Hadoop-HA Cluster Building-rehl7.4
There is no indication that other machine operations need to be logged in. They are all commands executed on cluster HD-2-101.
All installation package addresses: Baidu Disk Extraction code: 24oy
1. Basic Environment Configuration
1.1 Cloning Virtual Machine
For virtual installation and static IP configuration, see: Summary of Linux ports
- Mouse click on virtual machine, right-click management - > clone
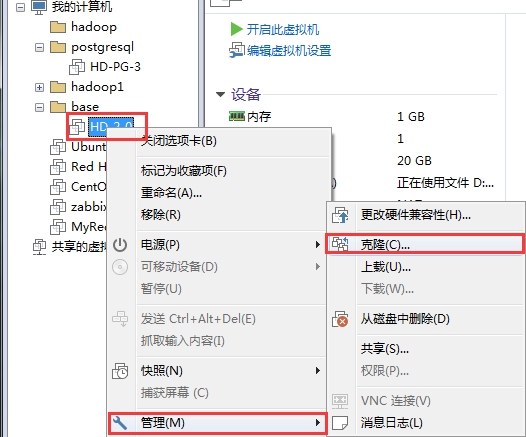
- Click Next to clone from the current status or snapshot - > Select the complete clone.
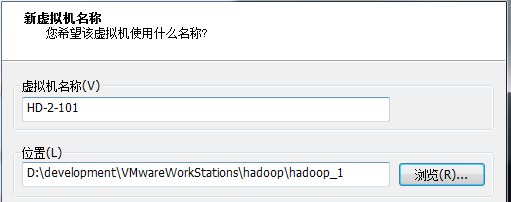
- Modify the name of the virtual machine, select the storage location, and click Finish. Waiting for cloning to complete.
- Clone the required virtual machine according to the above method.
1.2 Modify static IP
- Click to open all virtual machines.
- vmware enters the virtual machine and opens / etc/sysconfig/network-scripts/ifcfg-ens33 to modify the static IP field IPADDR.
- Restart network services: system CTL restart network.
Note: There are three machines (192.168.2.101; 192.168.2.102; 192.168.2.103)
1.3 Local Dependent Installation
# First install the dependencies of the local computer, and then install the other dependencies that do not exist. These are the only ones that my computer needs now. o_0
yum install tcl-devel.x86_64 rsync.x86_64 ntp.x86_64 -y1.4 Configuration Group Reform
shell script content:
- Configure the trust of the current machine to the rest
- shell scripts modify host name mapping
- shell distributes host list mapping files
- Close the firewall
- Turn off SELinux
- Adding other functions later.
Implementation steps:
- Upload autoconfig.tar.gz to 101 machine home directory to decompress, tar -zxvf autoconfig.tar.gz -C /home
- Modify the script host.list file/home/autoconfig/etc/host.list
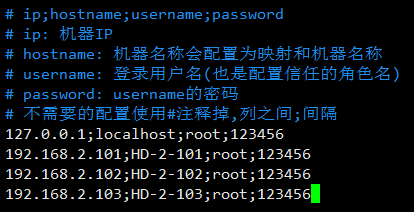
- Modifying scripts with hosts file / home/autoconfig/file/hosts will be distributed to all machine overlays / etc/hosts. Be careful not to make mistakes mapping with host.list host name.
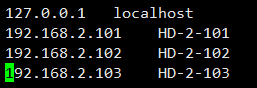
4. Switch to the / home/autoconfig/bin directory to execute:sh autoconfig.sh all
5. Distribution to all machines for execution.
cd /home/autoconfig/bin; sh xsync "/home/autoconfig" "/home"; sh doCommand other "cd /home/autoconfig/bin/; sh autoconfig.sh trust";
- Restart all machines
sh doCommand other "init 0"; init 0;
1.5 Installation Dependence
cd /home/autoconfig/bin; sh doCommand all "yum install tcl-devel.x86_64 rsync.x86_64 ntp.x86_64 -y"
1.6 Install jdk
First, check that all machines have java installed and uninstalled
Check: sh doComm and all "rpm-qa | grep java";
Uninstall: rpm-e -- packages to be uninstalled by nodeps
- All machines create directories / opt/cluster
sh doCommand all "mkdir -p /opt/cluster";
- jdk uploaded to 101 machine / opt/cluster
- Unzip and distribute to other machines.
