1, Overview of MapReduce performance optimization
1. Application scenario of MapReduce
Hadoop includes HDFS, an open source implementation of GFS (Hadoop distributed file system) and the open source implementation of MapReduce framework. Hadoop has attracted the attention of enterprises and academia. Many companies and technical groups such as Yahoo, Facebook, cloudera, Twitter, Intel and Huawei have given strong support to Hadoop. Cloudera has integrated, optimized and tested the version compatibility of Apache Hadoop and related components, and launched its Open source Hadoop of enterprise version. Intel has launched an efficient, secure and easy to manage Hadoop enterprise version. Due to its open source nature, Hadoop has become an important sample and foundation for the current research and optimization of cloud computing framework. Among them, MapReduce framework is very suitable for processing document analysis, inverted index establishment and other applications. However, in column storage, index establishment, connection calculation and iterative calculation The performance of scientific computing and scheduling algorithms needs to be further optimized.
2. Advantages, disadvantages and requirements
1. Advantages
- Mapreduce is easy to program
As like as two peas, it can be implemented by simply implementing some interfaces, which can be distributed to a large number of inexpensive pc machines. That is to say, you write a distributed program, which is exactly the same as writing a simple serial program. This is because Mapreduce programming is very popular. - Good scalability
In the project, when your computing resources are not satisfied, you can simply expand its computing power by adding machines - High fault tolerance
Mapreduce is designed to enable programs to be deployed on cheap pc machines, which requires it to have high fault tolerance. For example, if a machine hangs up, it can transfer the above computing tasks to another node to run, so that the task will not fail, and this process does not require manual participation, but is completely completed within hadoop. - It is suitable for offline processing of massive data above PB level
2. Disadvantages

Although MapReduce has many advantages, there are also some things it is not good at. The "not good at" here does not mean that it cannot be done, but the effect achieved in some scenarios is poor and is not suitable for processing with MapReduce, mainly in the following results:
- Real time calculation: MapReduce mainly processes data from the file system, so it cannot return results in millimeter or second level like Oracle or MySQL. If a large amount of millisecond level response is required, it can be realized in combination with the real-time storage system, using HBase, Kudu, etc
- Stream computing: the input data of stream computing is dynamic, while the main input of MapReduce comes from file systems such as HDFS. The data is static and cannot change dynamically. This is because the design characteristics of MapReduce determine that the data source must be static. If streaming data needs to be processed, stream computing frameworks such as Storm,Spark Steaming and Flink can be used.
- DGA (directed acyclic graph) Calculation: multiple applications have dependencies, and the input of the latter application is the output of the previous one. In this case, MapReduce cannot do it, but after use, the output results of each MapReduce job will be written to disk, resulting in a large number of word frequency IO and very low performance. At this time, you can consider using Spark and other iterative calculation frameworks.
Based on the above problems, MapReduce mainly considers how to improve performance and speed up the distributed computing process in the process of solving offline distributed computing.
3. Demand
Based on the shortcomings of the whole MapReduce, since the overall structure of MapReduce has been fixed, the overall optimization scheme can only be considered and implemented from the following two points:
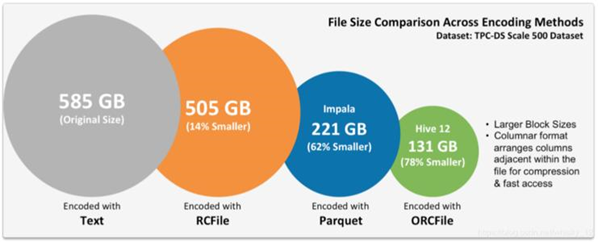
- Using the idea of column storage to optimize the storage structure, column storage can improve the query performance in applications such as data warehouse and OLAP (on-line analytical processing). Using the idea of column storage to optimize the MapReduce framework faces the challenges of reasonable data structure design and data compression.
- The connection algorithm is optimized by using hardware resources to improve the connection efficiency of each stage. The process of MapReduce framework dealing with connection operation is relatively complex. It is faced with challenges such as data tilt, data transmission in distributed environment and the need for multiple MapReduce jobs. Optimizing the resources in each stage of MapReduce can make full use of the performance of hardware resources to improve the efficiency of MapReduce.
