Basic concepts
-
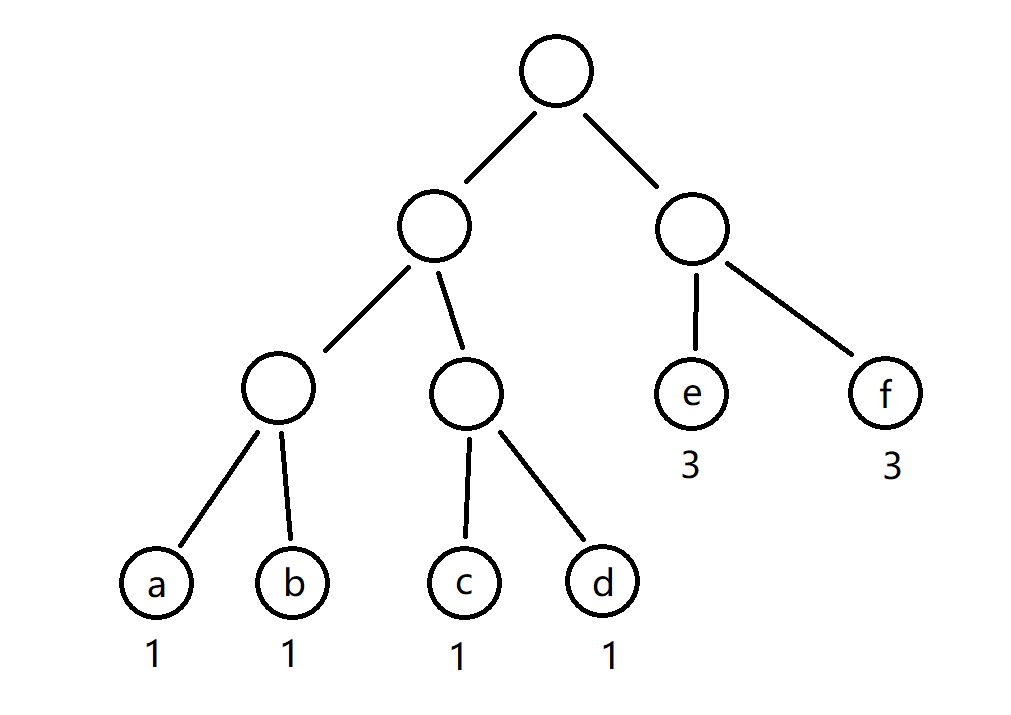
Path: the path from one node to another in a tree is called a path. In the following figure, the path from the root node to node a is a path.
-
Path length: in a path, the path length should be increased by 1 for each node. For example, in a tree, if the number of layers of the root node is specified as 1, the path length from the root node to the node of layer i is i - 1. In the following figure, the path length from root node to node c is 3.
-
Node weight: give each node a new value, which is called the weight of this node. In the following figure, the weight of node a is 1.
-
Weighted path length of a node: refers to the product of the path length from the root node to the node and the weight of the node. In the figure below, the weighted path length of node B is b * 3.
-
Weighted path length of tree: the sum of the weighted path lengths of all leaf nodes in the tree. Usually referred to as "WPL". The weighted path length of the tree shown in the figure below is:
W P L = a ∗ 3 + b ∗ 3 + c ∗ 3 + d ∗ 3 + e ∗ 2 + f ∗ 2 = 24 WPL = a * 3 + b * 3 + c * 3 + d * 3 + e * 2 + f * 2 = 24 WPL=a∗3+b∗3+c∗3+d∗3+e∗2+f∗2=24
The calculation of weighted path length can also be regarded as node merging:
1. Merge a and b as g, c and d as h, at the cost of: a + b + c + d = 4 a+b+c+d = 4 a+b+c+d=4
2. Merge g and h into i at the cost of: g + h = a + b + c + d = 4 g+h=a+b+c+d = 4 g+h=a+b+c+d=4
3. Merge e and f into j at the cost of: e + f = 6 e + f = 6 e+f=6
4. Merge i and j into k at the cost of: i + j = a + b + c + d + e + f = 10 i + j = a + b + c + d + e + f = 10 i+j=a+b+c+d+e+f=10
The total cost is 24. -
Huffman tree: when trying to build a tree with n nodes (all leaf nodes and each has its own weight), if the weighted path length of the tree is the smallest, the tree is called "optimal binary tree / Huffman tree / Huffman tree".
algorithm
How to build huffman tree?
Just follow one principle: the greater the weight, the closer the node is to the tree root
Specific methods:
1. First, select the two smallest nodes from all nodes and merge them into a new node
2. Remove the two nodes before merging and add a new node
3. Repeat steps 1 and 2 until all nodes are merged
The above figure is an example:
- a=1, b=1, c=1, d=1, e=3, f=3. The smallest nodes are a and b.