tar -zxvf /opt/cluster/jdk-8u144-linux-x64.tar.gz; sh xsync "/opt/cluster/jdk1.8.0_144" "/opt/cluster";
- Create a connection
# java The version is jdk1.8.0_144
sh doCommand all "ln -s /opt/cluster/jdk1.8.0_144 /opt/cluster/java";- To add environment variables, all machines / etc / profiles append the following
#JAVA_HOME
export JAVA_HOME=/opt/cluster/java
export PATH=$PATH:$JAVA_HOME/bin1.7 Time Synchronization
Note: Select HD-2-101 as ntpd Timing Server here
- Modify the/etc/ntp.conf file
restrict 192.168.2.0 mask 255.255.255.0 nomodify notrap
restrict 127.0.0.1
# Note that the following can not be used in the Intranet
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# When the node loses network connection, it can still use local time as time server to provide time synchronization for other nodes in the cluster.
server 127.127.1.0
fudge 127.127.1.0 stratum 5- Modify / etc/sysconfig/ntpd file
# Add the following (synchronize hardware time with system time)
SYNC_HWCLOCK="yes"- Add timer tasks, add / etc/cron.d/ntp_crond file, as follows
*/10 * * * * root /usr/sbin/ntpdate HD-2-101- Distribution of Document Timing Documents
sh xsync "/etc/cron.d/ntp_crond" "/etc/cron.d";
- Restart crond service
# restart
sh doCommand all "systemctl restart crond.service"- Check the status of the timed server machine. It takes about 5 minutes to start the timed server.
# reach It's up to the top. NTP The number of times the server requests updates is an octal number, and each change is poll The corresponding number of seconds, etc. reach More than or equal to 17 other servers can be timed for this server.
watch ntpq -p

- Manual First Timing
# Guarantee other machines ntpd Not open
sh doCommand other "systemctl stop ntpd.service;/usr/sbin/ntpdate HD-2-101;"2. Cluster Planning
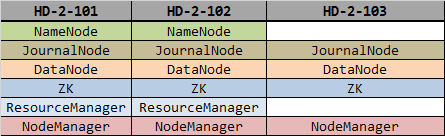
3. Configuring Zookeeper Cluster
Installation package download address: zookeeper-3.4.14.tar.gz
- Unzip the zookeeper installation package to / opt/cluster and unzip it
tar -zxvf /opt/cluster/zookeeper-3.4.14.tar.gz -C /opt/cluster;- All machines create zookeeper data directories.
sh doCommand all "mkdir -p /hdata/zookeeper;";
- Copy zoo_sample.cfg in conf directory as zoo.cfg. And modify the content of dataDir as follows, add the content of server:
dataDir=/hdata/zookeeper
server.1=HD-2-101:2888:3888
server.2=HD-2-102:2888:3888
server.3=HD-2-103:2888:3888
#server.A=B:C:D.
#A is a number, indicating which server this is.
#B is the IP address of the server.
#C is the port where the server exchanges information with the Leader server in the cluster.
#D In case of cluster Leader The server is down and needs a port to re-select#For example, select a new Leader, which is the port used to communicate between servers during the election.
#Configure a file myid in cluster mode. This file is in the dataDir directory. There is a value of A in this file. Zookeeper reads this file when it starts and compares the data with the configuration information in zoo.cfg to determine which server it is.- Copy items to other machines.
sh xsync "/opt/cluster/zookeeper-3.4.14" "/opt/cluster";
- Create myid files in the zookeeper data directory of all machines, and add numbers corresponding to server s in the files.
