preface
Part of the content is extracted from the training materials of Shang Silicon Valley, dark horse and so on
1. Get to know MapReduce
1.1 understand MapReduce idea
MapReduce thought can be seen everywhere in life, and everyone has been exposed to it more or less. The core idea of MapReduce is "divide and then combine, divide and rule". The so-called "divide and rule" is to divide a complex problem into several equivalent smaller parts according to a certain "decomposition" method, and then solve them one by one, find out the results of each part respectively, and form the results of each part into the results of the whole problem.
this idea comes from the experience of daily life and work. It is also fully applicable to a large number of complex task processing scenarios (large-scale data processing scenarios). Even Google, which has published papers to realize distributed computing, only realizes this idea, not its own originality.
Map is responsible for "dividing", that is, dividing complex tasks into several "simple tasks" for parallel processing. The premise of splitting is that these small tasks can be calculated in parallel and have little dependency on each other.
Reduce is responsible for "closing", that is, the global summary of the results of the map stage.
the combination of these two stages is the embodiment of MapReduce thought.
a more vivid language to explain MapReduce:
we need to count all the cars in the parking lot. You count the first column and I count the second column. This is "Map". The more people we have, the more people we can count cars at the same time, and the faster we can speed up.
after counting, we got together and added up everyone's statistics. This is "Reduce".
1.2 scenario: how to simulate distributed computing
1.2.1 what is distributed computing
distributed computing is a computing method, which is opposite to centralized computing.
with the development of computing technology, some applications need very huge computing power to complete. If centralized computing is adopted, it will take quite a long time to complete.
distributed computing decomposes the application into many small parts and distributes them to multiple computers for processing. This can save the overall calculation time and greatly improve the calculation efficiency.
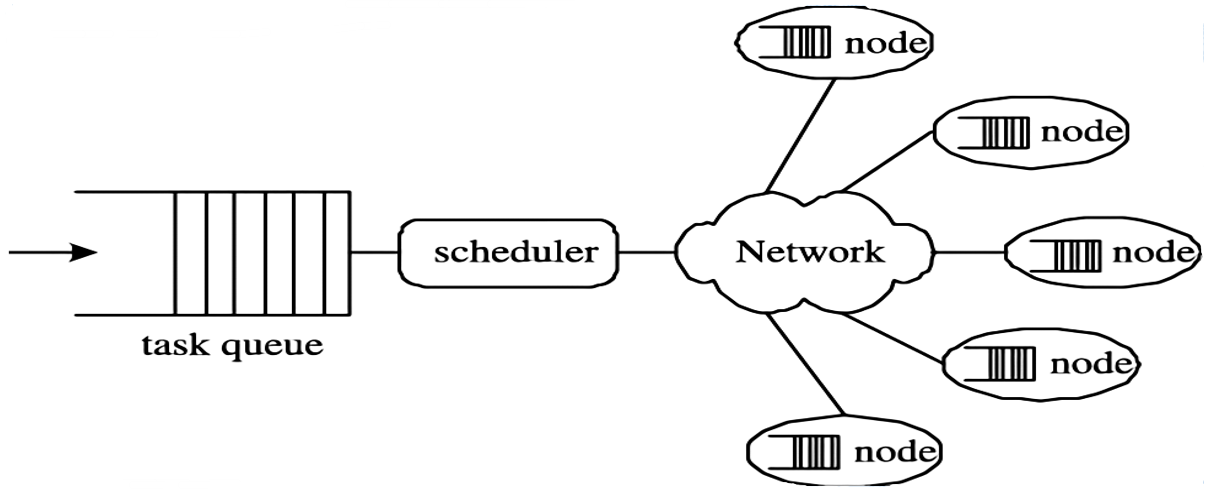
1.2.2 simulation implementation in big data scenario
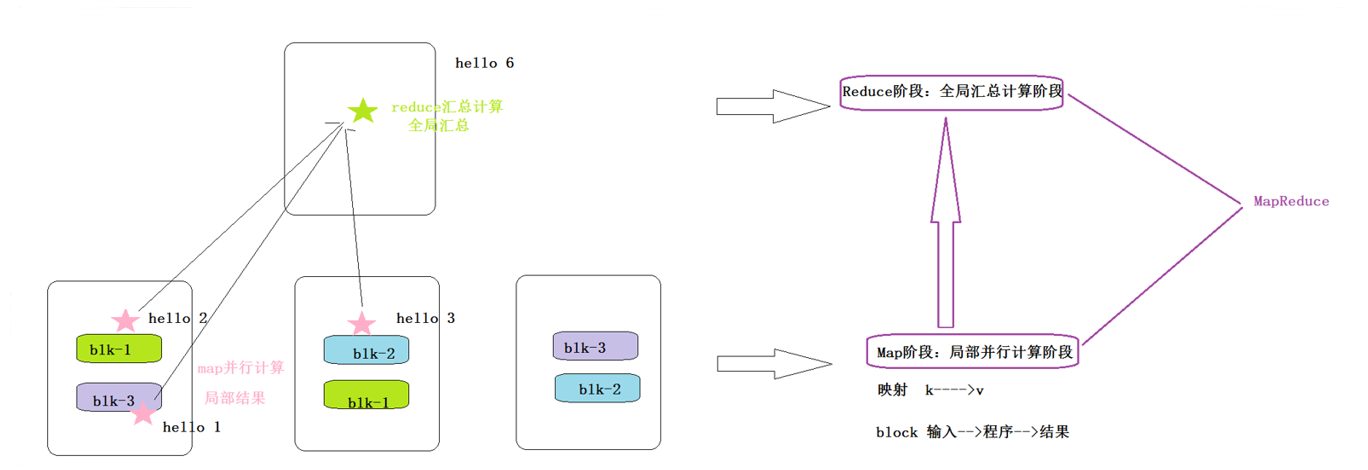
1.3 design concept of Hadoop MapReduce
MapReduce is a module of Hadoop and a programming framework for distributed computing programs.
