2021SC@SDUSC
A brief introduction to the research
Last week, we analyzed the iterator classes MarkableIterator, OutputCommitter, OutputFormat, and their subclasses, and learned more about custom format output. We will continue our analysis here, starting with org.apache.hadoop.mapreduce.Partitioner<KEY, VALUE>
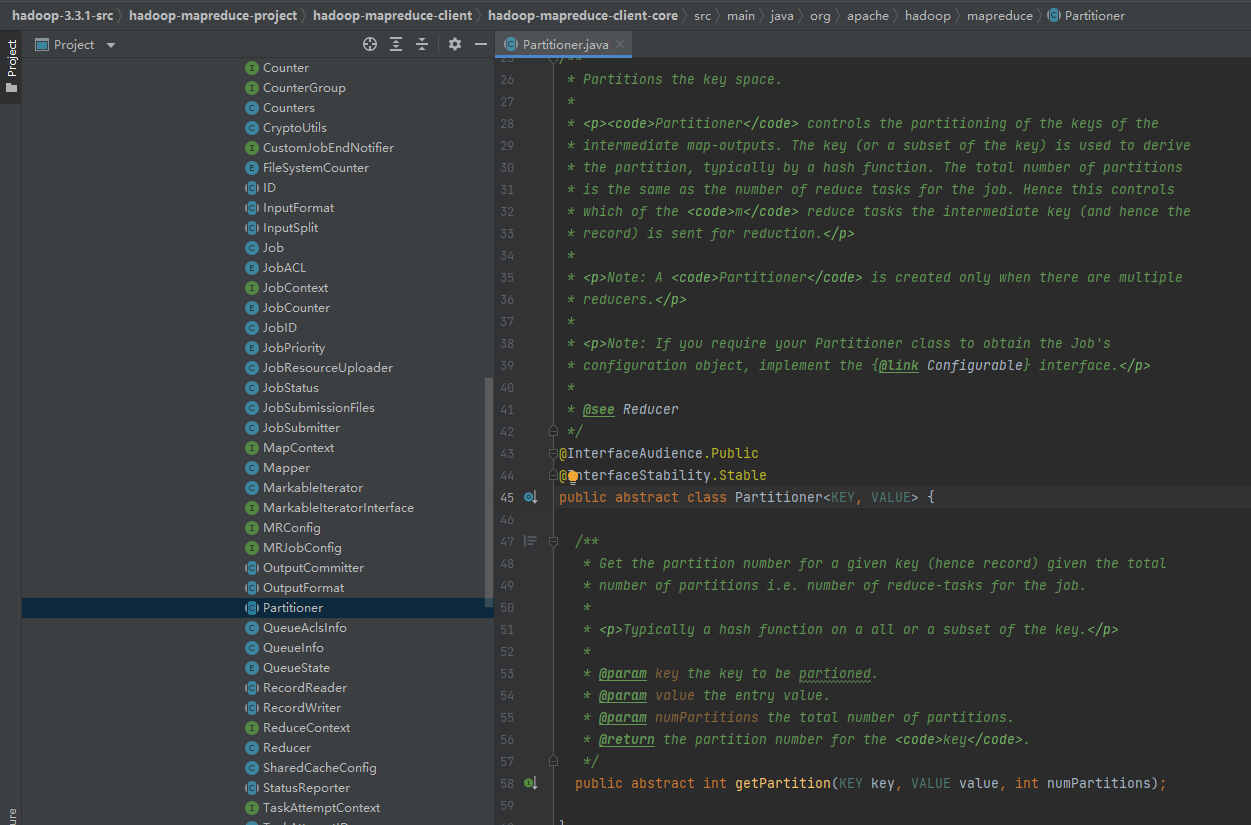
Org.apache.hadoop.mapreduce.Partitioner<KEY, VALUE>Source Code Analysis
First attach the source code of the file:
package org.apache.hadoop.mapreduce;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configurable;
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
The official explanation for the Partitioner is the partition of the key that the Partitioner controls the output of the intermediate map. A key (or subset of keys) is used to derive partitions, usually through a hash function. The total number of partitions is the same as the number of reduce tasks for the job. Therefore, this controls which mitigation tasks m sends intermediate keys (and records) to for mitigation.
Partitioners only create A when there are multiple reducer s. If you need the Partitioner class to get the Job's configuration object, you need to implement the Configurable interface first.
After querying the relevant documents, I learned that when making a MapReduce calculation, sometimes it is necessary to divide the final output data into different files, such as one file for the same province by province. By gender, you need to put the same gender data in one file. We know that the final output data comes from the Reducer task. Then, if you want to get more than one file, that means the same number of Reducer tasks are running. The data for the Reducer task comes from the Mapper task, which means that the Mapper task divides data and assigns different data to different Reducer tasks to run. The process by which Mapper tasks divide data is called Partition. The class responsible for partitioning the data is called a Partitioner.
