1, window concept
Window is the core of dealing with infinite flow. The window divides the flow into "buckets" of limited size, and we can apply the calculation on the buckets. This document focuses on how to perform window operations in Flink and how programmers can get the most benefit from the functions it provides.
The general structure of a windowed Flink program is as follows. The first segment refers to keyed flow, while the second segment refers to non keyed flow. As you can see, the only difference is that keyBy(...) calls the keystream, while window(...) calls the windowwall(...) of the non keystream. This will also serve as a guidepost for the rest of the page.
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Generally, real streams are unbounded. How to deal with unbounded data?
In the natural environment, the generation of data is originally streaming. Whether it is the event data from the Web server, the trading data of the stock exchange, or the sensor data from the machine in the factory workshop, the data is streaming. However, when you analyze data, you can organize and process data around two models: bounded flow and unbounded flow. Of course, if you choose different models, the execution and processing methods of programs will be different.
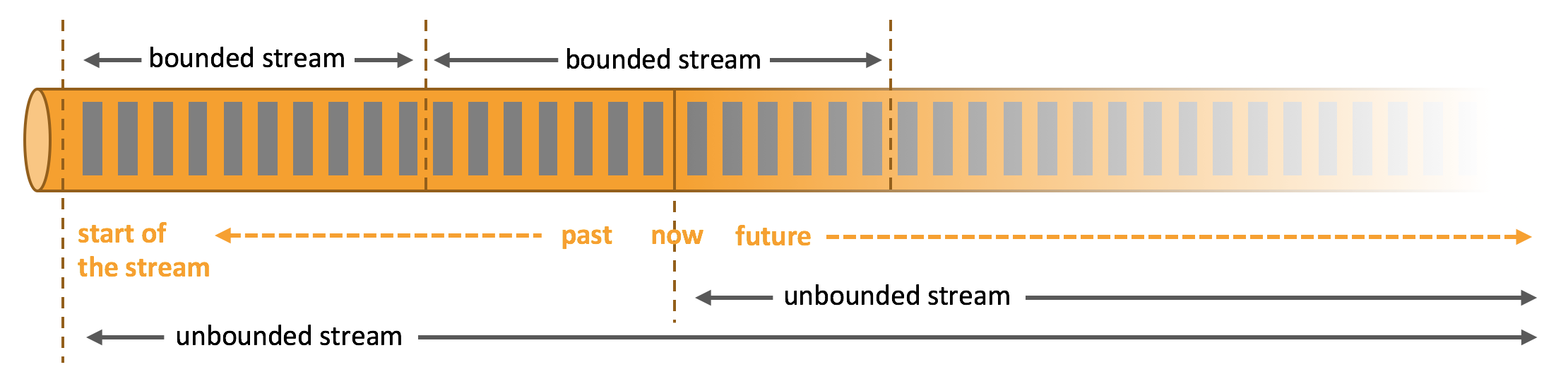
Source of the picture above: https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/learn-flink/overview/
