1, Introduction to SecondaryNameNode
When analyzing the edits log files just now, we have introduced the SecondaryNameNode. Here is a summary to show our attention.
The secondary namenode is mainly responsible for regularly merging the contents of the edits file into the fsimage
This merge operation is called checkpoint. When merging, the content in edits will be converted to generate new content and saved to fsimage file.
Note: there is no SecondaryNameNode process in the HA architecture of NameNode, and the file merging operation will be implemented by standby NameNode
Therefore, in Hadoop clusters, the SecondaryNameNode process is not necessary.
2, DataNode introduction
DataNode is a storage service that provides real file data
There are two main concepts for datanode: block and replication
The first is block
HDFS will divide and number the files according to the fixed size and order. Each divided Block is called a Block. The default Block size of HDFS is 128MB
Blokc block is the basic unit for HDFS to read and write data. Whether your file is a text file or a video or audio file, it is bytes for HDFS.
We uploaded a user Txt file. Its block information can be seen in fsimage file or hdfs webui. There is block id information in it, and it will also show which node the data is on
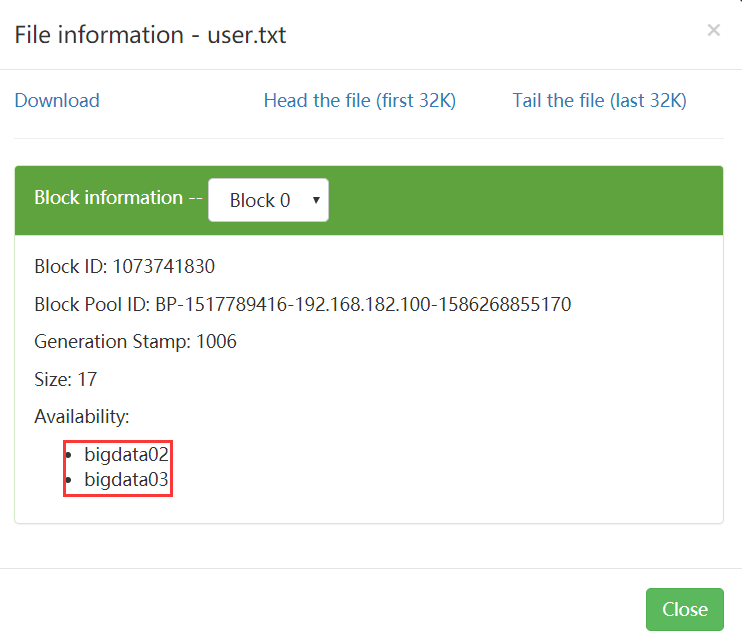
It is shown here on bigdata02 and bigdata03. Let's take a look. The specific storage location of data in datanode is determined by DFS datanode. data. Dir, by querying HDFS default XML can know that the specific location is here.
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices. The directories should be tagged
with corresponding storage types ([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]) for HDFS
storage policies. The default storage type will be DISK if the directory does
not have a storage type tagged explicitly. Directories that do not exist will
be created if local filesystem permission allows.
</description>
</property>
Let's connect to the node bigdata02 and have a look
[root@bigdata02 ~]# cd /data/hadoop_repo/dfs/data/ [root@bigdata02 data]# ll total 4 drwxr-xr-x. 3 root root 72 Apr 7 22:21 current -rw-r--r--. 1 root root 14 Apr 8 20:30 in_use.lock
Then enter the current directory and continue all the way down
[root@bigdata02 data]# cd current/ [root@bigdata02 current]# ll total 4 drwx------. 4 root root 54 Apr 8 20:30 BP-1517789416-192.168.182.100-1586268855170 -rw-r--r--. 1 root root 229 Apr 8 20:30 VERSION [root@bigdata02 current]# cd BP-1517789416-192.168.182.100-1586268855170/ [root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# ll total 4 drwxr-xr-x. 4 root root 64 Apr 8 20:25 current -rw-r--r--. 1 root root 166 Apr 7 22:21 scanner.cursor drwxr-xr-x. 2 root root 6 Apr 8 20:30 tmp [root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# cd current/ [root@bigdata02 current]# ll total 8 -rw-r--r--. 1 root root 20 Apr 8 20:25 dfsUsed drwxr-xr-x. 3 root root 21 Apr 8 15:34 finalized drwxr-xr-x. 2 root root 6 Apr 8 22:13 rbw -rw-r--r--. 1 root root 146 Apr 8 20:30 VERSION [root@bigdata02 current]# cd finalized/ [root@bigdata02 finalized]# ll total 0 drwxr-xr-x. 3 root root 21 Apr 8 15:34 subdir0 [root@bigdata02 finalized]# cd subdir0/ [root@bigdata02 subdir0]# ll total 4 drwxr-xr-x. 2 root root 4096 Apr 8 22:13 subdir0 [root@bigdata02 subdir0]# cd subdir0/ [root@bigdata02 subdir0]# ll total 340220 -rw-r--r--. 1 root root 22125 Apr 8 15:55 blk_1073741828 -rw-r--r--. 1 root root 183 Apr 8 15:55 blk_1073741828_1004.meta -rw-r--r--. 1 root root 1361 Apr 8 15:55 blk_1073741829 -rw-r--r--. 1 root root 19 Apr 8 15:55 blk_1073741829_1005.meta -rw-r--r--. 1 root root 17 Apr 8 20:31 blk_1073741830 -rw-r--r--. 1 root root 11 Apr 8 20:31 blk_1073741830_1006.meta -rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741831 -rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741831_1007.meta -rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741832 -rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741832_1008.meta -rw-r--r--. 1 root root 77190019 Apr 8 22:13 blk_1073741833 -rw-r--r--. 1 root root 603055 Apr 8 22:13 blk_1073741833_1009.meta
There are a lot of block blocks in it,
be careful: What's in here.meta Documents are also used for verification.