2, IO performance optimization: file types
1. Optimization scheme
- HDFS was originally developed to access large files, so the storage efficiency of a large number of small files is not high. When MapReduce reads and processes small files, there is also a waste of resources, resulting in low calculation efficiency. A scheme of merging and storing small files in HDFS is designed by using SequenceFile and MapFile. The main idea of this scheme is to serialize and store small files A SequenceFIle/MapFile container is merged into large files, and the corresponding index files are established to effectively reduce the number of files and improve access efficiency The experimental results show that the small file storage scheme based on SequenceFile or MapFile can more effectively improve the small file storage performance and reduce the node memory consumption of HDFS file system
- For ordinary text files stored by line, MapReduce has relatively poor performance in processing aggregation, filtering and other functions. To solve the problem of poor data processing performance of line storage, you can choose to use column storage to realize data aggregation processing, reduce IO of data transmission and reading and writing, and improve the performance of overall MapReduce computing processing
2. SequenceFile
1. Introduction
SequenceFile is a binary file format used to store serialized key value pairs in hadoop. SequenceFile file can also be used as the input and output of MapReduce jobs, and hive and spark also support this format.
It has the following advantages:
- Storing data in binary KV form makes it more friendly to interact with the bottom layer and faster performance. Therefore, images or more complex structures can be stored in HDFS as KV pairs.
- Sequencefile supports compression and fragmentation. When you compress a sequencefile, you do not compress the whole file into a single unit, but compress the records or block of records in the file Therefore, sequencefile can support sharding. Even if the compression methods used such as Snappy, Lz4 or Gzip do not support sharding, sequencefile can be used to realize sharding.
- SequenceFile can also be used to store multiple small files. Since Hadoop itself is used to process large files, small files are not suitable, so using a SequenceFile to store many small files can improve processing efficiency and save Namenode memory, because Namenode only needs a SequenceFile metadata, rather than creating a separate metadata for each small file.
- Because the data is stored in the form of SequenceFile, the intermediate output file, i.e. map output, will also be stored in SequenceFile, which can improve the overall IO overhead performance
2. Storage characteristics

- sequenceFile is a flat file designed by Hadoop to store binary [Key,Value] pairs.
- You can regard SequenceFile as a container and package all files into SequenceFile class, which can efficiently store and process small files.
- SequenceFile files are not sorted and stored according to their stored keys. The internal class Writer of SequenceFile provides the append function.
- The Key and Value in the SequenceFile can be any type of Writable or custom Writable.
- In terms of storage structure, SequenceFile is mainly composed of a Header followed by multiple records. The Header mainly contains Key classname, value classname, storage compression algorithm, user-defined metadata and other information. In addition, it also contains some synchronization identifiers to quickly locate the boundary of records. Each Record is stored as a Key value pair. The character array used to represent it can be parsed into: Record length, Key length, Key value and value value at one time. The structure of value value depends on whether the Record is compressed.
- In resources, it is divided into whether to compress the format. When not compressed, key and value are serialized and written to SequenceFile. When the compression format is selected, the compression format of record is actually different from that without compression, except that the bytes of value are compressed and the key is not compressed
- In Block, it compresses all information. The minimum size of compression is determined by the io.seqfile.compress.blocksize configuration item in the configuration file.
3. SequenceFile tool class
- SequenceFileOutputFormat
Used to output the results of MapReduce as a SequenceFile file - SequenceFileInputFormat
Used to read the SequenceFile file
4. Generate SequenceFile
- Requirements: convert ordinary files to SequenceFile files

thinking
- Reading normal files using TextInputFormat
- The Map stage outputs each line of the read file
- In the Reduce phase, each data is output directly
- Save the results as SequenceFile using SequenceFileOutputFormat
code implementation
- Driver class
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.Iterator; /** * @ClassName MrWriteToSequenceFile * @Description TODO Read the text file and convert it to SequenceFile file * @Create By itcast */ public class MrWriteToSequenceFile extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { // Instantiate job Job job = Job.getInstance(this.getConf(), "MrWriteToSequenceFile"); // Set the main program of the job job.setJarByClass(this.getClass()); // Set the input of the job to TextInputFormat (normal text) job.setInputFormatClass(TextInputFormat.class); // Set the input path for the job FileInputFormat.addInputPath(job, new Path(args[0])); // Set the implementation class of the Map side job.setMapperClass(WriteSeqFileAppMapper.class); // Set the Key type input at the Map end job.setMapOutputKeyClass(NullWritable.class); // Set the Value type input at the Map end job.setMapOutputValueClass(Text.class); // Set the output of the job to SequenceFileOutputFormat job.setOutputFormatClass(SequenceFileOutputFormat.class); // Block level compression using SequenceFile SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK); // Set the implementation class on the Reduce side job.setReducerClass(WriteSeqFileAppReducer.class); // Set the Key type output from the Reduce side job.setOutputKeyClass(NullWritable.class); // Set the Value type of the output on the Reduce side job.setOutputValueClass(Text.class); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(this.getConf() ).delete(outputDir, true); // Set the output path of the job FileOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new MrWriteToSequenceFile(), args); System.exit(status); } }- Mapper class
