I recently built a distributed hadoop environment using four Centos virtual machines, which simply simulated the online hadoop real distributed cluster, which is mainly used for amateur learning big data related systems.
One server serves as a NameNode, one as a Secondary NameNode, and the other two as DataNodes node servers, similar to the following architecture——
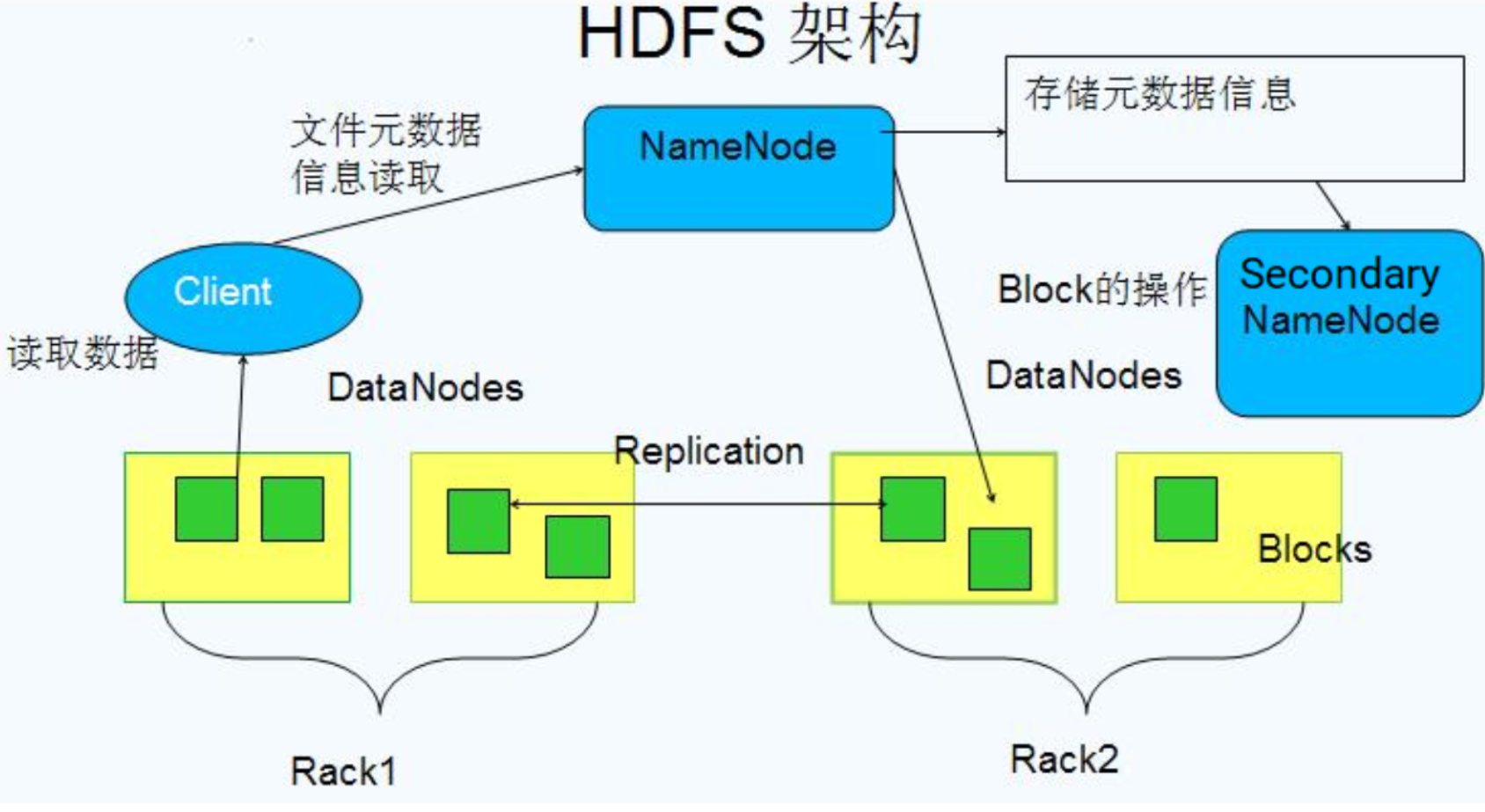
| NameNode | Secondary NameNode | DataNodes | |
|---|---|---|---|
| master1(192.168.200.111) | √ | ||
| master2(192.168.200.112) | √ | ||
| slave1(192.168.200.117) | √ | ||
| slave2(192.168.200.115) | √ |
Next, start counting the number of characters in the file through the wordcount provided by hadoop.