According to the blockid information you saw earlier, you can find the corresponding file directly. It is found that the content of the file is the content we uploaded before.
[root@bigdata02 subdir0]# cat blk_1073741830 jack tom jessic [root@bigdata02 subdir0]#
be careful
this block The contents in may only be part of the file. If your file is large, it will be divided into multiple files block Storage, default hadoop3 One in block The size of the is 128 M. Intercept according to bytes, and intercept to 128 M Just one block. If there is no default file size block If it's big, there's only one in the end block.
In HDFS, if a file is smaller than the size of a data block, it will not occupy the storage space of the whole data block.
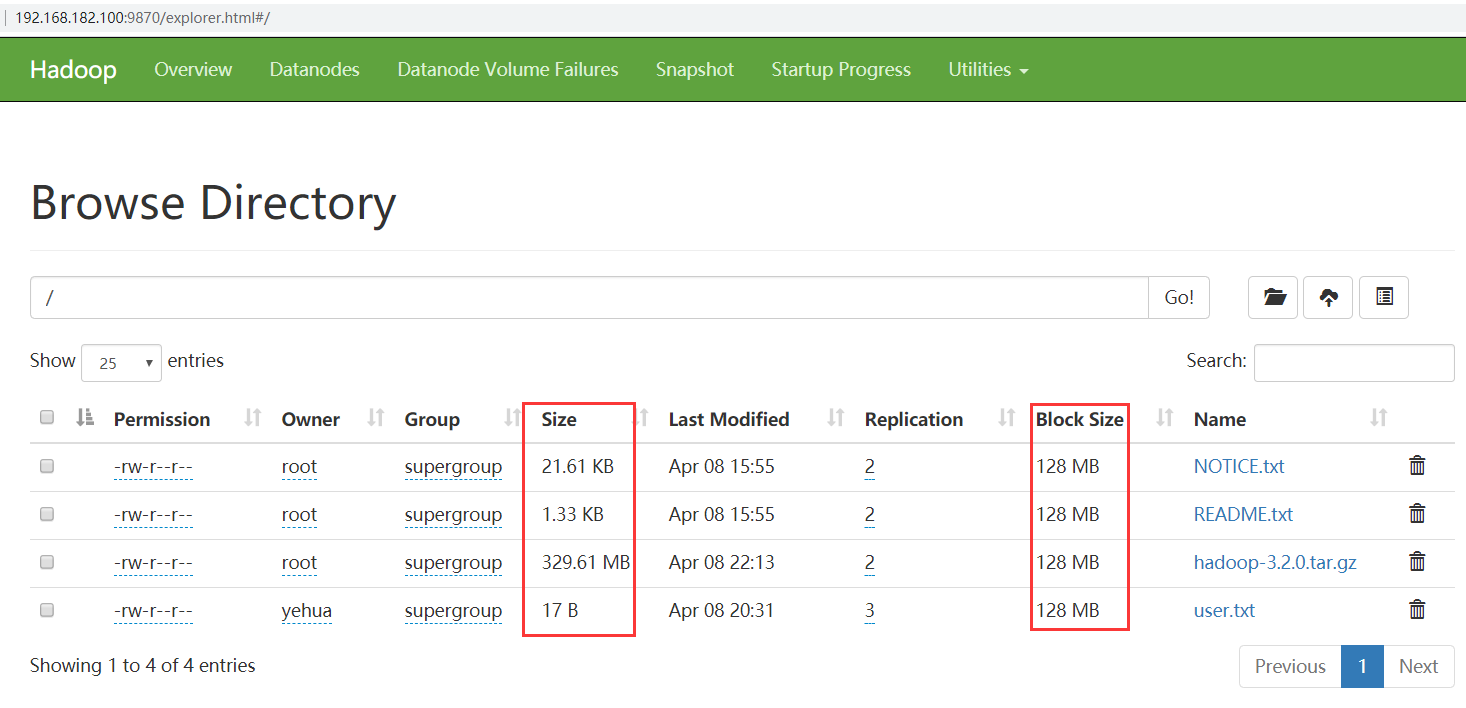
Size refers to the actual size of the uploaded file, and blocksize refers to the maximum block size of the file.