Merge a and b, and the new node g=2. - c=1, d=1, e=3, f=3, g=2. The smallest nodes are c and D
Merge c and d, new node h=2 - e=3, f=3, g=2, h=2. The smallest nodes are g and h
Merge g and h, new node i=4 - e=3, f=3, i=4, and the smallest nodes are e and F
Merge e and f, and the new node j=6 - i=4, j=6, and the smallest nodes are i and J
Merge i and j, new node k=10, merge all nodes, stop.
A small root heap can be used to find the minimum two nodes each time.
Correctness
Proof 1: in huffman tree, the two points with the smallest weight must be the deepest and can be brothers to each other.
Suppose that the weight of a point is the smallest and the depth is not the deepest.
Then, if it is exchanged with the deepest point, the weighted path length of the tree will be reduced.
Similarly, taking the following figure as an example, if f and b are exchanged, the weighted path length of these two points is from
b
∗
2
+
f
∗
3
=
1
∗
2
+
3
∗
3
=
11
b*2+f*3=1*2+3*3=11
b * 2+f * 3 = 1 * 2 + 3 * 3 = 11
b
∗
3
+
f
∗
2
=
1
∗
3
+
3
∗
2
=
9
b*3+f*2=1*3+3*2=9
b∗3+f∗2=1∗3+3∗2=9.
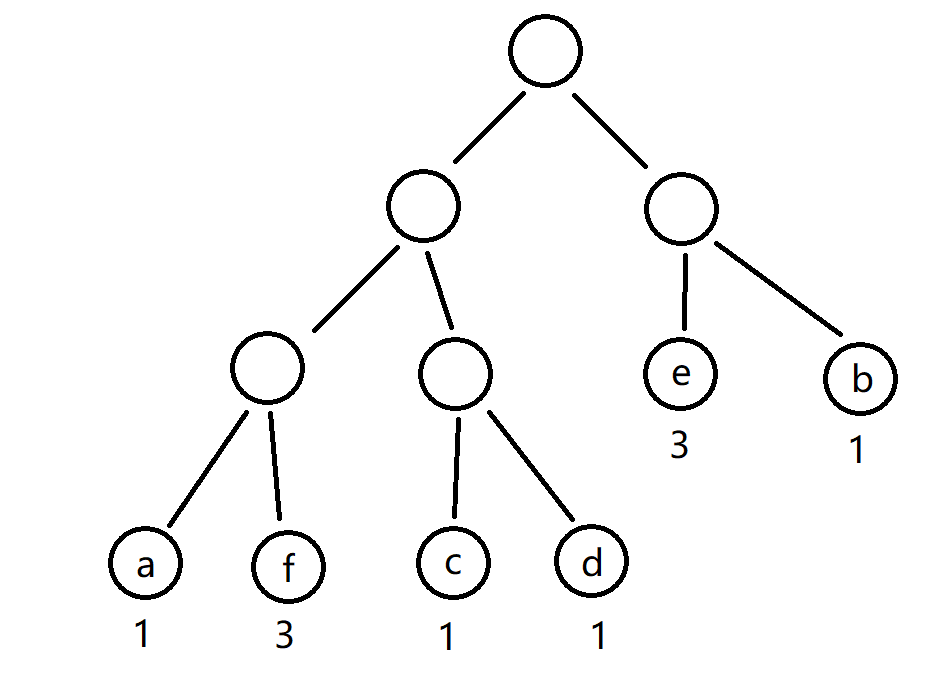 Therefore, the points with the smallest weight will be exchanged to the bottom (the deepest).
Therefore, the points with the smallest weight will be exchanged to the bottom (the deepest).
Obviously, abcd exchanges with each other, the depth remains unchanged, and the weighted path length of the tree is still the smallest.
From proof 1, we can see that the optimal solution must first merge the smallest two points, because they must be the deepest and on the same layer.
Proof 2: selecting the smallest two nodes from all nodes each time can ensure the global optimization (the weighted path length of the whole tree is the smallest)
After merging the smallest two nodes, the new node and the remaining n-2 nodes have a total of n-1 nodes.
From proof 1, we know that no matter what the merging scheme of n-1 nodes is, the optimal solution of n-node merging must first merge the smallest two points.
Therefore, we only require the minimum cost of merging n-1 nodes, plus the minimum cost of merging two nodes, we can find the global optimal solution.
The remaining n-1 nodes can repeat the above process, and then find the smallest two nodes in the N-1 nodes to merge.
