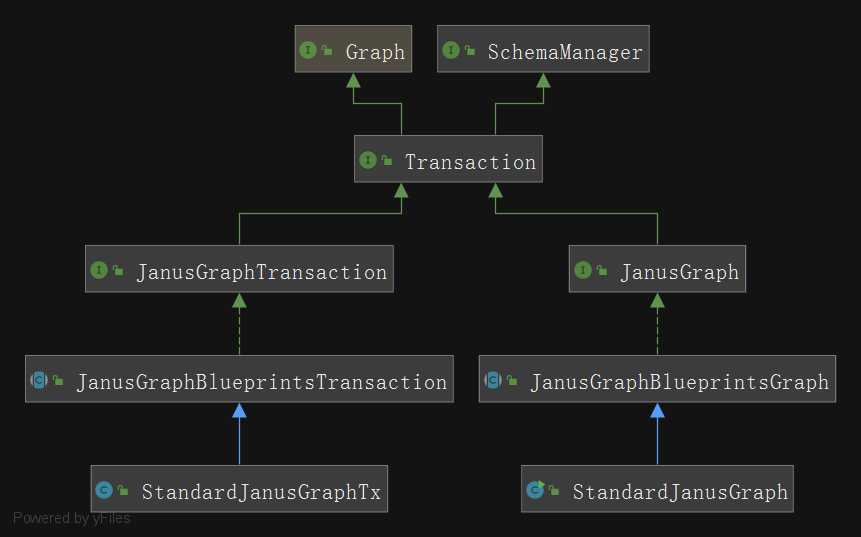
The source code of JanusGraph mainly contains two parts and some other components:
- Graph related classes: used for operations on nodes, attributes, and edges
- Transaction related class: used for transaction processing when CURD data or Schema
- Others: distributed node id generation class; Serialization class; Third party index operation class, etc
The class diagram of Graph and Transaction related classes is as follows:
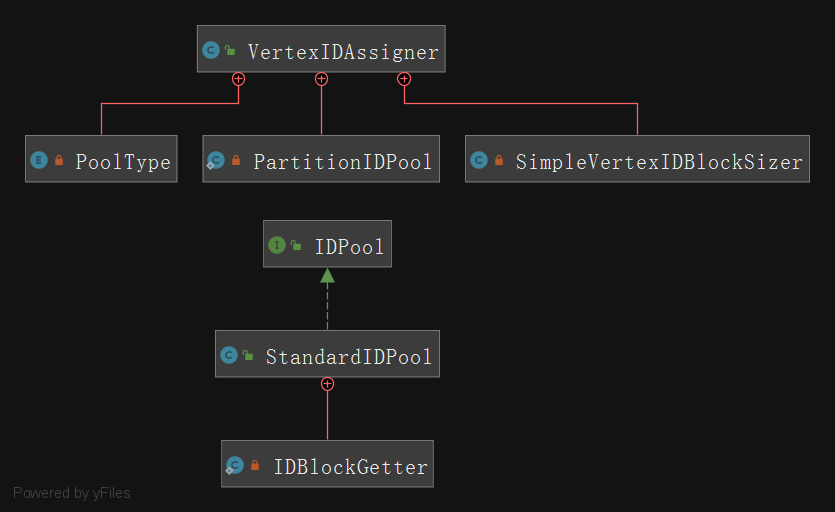
The class diagram of id generation involved in distributed id is as follows:
Initial data:
@Test
public void addVertexTest(){
List<Object> godProperties = new ArrayList<>();
godProperties.add(T.label);
godProperties.add("god");
godProperties.add("name");
godProperties.add("lyy");
godProperties.add("age");
godProperties.add(18);
JanusGraphVertex godVertex = graph.addVertex(godProperties.toArray());
assertNotNull(godVertex);
}
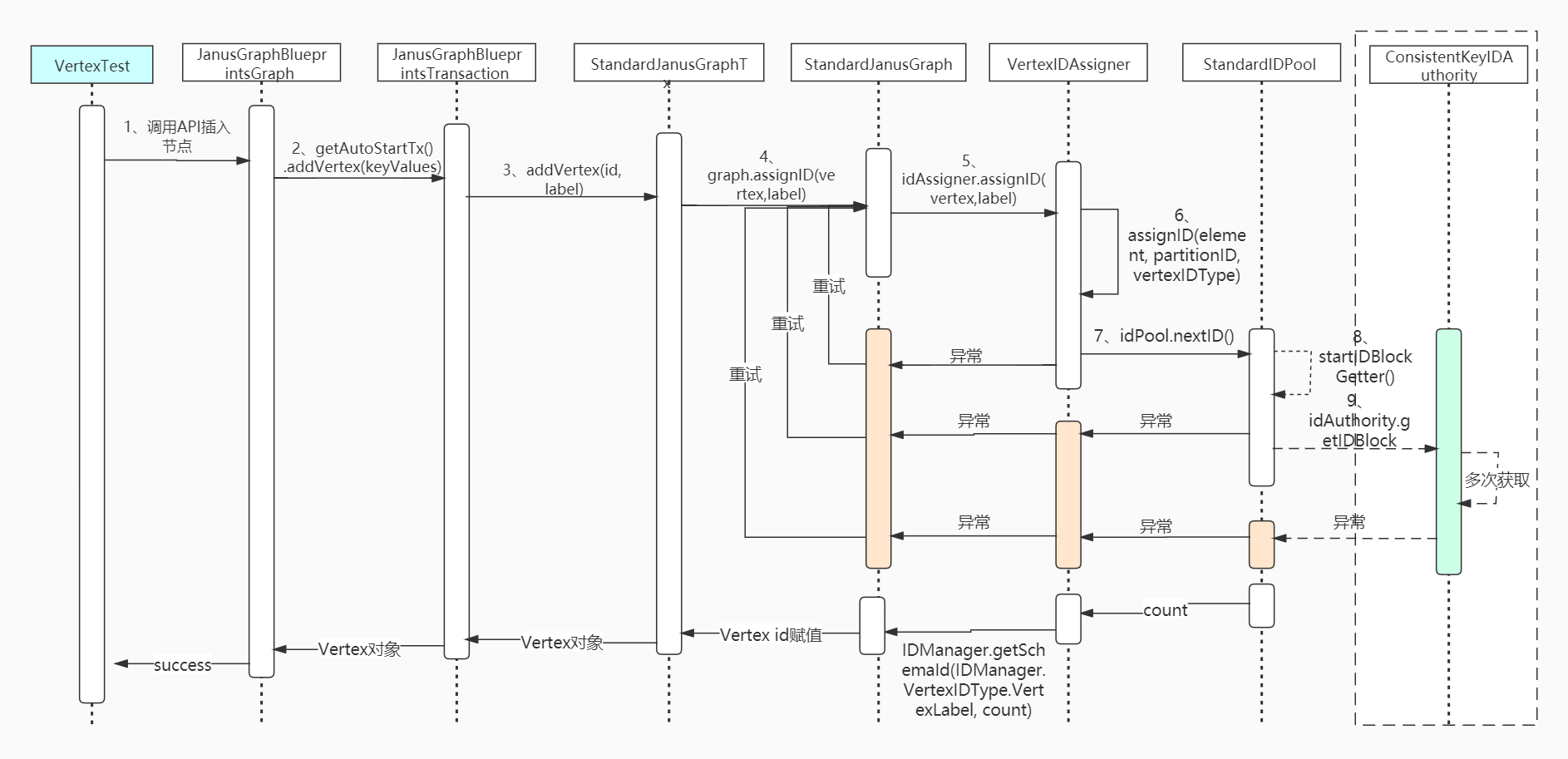
Add a lyy node with name in the diagram of gods; Take a look at the execution process. Note that the distributed id generation code of the node mainly analyzed here!
1. Call the AddVertex method of the JanusGraphBlueprintsGraph class
@Override
public JanusGraphVertex addVertex(Object... keyValues) {
// Add node
return getAutoStartTx().addVertex(keyValues);
}
2. Call the addVertex method of JanusGraphBlueprintsTransaction
public JanusGraphVertex addVertex(Object... keyValues) {
// . . . Other processing is omitted
// The node object is generated here, including the unique id generation logic of the node
final JanusGraphVertex vertex = addVertex(id, label);
// . . . Other processing is omitted
return vertex;
}
3. Call the addVertex method of StandardJanusGraphTx
@Override
public JanusGraphVertex addVertex(Long vertexId, VertexLabel label) {
// . . . Other processing is omitted
if (vertexId != null) {
vertex.setId(vertexId);
} else if (config.hasAssignIDsImmediately() || label.isPartitioned()) {
graph.assignID(vertex,label); // Assign a formal node id to the node!