/** * Define Mapper class */ public static class WriteSeqFileAppMapper extends Mapper<LongWritable, Text,NullWritable, Text>{ private NullWritable outputKey; @Override protected void setup(Context context) throws IOException, InterruptedException { this.outputKey = NullWritable.get(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(outputKey, value); } @Override protected void cleanup(Context context) throws IOException, InterruptedException { this.outputKey = null; }}- Reduce class
/** * Define Reduce class */ public static class WriteSeqFileAppReducer extends Reducer<NullWritable,Text,NullWritable,Text>{ private NullWritable outputKey; @Override protected void setup(Context context) throws IOException, InterruptedException { this.outputKey = NullWritable.get(); } @Override protected void reduce(NullWritable key, Iterable<Text> value, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = value.iterator(); while (iterator.hasNext()) { context.write(outputKey, iterator.next()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { this.outputKey = null; } }5. Read SequenceFile
- Requirement: the SequenceFile converted in the previous step is parsed and converted into ordinary text file content
Idea:
- Use SequenceFileInputformat to read SequenceFile
- The Map phase directly outputs each piece of data
- In the Reduce phase, each piece of data is directly output
- Use TextOutputFormat to save the results as a normal text file
code implementation
- Driver class
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.Iterator; /** * @ClassName MrReadFromSequenceFile * @Description TODO Read the SequenceFile file and convert it into a normal text file * @Create By itcast */ public class MrReadFromSequenceFile extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { // Instantiate job Job job = Job.getInstance(this.getConf(), "MrReadFromSequenceFile"); // Set the main program of the job job.setJarByClass(this.getClass()); // Set the input of the job as SequenceFileInputFormat (SequenceFile text) job.setInputFormatClass(SequenceFileInputFormat.class); // Set the input path for the job SequenceFileInputFormat.addInputPath(job, new Path(args[0])); // Set the implementation class of the Map side job.setMapperClass(ReadSeqFileAppMapper.class); // Set the Key type input at the Map end job.setMapOutputKeyClass(NullWritable.class); // Set the Value type input at the Map end job.setMapOutputValueClass(Text.class); // Set the output of the job to TextOutputFormat job.setOutputFormatClass(TextOutputFormat.class); // Set the implementation class on the Reduce side job.setReducerClass(ReadSeqFileAppReducer.class); // Set the Key type output from the Reduce side job.setOutputKeyClass(NullWritable.class); // Set the Value type of the output on the Reduce side job.setOutputValueClass(Text.class); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(this.getConf()).delete(outputDir, true); // Set the output path of the job TextOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new MrReadFromSequenceFile(), args); System.exit(status); } }- Mapper class
/** * Define Mapper class */ public static class ReadSeqFileAppMapper extends Mapper<NullWritable, Text, NullWritable, Text> { private NullWritable outputKey; @Override protected void setup(Context context) throws IOException, InterruptedException { this.outputKey = NullWritable.get(); } @Override protected void map(NullWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(outputKey, value); } @Override protected void cleanup(Context context) throws IOException, InterruptedException { this.outputKey = null; }- Reducer class
/** * Define Reduce class */ public static class ReadSeqFileAppReducer extends Reducer<NullWritable,Text,NullWritable,Text>{ private NullWritable outputKey; @Override protected void setup(Context context) throws IOException, InterruptedException { this.outputKey = NullWritable.get(); } @Override protected void reduce(NullWritable key, Iterable<Text> value, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = value.iterator(); while (iterator.hasNext()) { context.write(outputKey, iterator.next()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { this.outputKey = null; } }
3. MapFile
1. Introduction
It can be understood that MapFile is a SequenceFile after sorting. By observing its structure, we can see that MapFile is composed of two parts: data and index. Data is a file that stores data. Index, as the data index of the file, mainly records the Key value of each Record and the offset position of the Record in the file. When the MapFile is accessed, the index file will be loaded into memory, and the file location of the specified Record can be quickly located through the index mapping relationship. Therefore, compared with the SequenceFile, the retrieval efficiency of MapFile is the highest, and the disadvantage is that it will consume part of memory to store index data.