for many developers, it is too difficult to completely implement a parallel computing program by themselves, and MapReduce is a programming model that simplifies parallel computing and reduces the entry threshold for developing parallel applications.
the idea of Hadoop MapReduce is embodied in the following three aspects.
1.3.1 how to deal with big data processing
for big data computing tasks that do not have computing dependencies, the most natural way to achieve parallelism is to adopt the strategy of MapReduce divide and conquer.
that is, the Map stage is divided into several stages. The big data is divided into several small data, and multiple programs calculate in parallel at the same time to produce intermediate results; Then there is the Reduce aggregation stage. The final summary calculation of the parallel results is carried out through the program to obtain the final result.
the first important problem of parallel computing is how to divide computing tasks or computing data so that the divided subtasks or data blocks can be calculated at the same time. Non separable computing tasks or mutually dependent data cannot be calculated in parallel!
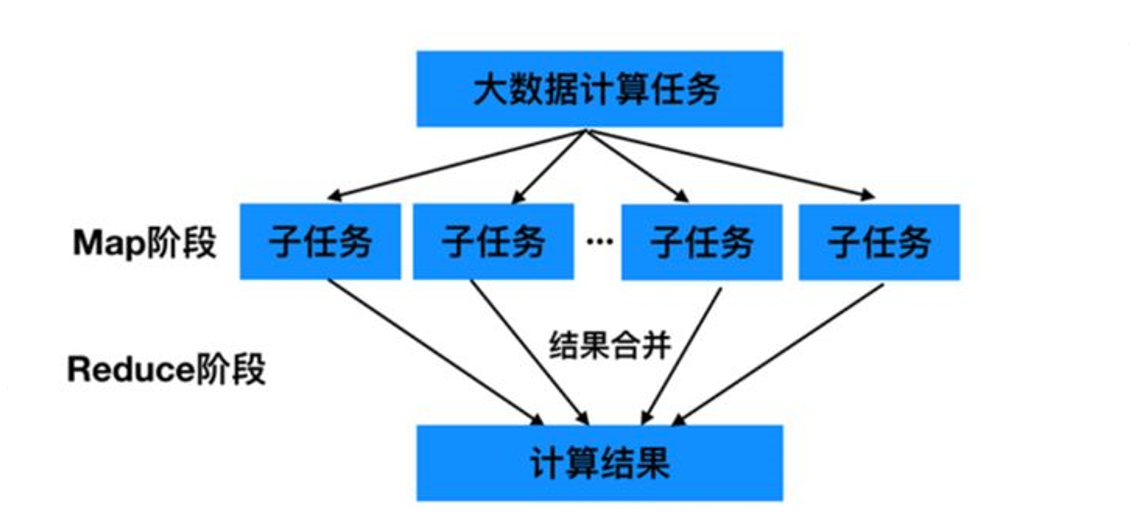
1.3.2 building an abstract model
MapReduce draws lessons from the idea of functional language and provides a high-level parallel programming abstract model with Map and Reduce functions.
Map: perform some repetitive processing on a group of data elements;
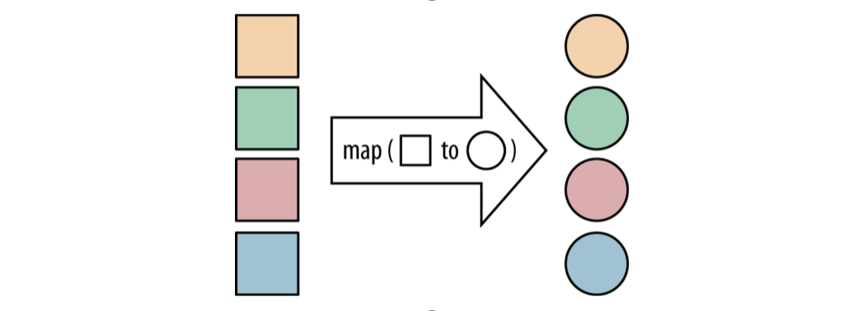
Reduce: sort out the intermediate results of Map.