}
// . . . Other processing is omitted
return vertex;
}
4. Call the assignID(InternalElement element, IDManager.VertexIDType vertexIDType) method of VertexIDAssigner
private void assignID(InternalElement element, IDManager.VertexIDType vertexIDType) {
// Start getting node unique id
// Failed to obtain node id due to some exceptions. Retry. The default is 1000 times
for (int attempt = 0; attempt < MAX_PARTITION_RENEW_ATTEMPTS; attempt++) {
// Initialize a partiiton id
long partitionID = -1;
// Get a partition id
// Different types of data have different ways to obtain partition id
if (element instanceof JanusGraphSchemaVertex) {
// Assign a value to the partition id
}
try {
// Formally allocate node id according to partition id and node type
assignID(element, partitionID, vertexIDType);
} catch (IDPoolExhaustedException e) {
continue; //try again on a different partition
}
assert element.hasId();
// . . . Other codes are omitted
}
}
5. The assignID(final InternalElement element, final long partitionIDl, final IDManager.VertexIDType userVertexIDType) method of VertexIDAssigner was called
private void assignID(final InternalElement element, final long partitionIDl, final IDManager.VertexIDType userVertexIDType) {
final int partitionID = (int) partitionIDl;
// count is a part of the distributed id, accounting for 55 bytes
// The uniqueness of Distributed IDS is guaranteed by the uniqueness of 'count' based on the 'partition' dimension
long count;
if (element instanceof JanusGraphSchemaVertex) { // schema node processing
Preconditions.checkArgument(partitionID==IDManager.SCHEMA_PARTITION);
count = schemaIdPool.nextID();
} else if (userVertexIDType==IDManager.VertexIDType.PartitionedVertex) { // The configured hotspot node is similar to ` makevertexlabel ('product ') Processing of partition() `
count = partitionVertexIdPool.nextID();
} else { // Handling of common node and edge types
// First, get the idPool of the enemy camp of the current partition
PartitionIDPool partitionPool = idPools.get(partitionID);
// If the IDPool corresponding to the current partition is empty, a default IDPool will be created with the default size = 0
if (partitionPool == null) {
// The PartitionIDPool contains StandardIDPool types corresponding to multiple types
// The StandardIDPool contains the corresponding block information and count information
partitionPool = new PartitionIDPool(partitionID, idAuthority, idManager, renewTimeoutMS, renewBufferPercentage);
// Cache down
idPools.putIfAbsent(partitionID,partitionPool);
// Take it out of the cache again
partitionPool = idPools.get(partitionID);
}
// Ensure that the partitionPool is not empty
Preconditions.checkNotNull(partitionPool);
// Judge whether the IDPool of the current partition is exhausted; It has been used up
if (partitionPool.isExhausted()) {
// If it is used up, put the partition id into the corresponding cache to avoid obtaining the partition id later
placementStrategy.exhaustedPartition(partitionID);
// Throw an IDPool exception, catch it at the outermost layer, and then retry to obtain the node id
throw new IDPoolExhaustedException("Exhausted id pool for partition: " + partitionID);
}
// Store the IDPool corresponding to the current type, because several types of idpools are saved in the partitionPool
IDPool idPool;
if (element instanceof JanusGraphRelation) {
idPool = partitionPool.getPool(PoolType.RELATION);
} else {
Preconditions.checkArgument(userVertexIDType!=null);
idPool = partitionPool.getPool(PoolType.getPoolTypeFor(userVertexIDType));
}
try {
// Important!!!! Get the count value according to the given IDPool!!!!
// In this statement, the initialization of block and the processing of double buffer block are designed!
