Apache Hadoop
##Background
With the development requirements of information internet and Internet of things, the trend of interconnection of all things is imperative. This leads to the evolution of architecture from a single architecture to a highly concurrent distributed architecture. Data storage also began to evolve from the original stand-alone storage to distributed storage.
-
JavaWeb: in order to cope with high concurrency and distribution, LNMP: (Linux, Nginx, MySQL, PHP) is proposed.
-
-
Massive data storage | data analysis: storage scheme (HDFS), computing scheme (Map Reduce, Storm, Spark, Flink)
Big data background
Distributed: cross machine and cross process communication between services is called distributed
- storage
- Stand alone storage: capacity limitation, poor scalability and data disaster recovery
- Distributed storage: use the storage cluster to realize the parallel reading and writing of massive data and improve the throughput of the system. At present, distributed file storage schemes for traditional business areas include file storage and block storage.

- Calculation (analysis)
- Single machine analysis / calculation: slow, limited by the memory, CPU and network limitations of single machine storage
- Distributed computing: assign computing tasks to a special computing cluster to be responsible for task computing. Break the bottleneck of stand-alone computing, realize parallel computing, and simulate the computing power of multi-core CPU. It can achieve the effective analysis of data in a certain time.
Hadoop appears
In order to solve a series of problems caused by massive data, people realized the prototype of Hadoop in the early Nutch project by referring to the papers published by Googl e File System and simple Data processing on large cluster, In the early stage, there were two plates in Nutch: NDFS (Nutch distribution file system) and MapReduce, which respectively solved the two problems of storage and calculation of the project. Then, the plate was stripped into Nutch to form an independent module, and finally renamed Hadoop.
-
HDFS: Hadoop distributed file system
-
MapReduce: Distribution -- > summary. MapReduce is a general distributed parallel computing framework in hadoop.
Doug Cutting, known as the father of Hadoop, is the chairman of Apache Software Foundation and the initiator of Lucene, nutch, Hadoop and other projects. At first, Hadoop was just a part of nutch, a subproject of Apache Lucene. Lucene is the first open-source full-text search engine toolkit in the world. Nutch is based on Lucene and has the functions of web page capture and analysis. It can realize the development of a search engine. However, if it is put into use, it must respond in a very short time and be able to analyze and process hundreds of millions of web pages in a short time, This requires consideration of distributed task processing, fault recovery and load balancing. Later, Doug Cutting transplanted the technology from two papers of Google File System and MapReduce:Simplified Data Processing On Large Clusters, and named it Hadoop.
Download address: https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
Environment construction
Environmental preparation
-
Install the virtual machine and CentOS-7 64 bit
-
Install JDK and configure environment variables
① Install jdk
[root@CentOS ~]# rpm -ivh jdk-8u191-linux-x64.rpm
Warning: jdk-8u191-linux-x64.rpm: head V3 RSA/SHA256 Signature, secret key ID ec551f03: NOKEY
In preparation... ################################# [100%]
Upgrading/install...
1:jdk1.8-2000:1.8.0_191-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
By default, the JDK is installed in the / usr/java path
② Configure environment variables
[root@CentOS ~]# vi .bashrc JAVA_HOME=/usr/java/latest PATH=$PATH:$JAVA_HOME/bin CLASSPATH=. export JAVA_HOME export PATH export CLASSPATH # Reload variables using the source command [root@CentOS ~]# source ~/.bashrc
- Configure host name
[root@CentOS ~]# vi /etc/hostname CentOS
reboot is required after modifying the host name
-
Configure the mapping relationship between host name and IP
① View ip
[root@CentOS ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:3c:e6:31 brd ff:ff:ff:ff:ff:ff
inet 192.168.73.130/24 brd 192.168.73.255 scope global noprefixroute dynamic ens33
valid_lft 1427sec preferred_lft 1427sec
inet6 fe80::fffe:2129:b1f8:2c9b/64 scope link noprefixroute
valid_lft forever preferred_lft forever
You can see that the address of the network card ens33 is 192.168 73.130 then map the relationship between hostname and IP in / etc/hosts
[root@CentOS ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.73.130 CentOS
-
Configure SSH password free authentication
① Generate the public-private key pair required for authentication
[root@CentOS ~]# ssh-keygen -t rsa -P '' Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:KIx5N+++qLzziq6LaCBT2g5Dqcq0j+TxGV3jJXs7cwc root@CentOS The key's randomart image is: +---[RSA 2048]----+ | | | | | . | | o.+ . | |o+o + ++S. | |O....ooo= E | |*B.. . o.. . | |*+=o+ o.o.. . | |**++=*o.+o+ . | +----[SHA256]-----+
② Add the trust list, and then realize password free authentication
[root@CentOS ~]# ssh-copy-id CentOS /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'centos (192.168.73.130)' can't be established. ECDSA key fingerprint is SHA256:WnqQLGCjyJjgb9IMEUUhz1RLkpxvZJxzEZjtol7iLac. ECDSA key fingerprint is MD5:45:05:12:4c:d6:1b:0c:1a:fc:58:00:ec:12:7e:c1:3d. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@centos's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'CentOS'" and check to make sure that only the key(s) you wanted were added.
③ Test whether to set ssh password free successfully
[root@CentOS ~]# ssh root@CentOS Last failed login: Fri Sep 25 14:19:39 CST 2020 from centos on ssh:notty There was 1 failed login attempt since the last successful login. Last login: Fri Sep 25 11:58:52 2020 from 192.168.73.1
If you do not need to enter a password, SSH password free authentication is successful!
- Turn off firewall
[root@CentOS ~]# systemctl stop firewalld.service # Shut down service [root@CentOS ~]# systemctl disable firewalld.service # Turn off startup and self startup [root@CentOS ~]# firewall-cmd --state # View firewall status not running
HADOOP installation
- Unzip and install Hadoop, Download https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
[root@CentOS ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr/
- Configure HADOOP_HOME environment variable
[root@CentOS ~]# vi .bashrc JAVA_HOME=/usr/java/latest HADOOP_HOME=/usr/hadoop-2.9.2/ PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin CLASSPATH=. export JAVA_HOME export PATH export CLASSPATH export HADOOP_HOME # Reload HADOOP_HOME environment variable [root@CentOS ~]# source .bashrc
- Configure the hadoop configuration file, etc / hadoop / {core site. Xml|hdfs-site. Xml|slaves}
① Configure core site xml
[root@CentOS ~]# cd /usr/hadoop-2.9.2/ [root@CentOS hadoop-2.9.2]# vi etc/hadoop/core-site.xml
<!--NameNode Access portal-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs Working base directory-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
② Configure HDFS site xml
[root@CentOS ~]# cd /usr/hadoop-2.9.2/ [root@CentOS hadoop-2.9.2]# vi etc/hadoop/hdfs-site.xml
<!--block Replica factor-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--to configure Sencondary namenode Physical host-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
③ Configure slave text file
vi etc/hadoop/slaves
CentOS
- Start HDFS system
① When you start the HDFS system for the first time, you need to format the system to prepare for subsequent startup. Here, you need to pay attention to this only when you start it for the first time. You can ignore this step when you start HDFS again in the future!