- The infinite data stream can be segmented to obtain a limited data set for processing
Is to get a bounded flow - window is a way to cut an infinite flow into a finite flow, which will cut the flow
Data is distributed to bucket s of limited size for analysis
2, Time Window
1) Scrolling windows
The flip window evaluator assigns each element to a window of a specified window size. Scrolling windows have a fixed size and do not overlap. For example, if you specify a scrolling window with a size of 5 minutes, the current window will be evaluated and a new window will start every 5 minutes, as shown in the following figure:
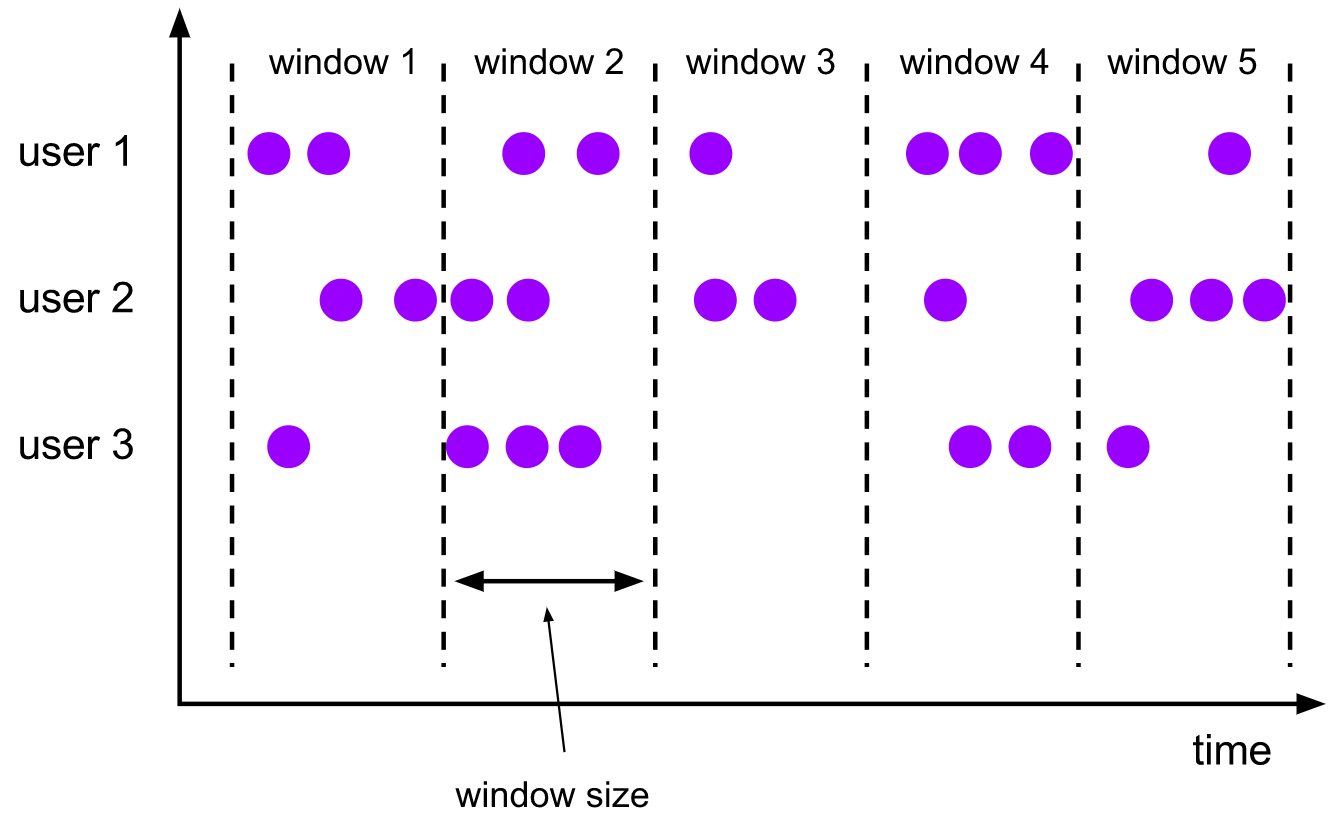
[features]
- Segment the data according to the fixed window length
- Time alignment, fixed window length, no overlap
[example code]
Tumbling event time windows: scrolling event time window
Tumbling processing time windows: scrolling processing time window
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
2) Sliding Windows
The sliding window assignor assigns an element to a fixed length window. Similar to the scroll window evaluator, the size of the window is configured by the window size parameter. Another window sliding parameter controls the frequency of sliding window startup. Therefore, if the sliding window is smaller than the window size, the sliding window can overlap. In this case, the element is assigned to multiple windows.
