HADOOP installation Linux stand-alone
Download Hadoop
Hadoop3.xx download address: http://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
Upload to Linux via FTP
Decompression software
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
Configure HADOOP environment variables
Create custom profile
vim /etc/profile.d/my_env.sh
Configure HADOOP_HOME environment variable
# HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
Make configuration effective
source /etc/profile
HADOOP local operation
Create test file
mkdir wcinput cd wcinput vim word.txt # Enter the following test contents hadoop yarn hadoop mapreduce czs czs # Save exit: wq
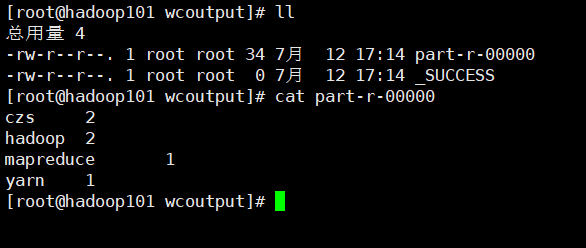
Execute test file
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput
View results
HADOOP installing Linux Cluster Edition
Write cluster distribution script
scp secure copy
- scp can copy data between servers.
- Basic syntax: scp -r $pdir/$fname $user@$host:$pdir/$fname
- Example: SCP - R / opt / module / jdk1 8.0_ two hundred and twelve root@hadoop103 :/opt/module
rscp
- rsync is mainly used for backup and mirroring. It has the advantages of high speed, avoiding copying the same content and supporting symbolic links
- Using rsync to copy files is faster than scp. rsync only updates difference files. scp is to copy all the files
- Basic syntax rsync -av $pdir/$fname $user@$host:$pdir/$fname -a: archive copy - v: Show copy process
- Example: rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/
xscp
Synchronize files by script
It is expected that the script can be used in any path (the script is placed in the path where the global environment variable is declared)

Create an xsync file in the / home/root/bin directory. The script code is as follows vim xsync
#!/bin/bash #1. Number of judgment parameters if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. Traverse all machines in the cluster for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. Traverse all directories and send them one by one for file in $@ do #4. Judge whether the document exists if [ -e $file ] then #5. Get parent directory pdir=$(cd -P $(dirname $file); pwd) #6. Get the name of the current file fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
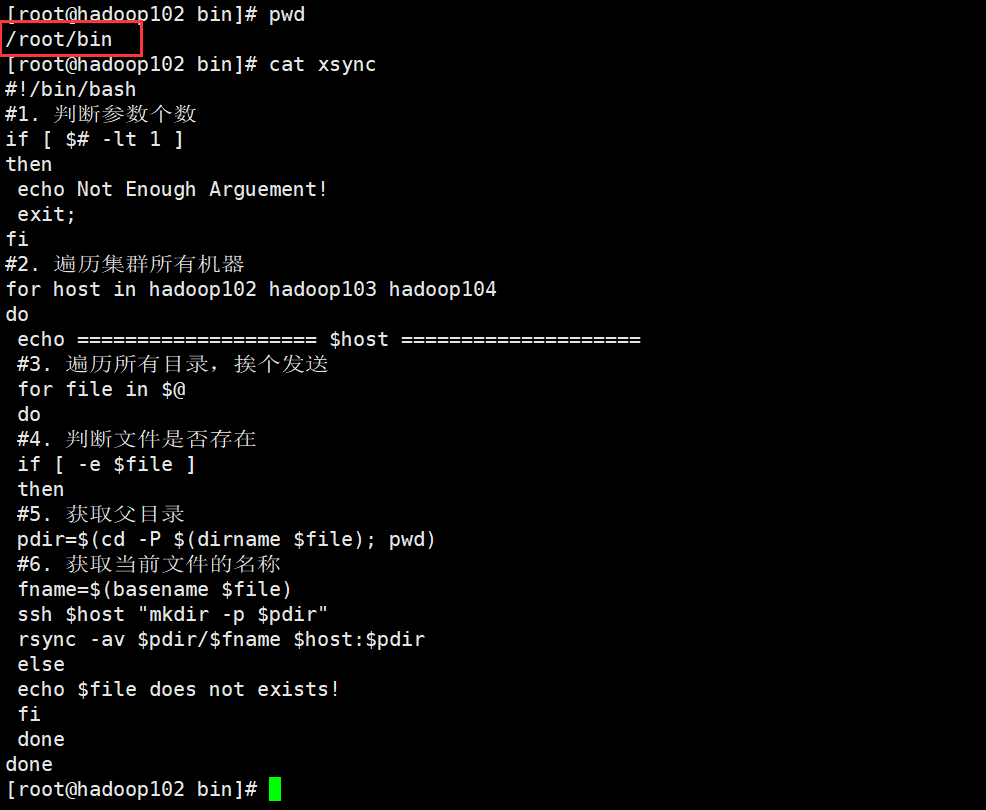
Modify the executable permissions of the script chmod 777 xsync

Configure ssh password free login in the cluster
Normal ssh connection login
Basic syntax: ssh the IP address of another computer
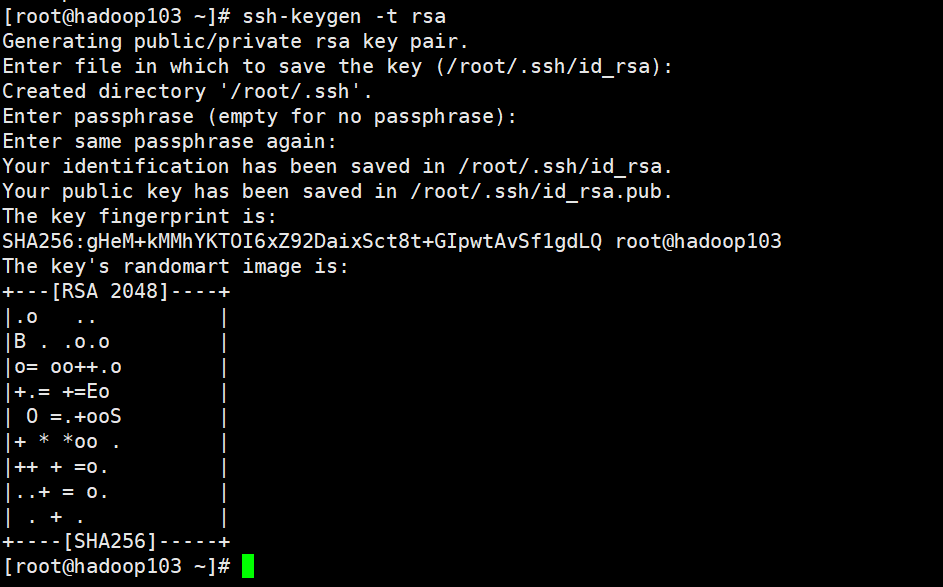
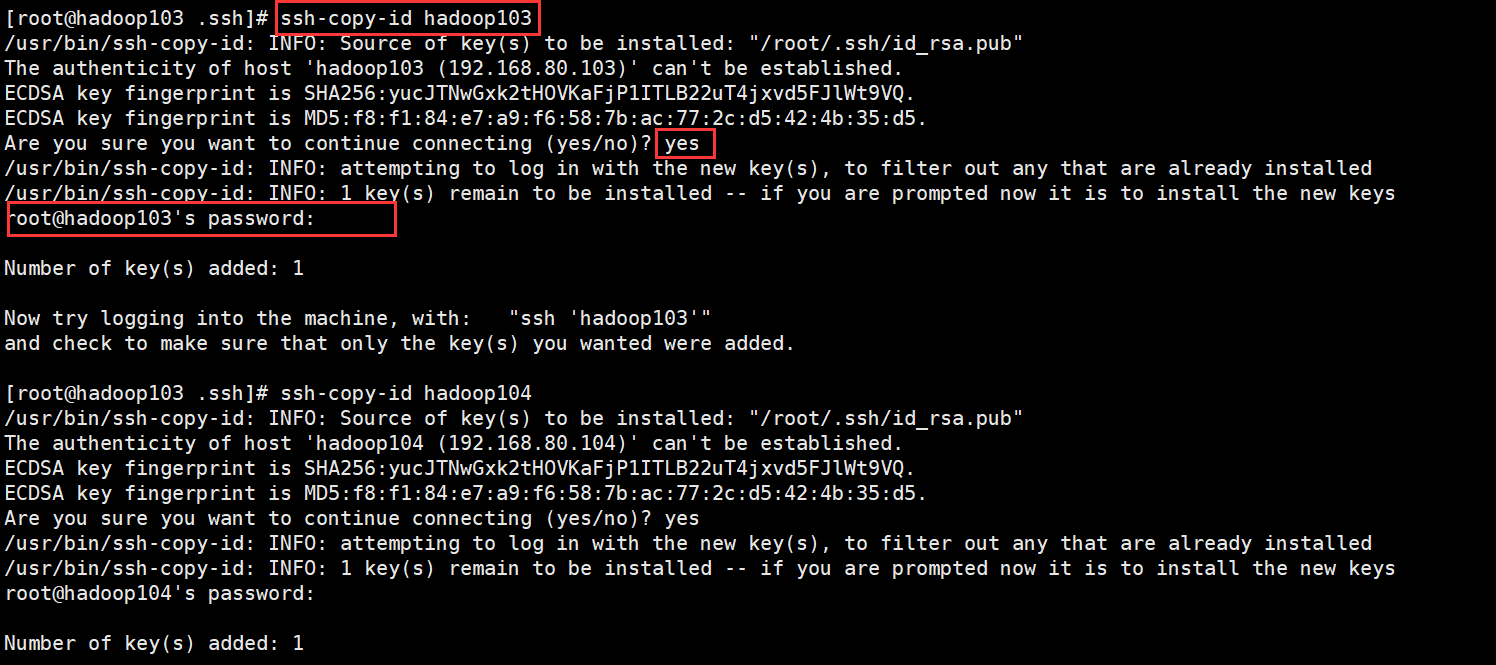
Generate public and private keys