[root@CentOS ~]# hdfs namenode -format ... 20/09/25 14:31:23 INFO common.Storage: Storage directory /usr/hadoop-2.9.2/hadoop-root/dfs/name has been successfully formatted. ...
Create the image file that needs to be loaded when the NameNode service starts in HDFS.
② Start HDFS service
The startup script is placed in the sbin directory. Because we have set the sbin directory to PATH, we can directly use start DFS The SH script starts HDFS. If you want to shut down the HDFS system, you can use stop DFS sh
[root@CentOS ~]# start-dfs.sh Starting namenodes on [CentOS] CentOS: starting namenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-namenode-CentOS.out CentOS: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-CentOS.out Starting secondary namenodes [CentOS] CentOS: starting secondarynamenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-secondarynamenode-CentOS.out
After successful startup, the user can view the java process using the jsp instruction provided with the JDK. Normally, the user can see three services: DataNode, NameNode and SecondaryNameNode.
[root@CentOS ~]# jps 3457 DataNode 3691 SecondaryNameNode 3325 NameNode 4237 Jps [root@CentOS ~]#
Finally, the user can access the WEB page embedded in the NameNode service to view the running status of HDFS. By default, the listening port of the service is 50070. The access effect is as follows:
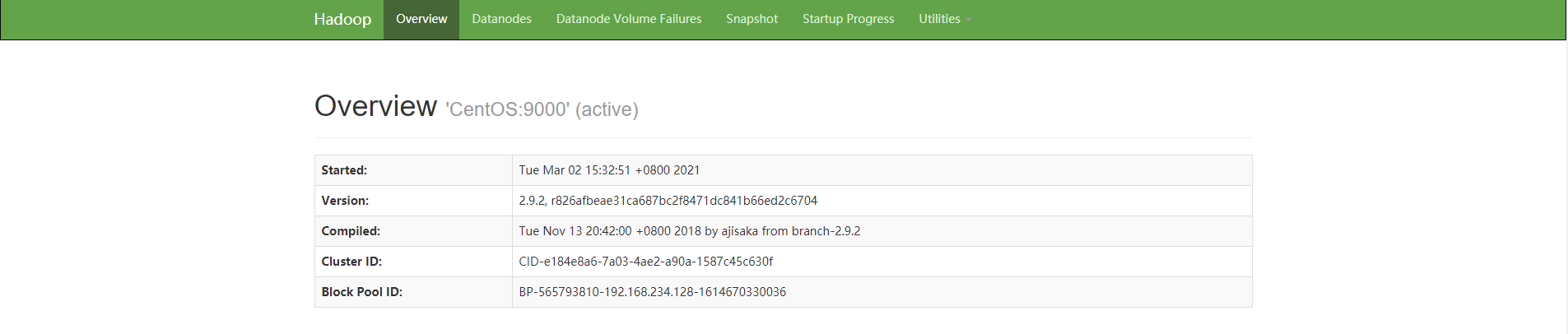
HDFS architecture
brief introduction
Hadoop Distributed File System (HDFS) is a Distributed File System designed to run on common hardware (Distributed File System). It has a lot in common with the existing Distributed File System. But at the same time, it is also very different from other distributed file systems. HDFS is a highly fault-tolerant system, which is suitable for deployment on cheap machines. HDFS can provide high-throughput data access, and is very suitable for applications on large-scale data sets. HDFS relaxes one Part of POSIX constraints to achieve the purpose of streaming reading file system data. HDFS was originally developed as the infrastructure of the Apache Nutch search engine project. HDFS is part of the Apache Hadoop Core project.
HDFS has a high Fault tolerance It is designed to be deployed on low-cost hardware, and it provides high throughput to access application data, which is suitable for applications with large data set s.
framework
NameNode & DataNodes
HDFS is a master/slave architecture. An HDFS cluster contains a NameNode. The service is the main service, which is responsible for managing the Namespace of the file system and responding to the regular access of the client. In addition, there are many DataNode nodes, and each DataNode is responsible for managing the files stored on the host where the DataNode runs. HDFS exposes a file system Namespace and allows user data to be stored in files. The bottom layer of HDFS will divide the file into 1~N blocks, which are stored on a series of datanodes. The NameNode is responsible for the DDL operations of modifying the Namespace, such as opening, closing and modifying files or folders. NameNode determines the mapping of data block to DataNode. The DataNode is responsible for responding to the read-write request of the client. At the same time, after receiving the instruction from the NameNode, the DataNode also needs to create, delete, copy and other operations of the block.
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
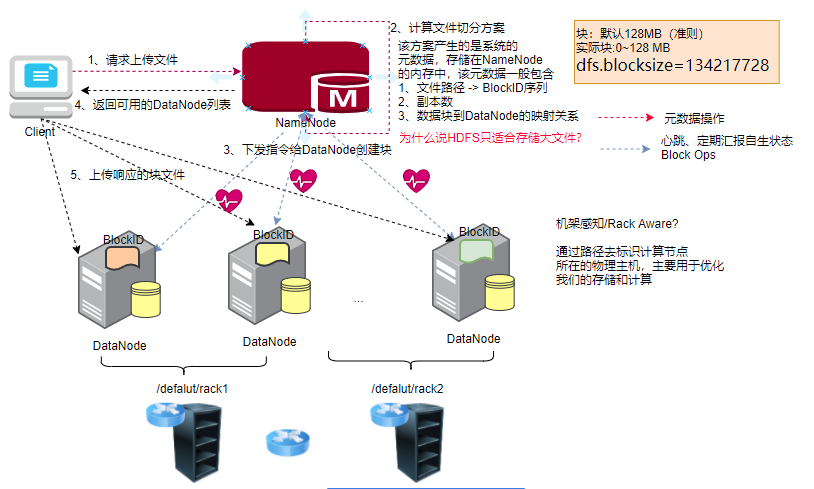
NameNode: use memory to store metadata in the cluster (file namespace - file directory structure, data block to DataNode mapping)
DataNode: it is responsible for responding to the client's read-write request for the data block and reporting its own status information to the NameNode.
Block: is the scale of HDFS segmentation file. The default is 128MB. A file can only have one block less than 128MB at most
Replica factor: in order to prevent block loss caused by DataNode downtime, HDFS allows one block and multiple backups. The default backup is 3
HDFS is not good at storing small files
Because Namenode uses stand-alone memory storage, small files will occupy more memory space, resulting in a waste of Namenode memory.
| case | NameNode | DataNode |
|---|---|---|
| 1 file 128MB | 1 data block mapping metadata | 128MB disk storage * (copy factor) |
| 128MB for 1000 files | 1000 * 1 data block mapping metadata | 128MB disk storage * (copy factor) |
HDFS rack awareness
Distributed clusters usually contain a large number of machines. Due to the limitations of rack slots and switch network ports, large distributed clusters usually span several racks, and machines in multiple racks form a distributed cluster. The network speed between machines in racks is usually higher than that between machines across racks, and the network communication between machines in racks is usually limited by the network bandwidth between upper switches.