You can slide your window for 5 minutes, for example. In this way, a window will appear every 5 minutes, containing the events that arrive in the last 10 minutes, as shown in the following figure:
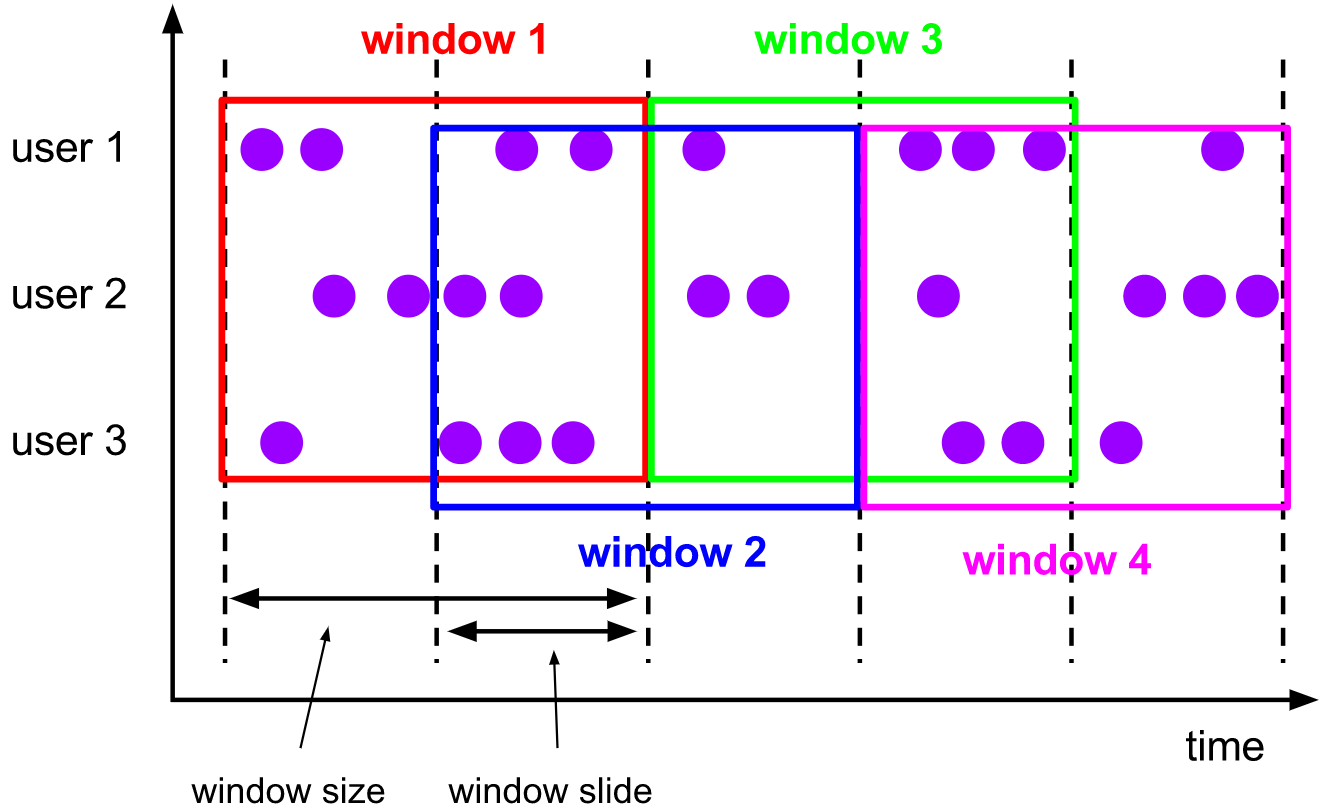
[features]
- Sliding window is a more generalized form of fixed window. Sliding window consists of fixed window
Length and sliding interval - The window length is fixed and can overlap
[example code]
SlidingEventTimeWindows: sliding event time window
SlidingProcessingTimeWindows: sliding processing time window
val input: DataStream[T] = ...