Command: SSH keygen - t RSA, then hit (three carriage returns), and two file IDS will be generated_ RSA (private key), id_rsa.pub (public key)

Copy the public key to the target machine for password free login
Command: SSH copy ID target machine IP
Hadoop cluster configuration
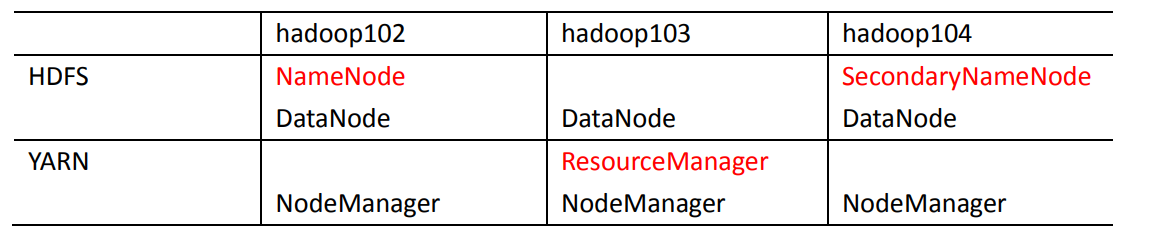
Cluster deployment planning
- NameNode and SecondaryNameNode should not be installed on the same server
- Resource manager also consumes a lot of memory and should not be configured on the same machine as NameNode and SecondaryNameNode.
Profile description
Hadoop configuration files are divided into two types: default configuration files and user-defined configuration files. Only when users want to modify a default configuration value, they need to modify the user-defined configuration file and change the corresponding attribute value.
Default profile:

Custom profile:
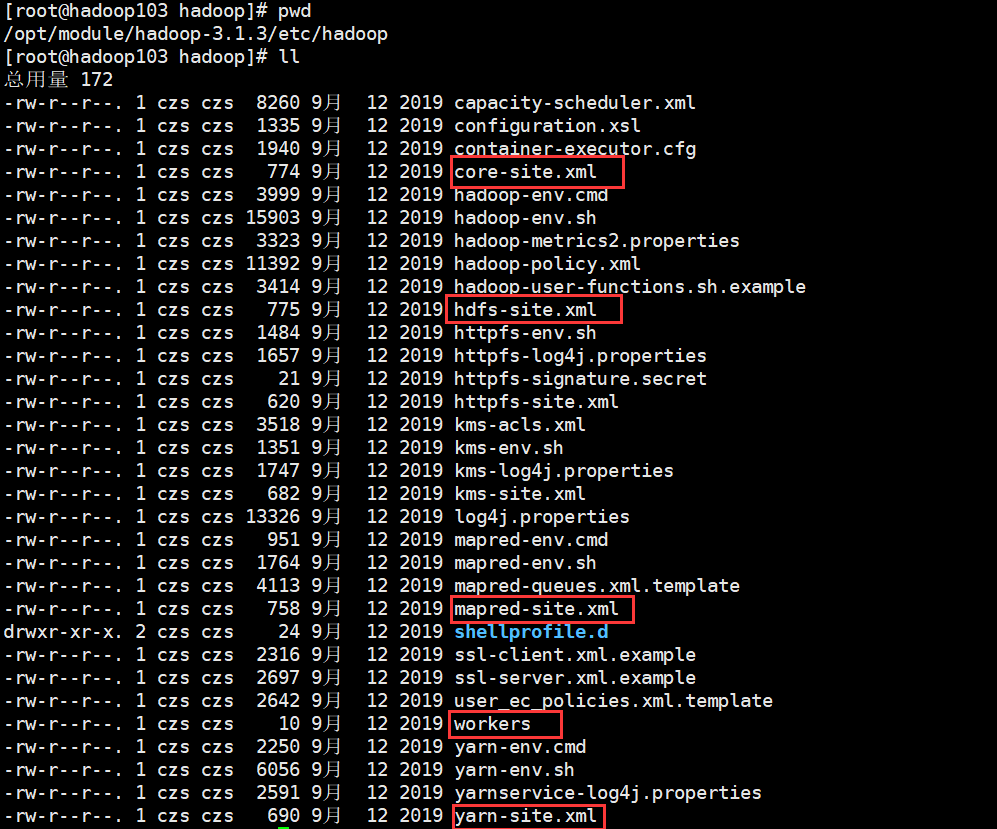
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- Four configuration files are stored in $Hadoop_ On the path of home / etc / Hadoop, users can modify the configuration again according to the project requirements.
Hadoop cluster configuration core
Core configuration file: core site xml
# Modify custom profile vim core-site.xml
<!-- The contents of the document are as follows -->
<configuration>
<!-- appoint NameNode Address of -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- appoint hadoop Storage directory of data -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- to configure HDFS The static user used for web page login is atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
HDFS configuration file: HDFS site xml
# Modify custom profile vim hdfs-site.xml
<!-- The contents of the document are as follows -->
<configuration>
<!-- nn web End access address-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web End access address-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
YARN configuration file: YARN site xml
# Modify custom profile vim yarn-site.xml
<!-- The contents of the document are as follows -->
<configuration>
<!-- appoint MR go shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- appoint ResourceManager Address of-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- Inheritance of environment variables -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
MapReduce configuration file: mapred site xml
# Modify custom profile vim mapred-site.xml
<configuration> <!-- appoint MapReduce The program runs on Yarn upper --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
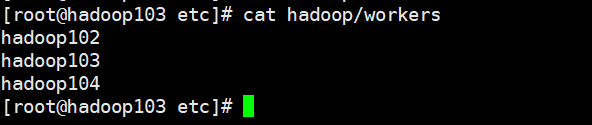
Configure workers
- No space is allowed at the end of the content added in the file, and no empty line is allowed in the file.