In the design of Hadoop, the security and efficiency of data are considered. By default, three copies of data files are stored on HDFS. The storage strategy is:
The first block copy is placed in the data node where the client is located (if the client is not in the cluster, a suitable data node is randomly selected from the whole cluster to store it).
The second replica is placed on other data nodes in the same rack as the node where the first replica is located
The third replica is placed on nodes in different racks
In this way, if the local data is damaged, the node can get the data from the adjacent nodes in the same rack, and the speed must be faster than that from the cross rack nodes; At the same time, if the network of the whole rack is abnormal, it can also ensure that data can be found on the nodes of other racks. In order to reduce the overall bandwidth consumption and read delay, HDFS will try to let the reader read the copy closest to it. If there is a copy in the same rack as the reader, the copy is read. If an HDFS cluster spans multiple data centers, the client will also read the replica of the local data center first.
reference resources: https://www.cnblogs.com/zwgblog/p/7096875.html
SecondaryNameNode & NameNode
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-421xa6yc-1628160864369) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210302171532758. PNG)]( https://img-blog.csdnimg.cn/62f5b900e0ae46e8b2ad2f1f3a44fe59.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
fsimage: a binary text file stored on the physical host disk where the Namenode service is located. Metadata information is recorded
edits: a binary text file stored on the disk of the physical host where the Namenode service is located, which records the modification of metadata.
When the namenode service is started for the first time, the system will load the fsimage and edits files, merge them to obtain the latest metadata information, and update the fsimage and edits. Once the service is started successfully, the fsimage will not be updated during the service operation, but the operation will be recorded in the edits. This may cause the namenode to restart after long-term operation, cause the namenode to start too long, and may also cause the edits file to be too large. Therefore, Hadoop HDFS introduces a Secondary Namenode to assist the namenode in sorting metadata during operation.
The NameNode stores modifications to the file system as a log appended to a native file system file, edits. When a NameNode starts up, it reads HDFS state from an image file, fsimage, and then applies edits from the edits log file. It then writes new HDFS state to the fsimage and starts normal operation with an empty edits file. Since NameNode merges fsimage and edits files only during start up, the edits log file could get very large over time on a busy cluster. Another side effect of a larger edits file is that next restart of NameNode takes longer.
The secondary NameNode merges the fsimage and the edits log files periodically and keeps edits log size within a limit. It is usually run on a different machine than the primary NameNode since its memory requirements are on the same order as the primary NameNode.
The start of the checkpoint process on the secondary NameNode is controlled by two configuration parameters.
- dfs.namenode.checkpoint.period, set to 1 hour by default, specifies the maximum delay between two consecutive checkpoints, and
- dfs.namenode.checkpoint.txns, set to 1 million by default, defines the number of uncheckpointed transactions on the NameNode which will force an urgent checkpoint, even if the checkpoint period has not been reached.
The secondary NameNode stores the latest checkpoint in a directory which is structured the same way as the primary NameNode's directory. So that the check pointed image is always ready to be read by the primary NameNode if necessary.
NameNode startup process
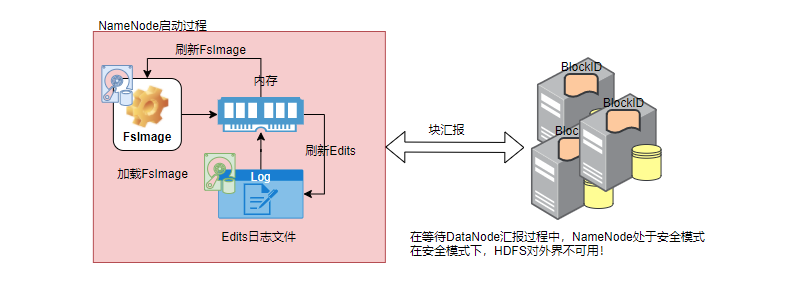
SafeMode of NameNode
During startup, NameNode will enter a special state called safemode HDFS does not replicate data blocks when it is in safe mode. NameNode receives heartbeat and Blockreport information from DataNode in safe mode. The report information of each DataNode block contains the information of all data blocks held on the physical host. Name will check whether all reported blocks meet the set minimum number of copies at startup (the default value is 1). The current block is recognized as safe only when the block reaches the minimum number of replicas. The NameNode waits for 30 seconds and then tries to check whether the proportion of the reported so-called safe blocks reaches 99.9%. If the threshold is reached, the NameNode automatically exits the safe mode. Then it starts to check whether the number of replicas of the block is lower than the configured number of replicas, and then sends a replication instruction for replication Copy of blocks.
On startup, the NameNode enters a special state called Safemode. Replication of data blocks does not occur when the NameNode is in the Safemode state. The NameNode receives Heartbeat and Blockreport messages from the DataNodes. A Blockreport contains the list of data blocks that a DataNode is hosting. Each block has a specified minimum number of replicas. A block is considered safely replicated when the minimum number of replicas of that data block has checked in with the NameNode. After a configurable percentage of safely replicated data blocks checks in with the NameNode (plus an additional 30 seconds), the NameNode exits the Safemode state. It then determines the list of data blocks (if any) that still have fewer than the specified number of replicas. The NameNode then replicates these blocks to other DataNodes.
Note: HDFS will automatically enter and exit the safe mode when it is started. Generally, HDFS will be forced to enter the safe mode sometimes in production, so as to maintain the server.
[root@CentOS ~]# hdfs dfsadmin -safemode get Safe mode is OFF [root@CentOS ~]# hdfs dfsadmin -safemode enter Safe mode is ON [root@CentOS ~]# hdfs dfs -put hadoop-2.9.2.tar.gz / put: Cannot create file/hadoop-2.9.2.tar.gz._COPYING_. Name node is in safe mode. [root@CentOS ~]# hdfs dfsadmin -safemode leave Safe mode is OFF [root@CentOS ~]# hdfs dfs -put hadoop-2.9.2.tar.gz /
SSH password free authentication
SSH is a security protocol based on the application layer. SSH is more reliable and designed for Remote login A protocol that provides security for sessions and other network services. Using SSH protocol can effectively prevent information disclosure in the process of remote management. There are two login methods provided:
- Password based security authentication - it is possible for the remote host to impersonate the target host and intercept user information.