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
3) Session window (Session Windows)
The session window allocator groups elements according to the active session. Unlike sliding windows, session windows do not overlap, nor do they have fixed start and end times. On the contrary, when the session window does not receive elements for a period of time, that is, when an inactive gap occurs, the session window will close. The session window allocator can configure either a static session gap or a session gap extractor function that defines the length of inactivity. When this period of time expires, the current session closes and subsequent elements are assigned to a new session window.
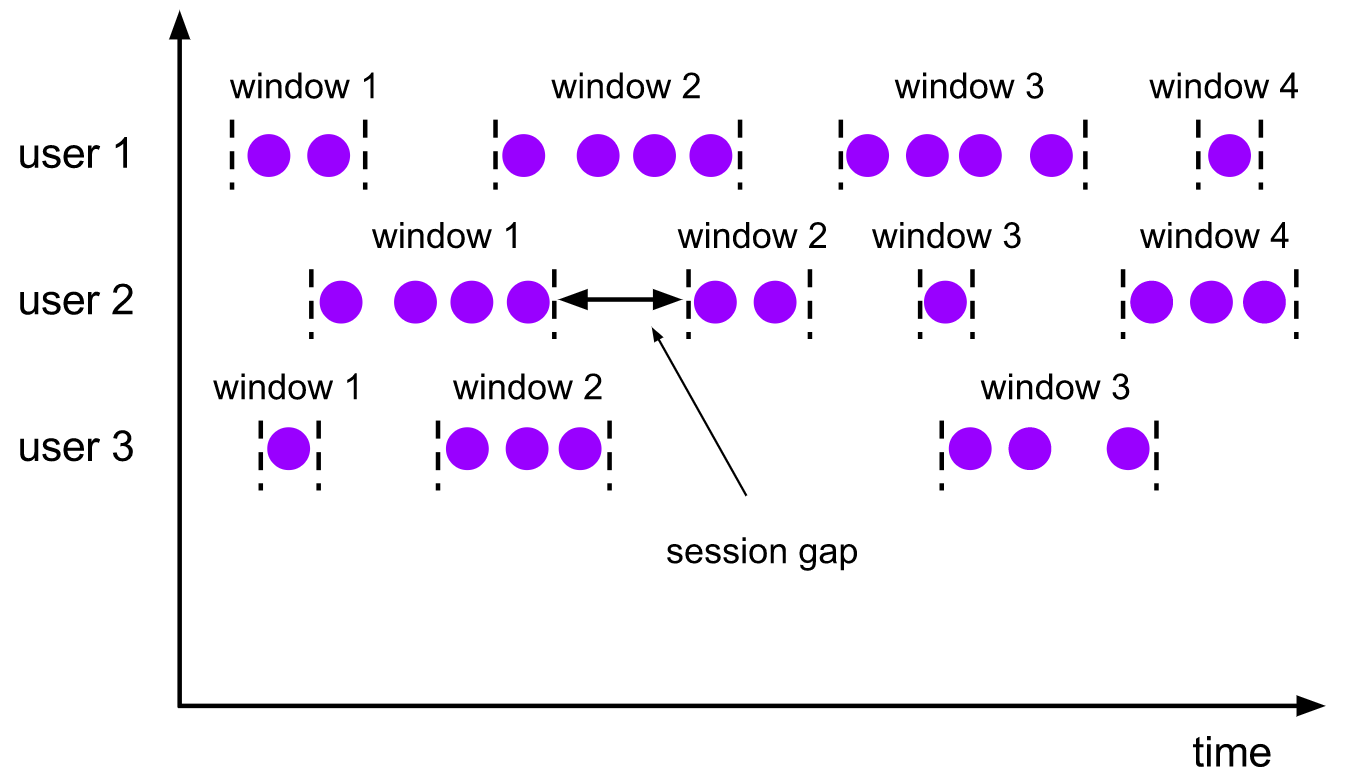
[features]
- It consists of a series of events combined with a timeout gap of a specified length of time, that is
If new data is not received for a period of time, a new window will be generated - Time no alignment
- The window length is not fixed and will not overlap
[example code]
EventTimeSessionWindows: session event time window
SlidingProcessingTimeWindows: session processing time window
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
3, window API
Window allocator -- window() method
- We can use it window() to define a window, and then do some aggregation based on this window
Closing or other processing operations. Note that the window () method can only be used after keyBy. - Flink provides three simpler types of time windows for defining time
The countWindowAll is also provided to define the counting window.