Code implementation O(nlogn)

The physical strength consumed by this problem is the weighted path length of Huffman tree.
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
int n, ans;
priority_queue<int, vector<int>, greater<int> > heap;
int main() {
scanf("%d", &n);
int t;
for (int i = 0; i < n; i ++ ) {
scanf("%d", &t);
heap.push(t);
}
while (heap.size() > 1) {
int a = heap.top();
heap.pop();
int b = heap.top();
heap.pop();
heap.push(a + b);
ans += a + b;
}
printf("%d\n", ans);
return 0;
}
Bucket row \ cardinality sorting + double queue O(n)
Title Link
The n of this question is extended to
1
0
7
10^7
107, so using O(nlogn) will timeout.
Because the two smallest nodes selected each time are getting larger and larger, the merged nodes are also getting larger and larger.
First, all nodes are sorted and stored in queue a, and the smallest two nodes are selected from a and merged.
Make a new queue b save the merged node
When selecting the smallest two nodes next time, because a and b are ordered, you can directly select the smallest node from the head of the queue of a and b and select it twice.
In this way, the time for selecting the minimum two nodes is reduced to O(1)
Because the fast row is nlogn, because the number range of this question is very small( 1 ≤ a i ≤ 1 0 5 1≤a_i≤10^5 1 ≤ ai ≤ 105), to be replaced with O(n) bucket row. If the number range is large, it can be changed to close O ( ( n + b ) l o g b n ) O((n+b)log_{b}n) Cardinality sorting of O((n+b)logb # n).
Pay attention to read in with long long and handwriting. scanf will timeout.
Bucket sorting
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
int n;
long long ans;
int bucket[100005];
queue<long long> a, b;
inline int read(){
int ret = 0, f = 1; char ch = getchar();
while (ch < '0' || ch > '9') { if (ch == '-') f = -1; ch = getchar(); }
while (ch >= '0' && ch <= '9') ret = ret * 10 + ch - '0', ch = getchar();
return ret * f;
}
int main() {
scanf("%d", &n);
long long t, max_t = 0;
for (int i = 0; i < n; i ++ ) {
// scanf("%d", &t);
t = read();
bucket[t] ++ ;
max_t = max(max_t, t);
}
for (int i = 0; i <= max_t; i ++ ) {
while(bucket[i] -- ) a.push(i);
}
for (int i = 1; i < n; i ++ ) {
long long t1, t2;
if (b.empty() || (!a.empty() && a.front() <= b.front() )) {
t1 = a.front();
a.pop();
}
else {
t1 = b.front();
b.pop();
}
if (b.empty() || (!a.empty() && a.front() <= b.front() )) {
t2 = a.front();
a.pop();
}
else {
t2 = b.front();
b.pop();
}
b.push(t1 + t2);
ans += t1 + t2;
}
printf("%lld\n", ans);
return 0;
}
Cardinality sort
#include <iostream>
#include <algorithm>
#include <queue>
#include <cstring>
using namespace std;
int n;
long long ans;
int x[10000005], y[10000005], cnt[260];
queue<long long> a, b;
inline int read() {
int ret = 0, f = 1; char ch = getchar();
while (ch < '0' || ch > '9') { if (ch == '-') f = -1; ch = getchar(); }
while (ch >= '0' && ch <= '9') ret = ret * 10 + ch - '0', ch = getchar();
return ret * f;
}
int main() {
scanf("%d", &n);
long long t, max_t = 0;
for (int i = 0; i < n; i ++ ) x[i] = read();
for (int i = 0; i <= 17; i += 8) {
memset(cnt, 0, sizeof cnt);
for (int j = 0; j < n; j ++ ) cnt[(x[j] >> i) & 255] ++ ;
for (int j = 1; j < 256; j ++ ) cnt[j] += cnt[j - 1];
for (int j = n - 1; j >= 0; j -- ) { // Sweep a from the back to the front, decrease cnt from high to low, and put b from the back to the front, which is equivalent to doing
y[ -- cnt[(x[j] >> i) & 255]] = x[j];
}
for (int j = 0; j < n; j ++ ) x[j] = y[j];
}
for (int i = 0; i < n; i ++ ) a.push(x[i]);
for (int i = 1; i < n; i ++ ) {
long long t1, t2;
if (b.empty() || (!a.empty() && a.front() <= b.front() )) {
t1 = a.front();
a.pop();
}
else {
t1 = b.front();
b.pop();
}
if (b.empty() || (!a.empty() && a.front() <= b.front() )) {
t2 = a.front();
a.pop();
}
else {
t2 = b.front();
b.pop();
}
b.push(t1 + t2);
ans += t1 + t2;
}
printf("%lld\n", ans);
return 0;
}