Hadoop[03-03] access count test based on DFS and ZKFC (Hadoop 2.0)
Prepare the environment
Prepare multiple virtual machines and start dfs and zookeeper
See link for details: Hadoop2.0 start DFS and Zookeeper
Some data of multiple virtual machines are as follows
| number | host name | Host domain name | ip address |
|---|---|---|---|
| ① | Toozky | Toozky | 192.168.64.220 |
| ② | Toozky2 | Toozky2 | 192.168.64.221 |
| ③ | Toozky3 | Toozky3 | 192.168.64.222 |
Set ssh secret free connection
See link for details: ssh secret free connection of Linux virtual machine
resource list
| Software | Software version |
|---|---|
| VMware | VMware® Workstation 16 Pro |
| Xshell | 6 |
| filezilla | 3.7.3 |
Start zookeeper and dfs
Virtual machines ①, ②, ③
zkServer.sh start
Virtual machine ①
Take virtual machine ① as namenode as an example
start-all.sh
Test upload file access count
IDEA creates a normal Maven project
pom.xml
In the project tag
Add dependencies to the dependencies tab
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--Log dependency-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
Add build
<build>
<!--appoint visitcount Export for jar name-->
<finalName>visitcount</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<!--Specifies the main class of the program-->
<mainClass>mapreduce.WordCountJobRun</mainClass>
</manifest>
</archive>
<descriptorRefs>
<!--appoint jar Add description to package name-->
<!--export jar Package name is visitcount-jar-with-dependencies.jar-->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
mapreduce
Create the mapreduce layer in the main/java directory of the project
VisitCountMapper.java
Create the visitcountmapper.com in the mapreduce layer java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class VisitCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
String[] split = s.split(" ");
for (int i = 6; i < split.length; i+=9) {
context.write(new Text(split[i]),new LongWritable(1));
}
}
}
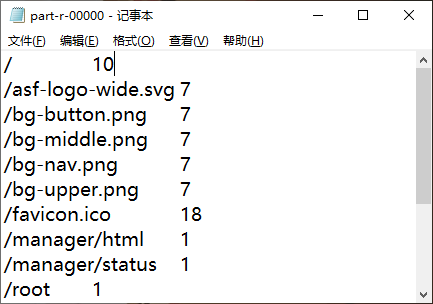
Since the data file separates the fields with spaces (and the newline character does not separate the fields), and the URL column is regular, the for loop sets the initial traversal subscript to 6 and the self increment to 9

As shown in the above figure, the 7th, 16th, 25th... (9n-2) are web address fields
So subscript 6, 15, 24... (9n-3)
VisitCountReducer.java
Create visitcountreducer in mapreduce layer java
Edit counter program
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class VisitCountReducer extends Reducer<Text, LongWritable, Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Long sum=0l;
for (LongWritable iterable : values) {
sum+=iterable.get();
}
context.write(key,new LongWritable(sum));
}
}
VisitCountJobRun.java
Create visitcountjobrun in mapreduce layer java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class VisitCountJobRun {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf=new Configuration();
Job job=new Job(conf);
//String Hadoop_Url = "hdfs://Toozky:8020";
job.setJarByClass(VisitCountJobRun.class);
job.setMapperClass(VisitCountMapper.class);
job.setReducerClass(VisitCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//job.setNumReduceTasks(1); Set the number of reduce tasks
//Input data file
FileInputFormat.addInputPath(job,new Path("/input/logs.txt"));
//Output data file
FileOutputFormat.setOutputPath(job,new Path("/output/logs_deal"));
//Submit job