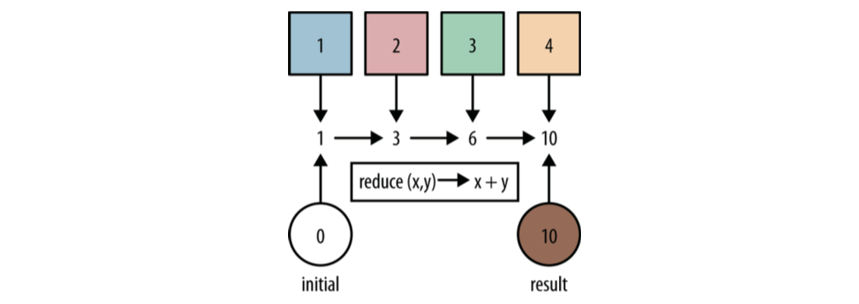
MapReduce defines the following two abstract programming interfaces: Map and Reduce, which are programmed and implemented by users:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map and Reduce provide programmers with a clear abstract description of the operation interface. Through the above two programming interfaces, you can see that the data type processed by MapReduce is < key, value > key value pairs.
1.3.3 unify the architecture and hide the underlying details
how to provide a unified computing framework? If the underlying details are not uniformly encapsulated, programmers need to consider many details such as data storage, division, distribution, result collection, error recovery and so on; To this end, MapReduce designs and provides a unified computing framework, hiding most of the system level processing details for programmers.
the biggest highlight of MapReduce is that it separates what needs to do from how to do through abstract model and computing framework, providing an abstract and high-level programming interface and framework for programmers.
programmers only need to care about the specific calculation problems of their application layer, and only need to write a small amount of program code to deal with the calculation problems of the application itself. Many system level details related to how to complete this parallel computing task are hidden and handed over to the computing framework: from the execution of distributed code to the automatic scheduling of thousands of small to single node clusters.
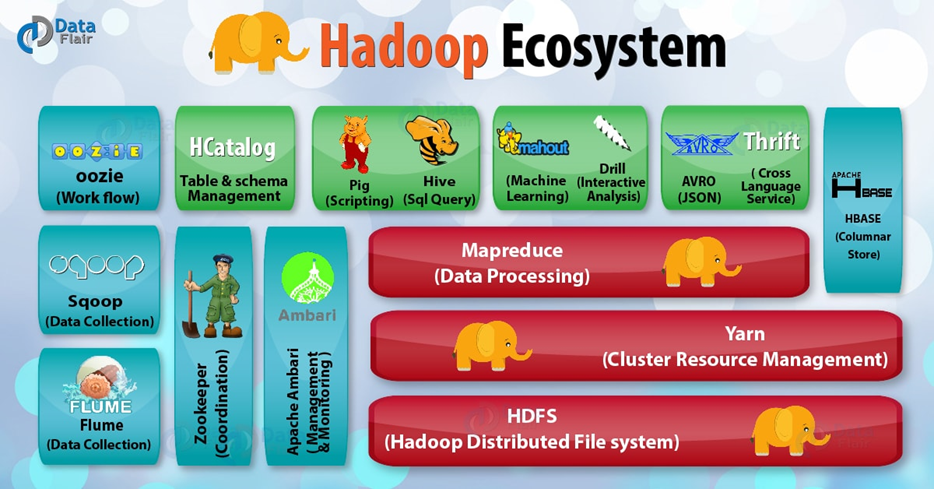
2. Introduction to Hadoop MapReduce
2.1 introduction to MapReduce
Hadoop MapReduce is a programming framework for distributed computing programs, which is used to easily write applications that process large amounts of data (multi TB data sets) on large hardware clusters (thousands of nodes) in parallel in a reliable and fault-tolerant manner.
MapReduce is a guiding ideology for massive data processing and a programming model for distributed computing of large-scale data.
the core function of MapReduce is to integrate the business logic code written by the user and its own default components into a complete distributed computing program, which runs concurrently on a Hadoop cluster.
MapReduce was first proposed by Google in a paper entitled "MapReduce: simplified data processing on large clusters" in 2004. The process of distributed data processing is divided into two operation functions: Map and Reduce (inspired by Lisp and other functional programming languages), which is then referenced by Apache Hadoop and supported as an open source version. Its appearance solves the problem that people are helpless in the initial face of massive data. At the same time, it is easy to use and highly scalable, which makes it easy for developers to write distributed data processing programs and run in tens of thousands of ordinary commercial servers without relating to the complexity of the bottom of the distributed system.