count = idPool.nextID();
partitionPool.accessed();
} catch (IDPoolExhaustedException e) { // If the IDPool is used up, an IDPool exception is thrown, the outermost layer is captured, and then retry to obtain the node id
log.debug("Pool exhausted for partition id {}", partitionID);
placementStrategy.exhaustedPartition(partitionID);
partitionPool.exhaustedIdPool();
throw e;
}
}
// Final distributed id of assembly: [count + partition id + ID padding]
long elementId;
if (element instanceof InternalRelation) {
elementId = idManager.getRelationID(count, partitionID);
} else if (element instanceof PropertyKey) {
elementId = IDManager.getSchemaId(IDManager.VertexIDType.UserPropertyKey,count);
} else if (element instanceof EdgeLabel) {
elementId = IDManager.getSchemaId(IDManager.VertexIDType.UserEdgeLabel, count);
} else if (element instanceof VertexLabel) {
elementId = IDManager.getSchemaId(IDManager.VertexIDType.VertexLabel, count);
} else if (element instanceof JanusGraphSchemaVertex) {
elementId = IDManager.getSchemaId(IDManager.VertexIDType.GenericSchemaType,count);
} else {
elementId = idManager.getVertexID(count, partitionID, userVertexIDType);
}
Preconditions.checkArgument(elementId >= 0);
// Assign its distributed unique id to the node object
element.setId(elementId);
}
According to the above code, we get the corresponding IdPool. There are two cases:
- When the distributed id is obtained for the first time, the IDPool corresponding to the partition is initialized to the default IDPool with size = 0
- The IDPool corresponding to the partition is not acquired for the first time
Both cases are handled in the code count = idpool nextID() is processed in the nextID() method in the StandardIDPool class of nextID()!
Before analyzing the code, we need to know the relationship between PartitionIDPool and StandardIDPool:
Each partition has a corresponding partitionidpool extensions enummap < pooltype. Idpool > is an enumerated map type;
Each PartitionIDPool has a corresponding different type of StandardIDPool:
- NORMAL_VERTEX: used to allocate vertex id
- UNMODIFIABLE_VERTEX: used to allocate schema label id
- Relaxation: used to allocate edge id
The StandardIDPool contains multiple fields representing different meanings. Several important fields are extracted for introduction:
private static final int RENEW_ID_COUNT = 100;
private final long idUpperBound; // The maximum value of Block. The default value is the 55th power of 2
private final int partition; // Partition corresponding to current pool
private final int idNamespace; // Identify the type of pool. The above three types are NORMAL_VERTEX,UNMODIFIABLE_VERTEX,RELATION; Value is the position of the current enumeration value in the enumeration
private final Duration renewTimeout;// Timeout for re obtaining block
private final double renewBufferPercentage;// In dual buffer, when the percentage used by the first buffer block reaches the configured percentage, the acquisition of other buffer block is triggered
private IDBlock currentBlock; // Current block
private long currentIndex; // Identify where the current block is used
private long renewBlockIndex; // According to currentblock Numids() * renewbufferpercentage to obtain this value, which is mainly used to trigger the acquisition of the next buffer block when the current block consumes an index
private volatile IDBlock nextBlock;// Another block in the dual buffer
private final ThreadPoolExecutor exec;// Asynchronously obtain the thread pool of double buffer
6. The nextID method in the StandardIDPool class was called
Through the above analysis, we know that the uniqueness of the distributed unique id is guaranteed by the uniqueness of the count value in the partition dimension;
The above code obtains the count value by calling the nextId of IDPool;
The following code is the logic to obtain count;
@Override
public synchronized long nextID() {
// currentIndex indicates that the current index is less than the maximum value of current block
assert currentIndex <= currentBlock.numIds();
// Two situations are involved here:
// 1. The IDPool corresponding to the partition is initialized for the first time; Then currentIndex = 0; currentBlock.numIds() = 0;
// 2. This IDPool corresponding to the partition is not the first time, but this index just uses the last count of the current block
if (currentIndex == currentBlock.numIds()) {
try {
// Assign current block to next block
// Set next block to null and calculate renewBlockIndex
nextBlock();
} catch (InterruptedException e) {
throw new JanusGraphException("Could not renew id block due to interruption", e);
}
}
// In the process of using current block, when current index = = renewblockindex, the asynchronous acquisition of double buffer next block is triggered!!!!