- Security verification of key - what needs to be authenticated is the identity of the machine
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-5dlonvyx-1628160864373) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210303165034628. PNG)]( https://img-blog.csdnimg.cn/2237283e1aad45549dcfc9b9bfacacbf.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
① To generate public-private key pairs, RSA or DSA algorithm can be selected
[root@CentOS ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:qWX5zumy1JS1f1uxPb3Gr+5e8F0REVueJew/WYrlxwc root@CentOS The key's randomart image is: +---[RSA 2048]----+ | ..+=| | .o*| | .. +.| | o o .E o| | S o .+.*+| | + + ..o=%| | . . o o+@| | ..o . ==| | .+= +*+o| +----[SHA256]-----+
By default, it will be in ~ / ID generated in ssh directory_ RSA (private key) and id_rsa.pub (public key)
② Add the local public key to the credit list file of the target host
[root@CentOS ~]# ssh-copy-id root@CentOS /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'centos (192.168.73.130)' can't be established. ECDSA key fingerprint is SHA256:WnqQLGCjyJjgb9IMEUUhz1RLkpxvZJxzEZjtol7iLac. ECDSA key fingerprint is MD5:45:05:12:4c:d6:1b:0c:1a:fc:58:00:ec:12:7e:c1:3d. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@centos's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'root@CentOS'" and check to make sure that only the key(s) you wanted were added.
By default, the local public key will be added to the ~ /. Of the remote target host ssh/authorized_keys file.
Trash recycle bin
In order to avoid data deletion loss due to user misoperation, HDFS users can configure the garbage collection function of HDFS when building HDFS. The so-called garbage collection essentially means that when a user deletes a file, the system will not delete the file immediately, but just move the file to the garbage collection directory. Then, the system will delete the file after a more configured time. Users need to remove the files in the recycle bin from the garbage bin before expiration to avoid deletion.
- To enable garbage collection, you need to go to the core site Add the following configuration to the XML, and then restart hdfs
<!--garbage collection,5 minites--> <property> <name>fs.trash.interval</name> <value>5</value> </property>
[root@CentOS hadoop-2.9.2]# hdfs dfs -rm -r -f /jdk-8u191-linux-x64.rpm 20/09/25 20:09:24 INFO fs.TrashPolicyDefault: Moved: 'hdfs://CentOS:9000/jdk-8u191-linux-x64.rpm' to trash at: hdfs://CentOS:9000/user/root/.Trash/Current/jdk-8u191-linux-x64.rpm
directory structure
[root@CentOS ~]# tree -L 1 /usr/hadoop-2.9.2/ /usr/hadoop-2.9.2/ ├── bin # System script, hdfs, hadoop, yarn ├── etc # Configuration directory xml, text file ├── include # Some C header files need no attention ├── lib # Third party native C implementation ├── libexec # When hadoop runs, load the configured script ├── LICENSE.txt ├── logs # System operation log directory, troubleshooting! ├── NOTICE.txt ├── README.txt ├── sbin # User script, usually used to start a service, for example: start|stop DFS sh, └── share # hadoop operation depends on jars and embedded webapp
HDFS practice
HDFS Shell command (frequently used)
√ print hadoop class path
[root@CentOS ~]# hdfs classpath
√ format NameNode
[root@CentOS ~]# hdfs namenode -format
dfsadmin command
① You can use - report -live or - dead to view the status of dataNode nodes in the cluster
[root@CentOS ~]# hdfs dfsadmin -report -live
② Use - safemode enter|leave|get and other operation security modes
[root@CentOS ~]# hdfs dfsadmin -safemode get Safe mode is OFF
③ View cluster network topology
[root@CentOS ~]# hdfs dfsadmin -printTopology Rack: /default-rack 192.168.73.130:50010 (CentOS)
For more information, please refer to: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#dfsadmin
Check the status of a directory
[root@CentOS ~]# hdfs fsck /
√ DFS command
[root@CentOS ~]# hdfs dfs - command options Or the old version [root@CentOS ~]# hadoop fs - command options
-appendToFile
Anaconda KS CFG added to AA Log
[root@CentOS ~]# hdfs dfs -appendToFile /root/anaconda-ks.cfg /aa.log [root@CentOS ~]# hdfs dfs -appendToFile /root/anaconda-ks.cfg /aa.log
-cat
view file contents
[root@CentOS ~]# hdfs dfs -cat /aa.log equivalence [root@CentOS ~]# hdfs dfs -cat hdfs://CentOS:9000/aa.log
-chmod
Modify file permissions
[root@CentOS ~]# hdfs dfs -chmod -R u+x /aa.log [root@CentOS ~]# hdfs dfs -chmod -R o+x /aa.log [root@CentOS ~]# hdfs dfs -chmod -R a+x /aa.log [root@CentOS ~]# hdfs dfs -chmod -R a-x /aa.log
-copyFromLocal/-copyToLocal
copyFromLocal is uploaded locally to HDFS;copyToLocal downloads files from HDFS
[root@CentOS ~]# hdfs dfs -copyFromLocal jdk-8u191-linux-x64.rpm / [root@CentOS ~]# rm -rf jdk-8u191-linux-x64.rpm [root@CentOS ~]# hdfs dfs -copyToLocal /jdk-8u191-linux-x64.rpm /root/ [root@CentOS ~]# ls anaconda-ks.cfg hadoop-2.9.2.tar.gz jdk-8u191-linux-x64.rpm
-mvToLocal/mvFromLocal
mvToLocal downloads the file first, and then deletes the remote data; mvFromLocal: upload first, then delete local
[root@CentOS ~]# hdfs dfs -moveFromLocal jdk-8u191-linux-x64.rpm /dir1 [root@CentOS ~]# ls anaconda-ks.cfg hadoop-2.9.2.tar.gz [root@CentOS ~]# hdfs dfs -moveToLocal /dir1/jdk-8u191-linux-x64.rpm /root moveToLocal: Option '-moveToLocal' is not implemented yet.