2.2 MapReduce features
- Easy to program
- Mapreduce framework provides an interface for secondary development; Simply implementing some interfaces can complete a distributed program. Task computing is handled by the computing framework. Distributed programs are deployed to hadoop clusters, and the cluster nodes can be expanded to hundreds and thousands.
- Good scalability
- When computer resources can not be met, we can expand its computing power by adding machines. Distributed computing based on MapReduce can maintain approximately linear growth with the growth of the number of nodes. This feature is the key for MapReduce to process massive data. By increasing the number of computing nodes to hundreds or thousands, it can easily process hundreds of TB or even PB of off-line data.
- High fault tolerance
- Hadoop cluster is built and deployed in a distributed way. When any single machine node goes down, it can transfer the above computing tasks to another node for operation without affecting the completion of the whole job task. The process is completely completed by Hadoop.
- Suitable for offline processing of massive data
- Can handle GB, TB and PB levels of data
Map3. Reduce limitations
although MapReduce has many advantages and relative limitations, it does not mean that it cannot be done, but the effect achieved in some scenarios is relatively poor, which is not suitable for processing with MapReduce. It is mainly reflected in the following results:
- Poor real-time computing performance
- MapReduce is mainly used for offline jobs, which cannot respond to second or sub second data.
- Flow calculation cannot be performed
- The characteristic of streaming computing is that the data is continuously calculated and the data is dynamic; As an offline computing framework, MapReduce is mainly aimed at static data sets, and the data cannot change dynamically.
- Not good at DAG (directed acyclic graph) calculation
- Multiple applications have dependencies, and the input of the latter application is the output of the previous one. In this case, MapReduce is not impossible, but after use, the output results of each MapReduce job will be written to the disk, which will cause a lot of disk IO, resulting in very low performance.
3. Hadoop MapReduce programming
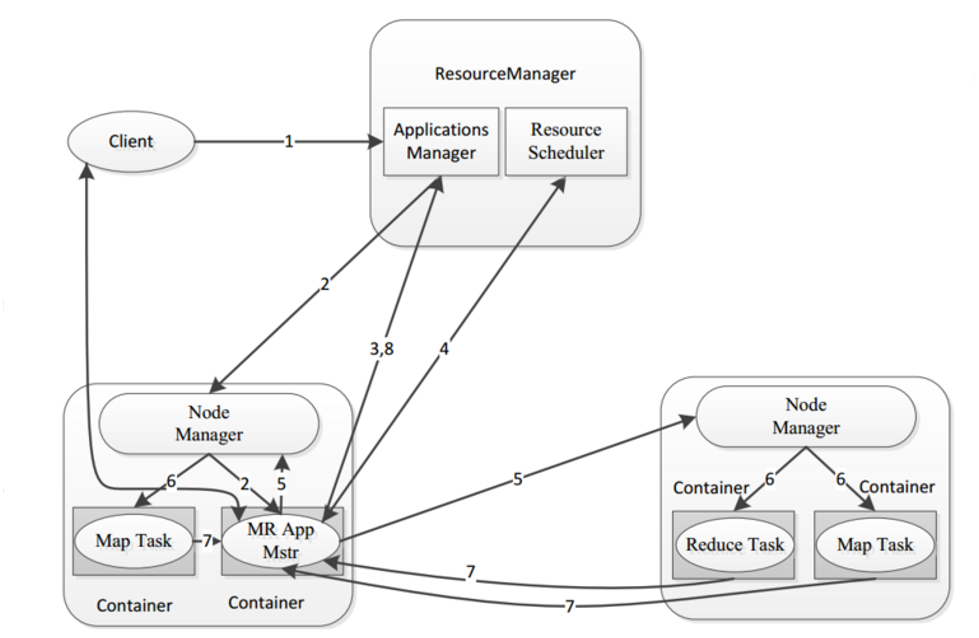
3.1 MapReduce architecture
a complete mapreduce program has three types of instance processes in distributed Runtime:
- MRAppMaster: responsible for the process scheduling and state coordination of the whole program.
- MapTask: responsible for the entire data processing process in the Map phase.
- ReduceTask: responsible for the entire data processing process in the Reduce phase.
3.2 MapReduce programming specification
MapReduce distributed computing program needs to be divided into two stages: Map stage and Reduce stage. The map phase corresponds to the concurrent instance of MapTask, which runs completely in parallel and irrelevant to each other. The Reduce phase corresponds to the ReduceTask concurrent instance, and the data depends on the data output results of all MapTask concurrent instances in the previous phase.
the MapReduce programming model can only contain one Map phase and one Reduce phase. If the user's business logic is very complex, it can only run multiple MapReduce programs in series.
the program written by the user is divided into three parts: Mapper, Reducer and Driver (submit the client Driver running mr program).
user defined Mapper and Reducer should inherit their respective parent classes. The business logic in Mapper is written in the map() method, and the business logic of Reducer is written in the reduce() method. The whole program needs a Driver to submit, which is a job object that describes all kinds of necessary information.
the most important thing to note is that in the whole MapReduce program, data flows in the form of kv key value pairs. Therefore, in the actual programming to solve various business problems, we need to consider what the input and output kv of each stage are. In MapReduce, data will be sorted and grouped by some default mechanisms. Therefore, the determination of kv type data is very important.
