hadoop basic configuration and pseudo distribution implementation
catalogue
1, Basic environmental preparation
-
Operating system preparation
-
Installing ubuntu virtual machines
Mirror address: https://mirrors.nju.edu.cn/ubuntu-releases/18.04/ubuntu-18.04.6-desktop-amd64.iso
-
If docker is used
docker pull ubuntu:18.04
-
-
Source change
-
Backup start source list
-
sudo cp /etc/apt/sources.list /etc/apt/sources.list_backup
-
-
Open the source list (gedit command is to open the editor of ubuntu. If it is docker, it needs to be replaced with vi command)
-
sudo gedit /etc/apt/sources.list
-
-
Add the following at the beginning of the file
-
# Ali source deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
-
-
Refresh List
-
sudo apt-get update sudo apt-get upgrade sudo apt-get install build-essential
-
-
-
Install java
-
Download openJdk directly
-
sudo apt-get update sudo apt-get install openjdk-8-jdk
-
-
Verify java
-
java -version
-
-
-
Install other software
-
Install ssh
-
sudo apt-get install ssh
-
Generate ssh key
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Get native ssh access
ssh-copy-id localhost
After pressing enter, you will be asked to confirm whether to join the hostList. Enter "yes" and press enter
Then you need to enter your local password
-
Test ssh access
ssh localhost
Install rsync
-
sudo apt-get install rsync
-
-
2, Single machine hadoop installation and configuration
-
hadoop installation
-
Download hadoop compressed package
-
cd ~ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
-
-
Unzip it here
-
hadoop@ubuntu:~$ tar –zxvf hadoop-3.2.2.tar.gz
-
-
Check whether the decompression is successful
-
hadoop@ubuntu:~$ ls Desktop Downloads hadoop-3.2.2 Music Public Videos Documents examples.desktop hadoop-3.2.2.tar.gz Pictures Templates
-
Is there a folder for hadoop-3.2.2?
-
-
Configure JAVA_HOME environment variable
-
gedit ~/hadoop-3.2.2/etc/hadoop/hadoop-env.sh
-
Find "# export JAVA_HOME =" in the editor
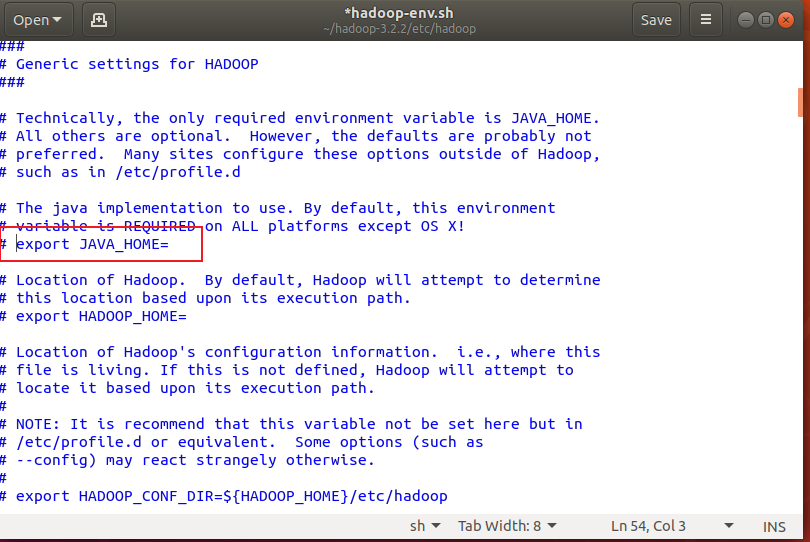
Change this line to export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64, save and exit
-
PS: the above address is obtained by entering the following command and then looking at the output
update-alternatives --config java
-
-
-
hadoop configuration - single machine pseudo distributed
First of all, the configuration here, often a space, a punctuation mark or case error will lead to the final operation failure, so be sure to check before entering!!