-put/get
File upload / download
[root@CentOS ~]# hdfs dfs -get /dir1/jdk-8u191-linux-x64.rpm /root [root@CentOS ~]# ls anaconda-ks.cfg hadoop-2.9.2.tar.gz jdk-8u191-linux-x64.rpm [root@CentOS ~]# hdfs dfs -put hadoop-2.9.2.tar.gz /dir1
For more commands, use
[root@CentOS ~]# hdfs dfs -help command
For example, I want to know how to use touchz
[root@CentOS ~]# hdfs dfs -touchz /dir1/Helloworld.java [root@CentOS ~]# hdfs dfs -ls /dir1/ Found 5 items -rw-r--r-- 1 root supergroup 0 2020-09-25 23:47 /dir1/Helloworld.java drwxr-xr-x - root supergroup 0 2020-09-25 23:07 /dir1/d1 drwxr-xr-x - root supergroup 0 2020-09-25 23:09 /dir1/d2 -rw-r--r-- 1 root supergroup 366447449 2020-09-25 23:43 /dir1/hadoop-2.9.2.tar.gz -rw-r--r-- 1 root supergroup 176154027 2020-09-25 23:41 /dir1/jdk-8u191-linux-x64.rpm
Java API operation HDFS (understand)
① Set up the development steps, create a Maven project (without selecting any template), and add the following dependencies in the pom.xml file
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
② Configure windows development environment (very important)
- Hadoop-2.9.0 needs to be 2. Unzip it in the specified directory of window. For example, here we unzip it in the C: / directory
- Add Hadoop to the environment variable of Windows system_ Home environment variable
- Add Hadoop window master All files in the bin directory in zip are copied to% Hadoop_ Overwrite in the home% / bin directory
- Restart IDEA, otherwise the integrated development environment does not recognize the configuration HADOOP_HOME environment variable
③ It is recommended that the core site XML and HDFS site Copy the XML file to the resources directory of the project
④ Configure the mapping relationship between host name and IP on Windows (omitted)
⑤ Create FileSystem and Configuration objects
public static FileSystem fs=null;
public static Configuration conf=null;
static {
try {
conf= new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
fs=FileSystem.get(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
File upload
Path src = new Path("file://xx path "");
Path dst = new Path("/");
fs.copyFromLocalFile(src,dst);
-
InputStream in=new FileInputStream("file://xx path "");
Path dst = new Path("/xx route");
OutputStream os=fs.create(dst);
IOUtils.copyBytes(in,os,1024,true);
File download
Path dst = new Path("file://xx path "");
Path src = new Path("/xx route");
fs.copyToLocalFile(src,dst);
-
Path dst = new Path("/xx route");
InputStream in= fs.open(dst);
OutputStream os=new FileOutputStream("file://xx path "");
IOUtils.copyBytes(in,os,1024,true);
Delete file
Path dst = new Path("/system");
fs.delete(dst,true);
recycle bin
Path dst = new Path("/aa.log");
Trash trash=new Trash(fs,conf);
trash.moveToTrash(dst);
All documents
Path dst = new Path("/");
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(dst, true);
while (listFiles.hasNext()){
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath()+" "+fileStatus.isDirectory()+" "+fileStatus.getLen());
}
All files or folders
Path dst = new Path("/");
FileStatus[] fileStatuses = fs.listStatus(dst);
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath()+" "+fileStatus.isDirectory());
}
MapReduce
summary
MapReduce is a Hadoop parallel computing framework, which draws lessons from the idea of functional programming and vector programming. Hadoop makes full use of the computing resources of the host where the storage node / Data Node runs (CPU, memory, network and a few disks) to complete the parallel computing of tasks. The Map Reduce framework will start a computing Resource Manager Node Manager on the physical host where all datanodes are located to manage local computing resources. By default, the system will divide the computing resources into 8 equal parts, and each equal part will be abstracted into a Container, which is mainly used as resource isolation Find some other hosts and start a resource management center Resource Manager to manage the computing resources of the cluster.
Process analysis
When a user submits a computing task to the MapReduce framework, The framework will split the task into Map phase and Reduce phase (the vector programming idea will split the task into two phases). The framework will start a task manager (each task has its own task manager) - MRAppMaster at the beginning of task submission according to the task parallelism of Map/Reduce phase (1 computing resource will be wasted in this process) it is used to manage the execution of tasks in Map phase and Reduce phase. During task execution, computing resources will be allocated in each phase according to the parallelism of phase tasks (each computing resource starts a Yan child), and MRAppMaster will complete the detection and management of phase tasks.

ResourceManager: be responsible for the unified scheduling of task resources, manage NodeManager resources, and start MRAppMaster
NodeManager: used to manage the computing resources on the local machine. By default, the computing resources on the local machine will be divided into 8 equal parts, and each equal part will be abstracted into a Container
MRAppMaster: for any task to be executed, there will be an MRAppMaster responsible for the execution and monitoring of YarnChild tasks.
YarnChild: it refers to the MapTask or ReduceTask executed specifically.
During task execution, the system will start mrappmaster and YarnChild to be responsible for task execution. Once task execution is completed, mrappmaster and YarnChild will exit automatically.
Environment construction
① Configure Explorer
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<!--to configure MapReduce Core implementation of computing framework Shuffle-shuffle the cards-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Configure the target host where the resource manager is located-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS2</value>
</property>
<!--Turn off physical memory check-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--Turn off virtual memory check-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
② Configure MapReduce computing framework
[root@CentOS ~]# mv /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml [root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<!--MapRedcue Implementation of framework resource manager-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
③ Start computing service
[root@CentOS ~]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-CentOS.out CentOS: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-CentOS.out [root@CentOS ~]# jps 13078 SecondaryNameNode 12824 DataNode 1080 ResourceManager 12681 NameNode 1195 NodeManager 1262 Jps
④ You can access the ResourceManager embedded WebUI page: http://CentOS2:8088

MapReduce task development
background
Suppose we have the following table. We need to count the number of clicks on each section.
| log level | category | Click date |
|---|---|---|
| INFO | /product/xxxx1 | 2020-09-28 10:10:00 |
| INFO | /product/xxxx2 | 2020-09-28 12:10:00 |
| INFO | /cart/xxxx2 | 2020-09-28 12:10:00 |
| INFO | /order/xxxx | 2020-09-28 12:10:00 |
If we can treat the above logs as a table in the database, we can use the following SQL to solve this problem:
select category,sum(1) from t_click group by category
If we use the MapReduce calculation model mentioned above, we can use Map to complete the function of group and Reduce to complete the function of sum. There are the following data formats
INFO /product/xxx/1?name=zhangsan 2020-09-28 10:10:00 INFO /product/xxx/1?name=zhangsan 2020-09-28 10:10:00 INFO /cart/xxx/1?name=lisi 2020-09-28 10:10:00 INFO /order/xxx/1?name=zhangsan 2020-09-28 10:10:00 INFO /product/xxx/1?name=zhaoliu 2020-09-28 10:10:00 INFO /cart/xxx/1?name=win7 2020-09-28 10:10:00
realization
① Write Mapper logic
package com.baizhi.click;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 1,Users must first understand the data format, storage location - data reading method - Mapper writing method?