# as server.1=B:C:D
echo "1" > /hdata/zookeeper/myid;- Create a soft connection.
sh doCommand all "ln -s /opt/cluster/zookeeper-3.4.14 /opt/cluster/zookeeper";- Start the cluster.
sh doCommand all "source /etc/profile; /opt/cluster/zookeeper/bin/zkServer.sh start";
- Check status
sh doCommand all "source /etc/profile; /opt/cluster/zookeeper/bin/zkServer.sh status";
4. HDFS-HA and YARN-HA cluster configuration
4.1 Modify the env.sh configuration
- Switch to / opt/cluster/hadoop/etc/hadoop path
- hadoop-env.sh modifies export JAVA_HOME=/opt/cluster/java
- yarn-env.sh adds export JAVA_HOME=/opt/cluster/java
- Add export JAVA_HOME=/opt/cluster/java to mapred-env.sh
4.2 Modify site.xml configuration
-
Upload the hadoop_template.tar.gz template compression package to the / home directory and extract it: tar-zxvf/home/hadoop_template.tar.gz-C/home
-
Fill in env.sh according to machine configuration export derives the value of the variable.
-
Sh/home/hadoop_template/ha/env.sh runs the script and automatically completes the configuration.
-
Ha template path / home/hadoop_template/ha, all template files are configured as follows:
4.2.1 core-site.xml.template
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Put two. NameNode Addresses are assembled into a cluster mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://${HADOOP_CLUSTER_NAME}</value>
</property>
<!-- Appoint hadoop Storage directory of files generated at runtime -->
<property>
<name>hadoop.tmp.dir</name>
<value>${HADOOP_TMP_DIR}</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>${HADOOP_ZOOKEEPERS}</value>
</property>
<!-- Prevention of use start-dfs.sh journalnode Unactivated NameNode Not connected journalnode Unable to start -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establisha server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.
</description>
</property>
</configuration>4.2.2 hdfs-site.xml.template
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Fully distributed cluster name -->
<property>
<name>dfs.nameservices</name>
<value>${HADOOP_CLUSTER_NAME}</value>
</property>
<!-- Cluster NameNode What are the nodes? -->
<property>
<name>dfs.ha.namenodes.${HADOOP_CLUSTER_NAME}</name>