3.3 Map Reduce workflow
the whole MapReduce workflow can be divided into three stages: map, shuffle and reduce.
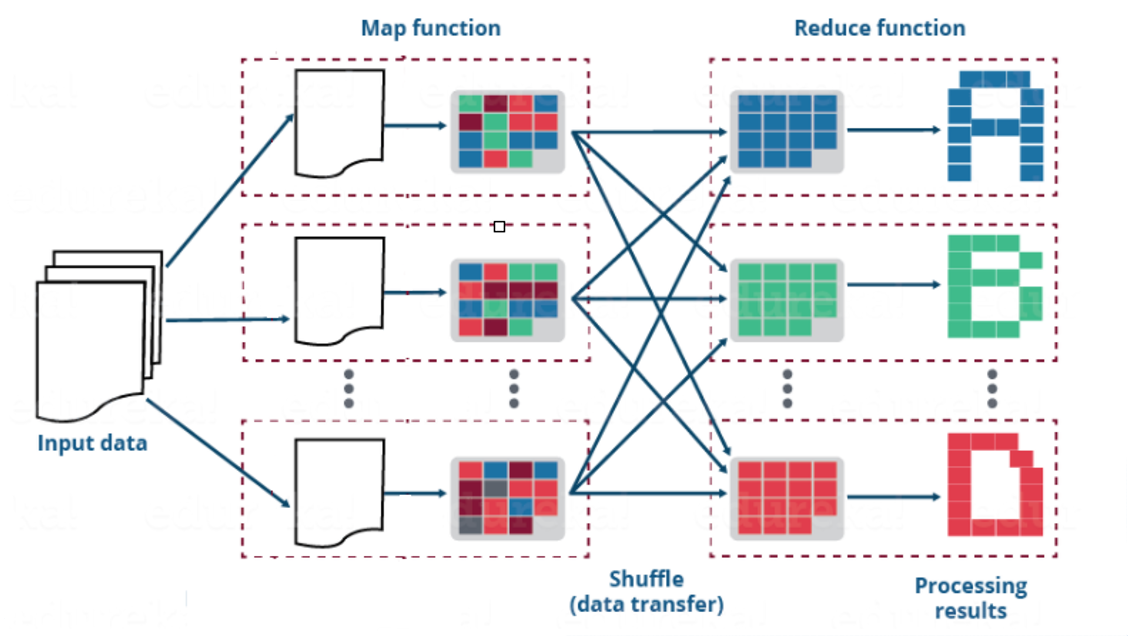
- map phase:
- It is responsible for processing the data read from the data source. By default, the read data returns the type of kv key value pair. After being processed by the user-defined map method, the output should also be the type of kv key value pair.
- shuffle phase:
- The data output from map will be reorganized through partition, sorting, grouping and other self-contained actions, which is equivalent to the reverse process of shuffling. This is the core and difficulty of MapReduce. It is also worthy of our in-depth exploration.
- Default partition rule: the same key is divided in the same partition, and the same partition is processed by the same reduce.
- Default sorting rule: sort by key dictionary
- Default grouping rule: the same key s are divided into one group. One group calls reduce for processing once.
- reduce phase:
- Responsible for aggregation processing of shuffle data. The output should also be a kv key value pair.
4. Hadoop serialization mechanism
4.1 what is serialization
Serialization is the process of converting structured objects into byte streams for network transmission or writing to persistent storage.
Deserialization is the process of converting a byte stream into a series of structured objects and re creating the object.
purpose of serialization:
- As a persistent format.
- As a data format for communication.
- As a data copy and cloning mechanism.
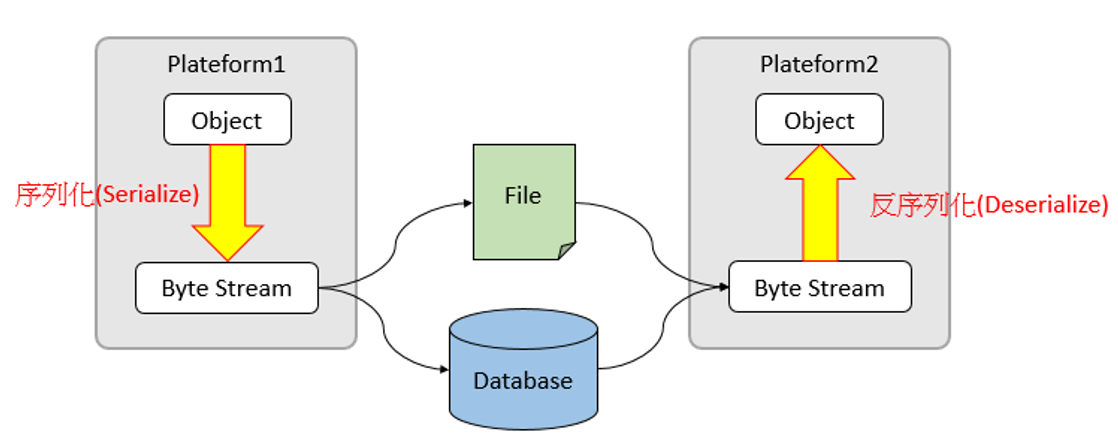
simple overview:
the process of converting an object into a sequence of bytes is called object serialization.