* TextInputFormat<LongWritable,Text> : Read file system, local system, HDFS
* Byte offset text line
* 2,You have to know what you want? Press__ Category__ Statistics__ Number of hits__ value
* key value
*/
public class URLMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String url=line.split(" ")[1];
//Get category
int endIndex=url.indexOf("/",1);
String category=url.substring(0,endIndex);
//Output the result of conversion
context.write(new Text(category),new IntWritable(1));
}
}
② Reducer logic
package com.baizhi.click;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* 1,Which Mapper output results do you want to summarize? Determine the Key and Value types entered by the Reducer
*
* 2,You need to know the format in which the final output result is written out. When outputting the Key/Value format, the user only needs to pay attention to his toString
*
* TextOutputFormat<key,value> Write the results to the file system: local, HDFS
*/
public class URLReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
③ Encapsulating Job objects
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
Job job= Job.getInstance(conf,"URLCountApplication");
//2. Tell the job the data format
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
TextInputFormat.addInputPath(job,new Path("/demo/click"));
//The system creates it automatically. If it exists before execution, the execution will be abandoned
TextOutputFormat.setOutputPath(job,new Path("/demo/result"));
//4. Set processing logic
job.setMapperClass(URLMapper.class);
job.setReducerClass(URLReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
Task release
Remote deployment
- You need to add the following code to the job
job.setJarByClass(URLCountApplication.class);
Set the class loading path of the program, because the task is submitted using hadoop jar command after the jar package is completed
[root@CentOS ~]# yarn jar MapReduce-1.0-SNAPSHOT.jar com.baizhi.click.URLCountApplication perhaps [root@CentOS ~]# hadoop jar MapReduce-1.0-SNAPSHOT.jar com.baizhi.click.URLCountApplication
tips: if you feel that this packaging and submission is complicated, we can use the ssh Remote Login plug-in provided by maven to log in to the system first and then automatically perform the subsequent submission tasks.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>MapReduce</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.10</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<executions>
<execution>
<id>upload-deploy</id>
<!-- function package Run while packaging upload-single and sshexec -->
<phase>package</phase>
<goals>
<goal>upload-single</goal>
<goal>sshexec</goal>
</goals>
<configuration>
<!-- Files to deploy -->
<fromFile>target/${project.artifactId}-${project.version}.jar</fromFile>
<!-- Deployment Directory User: password@ip+Deployment address: Port -->
<url>
<![CDATA[ scp://root:123456@CentOS/root/ ]]>
</url>
<!--shell Execute script -->
<commands>
<command> hadoop fs -rm -r -f /demo/result </command>
<command> hadoop jar MapReduce-1.0-SNAPSHOT.jar com.baizhi.click.URLCountApplication </command>
</commands>
<displayCommandOutputs>true</displayCommandOutputs>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Local simulation
Without any yarn environment, it can be realized directly by local simulation You generally need to change the NativeIO source code. Because we can't download 2.9 2 source package, you can try to use 2.6 0 instead, modify 557 lines of the source code as follows:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
}
Add log4j. In the resource directory proeprties
log4j.rootLogger=INFO,CONSOLE
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss,SSS} %C -%m%n
Cross platform submission
① Core|hdfs|yarn|mapred-site Copy the XML to the resources directory of the project
② At mapred site XML add the following configuration
<!--Open cross platform-->
<property>
<name>mapreduce.app-submission.cross-platform </name>
<value>true</value>
</property>
③ Modify job code
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("yarn-site.xml");
conf.addResource("mapred-site.xml");
conf.set("mapreduce.job.jar","file:///xxx.jar");
InputForamt&OutputFormat
Overall design
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-yyplpnjf-1628160864381) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210804115918216. PNG)]( https://img-blog.csdnimg.cn/dc1d87f1fba84b88810d7e7704714d8c.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
InputFormat
This class is the top-level abstract class provided by Hadoop. It mainly customizes slice calculation logic and slice data reading logic.
public abstract class InputFormat<K, V> {
public InputFormat() {
}
//Calculate slice / data split logical interval
public abstract List<InputSplit> getSplits(JobContext var1)
throws IOException, InterruptedException;
//Realize the reading logic of the logical interval and pass the read data to Mapper
public abstract RecordReader<K, V> createRecordReader(InputSplit var1,
TaskAttemptContext var2)
throws IOException, InterruptedException;
}
The implementation package of Hadoop provides the pre implementation of InputFormat interface, mainly including:
- CompositeInputFormat - mainly realizes the join of large-scale data sets on the Map side
- DBInputFormat - mainly provides the reading implementation for RDBMS databases, mainly for Oracle and MySQL databases.
- FileInputFormat - pre implementation for distributed file systems.
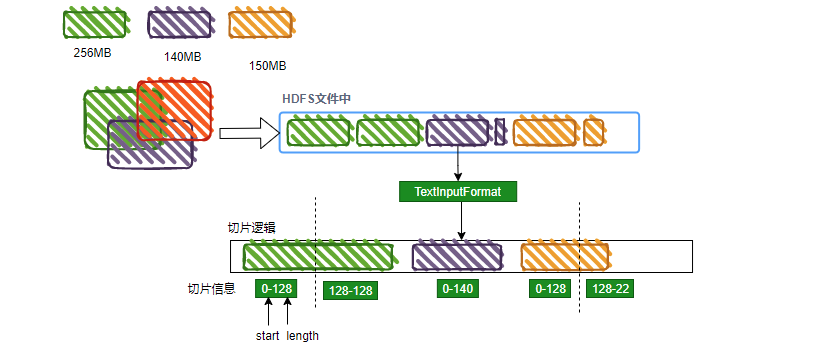
TextInputFormat
By default, the file is cut in 128MB. The cut interval is called a Split, and then the interval data is read by using the LineRecordReader. The LineRecordReader will provide Mapper with each line of text data as value, and provide the byte offset of the value in the text line. The offset is a Long type parameter, which usually has no effect.
Note: for all subclasses of the default FileInputFormat, when the getSplits method is not overridden, the default calculated slice size range (0140.8MB] because the underlying layer passes when calculating the file slice (file size / 128MB > 1.1)? Slice new blocks: do not slice
Refer to the above case for the code.
NLineInputFormat
By default, the file is cut according to N lines. The cut interval is called a Split, and then the interval data is read by using the LineRecordReader. The LineRecordReader will provide Mapper with each line of text data as value, and provide the byte offset of the value in the text line. The offset is a Long type parameter, which usually has no effect.
It overrides getSplits of FileInputFormat, so we generally need to set the number of rows when using NLineInputFormat.
NLineInputFormat.setNumLinesPerSplit(job,1000);
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
Job job= Job.getInstance(conf,"URLCountApplication");
//2. Tell the job the data format
job.setInputFormatClass(NLineInputFormat.class);
NLineInputFormat.setNumLinesPerSplit(job,1000);
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
TextInputFormat.addInputPath(job,new Path("D:/data/click"));
//The system creates it automatically. If it exists before execution, the execution will be abandoned
TextOutputFormat.setOutputPath(job,new Path("D:/data/result"));
//4. Set processing logic
job.setMapperClass(URLMapper.class);
job.setReducerClass(URLReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
KeyValueTextInputFormat
By default, the file is cut in 128MB units. The cut interval is called a Split. Then, the KeyValueLineRecordReader is used to read the interval data. The KeyValueLineRecordReader will provide Mapper with key and value, both of which are Text types. By default, the input of this format is separated by tab. Key/Value. If it is not Split correctly, the whole line will be taken as key, Value is null
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,",");
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,",");
Job job= Job.getInstance(conf,"AvgCostAplication");
//2. Tell the job the data format
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
TextInputFormat.addInputPath(job,new Path("file:///D:/data/keyvalue"));
//The system creates it automatically. If it exists before execution, the execution will be abandoned
TextOutputFormat.setOutputPath(job,new Path("file:///D:/data/result"));
//4. Set processing logic
job.setMapperClass(AvgCostMapper.class);
job.setReducerClass(AvgCostReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
MultipleInputs
This is a composite input format, which is mainly applicable to the combination of multiple inputformats of different formats. It is required that the output format of the Map segment must be consistent.