You can see that there is only one function, getPartition(), under Partitioner. among
Key - The key value to partition
Value - Input value
numPartitions - Total number of partitions
This function gives the total number of partitions, that is, the number of reduced tasks for a job, and gets the partition number for the given key (and therefore record). It is usually a hash function on all or a subset of keys.
Subclass HashPartitioner Source Analysis
There are many subclasses under Partitioner, including BinaryPartitioner, HashPartitioner, KeyFieldBasedPartitioner, RehashPartitioner, TotalOrderPartitioner.
We further analyze the source code of one of the subclasses HashPartitioner:
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
//Use hash value of key and maximum value of top int by default to avoid data overflow
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner handles the output of Mapper tasks. The getPartition() method has three parameters. key and value in the source code refer to the output of Mapper tasks, numReduceTasks refers to the number of Reducer tasks set, and the default value is 1. Then the remainder of any integer divided by 1 must be 0. That is, the return value of the getPartition(...) method is always 0. That is, the output of a Mapper task is always sent to a Reducer task, which can only be output to one file.
Based on this analysis, if you want to eventually output to multiple files, the data should be divided into zones in the Mapper task. Then, we just need to follow certain rules to make the return value of the getPartition(...) method 0,1,2,3...
In most cases, we use the default partition function. But if we have special needs and need to customize the Partition to accomplish our tasks, the Partition provides a customizable solution.
For example, we want to partition the following data by the length of the string, one for each length of 1, one for each of 2, and one for each of 3.
Henan Province;1 Henan;2 China;3 Chinese people;4 large;1 Small;3 in;11
If we use the default partition function, it won't work. First of all, we need three partition outputs, so when setting the number of reduce s, be sure to set it to 3. Second, in partitions, partition is based on length, not on the hash code of the string. The rough code is as follows:
public static class PPartition extends Partitioner<Text, Text>{
@Override
public int getPartition(Text arg0, Text arg1, int arg2) {
/**
* Custom partitions, which implement strings of different lengths, into different reduce s
*
* Now you only have three strings in length, so you can set the number of reduce s to 3
* Set the number of partitions to
* */
String key=arg0.toString();
if(key.length()==1){
return 1%arg2;
}else if(key.length()==2){
return 2%arg2;
}else if(key.length()==3){
return 3%arg2;
}
return 0;
}
}
This custom Partition allows partitioning by the length of the string.
Source Analysis for org.apache.hadoop.mapreduce.QueueAclsInfo
Next, analyze the QueueAclsInfo class.
package org.apache.hadoop.mapreduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableUtils;
import org.apache.hadoop.util.StringInterner;
@InterfaceAudience.Public
@InterfaceStability.Evolving
public class QueueAclsInfo implements Writable {
private String queueName;
private String[] operations;
/**
* Default constructor for QueueAclsInfo.
*
*/
public QueueAclsInfo() {
}
public QueueAclsInfo(String queueName, String[] operations) {
this.queueName = queueName;
this.operations = operations;
}
public String getQueueName() {
return queueName;
}
protected void setQueueName(String queueName) {
this.queueName = queueName;
}
public String[] getOperations() {
return operations;
}
@Override
public void readFields(DataInput in) throws IOException {
queueName = StringInterner.weakIntern(Text.readString(in));
operations = WritableUtils.readStringArray(in);
}
@Override
public void write(DataOutput out) throws IOException {
Text.writeString(out, queueName);
WritableUtils.writeStringArray(out, operations);
}
}
QueueAclsInfo is a class used to encapsulate a specific user's queue ACL.
public QueueAclsInfo(String queueName,String[] operations) constructs a new QueueAclsInfo object from a queue name and an array of queue operations, where queueName is the name of the job queue and operations is the operation used.
readFields(DataInput in) can deserialize the field in of this object. To improve efficiency, reuse storage in existing objects where possible. in-DataInput is a deserialized object.
write(DataOutput out) serializes the fields of this object as out, and out-DataOuput is the object that needs to be serialized.