The cluster synchronizes all node profiles
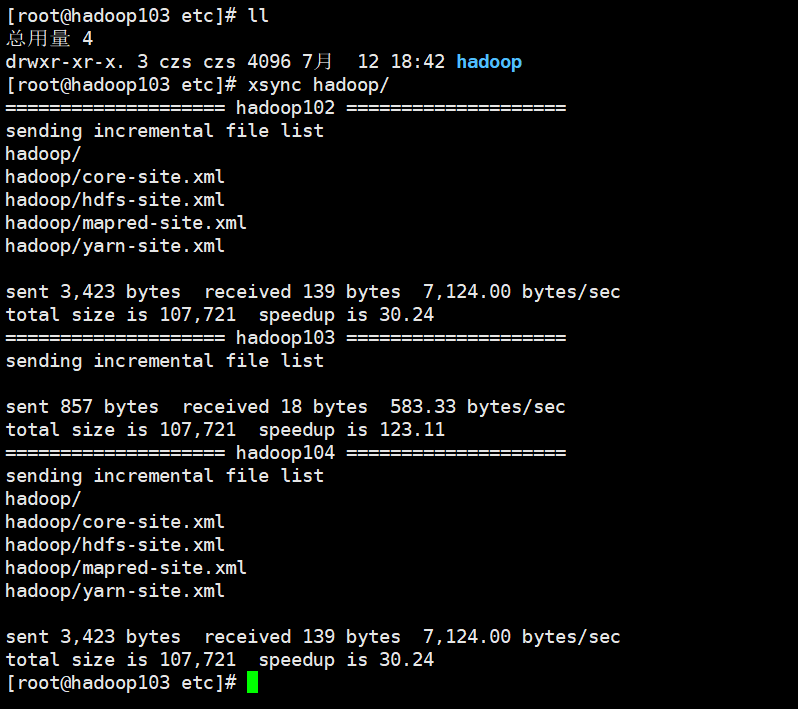
Start Hadoop cluster
Initial formatting
-
If the cluster is started for the first time, you need to format the NameNode on Hadoop 102 node and generate data and logs directories, indicating that the format is successful
-
Formatting namenode will generate a new cluster id, resulting in inconsistent cluster IDS between namenode and datanode, and the cluster cannot find past data. If the cluster reports an error during operation and needs to reformat the namenode, be sure to stop the namenode and datanode processes first, and delete the data and logs directories of all machines before formatting
Format command: hdfs namenode -format
Start HDFS
Command: SBIN / start DFS sh
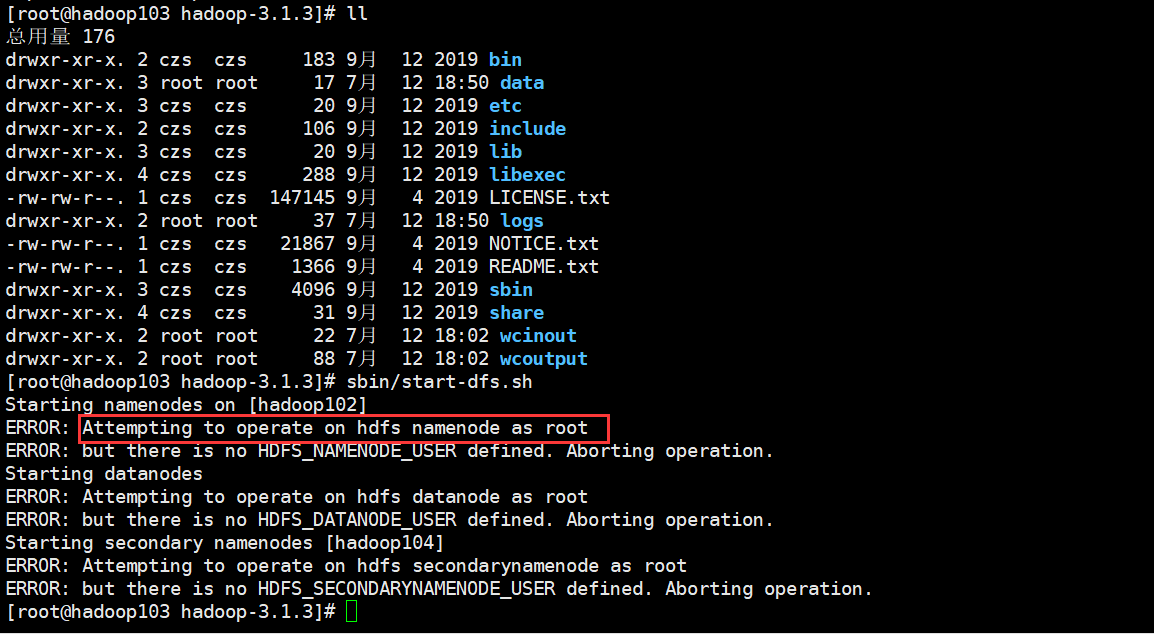
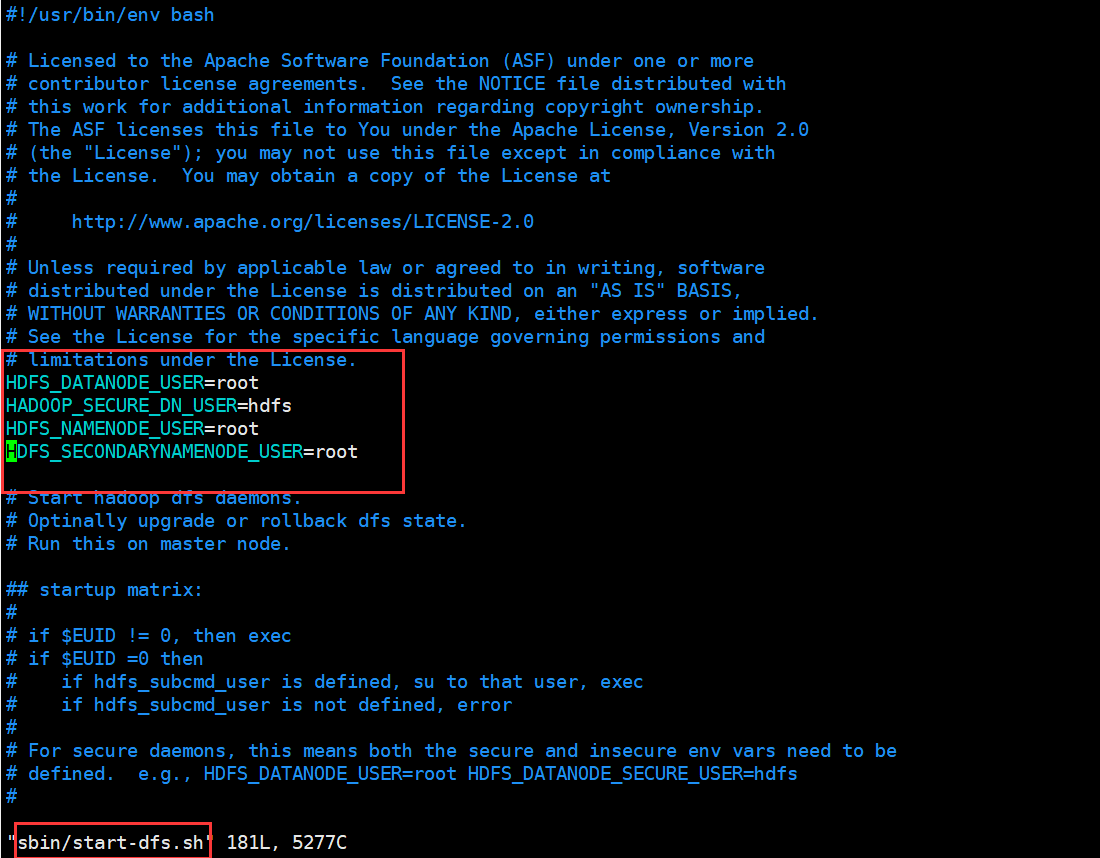
If the following error is caused by the lack of user definition, edit the start and close scripts respectively, add content in the blank space at the top, and restart