public class SumCostApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,",");
Job job= Job.getInstance(conf,"SumCostCountApplication");
//2. Tell the job the data format
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
TextOutputFormat.setOutputPath(job,new Path("file:///D:/data/result"));
//4. Set processing logic
MultipleInputs.addInputPath(job,new Path("file:///D:/data/mul/keyvalue"), KeyValueTextInputFormat.class,KeyVlaueCostMapper.class);
MultipleInputs.addInputPath(job,new Path("file:///D:/data/mul/text"), TextInputFormat.class,TextCostMapper.class);
job.setReducerClass(CostSumReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new SumCostApplication(),args);
}
}
CombineFileInputFormat
All fileinputformats mentioned above calculate file slices in file units, which means that if there are many small files in the calculated directory, there will be too many Map tasks in the first stage. Therefore, the default FileInputFormat is not very friendly to small file processing. Therefore, Hadoop provides a CombineFileInputFormat format format class, which is specially used for slice calculation in small file scenarios, and multiple small files will correspond to the same slice. However, the format of these small files must be consistent. We can use CombineTextInputFormat. The usage of this class is the same as TextInputFormat, except for the calculation of slices.
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
Job job= Job.getInstance(conf,"URLCountApplication");
//2. Tell the job the data format
job.setInputFormatClass(CombineTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
CombineTextInputFormat.addInputPath(job,new Path("file:///D:/data/click"));
//The system creates it automatically. If it exists before execution, the execution will be abandoned
TextOutputFormat.setOutputPath(job,new Path("file:///D:/data/result"));
//4. Set processing logic
job.setMapperClass(URLMapper.class);
job.setReducerClass(URLReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
DBInputFormat
It is mainly responsible for reading the data in RDBMS. At present, it only supports MySQL/Oracle databases
public class UserDBWritable implements DBWritable {
private Boolean sex;
private Double salary;
/**
* DBOutputFormat Used
* @param statement
* @throws SQLException
*/
public void write(PreparedStatement statement) throws SQLException {
}
public void readFields(ResultSet resultSet) throws SQLException {
this.sex=resultSet.getBoolean("sex");
this.salary=resultSet.getDouble("salary");
}
public Boolean getSex() {
return sex;
}
public void setSex(Boolean sex) {
this.sex = sex;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
}
public class DBAvgSalaryApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
//Set parallelism
conf.setInt(MRJobConfig.NUM_MAPS,5);
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/test","root","123456");
Job job= Job.getInstance(conf,"DBAvgSalaryApplication");
//2. Tell the job the data format
job.setInputFormatClass(DBInputFormat.class);
String query="select sex,salary from t_user";
String countQuery="select count(*) from t_user";
DBInputFormat.setInput(job,UserDBWritable.class,query,countQuery);
job.setOutputFormatClass(TextOutputFormat.class);
//3. Set data path
//The system creates it automatically. If it exists before execution, the execution will be abandoned
TextOutputFormat.setOutputPath(job,new Path("D:/data/result"));
//4. Set processing logic
job.setMapperClass(UserAvgMapper.class);
job.setReducerClass(UserAvgReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(BooleanWritable.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new DBAvgSalaryApplication(),args);
}
}
OutputFormat
This class is the top-level abstract class provided by Hadoop. It mainly implements the write logic, which is responsible for writing the output of the Reduce end to the peripheral system. At the same time, it also provides output check (only limited to the file system), and is responsible for returning to the committee to ensure that the system can output normally.
public abstract class OutputFormat<K, V> {
//Create RecordWriter
public abstract RecordWriter<K, V>
getRecordWriter(TaskAttemptContext context
) throws IOException, InterruptedException;
//Check whether the output directory is valid
public abstract void checkOutputSpecs(JobContext context
) throws IOException,
InterruptedException;
//Returns a submitter
public abstract
OutputCommitter getOutputCommitter(TaskAttemptContext context
) throws IOException, InterruptedException;
}
TextoutputFormat
Write the output of the Reducer directly to the file system, where the toString methods of key and value will be called when writing.
DBOutputFormat
Write the output of the Reducer directly to the database system.
public class URLCountDBWritable implements DBWritable {
private String category;
private Integer count;
public URLCountDBWritable(String category, Integer count) {
this.category = category;
this.count = count;
}
public URLCountDBWritable() {
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,category);
statement.setInt(2,count);
}
public void readFields(ResultSet resultSet) throws SQLException {
}
}
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
DBConfiguration.configureDB(conf,"com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/test",
"root","123456");
Job job= Job.getInstance(conf,"URLCountApplication");
//2. Tell the job the data format
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(DBOutputFormat.class);
//3. Set data path
TextInputFormat.addInputPath(job,new Path("file:///D:/data/click"));
DBOutputFormat.setOutput(job,"url_click","url_category","url_count");
//4. Set processing logic
job.setMapperClass(URLMapper.class);
job.setReducerClass(URLReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(URLCountDBWritable.class);
job.setOutputValueClass(NullWritable.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
JedisOutputFormat
public class JedisOutputFormat extends OutputFormat<String,String> {
public final static String JEDIS_HOST="jedis.host";
public final static String JEDIS_PORT="jedis.port";
public static void setOutput(Job job, String host, Integer port) {
job.getConfiguration().set(JEDIS_HOST,host);
job.getConfiguration().setInt(JEDIS_PORT,port);
}
public RecordWriter<String, String> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
Configuration config = context.getConfiguration();
String host=config.get(JEDIS_HOST);
Integer port=config.getInt(JEDIS_PORT,6379);
return new JedisRecordWriter(host,port);
}
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {}
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
return new FileOutputCommitter(FileOutputFormat.getOutputPath(context),
context);
}
}
public class JedisRecordWriter extends RecordWriter<String,String> {
private Jedis jedis=null;
public JedisRecordWriter(String host, Integer port) {
jedis=new Jedis(host,port);
}
public void write(String key, String value) throws IOException, InterruptedException {
jedis.set(key,value);
}
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
jedis.close();
}
}
public class URLCountApplication extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1. Create a Job object
Configuration conf = getConf();
Job job= Job.getInstance(conf,"URLCountApplication");
//2. Tell the job the data format
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(JedisOutputFormat.class);
//3. Set data path
TextInputFormat.addInputPath(job,new Path("file:///D:/data/click"));
JedisOutputFormat.setOutput(job,"CentOS",6379);
//4. Set processing logic
job.setMapperClass(URLMapper.class);
job.setReducerClass(URLReducer.class);
//5. Set the output key and value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(String.class);
job.setOutputValueClass(String.class);
//6. Submit job
return job.waitForCompletion(true)?1:0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new URLCountApplication(),args);
}
}
Dependency resolution
- Runtime dependency (Yan child dependency)
Option 1
Users are required to copy the dependent jar packages to all computing nodes (the host where NodeManager runs)
[root@CentOS ~]# hadoop jar xxx.jar entry class - libjars depends on jar package 1, jar package 2
Option 2
[root@CentOS ~]# hdfs dfs -mkdir /libs [root@CentOS ~]# hdfs dfs -put mysql-connector-java-5.1.46.jar /libs
conf.setStrings("tmpjars","/libs/xxx1.jar,/libs/xxx2.jar,...");
- Dependency on submission (client)
You need to configure HADOOP_CLASSPATH environment variable (/ root/.bashrc). Usually, this dependency occurs in the slice calculation phase.