be careful; this block Block is hdfs Generated, if we upload the file directly to this block The directory where the file is located. At this time hdfs It's unrecognized and useless
Suppose we upload two 10M files and another 200M file
Q1: how many block blocks will be generated? 4
Q2: how many files will be displayed in hdfs? 3
Let's take a look at the replica. The replica indicates how many backups of data there are
Our current cluster has two slave nodes, so there can be at most two backups. This is on HDFS site XML, DFS replication
The default configuration of this parameter is 3. Indicates that there will be 3 copies.
Replica has only one function, which is to ensure data security.
3, NameNode summary
be careful: block Where are blocks stored datanode In fact, only datanode I know that when the cluster starts, datanode It will scan all nodes on its own block Block information, and then put the node and all on this node block Block information to namenode. This relationship is dynamically loaded every time the cluster is restarted [this is actually why the more data the cluster has, the slower it starts]
The fsimage(edits) file we mentioned earlier contains the information between the file and the block block.
What we are talking about here is the relationship between block blocks and nodes. After these two blocks are associated, we can find the corresponding block block according to the file, and then find the corresponding datanode node according to the block block. In this way, we can really find the data.
Therefore, in fact, namenode not only maintains the information of files and block blocks, but also maintains the information of block blocks and datanode nodes.
It can be understood that namenode maintains two relationships:
The first relationship: the relationship between file and block list. The corresponding relationship information is stored in fsimage and edits files. When NameNode is started, the metadata information in the file will be loaded into memory
The second relationship: the relationship between datanode and block. The corresponding relationship is mainly saved in memory when the cluster starts. When the datanode starts, it will report the block information and node information on the current node to the NameNode
Attention, we just said NameNode When starting, the metadata information in the file will be loaded into memory, and then the metadata information of each file will occupy 150 bytes of memory space. This is constant and has nothing to do with the file size. We introduced it earlier HDFS When I said, HDFS It is not suitable for storing small files. In fact, the main reason is here. Whether it is a large file or a small file, the metadata information of a file is NameNode Will take up 150 bytes, NameNode The memory of a node is limited, so its storage capacity is also limited. If we store a pile, how many are there KB Small file, finally found NameNode The memory is full, and many files are indeed stored, but the overall size of the files is very small, so they are lost HDFS Value of existence
Finally, there is also a VERSION file in the current directory under the data directory of datanode
There are some similarities between this VERSION and the VERSION file of namenode. Let's specifically compare the contents of the two files.
VERSION file of namenode
[root@bigdata01 current]# cat VERSION #Wed Apr 08 20:30:00 CST 2020 namespaceID=498554338 clusterID=CID-cc0792dd-a861-4a3f-9151-b0695e4c7e70 cTime=1586268855170 storageType=NAME_NODE blockpoolID=BP-1517789416-192.168.182.100-1586268855170 layoutVersion=-65
VERSION file of datanode
[root@bigdata02 current]# cat VERSION #Wed Apr 08 20:30:04 CST 2020 storageID=DS-0e86cd27-4961-4526-bacb-3b692a90b1b0 clusterID=CID-cc0792dd-a861-4a3f-9151-b0695e4c7e70 cTime=0 datanodeUuid=0b09f3d7-442d-4e28-b3cc-2edb0991bae3 storageType=DATA_NODE layoutVersion=-57
We said earlier that namenode should not be formatted casually, because after formatting, the clusterID in VERSION will change, but the clusterID in VERSION of datanode does not change, so it cannot correspond.
We said before that if you really want to reformat, you need to change / data / Hadoop_ The contents in the repo data directory are emptied and all can be regenerated.