<value>${HADOOP_NAME_NODES}</value>
</property>
<!-- nn1 Of RPC Mailing address -->
<property>
<name>dfs.namenode.rpc-address.${HADOOP_CLUSTER_NAME}.nn1</name>
<value>${HADOOP_NN1}:9000</value>
</property>
<!-- nn2 Of RPC Mailing address -->
<property>
<name>dfs.namenode.rpc-address.${HADOOP_CLUSTER_NAME}.nn2</name>
<value>${HADOOP_NN2}:9000</value>
</property>
<!-- nn1 Of http Mailing address -->
<property>
<name>dfs.namenode.http-address.${HADOOP_CLUSTER_NAME}.nn1</name>
<value>${HADOOP_NN1}:50070</value>
</property>
<!-- nn2 Of http Mailing address -->
<property>
<name>dfs.namenode.http-address.${HADOOP_CLUSTER_NAME}.nn2</name>
<value>${HADOOP_NN2}:50070</value>
</property>
<!-- Appoint NameNode Metadata in JournalNode Storage location on -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>${HADOOP_JN}</value>
</property>
<!-- Configuration isolation mechanism, that is, only one server can respond to the outside world at the same time -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- Requirements when using isolation mechanisms ssh Secret-key login-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>${HADOOP_ISA_PATH}</value>
</property>
<!-- statement journalnode Server Storage Directory-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${HADOOP_JN_DATA_DIR}</value>
</property>
<!-- Close permission checking-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- Access Agent Class: client,mycluster,active Configuration Failure Automatic Switching Implementation-->
<property>
<name>dfs.client.failover.proxy.provider.${HADOOP_CLUSTER_NAME}</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4.2.3 yarn-site.xml.template
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Enable resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--Statement of two sets resourcemanager Address-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>${HADOOP_YARN_ID}</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>${HADOOP_YARN_RMS}</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>${HADOOP_YARN_RM1}</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>${HADOOP_YARN_RM2}</value>
</property>
<!--Appoint zookeeper Address of Cluster-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>${HADOOP_ZOOKEEPERS}</value>