the process of restoring a byte sequence to an object is called object deserialization.
4.2 Java serialization mechanism
in Java, everything is an Object. In a distributed environment, it is often necessary to transfer objects from one end of the network or device to the other. This requires a protocol that can transmit data at both ends. Java serialization mechanism is produced to solve this problem.
the mechanism of Java object serialization represents the object as a binary byte array, which contains the data of the object, the type information of the object, the type information of the data inside the object, and so on. By saving or transferring these binary arrays, we can achieve the purpose of persistence and transmission.
to implement serialization, you need to implement Java io. Serializable interface. Deserialization is the opposite process of serialization, that is, the process of converting binary arrays into objects.
4.3 serialization mechanism of Hadoop
the serialization of Hadoop does not adopt the serialization mechanism of java, but implements its own serialization mechanism.
the reason is that the serialization mechanism of java is bulky and heavyweight. It is a mechanism for continuously creating objects, and it will attach a lot of additional information (verification, inheritance relationship system, etc.). However, in the serialization mechanism of Hadoop, users can reuse objects, which reduces the allocation and recycling of java objects and improves the application efficiency.
Hadoop implements the serialization mechanism through the Writable interface, but does not provide the comparison function. Therefore, it is combined with the Comparable interface in java to provide an interface WritableComparable (user-defined comparison).
The Writable interface provides two methods (write and readFields).
package org.apache.hadoop.io;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
4.4 data types in Hadoop
Hadoop provides the following data types. These data types implement the WritableComparable interface, so that the data defined by these types can be serialized for network transmission, file storage, and size comparison.
| Hadoop data type | Java data type | remarks |
|---|---|---|
| BooleanWritable | boolean | Standard Boolean value |
| ByteWritable | byte | Single byte value |
| IntWritable | int | integer |
| FloatWritable | float | Floating point number |
| LongWritable | long | Long integer number |
| DoubleWritable | double | Double byte value |
| Text | String | Text stored in UTF8 format |
| MapWritable | map | mapping |
| ArrayWritable | array | array |
| NullWritable | null | Used when the key or value in < key, value > is empty |
note: if you need to transfer customized classes in the key, you also need to implement the Comparable interface, because the Shuffle process in the MapReduce box requires that you can sort the keys.
5. MapReduce classic introduction case
5.1 WordCount business requirements
WordCount is called word statistics and word frequency statistics in Chinese. It refers to the use of programs to count the total number of occurrences of each word in a text file. This is a classic entry-level case in the field of big data computing. Although the business is extremely simple, I hope to feel the execution process and default behavior mechanism of MapReduce through the case, which is the key.
# Input data 1 txt hello hadoop hello hello hadoop allen hadoop ------------------------------------------ # Output results hello 3 hadoop 3 allen 1
5.2 MapReduce programming ideas
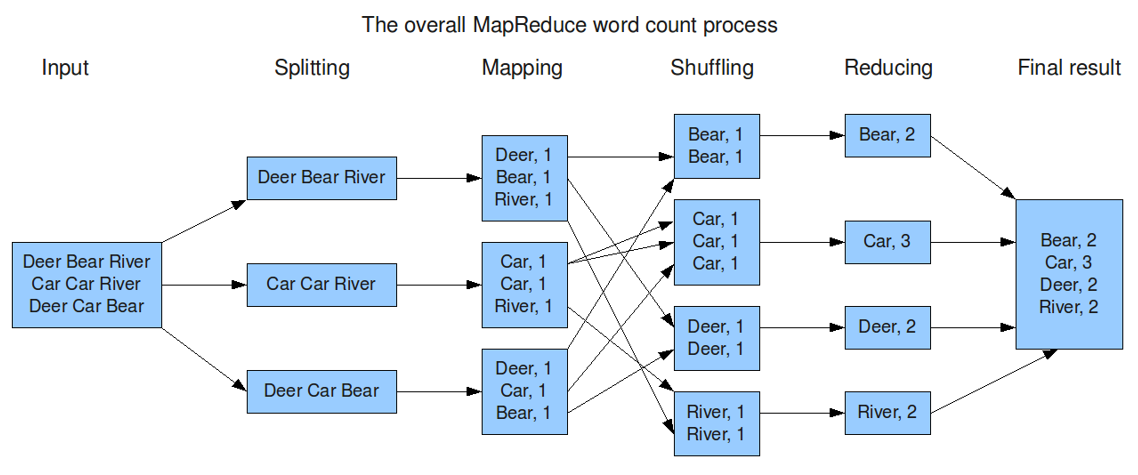
core of map stage: cut the input data and mark all 1. So the output is < word, 1 >.
shuffle stage core: after default sorting and partition grouping, words with the same key will form a new kv pair as a set of data.
core of reduce stage: a group of data processed after shuffle, which is all key value pairs of the word. The total number of times to sum up all 1 is the total number of times of the word. Final output < words, total times >.