Data storage structure of MapFile:

2. MapFile tool class
- MapFileOutputFormat: used to output MapReduce results to MapFile
MapReduce does not encapsulate the read input class of MapFile. The following scheme can be selected according to the situation
- Customize the InputFormat and use the getReader method in MapFileOutputFormat to get the read object
- Use SequenceFileInputFormat to parse the data of MapFile
Generate MapFile file
- Requirements: convert normal files to MapFile files
Idea:
- Input reads a normal file
- In the Map stage, the random value is used as the Key to build an orderly
- Output generate MapFile file
- realization
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.MapFileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.Iterator; import java.util.Random; /** * @ClassName MrWriteToMapFile * @Description TODO Read the text file and convert it into a MapFile file * @Create By itcast */ public class MrWriteToMapFile extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { Configuration conf = getConf(); // Instantiate job Job job = Job.getInstance(conf, "MrWriteToMapFile"); // Set the main program of the job job.setJarByClass(this.getClass()); // Set the input of the job to TextInputFormat (normal text) job.setInputFormatClass(TextInputFormat.class); // Set the input path for the job FileInputFormat.addInputPath(job, new Path(args[0])); // Set the implementation class of the Map side job.setMapperClass(WriteMapFileAppMapper.class); // Set the Key type input at the Map end job.setMapOutputKeyClass(IntWritable.class); // Set the Value type input at the Map end job.setMapOutputValueClass(Text.class); // Set the output of the job to MapFileOutputFormat job.setOutputFormatClass(MapFileOutputFormat.class); // Set the implementation class on the Reduce side job.setReducerClass(WriteMapFileAppReducer.class); // Set the Key type output from the Reduce side job.setOutputKeyClass(IntWritable.class); // Set the Value type of the output on the Reduce side job.setOutputValueClass(Text.class); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(conf).delete(outputDir, true); // Set the output path of the job MapFileOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new MrWriteToMapFile(), args); System.exit(status); } /** * Define Mapper class */ public static class WriteMapFileAppMapper extends Mapper<LongWritable, Text, IntWritable, Text>{ //Define the output Key and randomly generate one value at a time private IntWritable outputKey = new IntWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Randomly generate a value Random random = new Random(); this.outputKey.set(random.nextInt(100000)); context.write(outputKey, value); } /** * Define Reduce class */ public static class WriteMapFileAppReducer extends Reducer<IntWritable,Text,IntWritable,Text>{ @Override protected void reduce(IntWritable key, Iterable<Text> value, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = value.iterator(); while (iterator.hasNext()) { context.write(key, iterator.next()); } } } }Read MapFile file
- Requirement: parse MapFile into normal file content
Idea:
- input reads MapFile. Note that Hadoop does not provide MapFileInputFormat, so it uses SequenceFileInputFormat to parse, or you can customize InputFormat
- Direct output of Map and Reduce
- Output saves the results as a normal file
- realization
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.Iterator; /** * @ClassName MrReadFromMapFile * @Description TODO Read the MapFile file and convert it to a normal text file * @Create By itcast */ public class MrReadFromMapFile extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { // Instantiate job Job job = Job.getInstance(this.getConf(), "MrReadFromMapFile"); // Set the main program of the job job.setJarByClass(this.getClass()); // Set the input of the job as SequenceFileInputFormat (Hadoop does not directly provide MapFileInput) job.setInputFormatClass(SequenceFileInputFormat.class); // Set the input path for the job SequenceFileInputFormat.addInputPath(job, new Path(args[0])); // Set the implementation class of the Map side job.setMapperClass(ReadMapFileAppMapper.class); // Set the Key type input at the Map end job.setMapOutputKeyClass(NullWritable.class); // Set the Value type input at the Map end job.setMapOutputValueClass(Text.class); // Set the output of the job to SequenceFileOutputFormat job.setOutputFormatClass(TextOutputFormat.class); // Set the implementation class on the Reduce side job.setReducerClass(ReadMapFileAppReducer.class); // Set the Key type output from the Reduce side job.setOutputKeyClass(NullWritable.class); // Set