</property>
<!--Enable automatic recovery-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--Appoint resourcemanager The state information is stored in zookeeper colony-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
4.2.4 mapred-site.xml.template
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>4.2.5 env.sh script
#!/bin/bash
# hadoop Installation directory
export HADOOP_HOME="/opt/cluster/hadoop-2.7.2"
#
# hadoop Cluster name
export HADOOP_CLUSTER_NAME="myhadoop"
# hadoop Storage directory of files generated at runtime
export HADOOP_TMP_DIR="/hdata/hadoop"
#
# All in the cluster NameNode node
export HADOOP_NAME_NODES="nn1,nn2"
# According to the list above NameNode Configure all NameNode Node address, variable name such as HADOOP_NN1,HADOOP_NN2 Increase in turn
export HADOOP_NN1="HD-2-101"
export HADOOP_NN2="HD-2-102"
# NameNode Metadata in JournalNode Storage location on
export HADOOP_JN="qjournal://HD-2-101:8485;HD-2-102:8485;HD-2-103:8485/myhadoop"
# id_rsa Public key address
export HADOOP_ISA_PATH="~/.ssh/id_rsa"
# journalnode Server Storage Directory
export HADOOP_JN_DATA_DIR="/hdata/hadoop/journal"
# zookeeper Machine List
export HADOOP_ZOOKEEPERS="HD-2-101:2181,HD-2-102:2181,HD-2-103:2181"
# yarn colony id
export HADOOP_YARN_ID="yarn-ha"
# All in the cluster resourcemanager
export HADOOP_YARN_RMS="rm1,rm2"
# According to the list above resourcemanager Configure all resourcemanager Node address, variable name such as HADOOP_YARN_RM1,HADOOP_YARN_RM2 Increase in turn
export HADOOP_YARN_RM1="HD-2-101"
export HADOOP_YARN_RM2="HD-2-102"
baseDir=$(cd `dirname $0`; pwd)
for template in `cd ${baseDir}; ls *template`
do
siteFile=`echo ${template} | gawk -F"." '{print $1"."$2}'`
envsubst < ${template} > ${HADOOP_HOME}/etc/hadoop/${siteFile}
echo -e "#### set ${siteFile} succeed"
done
5. Cluster Startup
5.1 hdfs start-up
- Synchronized configuration to other machines
# synchronization
sh xsync "/opt/cluster/hadoop-2.7.2" "/opt/cluster";
# Establishing Soft Connection
sh doCommand all "ln -s /opt/cluster/hadoop-2.7.2 /opt/cluster/hadoop;";- Start the ZK cluster and initialize the state in the ZK