Tumbling event time windows: scrolling event time window
Tumbling processing time windows: scrolling processing time window
SlidingEventTimeWindows: sliding event time window
SlidingProcessingTimeWindows: sliding processing time window
EventTimeSessionWindows: session event time window
SlidingProcessingTimeWindows: session processing time window
4, Window assignor
window function defines the calculation operations to be performed on the data collected in the window. Can be divided into two categories.
1) incremental aggregation functions
- Each data will be calculated when it comes, keeping a simple state
- ReduceFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
- AggregateFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
2) full window functions
- First collect all the data in the window, and then traverse all the data when calculating
- ProcessWindowFunction
A ProcessWindowFunction can be defined and used as follows:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
3) Other optional window API s
- . trigger() -- trigger, which defines when the window closes, triggers the calculation and outputs the result
- . evictor() -- remover, which defines the logic to remove some data
- . allowedLateness() -- allow processing of late data
- . sideOutputLateData() -- put the late data into the side output stream
- . getSideOutput() -- get side output stream
5, Temporal semantics in Flink
Official documents
Flink explicitly supports the following three temporal semantics:
-
Event time: the time when the event is generated. It records the time when the equipment produces (or stores) the event
-
Ingestion time: the time when data enters Flink, and the time recorded when Flink reads events
-
Processing time: the local system time to execute the operator, which is machine related
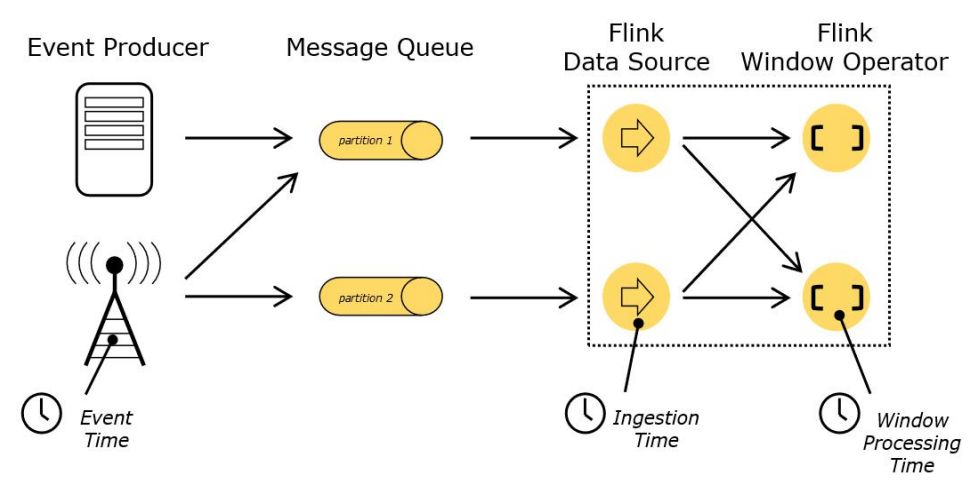
Source of the picture above: https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/concepts/time/
6, Set Event Time
We can call setStreamTimeCharacteristic on the execution environment directly in the code
Method, set the time characteristics of the stream, the specific time, and extract the timestamp from the data
import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment var env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
7, Watermark
1) Why is a Watermark needed
When Flink processes the data stream in Event Time mode, it will process the data according to the time stamp in the data
The time-based processing of distributed data will be out of order, which will lead to inaccurate data processing based on time. Watermark comes from processing out of order data.