if (currentIndex == renewBlockIndex) {
// Get next block asynchronously
startIDBlockGetter();
}
// Generate final count
long returnId = currentBlock.getId(currentIndex);
// current index + 1
currentIndex++;
if (returnId >= idUpperBound) throw new IDPoolExhaustedException("Reached id upper bound of " + idUpperBound);
log.trace("partition({})-namespace({}) Returned id: {}", partition, idNamespace, returnId);
// Returns the globally unique count of the finally obtained partition dimension
return returnId;
}
Two judgments are made in the above code:
- currentIndex == currentBlock.numIds():
- Generate distributed id for the first time: it is judged here as 0 = = 0; Then generate a new block
- Distributed id not generated for the first time: if it is equal to, it indicates that the current block has been used up and needs to be switched to next block
- currentIndex == renewBlockIndex
- renew index: identify how much index is used and start to get the next block of the next double buffer; There is a default value of 100, which is mainly compatible with the first generation of distributed id; If equal, it will trigger asynchronous acquisition of the next block
Next, let's compare nextBlock(); Logic and startIDBlockGetter(); Conduct analysis;
7. The nextBlock method in the StandardIDPool class was called
private synchronized void nextBlock() throws InterruptedException {
// When the IDPool corresponding to the partition is used for the first time, the nextBlock of the double buffer is empty
if (null == nextBlock && null == idBlockFuture) {
// Asynchronously start to get id block
startIDBlockGetter();
}
// When the IDPool corresponding to the partition is used for the first time, because the above is obtained asynchronously, the nextBlock may not be obtained when this step is executed
// Therefore, it is necessary to block the acquisition of the waiting block
if (null == nextBlock) {
waitForIDBlockGetter();
}
// Point the currently used block to the next block
currentBlock = nextBlock;
// index reset
currentIndex = 0;
// nextBlock null
nextBlock = null;
// renewBlockIndex is used in dual buffers. When the percentage used by the first buffer block reaches the configured percentage, the acquisition of other buffer block is triggered
// Count quantity corresponding to the value current block - (count quantity corresponding to the value current block * percentage of remaining space configured for renewBufferPercentage)
// When using current block, when current index = = renewblockindex, trigger asynchronous acquisition of double buffer next block!!!!
renewBlockIndex = Math.max(0,currentBlock.numIds()-Math.max(RENEW_ID_COUNT, Math.round(currentBlock.numIds()*renewBufferPercentage)));
}
Three main things have been done:
- 1. Whether the block is empty. If it is empty, a block will be obtained asynchronously
- 2. When nextBlock is not empty: assign next to current, set next to null, and set index to zero
- 3. Calculate and obtain the trigger index renewBlockIndex value of the next nextBlock
8. The startIDBlockGetter method in the StandardIDPool class was called
private synchronized void startIDBlockGetter() {
Preconditions.checkArgument(idBlockFuture == null, idBlockFuture);
if (closed) return; //Don't renew anymore if closed
//Renew buffer
log.debug("Starting id block renewal thread upon {}", currentIndex);
// Create a thread object containing the given permission control class, partition, namespace and timeout
idBlockGetter = new IDBlockGetter(idAuthority, partition, idNamespace, renewTimeout);
// Submit the thread task to obtain the double buffer and execute it asynchronously
idBlockFuture = exec.submit(idBlockGetter);
}
Create a thread task and submit it to the thread pool exec for asynchronous execution;
Next, the call method of the thread class mainly calls idauthority Getidblock method, which is mainly based on Hbase to obtain unused blocks;
/**
* Get the thread class of double buffer block
*/
private static class IDBlockGetter implements Callable<IDBlock> {
// Omit some codes
@Override
public IDBlock call() {
Stopwatch running = Stopwatch.createStarted();
try {
// Here, call idAuthority and HBase to get the Block
IDBlock idBlock = idAuthority.getIDBlock(partition, idNamespace, renewTimeout);
return idBlock;
} catch (BackendException e) {}
}
}
9. Call the getIDBlock method of the ConsistentKeyIDAuthority class
@Override
public synchronized IDBlock getIDBlock(final int partition, final int idNamespace, Duration timeout) throws BackendException {
// start time
final Timer methodTime = times.getTimer().start();
// Get the blockSize of the current namespace configuration, with the default value of 10000; Customizable configuration
final long blockSize = getBlockSize(idNamespace);
// Get the maximum id value idUpperBound of the current namespace configuration; The value is: the 55th power of 2
final long idUpperBound = getIdUpperBound(idNamespace);