# start-up zk colony
sh doCommand all "source /etc/profile; /opt/cluster/zookeeper/bin/zkServer.sh start";
# Initialized in ZK State in
sh /opt/cluster/hadoop/bin/hdfs zkfc -formatZK- Start journalnode
sh doCommand all "sh /opt/cluster/hadoop/sbin/hadoop-daemon.sh start journalnode";
- Log on to NameNode1 machine to format and start
# Format
sh /opt/cluster/hadoop/bin/hdfs namenode -format;
# start-up
sh /opt/cluster/hadoop/sbin/hadoop-daemon.sh start namenode;- Log on to NameNode2 machine to synchronize nn1 metadata and start
# Synchronized metadata
sh /opt/cluster/hadoop/bin/hdfs namenode -bootstrapStandby;
# start-up NameNode2
sh /opt/cluster/hadoop/sbin/hadoop-daemon.sh start namenode;- Web Interface Displays NameNode Information
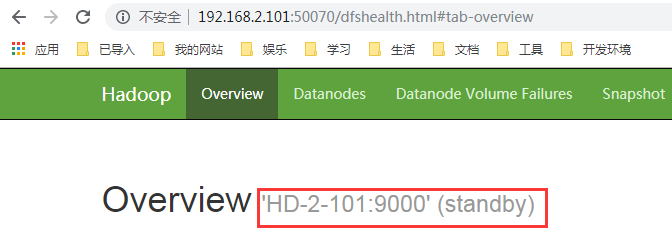
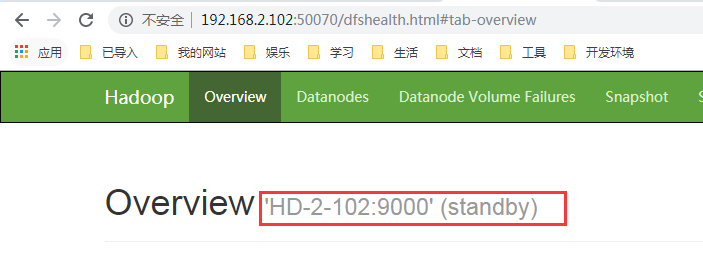
- Restart all dfs services except zk
sh /opt/cluster/hadoop/sbin/stop-dfs.sh sh /opt/cluster/hadoop/sbin/start-dfs.sh
- Check the NameNode status of all machines
# Check status
sh /opt/cluster/hadoop/bin/hdfs haadmin -getServiceState nn1;
sh /opt/cluster/hadoop/bin/hdfs haadmin -getServiceState nn2;5.2 yarn startup
- HD-2-101 Starts yarn
sh /opt/cluster/hadoop/sbin/start-yarn.sh;
- HD-2-103 Starts ResourceManager
sh /opt/cluster/hadoop/sbin/yarn-daemon.sh start resourcemanager;
- View ResourceManager Service Status
sh /opt/cluster/hadoop/bin/yarn rmadmin -getServiceState rm1; sh /opt/cluster/hadoop/bin/yarn rmadmin -getServiceState rm2;
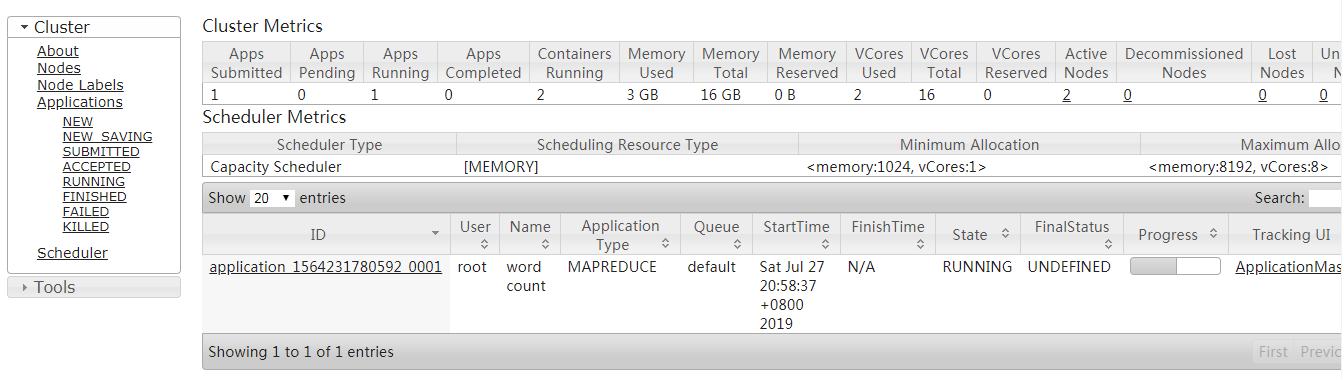
- Cluster state
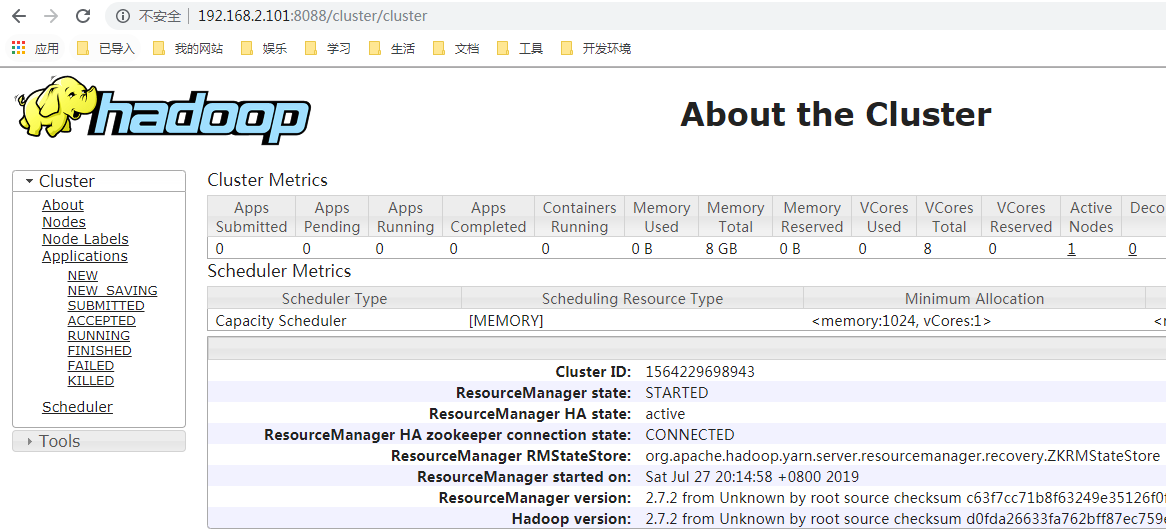
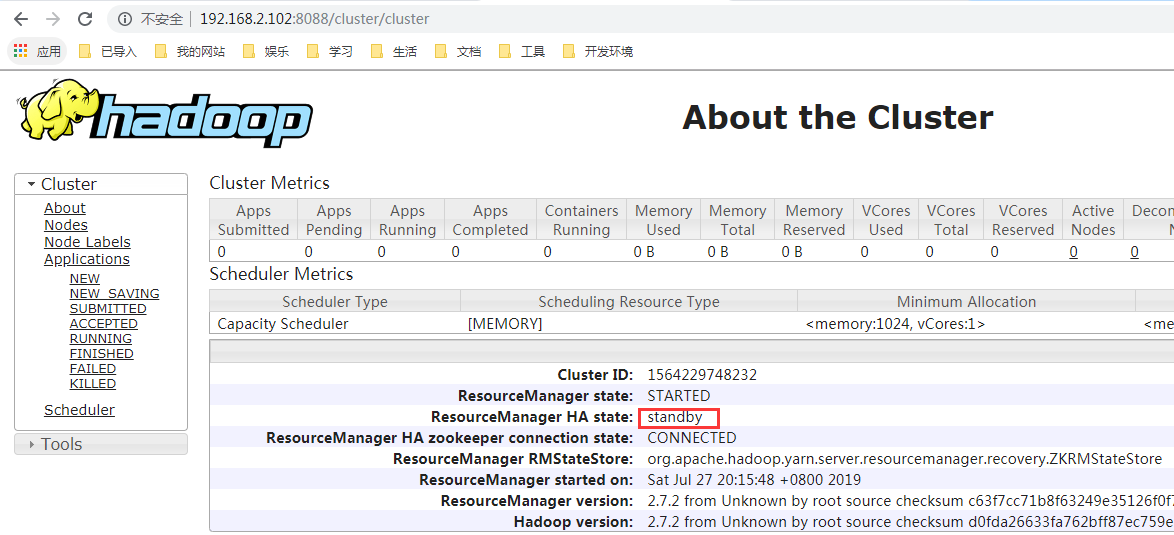
6. Environmental validation
- Create the file word.txt, which reads as follows:
export HADOOP_CLUSTER_NAME myhadoop export HADOOP_TMP_DIR hdata hadoop hdata export HADOOP_TMP_DIR myhadoop export
- Create a file to the specified path
# Create paths
/opt/cluster/hadoop/bin/hadoop fs -mkdir -p /mapreduce/test/input/20180702;
# upload
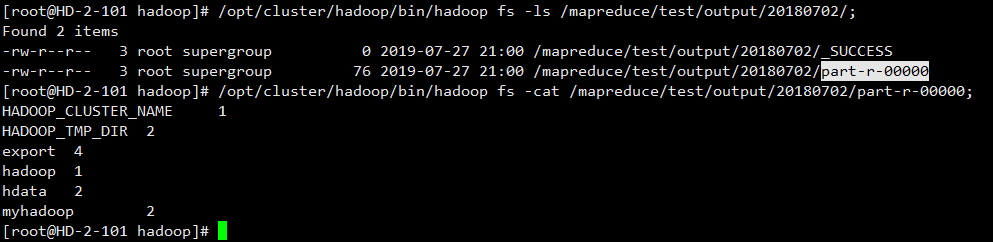
/opt/cluster/hadoop/bin/hadoop fs -put ./word.txt /mapreduce/test/input/20180702;- Test run wordcount
cd /opt/cluster/hadoop; bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /mapreduce/test/input/20180702 /mapreduce/test/output/20180702;