-
core-site.xml
-
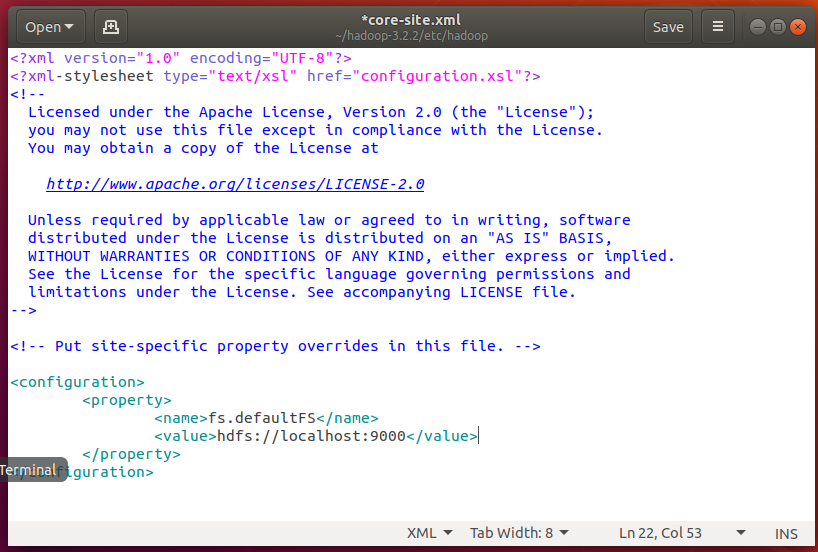
open editor
gedit ~/hadoop-3.2.2/etc/hadoop/core-site.xml
-
Insert the configuration without adding comments
<configuration> # to configure <property> # A property <name>fs.defaultFS</name> # The name of the property is this <value>hdfs://localhost:9000</value> # The value of the property is this, which is the path of hdfs </property> # The closed label of the attribute must have a slash </configuration>
-
-
hdfs-site.xml
-
gedit ~/hadoop-3.2.2/etc/hadoop/hdfs-site.xml
Write the following
<configuration> <property> <name>dfs.replication</name> # Number of data backups <value>1</value> # The number of backups is one </property> </configuration>
-
-
3, Hadoop operation
-
Start hadoop and run tasks
-
Format NameNode and start
-
format
~/hadoop-3.2.2/bin/hdfs namenode -format
-
Start NameNode
~/hadoop-3.2.2/sbin/start-dfs.sh
-
View cluster status
hadoop@ubuntu:~$ jps 10960 NameNode 11529 Jps 11115 DataNode 11372 SecondaryNameNode
-
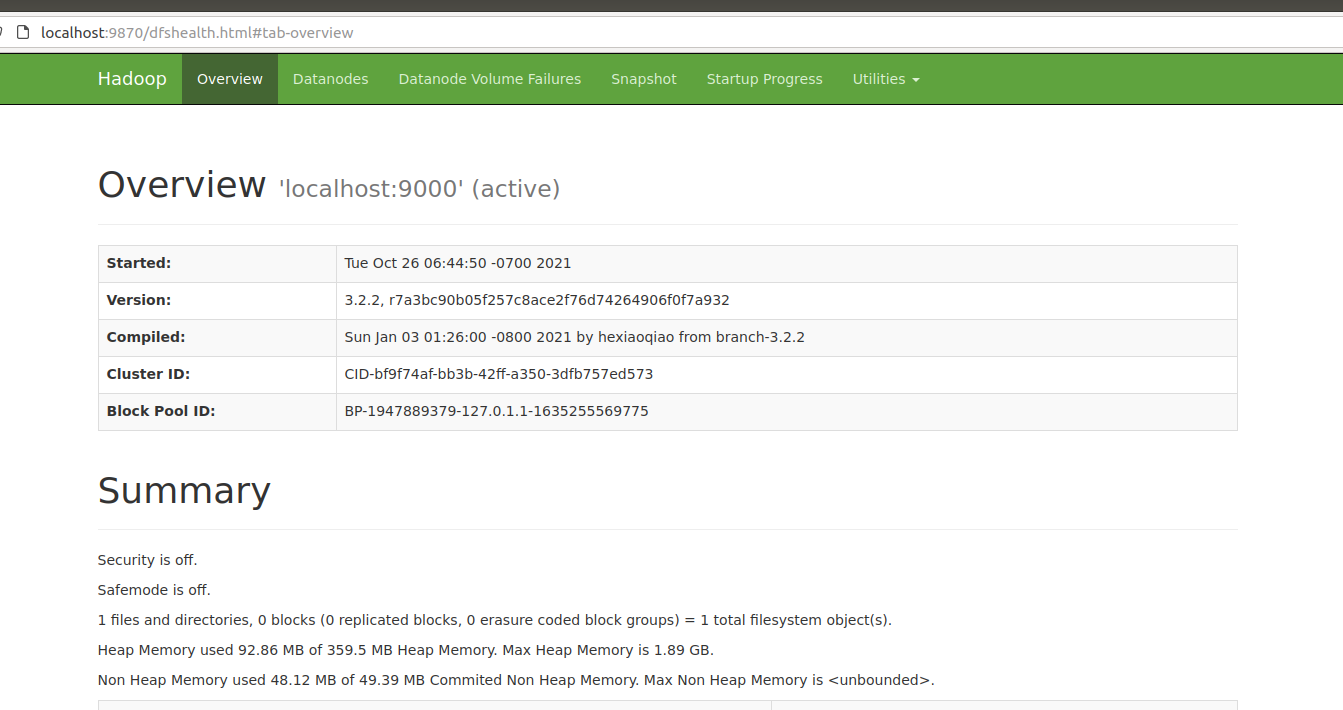
Browse the web interface of NameNode
Open directly in the browser of the virtual machine http://localhost:9870
-
-
Perform some hdfs operations (which will be frequently used later, remember by heart)
hdfs is a file system. Its operation is similar to that of the computer's file browser. It has operations such as creating folders, moving files, etc
-
Create hdfs directory
~/hadoop-3.2.2/bin/hdfs dfs -mkdir /user # -mkdir path is the create directory ~/hadoop-3.2.2/bin/hdfs dfs -mkdir /user/input
-
Copy input files to hdfs
~/hadoop-3.2.2/bin/hdfs dfs -put ~/hadoop-3.2.2/etc/hadoop/*.xml /user/input # -put a b is to place the local a on b of hdfs
This operation is to copy all files with xml suffix in the etc/hadoop / directory after - put to the / user/hadoop directory of hdfs file system
-
Check the hdfs file