2) How to use Watermark to deal with out of order data?
When a timestamp reaches the window closing time, the window calculation should not be triggered immediately, but wait
Wait for a period of time, and then close the window when the late data comes.
- Watermark is a mechanism to measure the progress of Event Time, which can set delay trigger;
- Watermark is used to handle out of order events, and to correctly handle out of order events, it is usually used
Watermark mechanism is implemented in combination with window; - Watermark in the data stream is used to represent data whose timestamp is less than watermark,
All have arrived. Therefore, the execution of window is also triggered by Watermark; - watermark is used to let the program balance the delay and the correctness of the result.
3) Characteristics of watermark
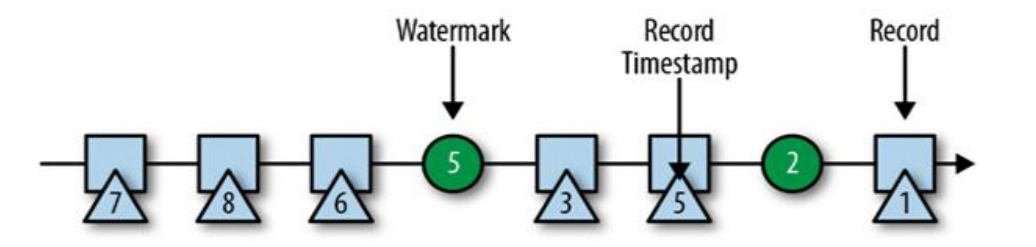
- watermark is a special data record
- watermark must be monotonically incremented to ensure that the event time clock of the task is moving forward without delay
It's going backwards - watermark is related to the timestamp of the data
4) Transmission of watermark
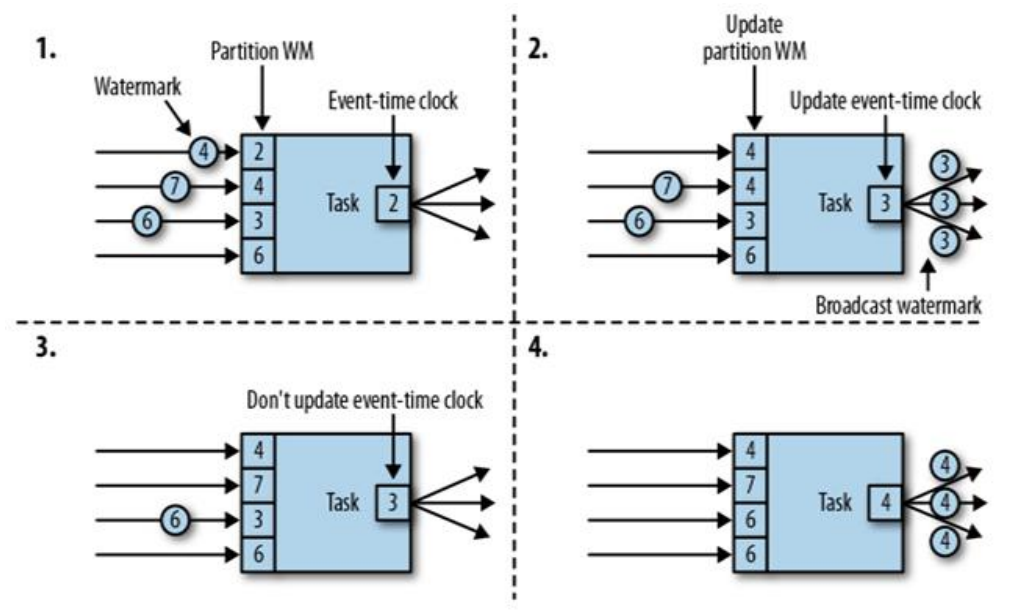
5) watermark strategy and Application
1) Watermark strategy introduction
The allocation of timestamps goes hand in hand with the generation of watermark, which can tell Flink application the progress of event time. It can configure the generation method of watermark by specifying WatermarkGenerator.