5.3 WordCount programming
5.3.1 establishment of programming environment
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HdfsDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>cental</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- Google Options -->
<dependency>
<groupId>com.github.pcj</groupId>
<artifactId>google-options</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.itcast.sentiment_upload.Entrance</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
5.3.2 Mapper class preparation
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
//Mapper output kv key value pair < word, 1 >
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Cut the read line according to the separator
String[] words = value.toString().split("\\s+");
//Traversal word array
for (String word : words) {
keyOut.set(word);
//Output the word and mark 1
context.write(new Text(word),valueOut);
}
}
}
5.3.3 Reducer class writing
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//Statistical variables
long count = 0;
//Traverse a group of data and take out all value s of the group
for (LongWritable value : values) {
//The sum of all value s is the total number of times of the word
count +=value.get();
}
result.set(count);
//Output final resu lt < words, total times >
context.write(key,result);
}
}
5.3.4 client driver class writing
5.3.4.1 mode 1: direct build job start
public class WordCountDriver_v1 {
public static void main(String[] args) throws Exception {
//Profile object
Configuration conf = new Configuration();
// Create job instance
Job job = Job.getInstance(conf, WordCountDriver_v1.class.getSimpleName());
// Set job driven class
job.setJarByClass(WordCountDriver_v1.class);
// Set job mapper reducer class
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// Set the output key value data type of job mapper stage
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//Set the output key value data type of the job reducer stage, that is, the final output data type of the program
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// Configure the input data path of the job
FileInputFormat.addInputPath(job, new Path(args[0]));
// Configure the output data path of the job
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Determine whether the output path exists. If so, delete it
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// Submit the job and wait for execution to complete
boolean resultFlag = job.waitForCompletion(true);
//Program exit
System.exit(resultFlag ? 0 :1);
}
}
5.3.4.2 method 2: start Tool class creation
public class WordCountDriver_v2 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// Create job instance
Job job = Job.getInstance(getConf(), WordCountDriver_v2.class.getSimpleName());
// Set job driven class
job.setJarByClass(WordCountDriver_v2.class);
// Set job mapper reducer class
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// Set the output key value data type of job mapper stage
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//Set the output key value data type of the job reducer stage, that is, the final output data type of the program
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// Configure the input data path of the job
FileInputFormat.addInputPath(job, new Path(args[0]));
// Configure the output data path of the job
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Determine whether the output path exists. If so, delete it
FileSystem fs = FileSystem.get(getConf());
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// Submit the job and wait for execution to complete
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//Profile object
Configuration conf = new Configuration();
//Using the tool classtoolrunner submitter
int status = ToolRunner.run(conf, new WordCountDriver_v2(), args);
//Exit the client program. The client exit status code is bound to the execution result of MapReduce program
System.exit(status);
}
}
6. MapReduce program running
the so-called operation mode is: does mr program run alone or distributed? Is the computing resource required by mr program allocated by yarn or single machine system?
the mode of operation depends on the following parameters:
mapreduce.framework.name=yarn, cluster mode
mapreduce.framework.name=local, local mode
the default is the local mode in mapred default Defined in XML. If there is a configuration in the code and in the running environment, the default configuration will be overwritten by default.
6.1 local mode operation
The mapreduce program is submitted to LocalJobRunner and runs locally in the form of a single process. The processed data and output results can be in the local file system or on hdfs.
the essence is whether there is MapReduce in the conf of the program framework. name=local.
the local mode is very convenient for debug ging business logic.
right click to directly run the main class where the main method is located.
6.2 cluster mode operation
submit the mapreduce program to the yarn cluster and distribute it to many nodes for concurrent execution. The processed data and output should be located on the hdfs file system.
print the program into a jar package, and then start it on any node of the cluster with the following command:
hadoop jar wordcount.jar com.mapreduce.WordCountDriver args yarn jar wordcount.jar com.mapreduce.WordCountDriver args
7. MapReduce input and output sorting
MapReduce framework operates on < key, value > key value pairs, that is, the framework regards the input of the job as a group of < key, value > key value pairs, and also generates a group of < key, value > key value pairs as the output of the job. These two groups of key value pairs may be different.