$ vim sbin/start-dfs.sh $ vim sbin/stop-dfs.sh HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
Similarly, if yarn SH starts with an error, and the following configuration is also added:
$ vim sbin/start-yarn.sh $ vim sbin/stop-yarn.sh YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
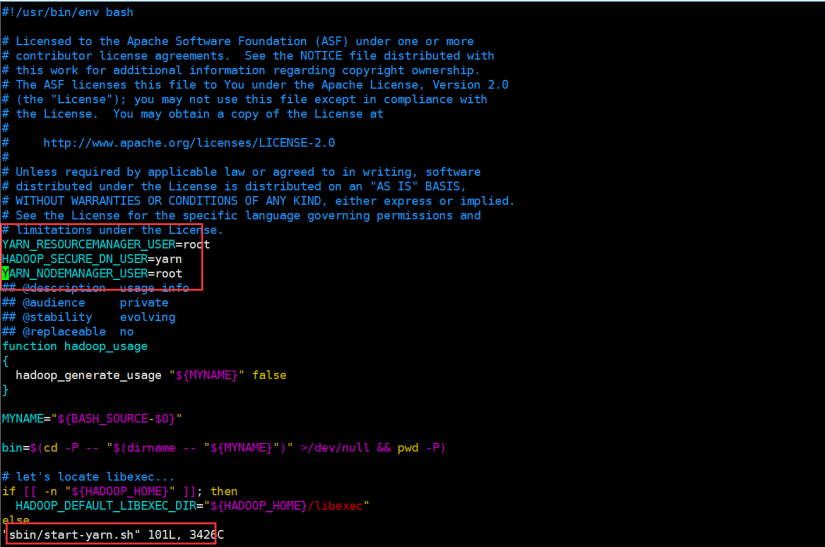
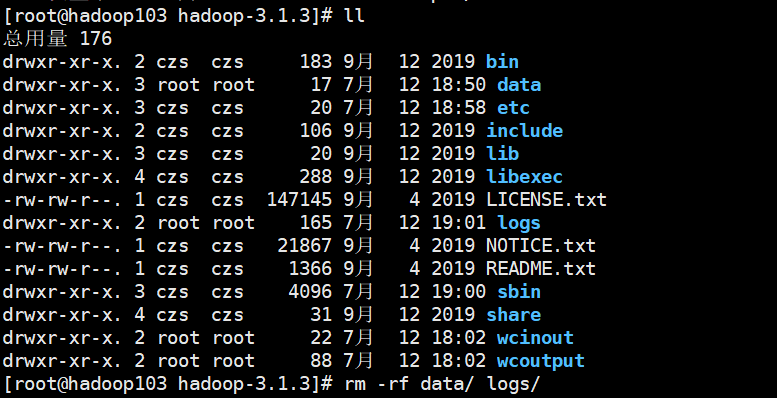
After modifying the configuration, delete the data and logs directories and reformat NameNodehdfs namenode -format
On the node with NameNode configured, start HDFS: SBIN / start DFS sh
On the node where ResourceManager is configured, start YARN: SBIN / start YARN sh
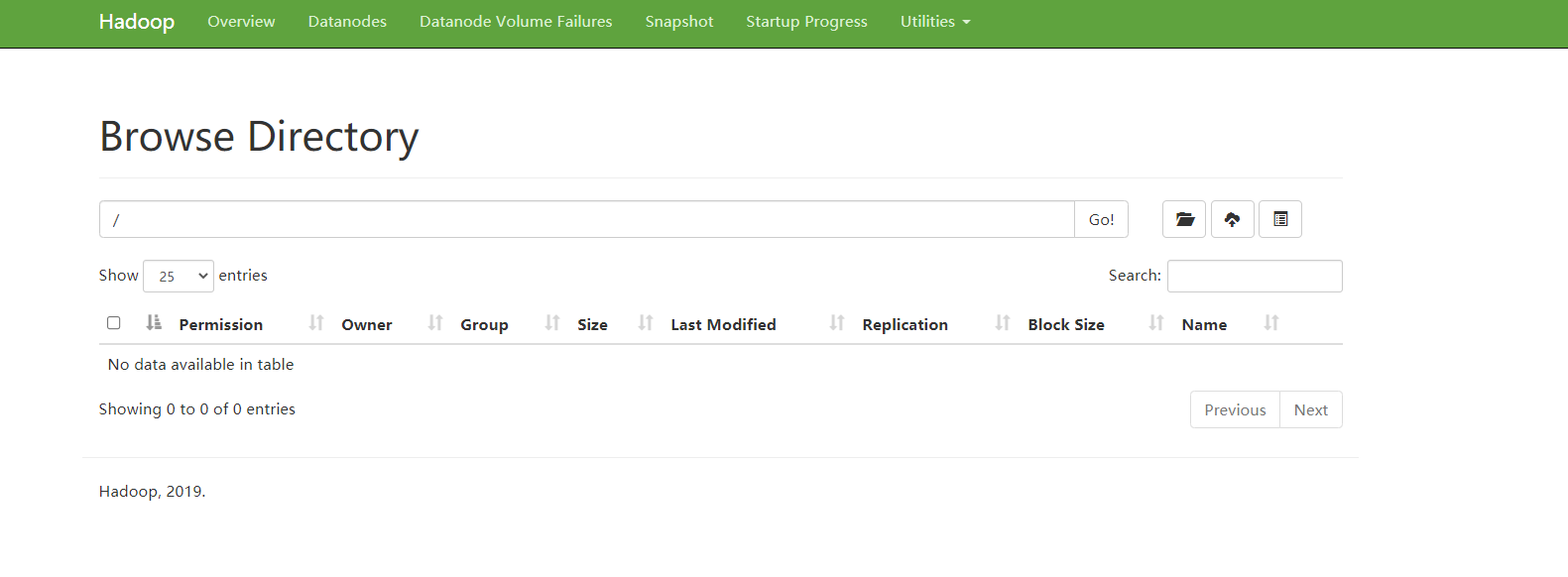
View the NameNode of HDFS on the Web side and access it by browser http://hadoop102:9870/
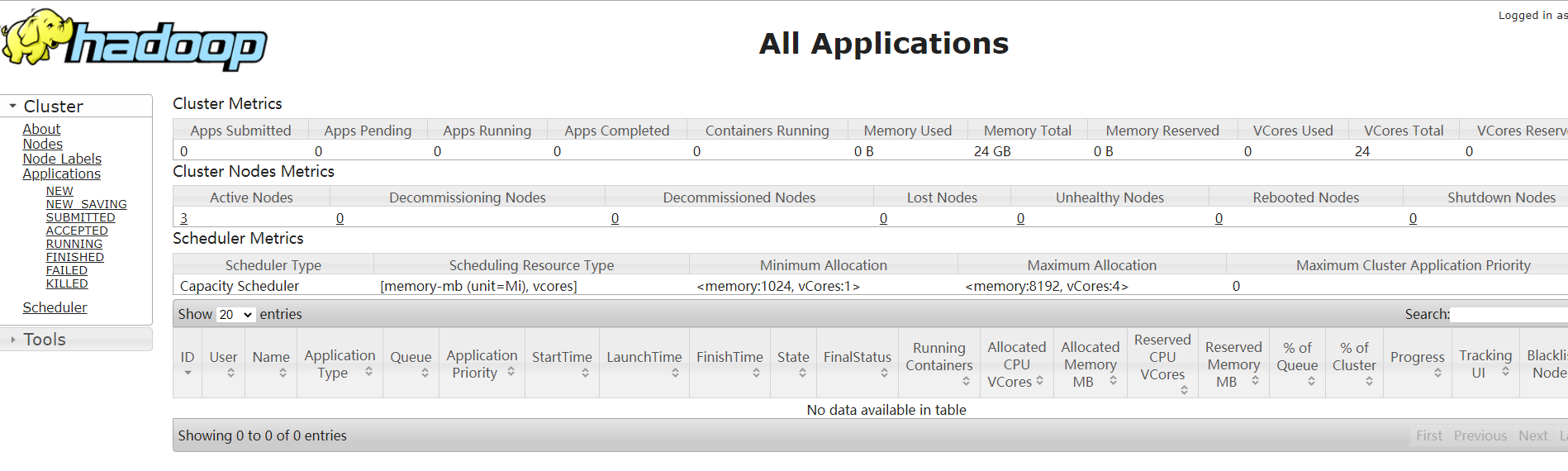
View YARN's resource manager on the WEB side and visit it by browser http://hadoop103:8088/