boolean result = job.waitForCompletion(true);
//Follow up operation after successful execution
if (result) {
System.out.println("Access counting task completed!");
}
}
}
Through the configuration of the following related setting files, the program does not need to specify the namenode domain name, and the working mode will change to access the address of namenode(active) by itself
resources
In the / src/main/resources directory of the project (if not, create the resources directory)
Install core - site. In the hadoop installation directory xml,hdfs-site.xml,mapred-site. Copy XML to resources
(in the virtual machine / home / Hadoop 2.6/etc/hadoop, use filezilla to download files locally)
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://dfbz</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Toozky:2181,Toozky2:2181,Toozky3:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop2.6</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>dfbz</value>
</property>
<property>
<name>dfs.ha.namenodes.dfbz</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dfbz.nn1</name>
<value>Toozky:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.dfbz.nn2</name>
<value>Toozky2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.dfbz.nn1</name>
<value>Toozky:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.dfbz.nn2</name>
<value>Toozky2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Toozky:8485;Toozky2:8485;Toozky3:8485/dfbz</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.dfbz</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journal/node/local/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Export the access count jar package and upload the test data file
visitcount-jar-with-dependencies.jar
Click the Maven menu on the right side of IDEA to expand the project, and click package (export jar package)
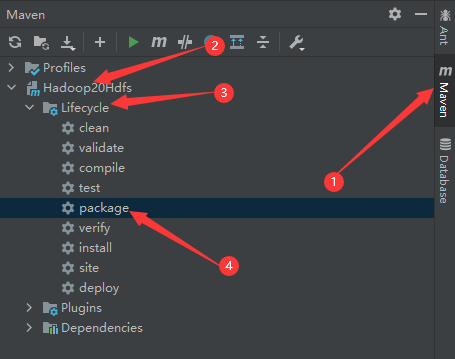
After clicking package, the target directory will be generated in the project. Select the required jar package and copy it with ctrl+c
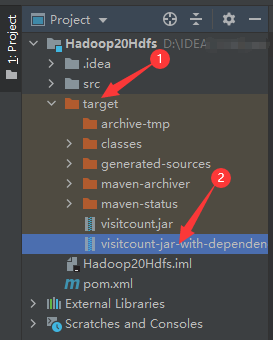
Add visitcount jar with dependencies Paste the jar to a convenient location and send it to the / root directory of the virtual machine ① with filezilla
logs.txt
logs. The test data in TXT file is as follows
The file is localhost of logs in Tomcat installation directory_ access_ log. xxxx_ xx_ xx. Txt copy and rename to logs Txt get
Use filezilla to add logs Txt file is uploaded to the / root directory of virtual machine ①
Upload test data to HDFS
Verify the upload in virtual machine ①
cd ls
Create / input directory in DFS system to store relevant files before processing
hadoop dfs -mkdir /input
Supplement:
Deletion of directory in DFS hadoop dfs -rmr / directory or file name
Send logs Txt to HDFS
cd hadoop dfs -put logs.txt /input/
Execute TestVisitCount project
Run the jar file
cd hadoop jar visitcount-jar-with-dependencies.jar
Access count verification
Browser authentication
Enter Toozky:50070 in the browser address bar (namenode(active) domain name: 50070)
Click Browse the file system to enter the DFS file system
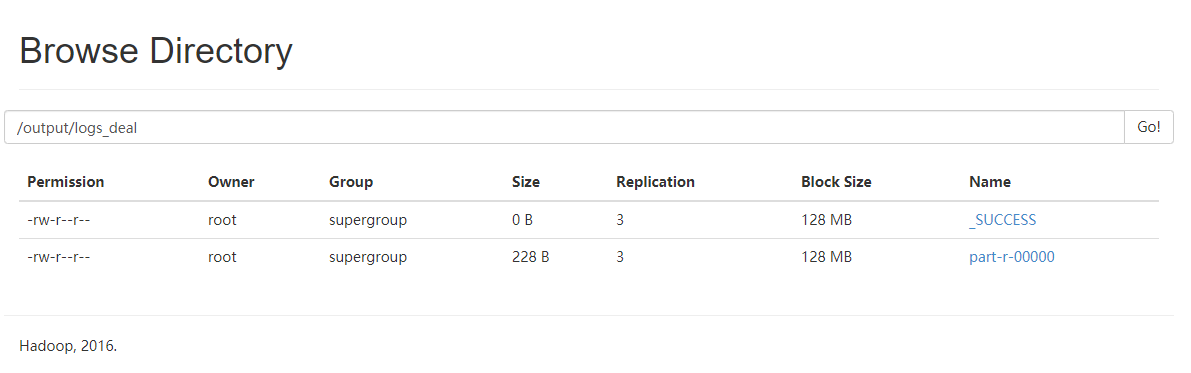
Click output to view the output directory, and click logs_deal
See_ SUCCESS indicates that the operation is successful
Click part-r-00000 to Download the file and click Download to Download the file verification results
The above is the whole content of this summary. I hope you can learn from each other and make common progress!