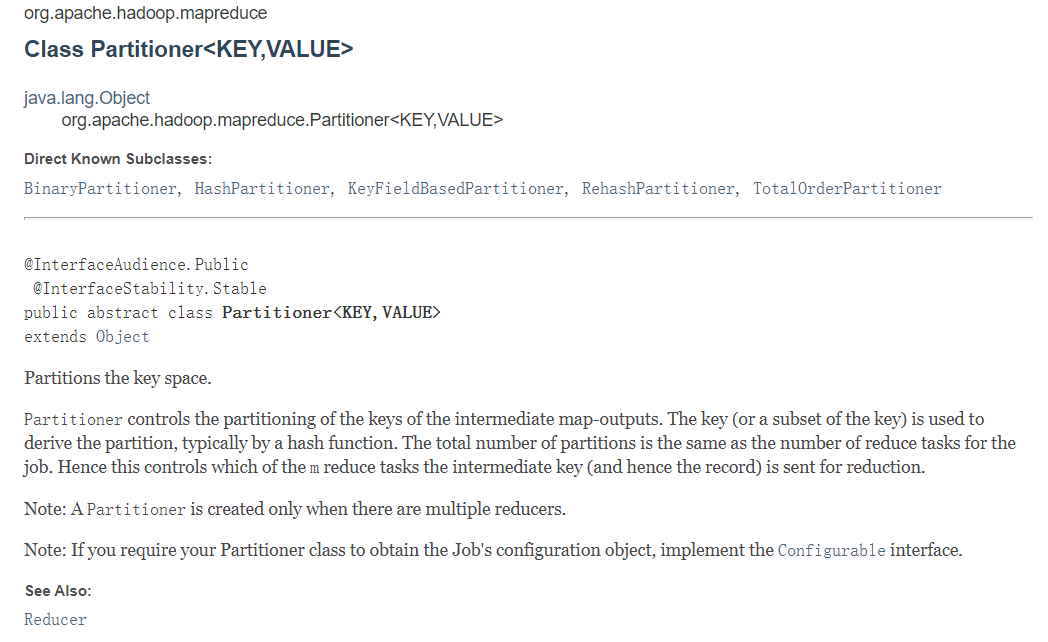
Org.apache.hadoop.mapreduce.RecordReader<KEYIN,VALUEIN>Source Code Analysis
RecordReader's official explanation is as follows:
RecordReader actually does this by slicing the data into key/value formats and passing it to Mapper as input.
package org.apache.hadoop.mapreduce;
import java.io.Closeable;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
/**
* The record reader breaks the data into key/value pairs for input to the
* {@link Mapper}.
* @param <KEYIN>
* @param <VALUEIN>
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
/**
* Called once at initialization.
* @param split the split that defines the range of records to read
* @param context the information about the task
* @throws IOException
* @throws InterruptedException
*/
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
/**
* Read the next key, value pair.
* @return true if a key/value pair was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
/**
* Get the current key
* @return the current key or null if there is no current key
* @throws IOException
* @throws InterruptedException
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
/**
* Get the current value.
* @return the object that was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
/**
* The current progress of the record reader through its data.
* @return a number between 0.0 and 1.0 that is the fraction of the data read
* @throws IOException
* @throws InterruptedException
*/
public abstract float getProgress() throws IOException, InterruptedException;
/**
* Close the record reader.
*/
public abstract void close() throws IOException;
}
All methods:
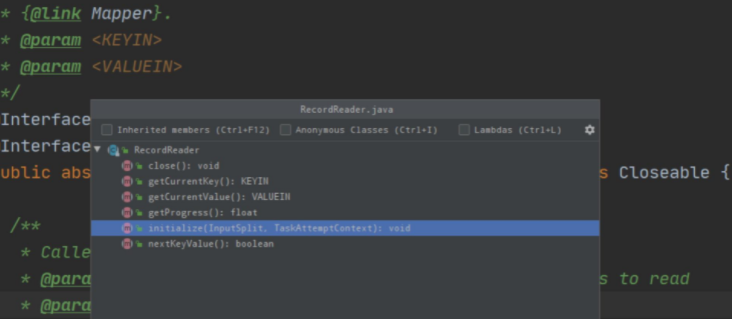
linitialize: Initialize RecordReader can only be called once
nextKeyValue: Read the next key/value pair
getCurrentKey: Current key
getCurrentValue: Current Value
getProcess: Get the current progress
colse: Close RecordReader
The RecordReader process can be divided into the following steps:
MapTask first constructs a NewTrackingRecordReader object, then invokes the initalize method of RecordReader before executing the Mapper#run method. InputFormat.createRecordReader is called in this initialization method. The default InputFormat is TextInputFormat, so go back to using TextInputFormat createRecordReader and return to LineRecordRead.
Next, the execution process of the initialization method is divided into the following steps
1.jiangInputSplit to FileSplit
2. Getting the maximum length each line can read defaults to Integer.MAX_VALUE
3. Get the start of the current FileSplit
4. Get the end of the current FileSplit
5. Get the file path of the current FileSplit
Enter the Mapper.run method after initialization to determine if there is the next key/value, and if so, the map method of the current key and value. Final close.
There are several common RecordReader s.
By looking at the source code, I summarized some of the subclasses.
LineRecordRader
The offset from the beginning of the text as the key
Whole line of text as value
CombineFileRecordReader
Processing EcordReader for each chunk in CombineInputSplit,
CombineInputSplit contains different small file chunk information
However, the data for each file is read by a separate RecordReader, while the CombineFileRecordReader is responsible for manipulating the chunk data only
DBRecordReader
Reading data from a database
keyValueRecordReader: Divides each row of data according to the specified delimiter.
No delimiter specified, key is the whole line of text, value is empty
summary
This time, we analyze the class Partitioner and its representative subclass HashPartitioner, and make some attempts to define the word Partitioner. Then QueueAclsInfo and RecordReader are analyzed. Meanwhile, the methods of RecordReader and several common RecordReaders are analyzed, which lays a foundation for the source code analysis in the future.