// uniqueIdBitWidth identifies the number of bits occupied by uniqueId; uniqueId to be compatible with the "turn off distributed id uniqueness guarantee" switch, the default value of uniqueIdBitWidth = 4
// Value: 64-1 (default 0) - 5 (partition occupancy) - 3 (ID Padding occupancy) - 4 (uniqueIdBitWidth) = 51; identifies the size of the 51st power with the upper limit of 2 in the block
final int maxAvailableBits = (VariableLong.unsignedBitLength(idUpperBound)-1)-uniqueIdBitWidth;
// Identifies the size of the 51st power with an upper limit of 2 in the block
final long idBlockUpperBound = (1L <<maxAvailableBits);
// UniquePID exhausted UniquePID set. By default, randomUniqueIDLimit = 0;
final List<Integer> exhaustedUniquePIDs = new ArrayList<>(randomUniqueIDLimit);
// The default time is 0.3 seconds, which is used to handle the TemporaryBackendException exception (there is a problem with the back-end storage): block for a period of time, and then try again
Duration backoffMS = idApplicationWaitMS;
// Starting from the beginning of obtaining the IDBlock, retry obtaining the IDBlock within the timeout (2 minutes by default)
while (methodTime.elapsed().compareTo(timeout) < 0) {
final int uniquePID = getUniquePartitionID(); // Obtain uniquePID. By default, "distributed id uniqueness control" is enabled, and the value = 0; It is a random value when "turn off distributed id uniqueness control"
final StaticBuffer partitionKey = getPartitionKey(partition,idNamespace,uniquePID); // Assemble a RowKey according to partition + idNamespace + uniquePID
try {
long nextStart = getCurrentID(partitionKey); // Obtain the maximum value allocated in the IDPool corresponding to the current partition from the Hbase, which is used as the starting value of the current application for a new block
if (idBlockUpperBound - blockSize <= nextStart) { // Ensure that the number of IDS in the id pool that has not been allocated is greater than or equal to blockSize
// Corresponding treatment
}
long nextEnd = nextStart + blockSize; // Get the maximum value of the current block you want to get
StaticBuffer target = null;
// attempt to write our claim on the next id block
boolean success = false;
try {
Timer writeTimer = times.getTimer().start(); // ===Start: start inserting your own block requirements into Hbase
target = getBlockApplication(nextEnd, writeTimer.getStartTime()); // Assembly corresponding Column: -nextEnd + current timestamp + uid (uniquely identifying the current graph instance)
final StaticBuffer finalTarget = target; // copy for the inner class
BackendOperation.execute(txh -> { // Asynchronously insert the currently generated RowKey and Column
idStore.mutate(partitionKey, Collections.singletonList(StaticArrayEntry.of(finalTarget)), KeyColumnValueStore.NO_DELETIONS, txh);
return true;
},this,times);
writeTimer.stop(); // ===End: insert complete
final boolean distributed = manager.getFeatures().isDistributed();
Duration writeElapsed = writeTimer.elapsed(); // ===Time consuming to get just inserted
if (idApplicationWaitMS.compareTo(writeElapsed) < 0 && distributed) { // Judge whether the configured timeout is exceeded. If it is exceeded, an error is reported as TemporaryBackendException, and then wait for a break to retry
throw new TemporaryBackendException("Wrote claim for id block [" + nextStart + ", " + nextEnd + ") in " + (writeElapsed) + " => too slow, threshold is: " + idApplicationWaitMS);
} else {
assert 0 != target.length();
final StaticBuffer[] slice = getBlockSlice(nextEnd); // Assemble the following lookup range of columns based on the above Rowkey: (- nextend + 0: 0nextend + maximum)
final List<Entry> blocks = BackendOperation.execute( // Asynchronously obtain the value of the specified Rowkey and the specified Column interval
(BackendOperation.Transactional<List<Entry>>) txh -> idStore.getSlice(new KeySliceQuery(partitionKey, slice[0], slice[1]), txh),this,times);
if (blocks == null) throw new TemporaryBackendException("Could not read from storage");
if (blocks.isEmpty())
throw new PermanentBackendException("It seems there is a race-condition in the block application. " +
"If you have multiple JanusGraph instances running on one physical machine, ensure that they have unique machine idAuthorities");
if (target.equals(blocks.get(0).getColumnAs(StaticBuffer.STATIC_FACTORY))) { // If the data inserted by the current graph instance is the first one in the obtained set, it means to obtain a Block; If it is not the first one, obtaining the Block fails
// Assembling IDBlock objects
ConsistentKeyIDBlock idBlock = new ConsistentKeyIDBlock(nextStart,blockSize,uniqueIdBitWidth,uniquePID);
if (log.isDebugEnabled()) {
idBlock, partition, idNamespace, uid);
}
success = true;
return idBlock; // return
} else { }
}
} finally {
if (!success && null != target) { // After obtaining the Block fails, delete the current insert; If there is no failure, keep the current insertion and identify that the Block has been occupied in hbase
//Delete claim to not pollute id space