Cluster basic function test
Upload files to cluster
Command: hadoop fs -put file address cluster directory address
hadoop fs -put wcinout/word.txt /input
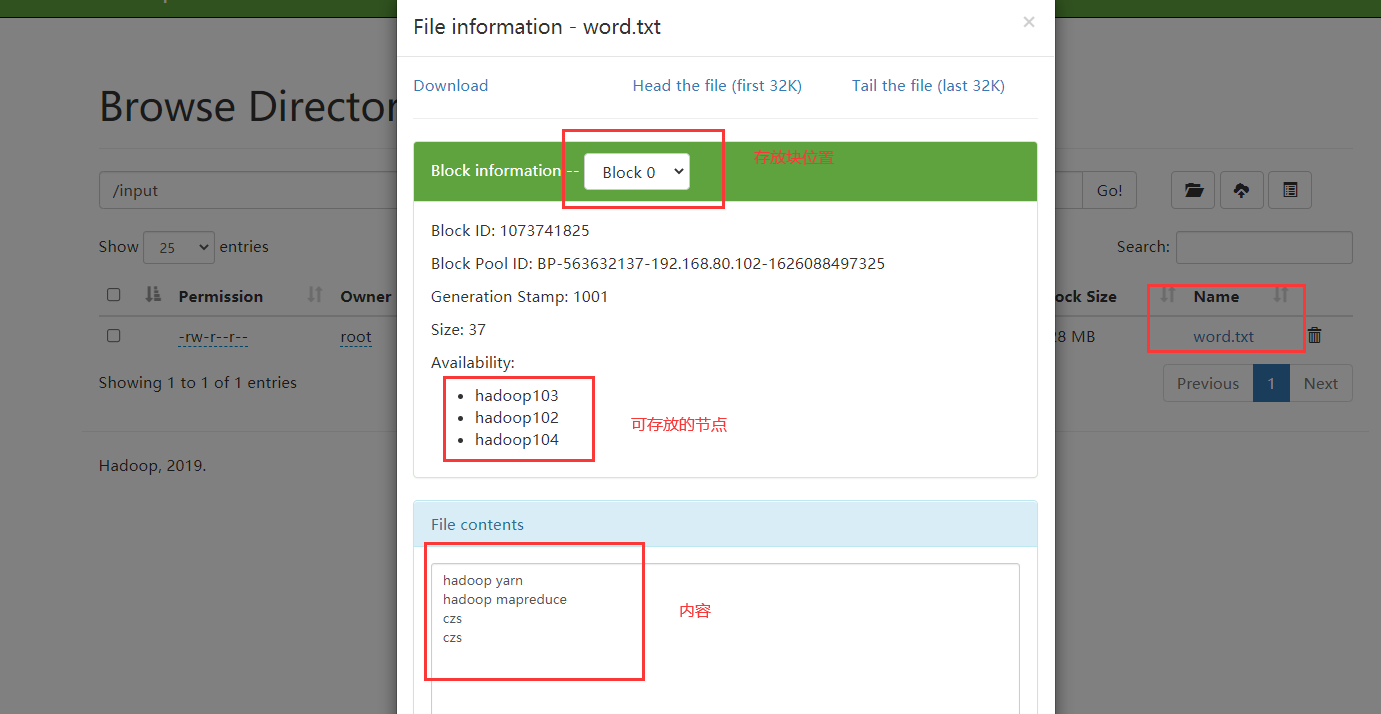
Execute the wordcount program
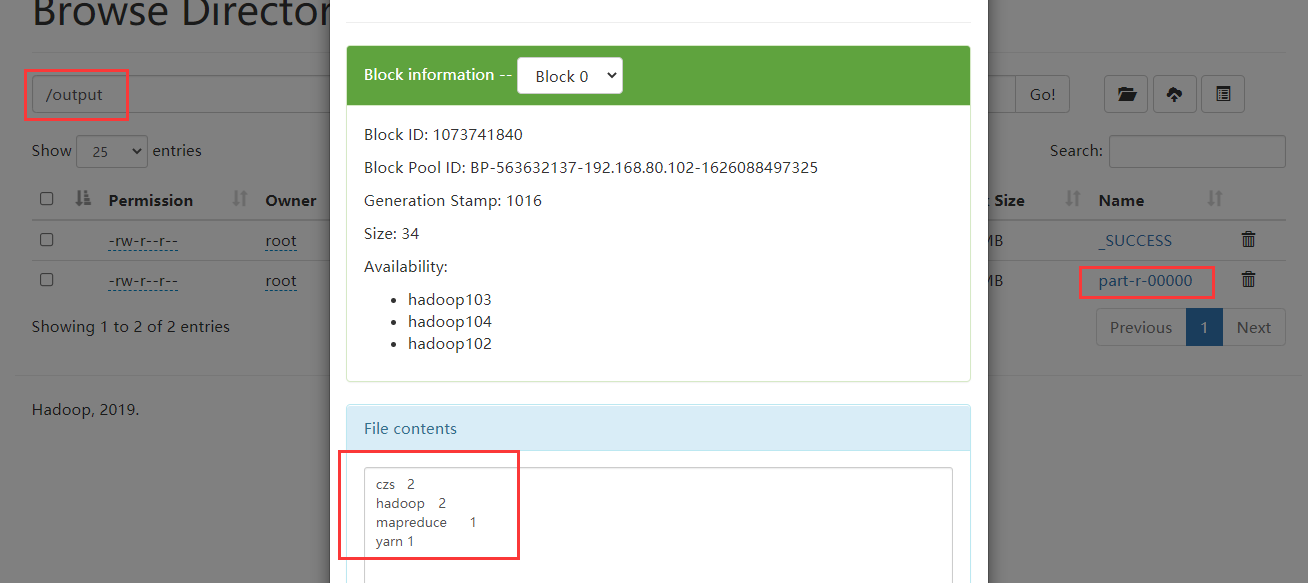
Command: Hadoop jar share / Hadoop / MapReduce / hadoop-mapreduce-examples-3.1.3 Jar wordcount source directory destination directory
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
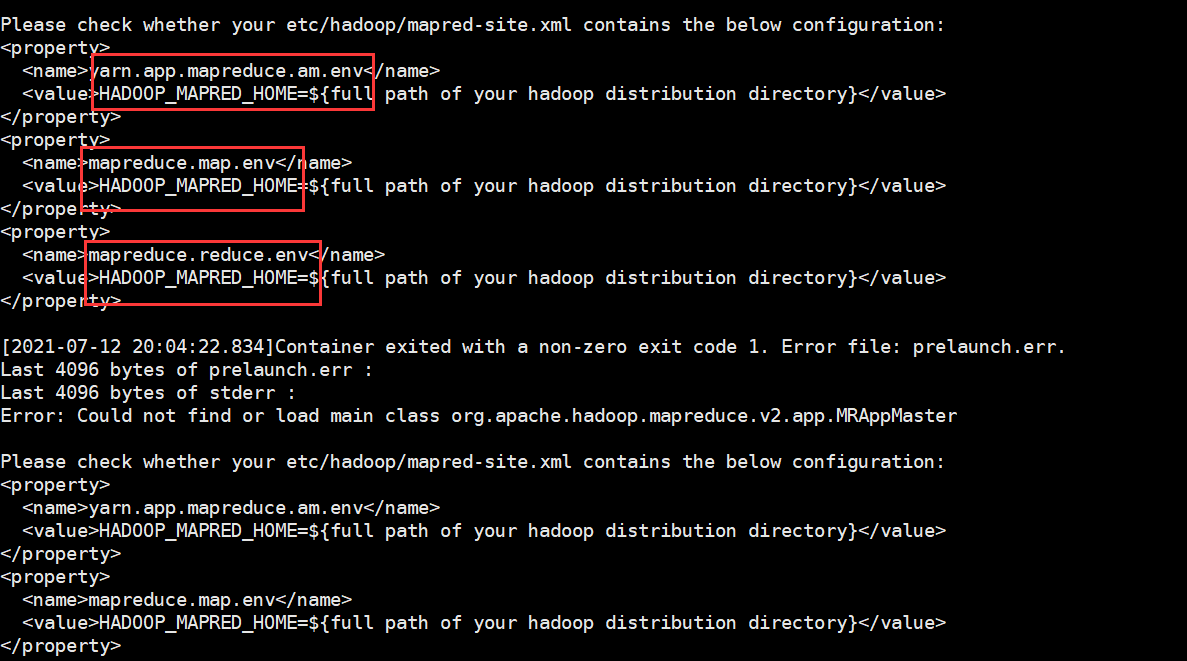
If the following errors are reported, configure the following to mapred site XML, Hadoop home directory, restart the cluster
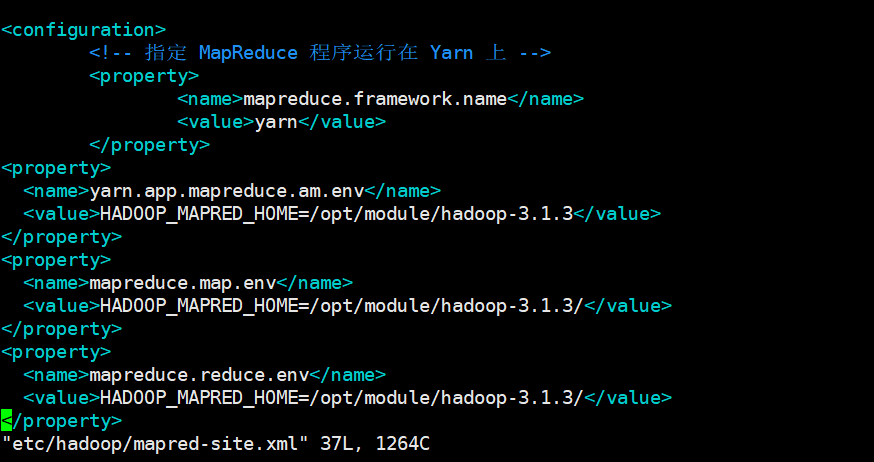
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3/</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3/</value> </property>
Configure history server
In order to view the historical operation of the program, you need to configure the history server.