the Value type of the output on the Reduce side job.setOutputValueClass(Text.class); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(this.getConf()).delete(outputDir, true); // Set the output path of the job TextOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new MrReadFromMapFile(), args); System.exit(status); } /** * Define Mapper class */ public static class ReadMapFileAppMapper extends Mapper<IntWritable, Text, NullWritable, Text> { private NullWritable outputKey = NullWritable.get(); @Override protected void map(IntWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(outputKey, value); } } /** * Define Reduce class */ public static class ReadMapFileAppReducer extends Reducer<NullWritable,Text,NullWritable,Text>{ @Override protected void reduce(NullWritable key, Iterable<Text> value, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = value.iterator(); while (iterator.hasNext()) { context.write(key, iterator.next()); } } } }
4. ORCFile
1. ORC introduction
ORC (optimized RC file) file format is a columnar storage format in the Hadoop ecosystem, derived from RC (RecordColumnar File). It was first generated from Apache Hive in early 2013 to reduce Hadoop data storage space and accelerate Hive query speed. It is not a simple column storage format. It is still divided according to row groups first
The entire table is stored by column in each row group. The orc file is self describing. Its metadata is serialized using Protocol Buffers, and the data in the file is compressed as much as possible to reduce the consumption of storage space. At present, it is also supported by Spark SQL, Presto and other query engines. In 2015, ORC project was promoted to Apache top project by Apache project foundation.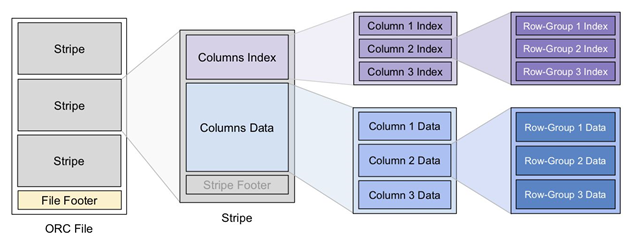
Three levels of statistics are saved in the ORC file: file level, stripe level and row group level. They can be used to judge whether some data can be skipped according to Search ARGuments (predicate push down condition). The statistics include the number of members and whether there are null values, and set some specific statistics for different types of data.
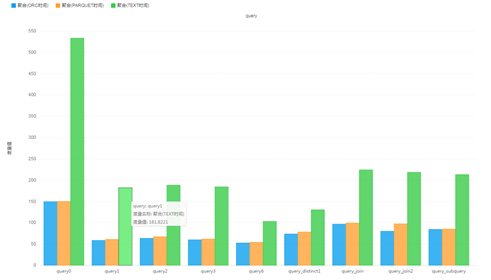
Performance test:
- Original Text format, uncompressed: 38.1 G
- ORC format, default compression (ZLIB): 11.5 G
- Parquet format, default compression (Snappy): 14.8 G
- Test comparison: complex data Join association test
2. ORCFile tool class
1. Add Maven dependency for ORC and MapReduce integration
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-mapreduce</artifactId>
<version>1.6.3</version>
</dependency>
2. Generate ORC file
- Requirements: convert ordinary files to ORC files
Implementation idea:
- The Input stage reads ordinary files
- Map: the stage directly outputs data, and there is no Reduce stage
- The Output phase uses OrcOutputFormat to save as an ORC file type
realization
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.orc.OrcConf; import org.apache.orc.TypeDescription; import org.apache.orc.mapred.OrcStruct; import org.apache.orc.mapreduce.OrcOutputFormat; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; /** * @ClassName WriteOrcFileApp * @Description TODO Used to read ordinary text files and convert them to ORC files */ public class WriteOrcFileApp extends Configured implements Tool { // Job name private static final String JOB_NAME = WriteOrcFileApp.class.getSimpleName(); //Build log listening private static final Logger LOG = LoggerFactory.getLogger(WriteOrcFileApp.class); //Define field information for data private static final String SCHEMA = "struct<id:string,type:string,orderID:string,bankCard:string,cardType:string,ctime:string,utime:string,remark:string>"; /** * Override the run method of the Tool interface to submit the job * @param args * @return * @throws Exception */ public int run(String[] args) throws Exception { // Set Schema OrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA); // Instantiate job Job job = Job.getInstance(this.getConf(), JOB_NAME); // Set the main program of the job job.setJarByClass(WriteOrcFileApp.class); // Sets the Mapper class for the job job.setMapperClass(WriteOrcFileAppMapper.class); // Set the input of the job to TextInputFormat (normal text) job.setInputFormatClass(TextInputFormat.class); // Set the output of the job to OrcOutputFormat job.setOutputFormatClass(OrcOutputFormat.class); // Set the job to use 0 Reduce (output directly from the map side) job.setNumReduceTasks(0); // Set the input path for the job FileInputFormat.addInputPath(job, new