After starting the hadoop cluster, if the cluster is available, follow the steps below:
1, Enter the hadoop installation directory and create a test file example.txt
My installation directory is: / opt/hadoop/app/hadoop/hadoop-2.7.5
[root@192 hadoop-2.7.5]# pwd /opt/hadoop/app/hadoop/hadoop-2.7.5
Create a new example.txt and write some characters randomly:
aaa bbb cccc dedef dedf dedf ytrytrgtrcdscdscdsc dedaxa cdsvfbgf uyiuyi ss xaxaxaxa
Next, create an input folder on the hdfs file system to store the example.txt file——
[root@192 hadoop-2.7.5]# hdfs dfs -mkdir /input
Then, copy example.txt to the input directory on the hdfs system——
[root@192 hadoop-2.7.5]# hdfs dfs -put example.txt /input
Check and you can see that the example.txt file is already under the input directory——
[root@192 hadoop-2.7.5]# hdfs dfs -ls /input Found 1 items -rw-r--r-- 3 root supergroup 84 2021-10-20 12:43 /input/example.txt
After these preparations are completed, you can start using the jar package provided with hadoop to count the number of characters in the file example.txt.
2, Run wordcount to count the file characters
Directly execute on the server corresponding to the NameNode node——
[root@192 hadoop-2.7.5]# hadoop jar /opt/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /input /output