Configure mapred site xml
# Modify custom profile vim mapred-site.xml
<!-- Add the following file contents -->
<configuration>
<!-- Historical server address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- History server web End address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
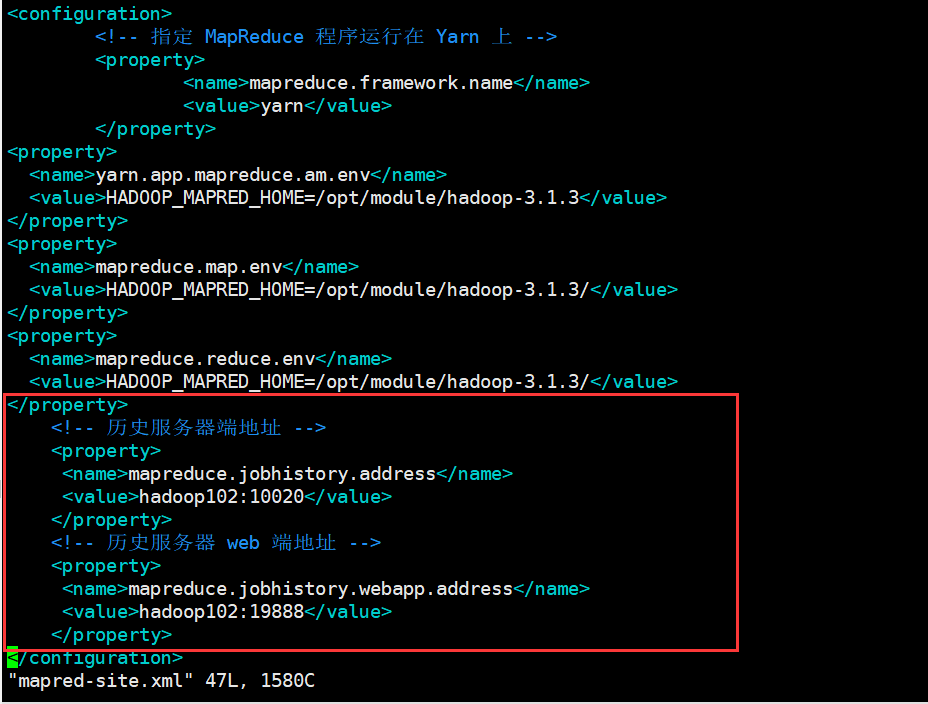
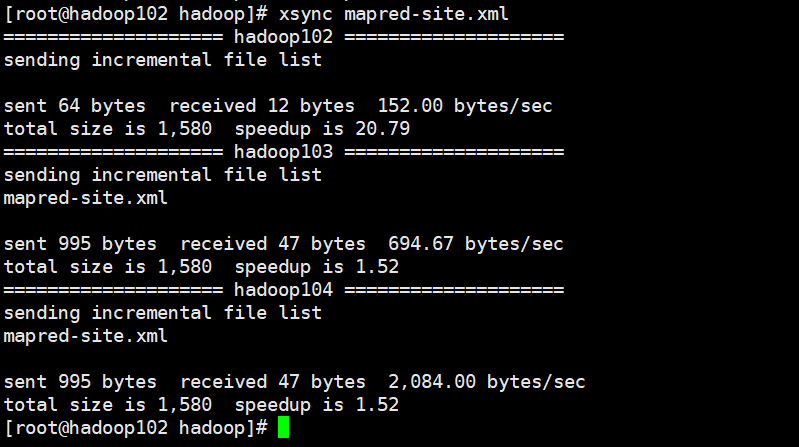
Cluster distribution configuration
xsync mapred-site.xml
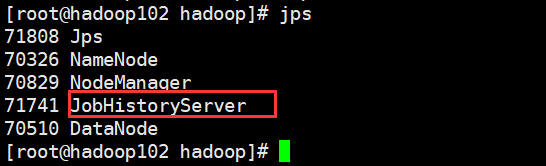
Start the history server on the NameNode server
mapred --daemon start historyserver
Check whether the history server is started
jps
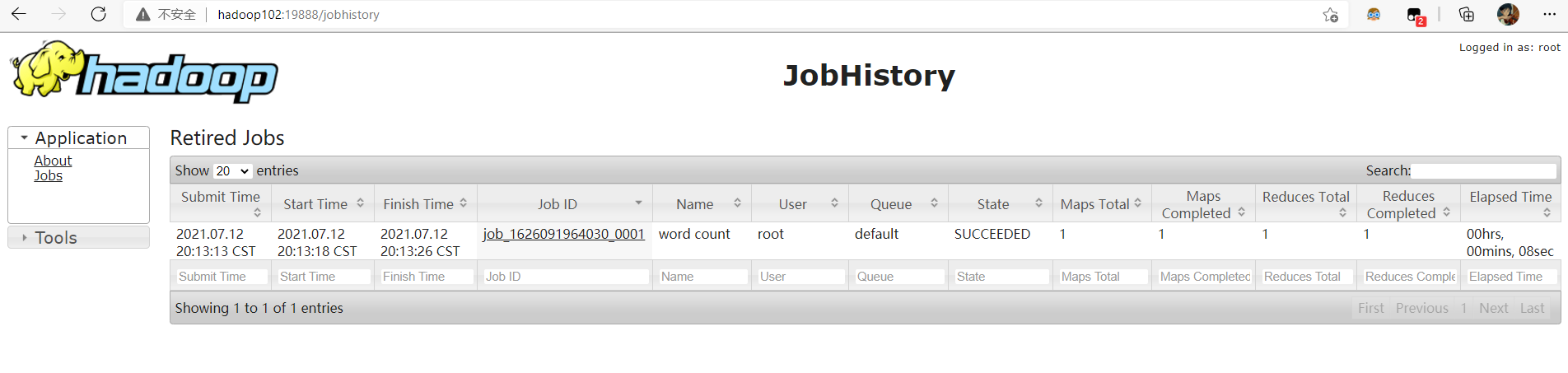
Browser access http://hadoop102:19888/jobhistory
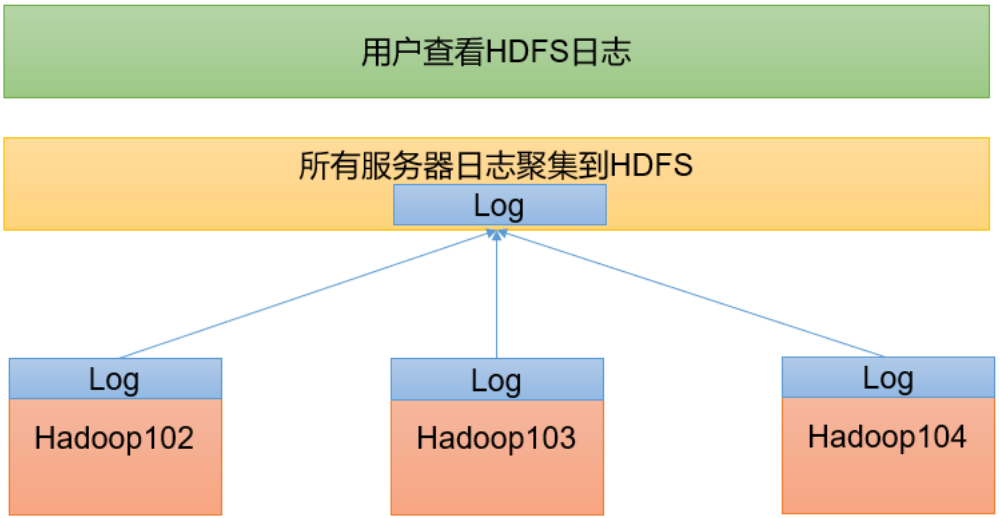
Configure log aggregation
Log aggregation concept: after the application runs, upload the program running log information to the HDFS system.