Path(args[0])); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(this.getConf()).delete(outputDir, true); // Set the output path of the job OrcOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new WriteOrcFileApp(), args); System.exit(status); } /** * Implement Mapper class */ public static class WriteOrcFileAppMapper extends Mapper<LongWritable, Text, NullWritable, OrcStruct> { //Get field description information private TypeDescription schema = TypeDescription.fromString(SCHEMA); //Build Key for output private final NullWritable outputKey = NullWritable.get(); //The Value of the build output is of type ORCStruct private final OrcStruct outputValue = (OrcStruct) OrcStruct.createValue(schema); public void map(LongWritable key, Text value, Context output) throws IOException, InterruptedException { //Divide each row of data read to obtain all fields String[] fields = value.toString().split(",",8); //Assign all fields to the columns in Value outputValue.setFieldValue(0, new Text(fields[0])); outputValue.setFieldValue(1, new Text(fields[1])); outputValue.setFieldValue(2, new Text(fields[2])); outputValue.setFieldValue(3, new Text(fields[3])); outputValue.setFieldValue(4, new Text(fields[4])); outputValue.setFieldValue(5, new Text(fields[5])); outputValue.setFieldValue(6, new Text(fields[6])); outputValue.setFieldValue(7, new Text(fields[7])); //Output KeyValue output.write(outputKey, outputValue); } } }
Question:
Error: the jar package dependency of ORC MapReduce is missing
Solution: add the jar package of ORC MapReduce to the environment variable of Hadoop, and all NodeManager nodes should be added
cp orc-shims-1.6.3.jar orc-core-1.6.3.jar orc-mapreduce-1.6.3.jar aircompressor-0.15.jar hive-storage-api-2.7.1.jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/

3. Read ORC file
- Requirements: read the ORC file and restore it to a normal text file
Idea:
- The Input stage reads the ORC file generated in the previous step
- The Map phase reads the output directly
- The Output stage saves the results as a normal text file
realization
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.apache.orc.mapred.OrcStruct; import org.apache.orc.mapreduce.OrcInputFormat; import java.io.IOException; /** * @ClassName ReadOrcFileApp * @Description TODO Read the ORC file for parsing and restore it to a normal text file */ public class ReadOrcFileApp extends Configured implements Tool { // Job name private static final String JOB_NAME = WriteOrcFileApp.class.getSimpleName(); /** * Override the run method of the Tool interface to submit the job * @param args * @return * @throws Exception */ public int run(String[] args) throws Exception { // Instantiate job Job job = Job.getInstance(this.getConf(), JOB_NAME); // Set the main program of the job job.setJarByClass(ReadOrcFileApp.class); // Set the input of the job to OrcInputFormat job.setInputFormatClass(OrcInputFormat.class); // Set the input path for the job OrcInputFormat.addInputPath(job, new Path(args[0])); // Sets the Mapper class for the job job.setMapperClass(ReadOrcFileAppMapper.class); // Set the job to use 0 Reduce (output directly from the map side) job.setNumReduceTasks(0); // Set the input of the job as TextOutputFormat job.setOutputFormatClass(TextOutputFormat.class); // Get output path from parameter Path outputDir = new Path(args[1]); // Delete if the output path already exists outputDir.getFileSystem(this.getConf()).delete(outputDir, true); // Set the output path of the job FileOutputFormat.setOutputPath(job, outputDir); // Submit the job and wait for execution to complete return job.waitForCompletion(true) ? 0 : 1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new ReadOrcFileApp(), args); System.exit(status); } /** * Implement Mapper class */ public static class ReadOrcFileAppMapper extends Mapper<NullWritable, OrcStruct, NullWritable, Text> { private NullWritable outputKey; private Text outputValue; @Override protected void setup(Context context) throws IOException, InterruptedException { outputKey = NullWritable.get(); outputValue = new Text(); } public void map(NullWritable key, OrcStruct value, Context output) throws IOException, InterruptedException { //Convert each piece of data in the ORC to a Text object this.outputValue.set( value.getFieldValue(0).toString()+","+ value.getFieldValue(1).toString()+","+ value.getFieldValue(2).toString()+","+ value.getFieldValue(3).toString()+","+ value.getFieldValue(4).toString()+","+ value.getFieldValue(5).toString()+","+ value.getFieldValue(6).toString()+","+ value.getFieldValue(7).toString() ); //Output results output.write(outputKey, outputValue); } } }