The general meaning of this line of instructions is that distributed computing counts the number of characters in the file under the input directory and reduce s the statistical results to output. Therefore, if the execution is OK, the statistical result record can be obtained under the output directory.
The first time I execute, an exception occurs, that is, after execution, the log runs to info mapreduce.job: running job: job_ 1631618032849_ In 0002, I got stuck here without any movement——
[hadoop@192 bin]$ hadoop jar /opt/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /input /output 21/10/20 10:43:29 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.200.111:8032 21/10/20 10:43:30 INFO input.FileInputFormat: Total input paths to process : 1 21/10/20 10:43:30 INFO mapreduce.JobSubmitter: number of splits:1 21/10/20 10:43:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1631618032849_0002 21/10/20 10:43:31 INFO impl.YarnClientImpl: Submitted application application_1631618032849_0002 21/10/20 10:43:31 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1631618032849_0002/ 21/10/20 10:43:31 INFO mapreduce.Job: Running job: job_1631618032849_0002
After Baidu, according to some ideas, the initial configuration of mapred-site.xml is changed from
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Change it here——
<configuration>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://master1:8001</value>
<final>true</final>
</property>
</configuration>
Then, restart the hadoop cluster and it will be normal. The log information will not be stuck, but will be executed in one step and the following log records will be printed——
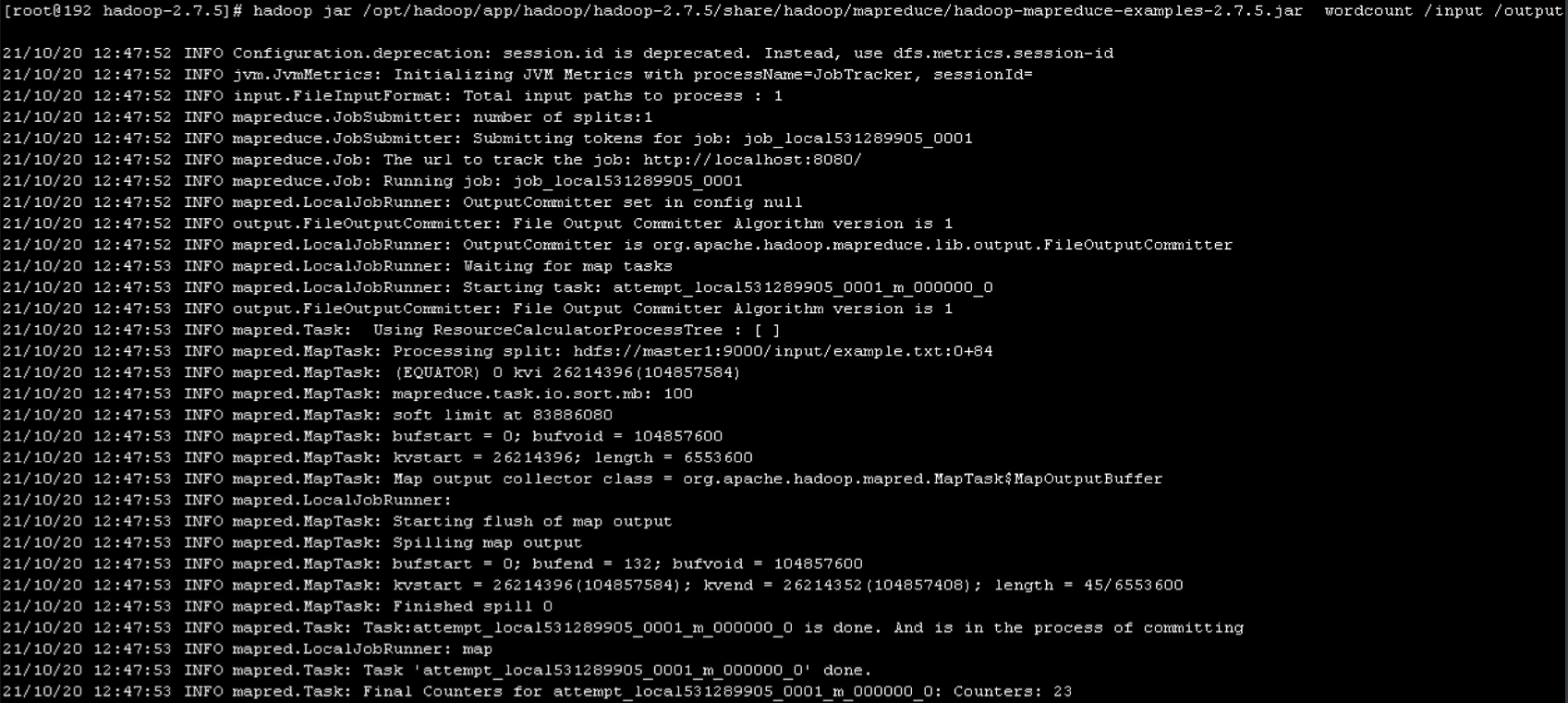
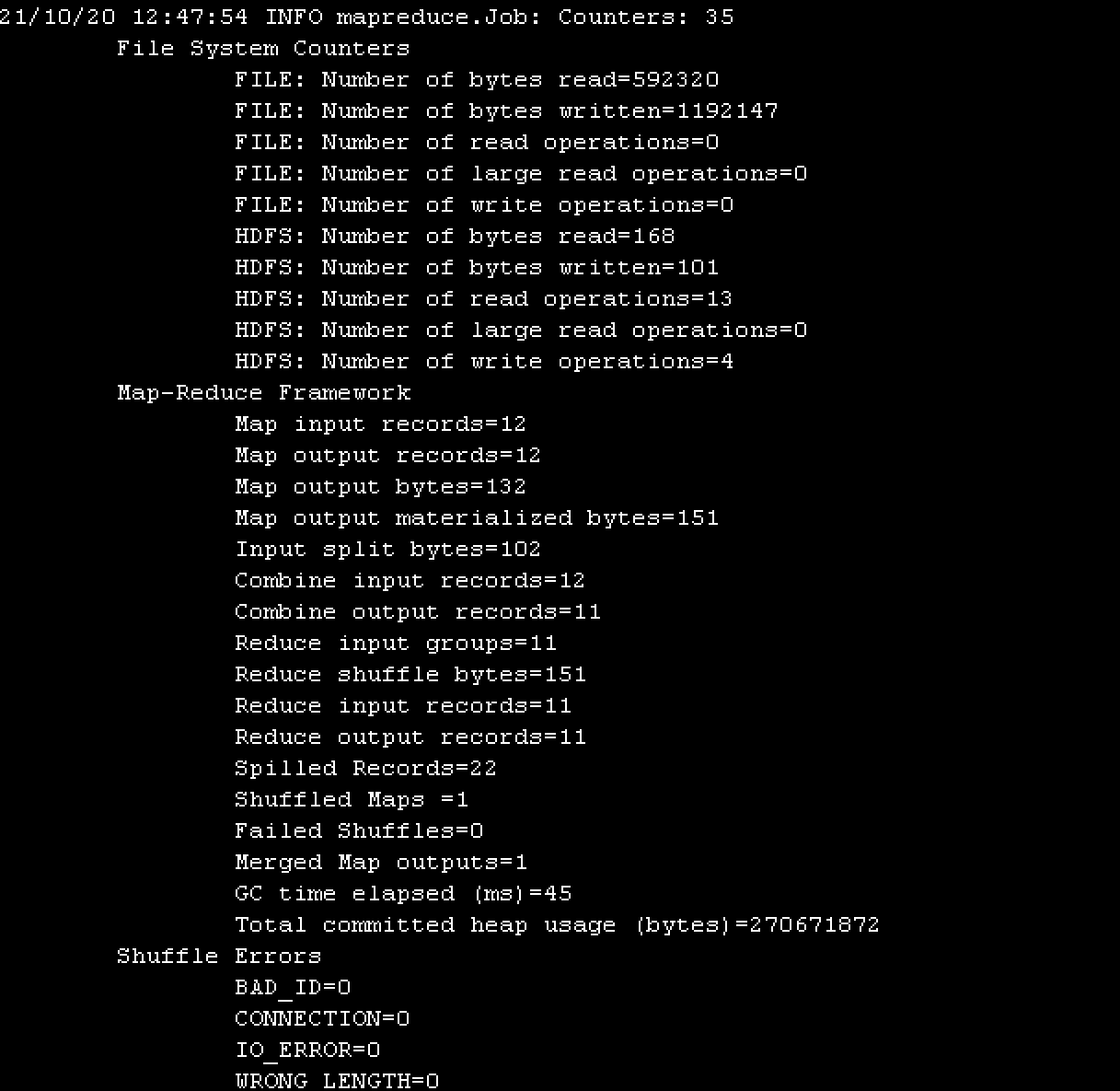
If there is no problem in the process, you can go to the last step to view the statistics results.
3, Get statistical results
After the above steps are executed, directly enter the instruction to view the information in the output directory. You can see that two files are generated——
[root@192 hadoop-2.7.5]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root supergroup 0 2021-10-20 12:47 /output/_SUCCESS -rw-r--r-- 3 root supergroup 101 2021-10-20 12:47 /output/part-r-00000
part-r-00000 file is used to store statistical results. Let's check it——
[root@192 hadoop-2.7.5]# hdfs dfs -cat /output/part-r-00000 aaa 1 bbb 1 cccc 1 cdsvfbgf 1 dedaxa 1 dedef 1 dedf 2 ss 1 uyiuyi 1 xaxaxaxa 1 ytrytrgtrcdscdscdsc 1
Compared with the previous example.txt file, you can see that there are two dedf strings and one other. The hadoop statistical results are indeed the same.
The above is a small case of a preliminary understanding of hadoop. Next, I will summarize the experience worth sharing in the learning process.