Benefits of log aggregation function: you can easily view the details of program operation, which is convenient for development and debugging.
To enable the log aggregation function, you need to restart NodeManager, ResourceManager and HistoryServer.
Configure yarn site xml
The configuration on the NameNode server is as follows
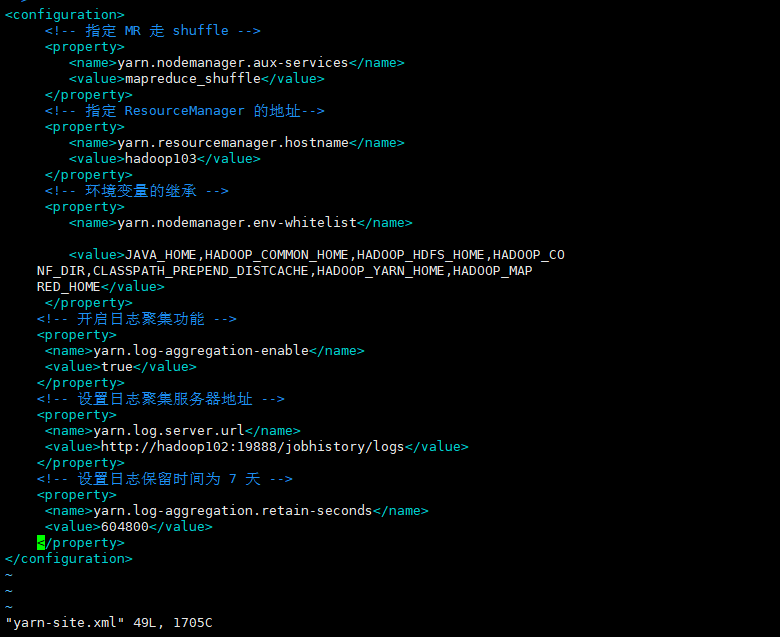
# Modify custom profile vim yarn-site.xml
<!-- Add the following file contents -->
<configuration>
<!-- Enable log aggregation -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Set log aggregation server address -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- Set the log retention time to 7 days -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
Cluster distribution configuration
xsync yarn-site.xml
Restart NodeManager, ResourceManager, and HistoryServer
# close sbin/stop-yarn.sh mapred --daemon stop historyserver # start-up sbin/start-yarn.sh mapred --daemon start historyserver
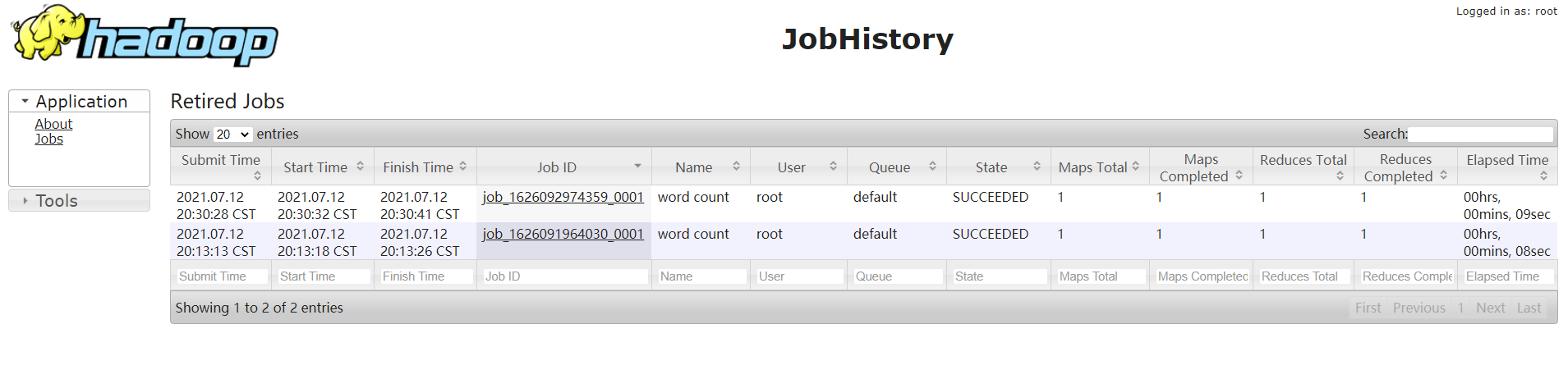
Delete and re execute the wordcount program to view the log
Historical server address http://hadoop102:19888/jobhistory
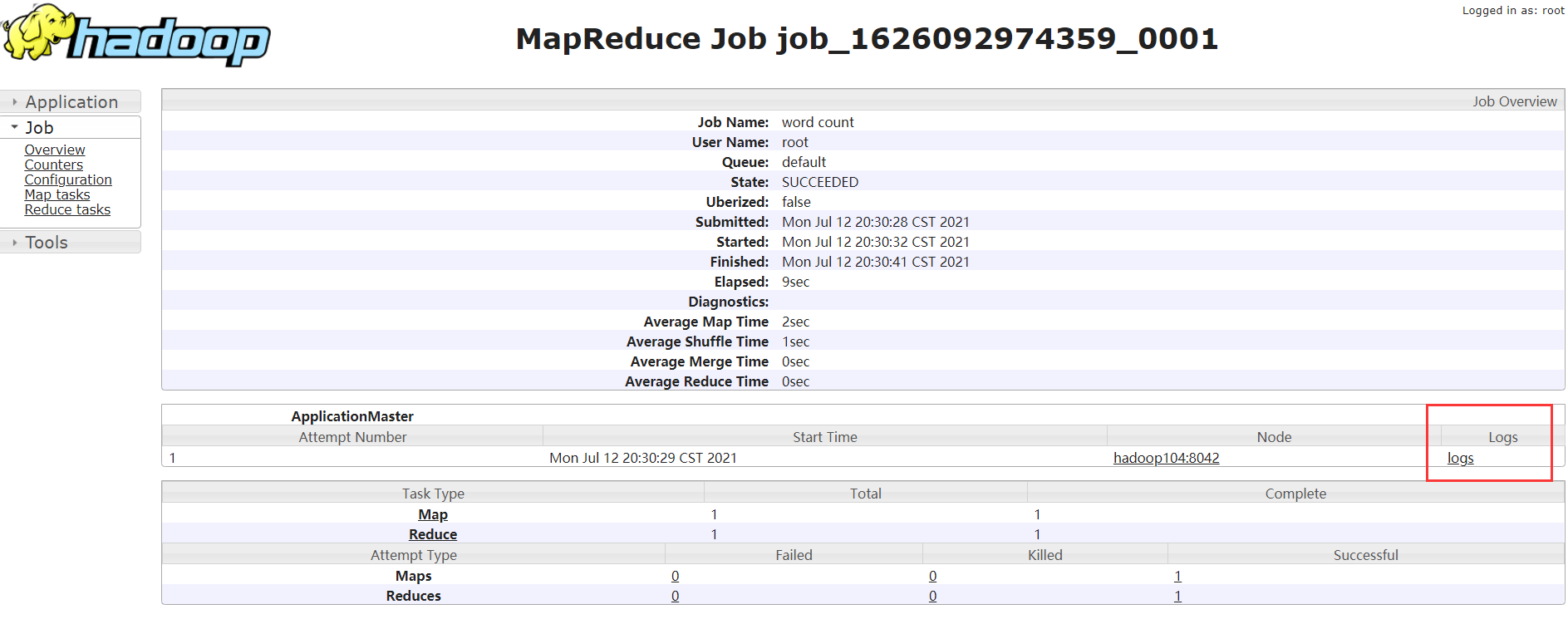
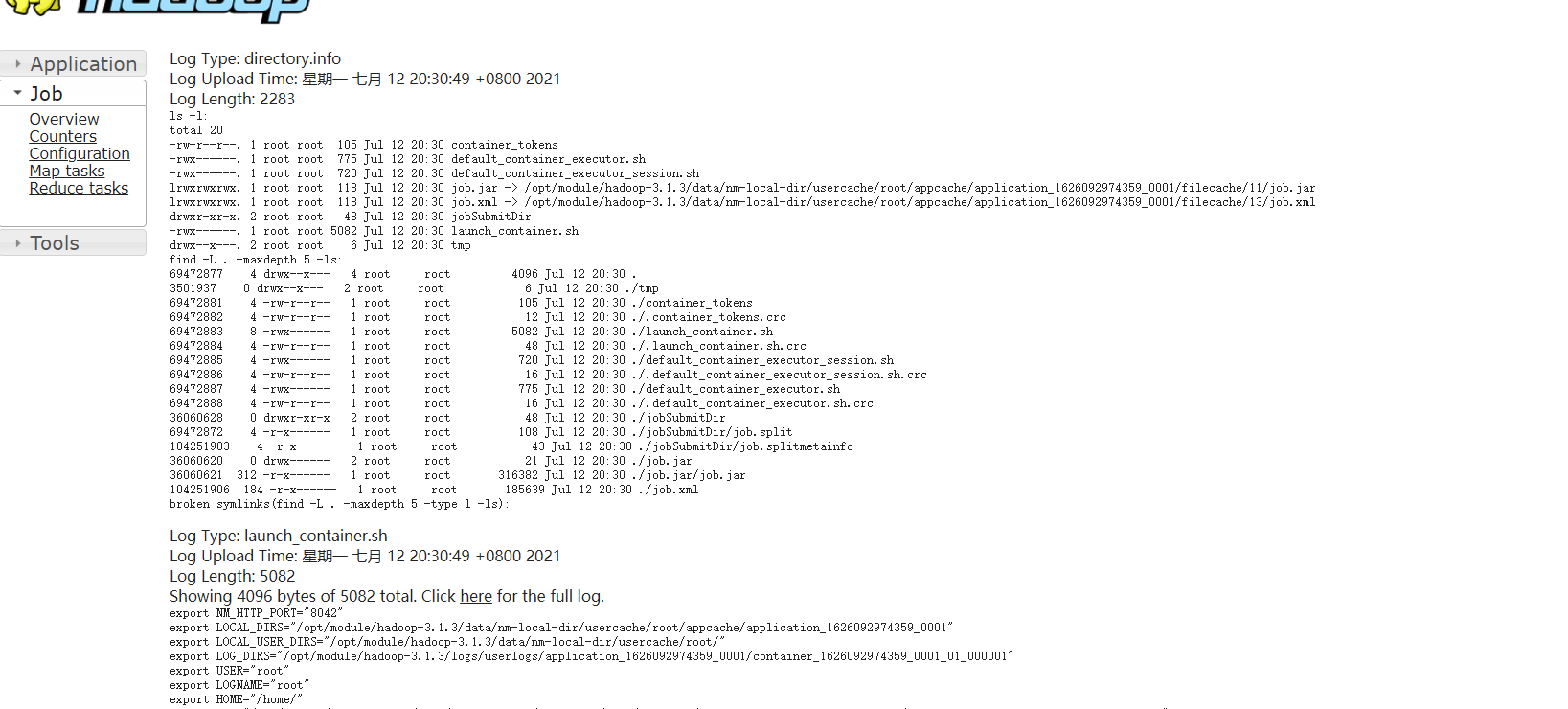
Summary of cluster start / stop modes
Each module starts / stops separately (ssh configuration is the premise)
Overall start / stop HDFS
start-dfs.sh/stop-dfs.sh
Overall start / stop of YARN
start-yarn.sh/stop-yarn.sh
Each service component starts / stops one by one
Start / stop HDFS components respectively
hdfs --daemon start/stop namenode/datanode/secondarynamenode