for (int attempt = 0; attempt < ROLLBACK_ATTEMPTS; attempt++) { // Rollback: deletes the current insert. The number of attempts is 5
}
}
}
} catch (UniqueIDExhaustedException e) {
// No need to increment the backoff wait time or to sleep
log.warn(e.getMessage());
} catch (TemporaryBackendException e) {
backoffMS = Durations.min(backoffMS.multipliedBy(2), idApplicationWaitMS.multipliedBy(32));
sleepAndConvertInterrupts(backoffMS); \
}
}
throw new TemporaryLockingException();
}
The main logic is:
- Assemble Rowkey: partition + idNameSpace+unquePId
- Assemble Column: - nextEnd+now time+uid
- Insert RowKey+Column into Hbase
- The obtained RowKey of the above assembly is based on all Column sets in the (- nextend + 0: - nextend + max) range
- Judge whether the first Column of the collection is the currently inserted Column. If yes, the block will be occupied successfully, if not, the occupation will fail. Delete the occupied Column and try again
Finally: asynchronously obtain the unique occupied Block, then generate the corresponding unique count and assemble the final unique id
The overall calling process is as follows:
4: Other types of id generation
The above analysis is mainly based on the process of generating node id (vertex id)
JanusGraph also includes distributed id generation of edge id, property id and schema label id
The main ideas and logic of all types of distributed id generation are almost the same, but some specific logic may be different. We understand the distributed id generation process of vertex id, and others can also be understood.
1. Generation of property id
The overall logic for generating the distributed unique id of property in JanusGraph is roughly the same as that of vertex id;
There are two differences between the generation of property id and vertex id:
- Component of ID: in vertex id, the component includes count+partition+ID Padding; There is no ID Padding part in the property id, which consists of count + partition
long id = (count<<partitionBits)+partition;
if (type!=null) id = type.addPadding(id); // In this case, type = null
return id;
- How to obtain partition id: when generating vertex id, partition id is obtained randomly; When generating the property id, the partition id is the partition id corresponding to the obtained current node. If the node cannot obtain the partition id, it will randomly generate one;
if (element instanceof InternalRelation) { // Attribute + edge
InternalRelation relation = (InternalRelation)element;
if (attempt < relation.getLen()) {
InternalVertex incident = relation.getVertex(attempt);
Preconditions.checkArgument(incident.hasId());
if (!IDManager.VertexIDType.PartitionedVertex.is(incident.longId()) || relation.isProperty()) { // Get the existing partition id of the corresponding node
partitionID = getPartitionID(incident);
} else {
continue;
}
} else { // If there are no corresponding nodes, a partition id is randomly obtained
partitionID = placementStrategy.getPartition(element);
}
2. Generation of Edge id
The overall logic of generating the distributed unique id of edge in JanusGraph is roughly the same as that of vertex id;
There are two differences between the generation of edge id and vertex id:
- Component of ID: in vertex id, the component includes count+partition+ID Padding; There is no ID Padding part in the edge id, which consists of count + partition. The code is the same as the generated code of property id
- How to obtain partition id: when generating vertex id, partition id is obtained randomly; When generating the edge id, the partition id is the partition id corresponding to the current source vertex or target vertex obtained. If the node cannot obtain the partition id, it will randomly generate one. The code is the same as the generation code of the property id;
3. Generation of Schema related IDS
In JanusGraph, the overall logic of the generation of the distributed unique id of the schema related id is roughly the same as that of the vertex id;
There are four types of schema related id generation: PropertyKey, EdgeLabel, VertexLabel, and janusgraphsphemavertex
- Component of ID: in vertex id, the component includes count+partition+ID Padding; In the ID generation corresponding to the schema, the corresponding structures of the four generated IDs are the same: count + fixed suffix of the corresponding type
return (count << offset()) | suffix();
- How to obtain partition ID: when generating vertex id, partition ID is obtained randomly; When generating the schema id, the partition ID is the default partition id = 0;
public static final int SCHEMA_PARTITION = 0;
if (element instanceof JanusGraphSchemaVertex) {
partitionID = IDManager.SCHEMA_PARTITION; // Default partition
}
summary
This paper summarizes the generation logic of JanusGraph's distributed unique id, and also analyzes the source code of JanusGraph;
Next, JanusGraph's lock mechanism analysis, including the analysis of local locks and distributed locks. I'm "Yang Zi". I'll see you in the next issue~