When using the Flink API, you need to set a WatermarkStrategy that contains both timestampassignor and WatermarkGenerator. WatermarkStrategy tool class also provides many commonly used watermark strategies, and users can also build their own watermark strategies in some necessary scenarios. The WatermarkStrategy interface is as follows:
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{
/**
* Instantiate a {@ link TimestampAssigner} that can be assigned a timestamp according to the policy.
*/
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
/**
* Instantiate a watermark generator according to the policy.
*/
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
Generally, you don't need to implement this interface. Instead, you can use the general watermark policy in the WatermarkStrategy tool class, or you can use this tool class to bind the custom TimestampAssigner with the WatermarkGenerator.
[for example] if you want to use the bounded out of order watermark generator and a lambda expression as the timestamp allocator, you can implement it as follows:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner[(Long, String)] {
override def extractTimestamp(element: (Long, String), recordTimestamp: Long): Long = element._1
})
[warm tip] the setting of TimestampAssigner is optional. In most cases, you don't need to specify it.
2) Apply using Watermark policy
WatermarkStrategy can be used in two places in the Flink application:
- The first is to use it directly on the data source
- The second is to use it directly after the operation of non data source.
[warm tip] compared with the first method, it is better because the data source can use watermark to generate information about shards/partitions/splits in the logic. In this way, the data source can usually track watermark more accurately, and the overall generation of watermark will be more accurate.
[example] the second method should be used only when the policy cannot be set directly on the data source (set WatermarkStrategy after any conversion operation):
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream: DataStream[MyEvent] = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter())
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.filter( _.severity == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>)
withTimestampsAndWatermarks
.keyBy( _.getGroup )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) => a.add(b) )
.addSink(...)
[example] processing idle data sources
If a partition / slice in the data source does not send event data for a period of time, it means that WatermarkGenerator will not obtain any new data to generate watermark. We call this kind of data source idle input or idle source. In this case, a problem occurs when some other partition still sends event data. Since the calculation method of downstream operator watermark is to take the minimum value of watermark of all different upstream parallel data sources, its watermark will not change.
WatermarkStrategy .forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20)) .withIdleness(Duration.ofMinutes(1))
3) Usage scenario
- For ordered data, there is no need to delay triggering. You can only specify the timestamp.
// Note that the time is in milliseconds, so depending on the timestamp, it may need to be multiplied by 1000 dataStream.assignAscendingTimestamps(_.timestamp * 1000)
- Flink exposes the TimestampAssigner interface for us to implement, so that we can customize such as
How to extract timestamp from event data and generate watermark.
// MyAssigner can have two types, both of which are inherited from TimestampAssigner dataStream.assignAscendingTimestamps(new MyAssigner())
4)TimestampAssigner
It defines the methods of extracting timestamp and generating watermark. There are two types
1,AssignerWithPeriodicWatermarks
- Generate watermarks periodically: the system will periodically insert watermarks into the stream
- The default cycle is 200 milliseconds. You can use executionconfig setAutoWatermarkInterval()
Method - The ascending order and the previous disordered order processing boundedoutorderness are based on periodicity
watermark.
2,AssignerWithPunctuatedWatermarks
- There is no time periodic law, and the generation of watermark can be interrupted
AssignerWithPeriodicWatermarks and AssignerWithPunctuatedWatermarks can be discarded
Before Flink's new WatermarkStrategy, timestampassignor and WatermarkGenerator's abstract interfaces, Flink used AssignerWithPeriodicWatermarks and assignerwithpunctatedwatermarks. You can still see them in the API, but it is recommended to use the new interface, because it has a clear abstraction and separation of key points such as timestamp and watermark, and also unifies the generation method of watermark in the form of periodicity and markup.
Unfinished to be continued~