Start / stop YARN
yarn --daemon start/stop resourcemanager/nodemanager
Write common scripts for Hadoop cluster
Hadoop cluster startup and shutdown script (including HDFS, Yan and Historyserver): myhadoop sh
cd /root/bin vim myhadoop.sh
The script code is as follows
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== start-up hadoop colony ===================" echo " --------------- start-up hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- start-up yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- start-up historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver";; "stop") echo " =================== close hadoop colony ===================" echo " --------------- close historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- close yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- close hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh";; *) echo "Input Args Error...";; esac
Grant script execution permission
chmod +x myhadoop.sh
Cluster distribution ensures that user-defined scripts can be used on cluster machines
xsync myhadoop.sh
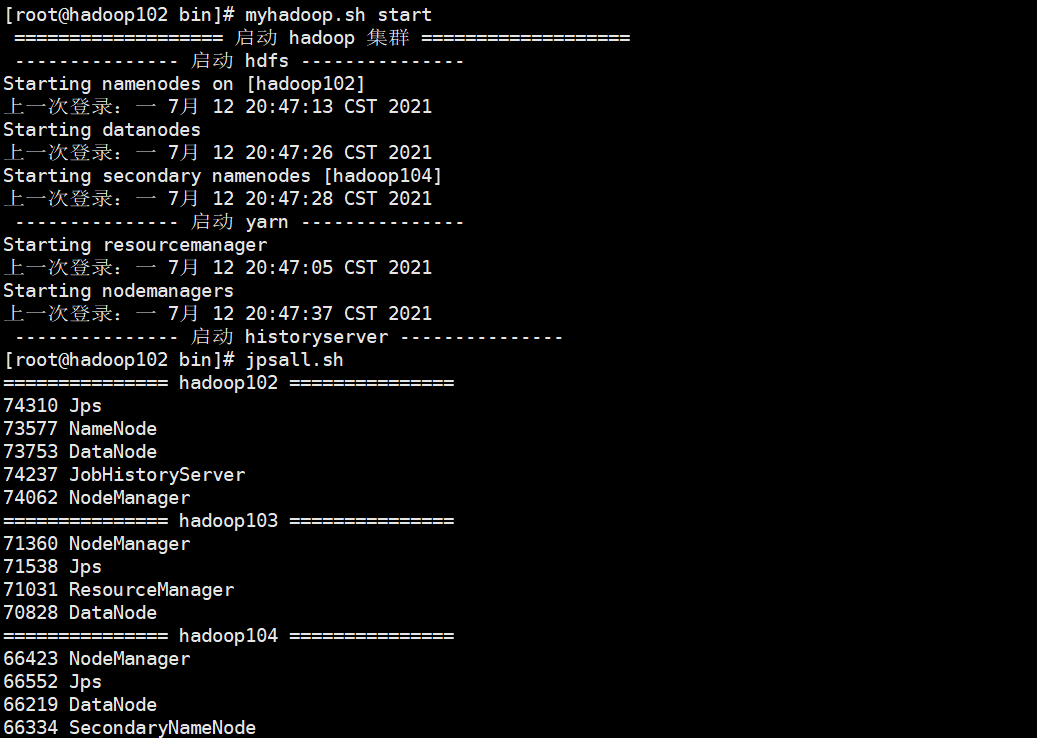
Write and view the Java process script of cluster server
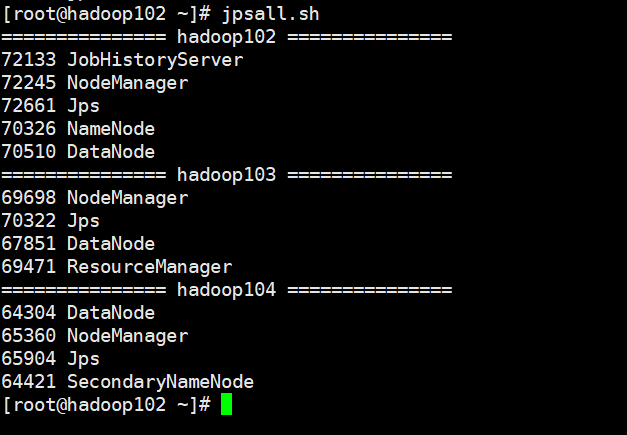
cd /root/bin vim jpsall.sh
The script code is as follows
#!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo =============== $host =============== ssh $host jps done
Grant script execution permission
chmod +x jpsall.sh
Cluster distribution ensures that user-defined scripts can be used on cluster machines
xsync jpsall.sh