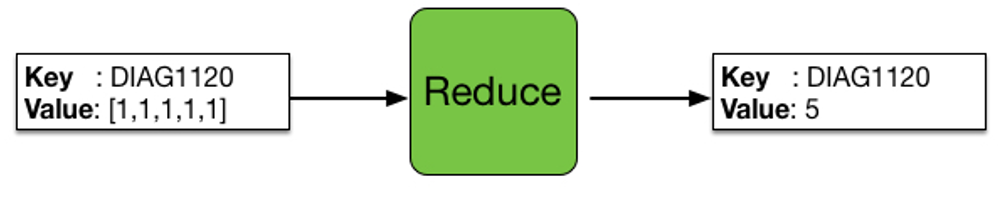
7.1 input characteristics
the component that reads data by default is called TextInputFormat.
about input path:
- If you point to a file, process the file
- If you point to a folder (directory), process all the files in the directory as a whole.
7.2 output characteristics
the component that outputs data by default is called TextOutputFormat.
the output path cannot exist in advance, otherwise an error is reported and the output path is detected and judged.
8. Simple sorting of MapReduce process
8.1 execution flow chart
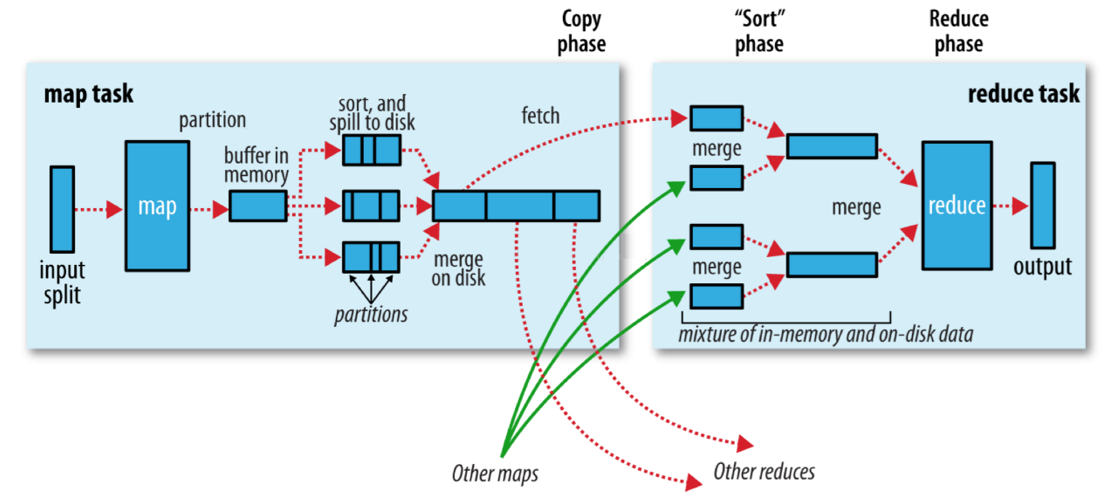
8.2 Map stage execution process
- The first stage is to logically slice the files in the input directory one by one according to certain standards to form a slice planning. By default, Split size=Block size. Each slice is processed by a MapTask (getSplits).
- The second stage is to parse the data in the slice into < key, value > pairs according to certain rules. The default rule is to parse each line of text content into key value pairs. Key is the starting position of each line (in bytes), and value is the text content of the line (TextInputFormat).
- The third stage is to call the map method in Mapper class. For each < K, V > parsed in the previous stage, the map method is called once. Every time the map method is called, zero or more key value pairs will be output.
- The fourth stage is to partition the key value pairs output in the third stage according to certain rules. By default, there is only one area. The number of partitions is the number of Reducer tasks running. By default, there is only one Reducer task.
- The fifth stage is to sort the key value pairs in each partition. First, sort by key. For key value pairs with the same key, sort by value. For example, for three key value pairs < 2,2 >, < 1,3 >, < 2,1 >, the key and value are integers respectively. Then the sorted results are < 1,3 >, < 2,1 >, < 2,2 >. If there is a sixth stage, enter the sixth stage; If not, output directly to the file.
- The sixth stage is the local aggregation processing of data, that is, combiner processing. Key value pairs with equal keys will call the reduce method once. After this stage, the amount of data will be reduced. It is not available by default at this stage.
8.3 execution process of redue stage
- The first stage is that the Reducer task will actively copy its output key value pairs from the Mapper task. There may be many Mapper tasks, so Reducer will copy the output of multiple mappers.
- The second stage is to merge all the local data copied to Reducer, that is, merge the scattered data into one large data. Then sort the merged data.
- The third stage is to call the reduce method for the sorted key value pairs. Key value pairs with equal keys call the reduce method once, and each call will produce zero or more key value pairs. Finally, these output key value pairs are written to the HDFS file.
in the whole development process of MapReduce program, our biggest workload is to cover map function and reduce function.