hadoop@ubuntu:~$ ~/hadoop-3.2.2/bin/hdfs dfs -ls /user/input # -ls a lists all files in directory a Found 9 items -rw-r--r-- 1 hadoop supergroup 9213 2021-10-26 06:54 /user/hadoop/capacity-scheduler.xml -rw-r--r-- 1 hadoop supergroup 867 2021-10-26 06:54 /user/hadoop/core-site.xml -rw-r--r-- 1 hadoop supergroup 11392 2021-10-26 06:54 /user/hadoop/hadoop-policy.xml -rw-r--r-- 1 hadoop supergroup 849 2021-10-26 06:54 /user/hadoop/hdfs-site.xml -rw-r--r-- 1 hadoop supergroup 620 2021-10-26 06:54 /user/hadoop/httpfs-site.xml -rw-r--r-- 1 hadoop supergroup 3518 2021-10-26 06:54 /user/hadoop/kms-acls.xml -rw-r--r-- 1 hadoop supergroup 682 2021-10-26 06:54 /user/hadoop/kms-site.xml -rw-r--r-- 1 hadoop supergroup 758 2021-10-26 06:54 /user/hadoop/mapred-site.xml -rw-r--r-- 1 hadoop supergroup 690 2021-10-26 06:54 /user/hadoop/yarn-site.xml
-
-
Run MapReduce
-
Run the sample that comes with hadoop
~/hadoop-3.2.2/bin/hadoop jar ~/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep /user/input /user/output 'dfs[a-z.]+'
Analyze the following:
- ~/hadoop-3.2.2/bin/hadoop: call Hadoop program
- Jar: to execute the jar instruction of this program is to tell the program to run the jar package
- ~/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar: the address of the jar package to be executed
- Grep: grep is the instruction in the jar package, which is similar to the above relationship between jar and hadoop (the main class is specified in the hadoop program written by yourself later, so you can not fill in this branch instruction)
- /user/input: is the input address
- /user/output: is the output address. Both addresses are addresses on hdfs. It should be noted that the / user/output directory cannot exist in advance
- '' dfs[a-z.] + ': is a parameter of the grep instruction. What grep does is filter text. This parameter tells grep to filter text according to this mode.
-
View run results:
-
First get the results on hdfs to local
~/hadoop-3.2.2/bin/hdfs dfs -get /user/output ~/output
-
Read results
cat ~/output/* # cat is a command that displays text
-
-
-
Finally, close the hadoop cluster. Close the cluster before modifying the configuration
~/hadoop-3.2.3/sbin/stop-dfs.sh
-