HADOOP_CLASSPATH=/root/mysql-connector-java-5.1.46.jar export HADOOP_CLASSPATH [root@CentOS ~]# source .bashrc [root@CentOS ~]# hadoop classpath #View the class path of hadoop /usr/hadoop-2.6.0/etc/hadoop:/usr/hadoop-2.6.0/share/hadoop/common/lib/*:/usr/hadoop-2.6.0/share/hadoop/common/*:/usr/hadoop-2.6.0/share/hadoop/hdfs:/usr/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/usr/hadoop-2.6.0/share/hadoop/hdfs/*:/usr/hadoop-2.6.0/share/hadoop/yarn/lib/*:/usr/hadoop-2.6.0/share/hadoop/yarn/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/*:`/root/mysql-connector-java-5.1.46.jar`:/usr/hadoop-2.6.0/contrib/capacity-scheduler/*.jar
InputFormat/OuputFormat and Mapper and Reducer
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-xkrrjkce-1628160864385) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210804172611934. PNG)]( https://img-blog.csdnimg.cn/3e598436154c4b3e989069ad0e37caad.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
MapReduce Shuffle
definition
In MapReduce, how to transfer the data processed in the mapper phase to the reducer phase is the most critical process in the MapReduce framework. This process is called shuffle. Generally speaking, the core process of shuffle mainly includes the following aspects: data partitioning, sorting, local aggregation / Combiner, buffer, overflow, Fetch / Fetch, merge sorting, etc.
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-2fkjxkgi-1628160864387) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210308171221736. PNG)]( https://img-blog.csdnimg.cn/1e6868f1d7504339a636edde45cbc12f.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
common problem
1. Can MapReduce implement global sorting?
By default, MapReduce cannot achieve global ordering, because the underlying MapReduce uses the HashPartitioner implementation, which can only ensure that the data in the data partition is arranged in the natural order of key s, so it cannot achieve global ordering. However, the following ideas can be used to complete global sorting:
- Set the number of numeducetask to 1, which will cause all data to fall into the same partition to realize full sorting, but it is only applicable to small batch data sets
- The user-defined partition strategy allows the data to be partitioned according to the interval, not according to the hash strategy. At this time, only the order between the intervals can be ensured to achieve global order. However, this method will lead to uneven distribution of interval data, resulting in data skew in the calculation process.
- Use the TotalOrderPartitioner provided by Hadoop to sample the target first, and then calculate the partition interval.
reference resources: https://blog.csdn.net/lalaguozhe/article/details/9211919
2. How to interfere with MapReduce's partition policy?
Generally speaking, in the actual development, the partition strategy is rarely intervened, because based on big data, the first thing to consider is the uniform distribution of data to prevent data skew. Therefore, Hash is often the best choice. If you need to overwrite the original partition, you can call:
job.setPartitionerClass(Partition class information can be implemented)
public class CustomHashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
3. How to solve the problem of data skew in MapReduce calculation (interview hot issue)?
Scenario: count the population of Asian countries, taking China and Japan as examples. Naturally, the state will be used as the key and the citizen information as the value. During MapReduce calculation, Chinese citizens will naturally fall into a partition because their nationality is China. In this way, the data is heavily skewed.
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-sa3hgtun-1628160864401) (C: \ users \ administrator \ appdata \ roaming \ typora \ typora user images \ image-20210308171703780. PNG)]( https://img-blog.csdnimg.cn/86355fa86b724058a5f664b6b666e07d.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
4. What determines the parallelism of Map and Reduce?
The parallelism of the Map side is determined by computing task slices, and the Reduce side is determined by job setNumReduceTask(n)
5. MapReduce tuning strategy
1) Avoid small file calculation. After offline merging into large files, conduct MapReduce analysis or CombineTextInputFormat.
2) Adjust the parameters of the ring buffer to reduce the IO operation of the Map task, which can not be increased without limit, and also consider the system GC problem.
3) Turn on Map Compression and compress the overflow file into GZIP format to reduce the network bandwidth occupation in the ReduceShuffle process at the cost of CPU consumption
//To enable decompression, you must run in a real environment
conf.setBoolean("mapreduce.map.output.compress",true);
conf.setClass("mapreduce.map.output.compress.codec", GzipCodec.class, CompressionCodec.class);
4) If conditions permit, we can turn on the Map side preprocessing mechanism to execute Reduce logic on the Map side in advance for local calculation, which can greatly improve the computing performance, but this optimization method is not suitable for all scenarios. For example, if the average value is calculated, this scenario is not suitable for implementing Reduce logic on the Map side.
1) The input and output types of Combiner/Reduce must be consistent, that is, the precomputing logic cannot change the Map side output type / Reduce side input type.
2) The original business logic, such as averaging, cannot be changed. Although the types are compatible, the business calculation is incorrect.
! [[the external chain picture transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-C3R2ZHQl-1628160864402)(assets/image-20200930142652073.png)] [the external chain picture transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ebvFZep0-1628160864404)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210308173904104.png)](https://img-blog.csdnimg.cn/7291b1851ecd4951a11aa3eb5fdfaef5.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_16,color_FFFFFF,t_70)
Advantages: reduce the number of keys, save the memory space occupied by sorting, greatly reduce the amount of data download in ReduceShuffle and save bandwidth.
5) Adjust the number of resources managed by NodeManager appropriately
yarn.nodemanager.resource.memory-mb=32G yarn.nodemanager.resource.cpu-vcores = 16
Or turn on hardware resource monitoring
yarn.nodemanager.resource.detect-hardware-capabilities=true
6) If multiple small tasks are executed sequentially, we can consider using the JVM reuse mechanism. We can use one JVM to execute multiple tasks sequentially without restarting the new JVM.
mapreduce.job.jvm.numtasks=2
Hadoop HA build
summary
- NameNode HA build storage, ResourceManager HA build calculation
! [[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-vpvas1pe-1628160864405) (C: \ users \ administrator \ appdata \ roaming \ typora \ typera user images \ image-20210310102724193. PNG)]( https://img-blog.csdnimg.cn/5ec5f801befc4b7692ab817131ad53b4.png?x -oss-process=image/watermark,type_ ZmFuZ3poZW5naGVpdGk,shadow_ 10,text_ aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMDc0OTQ5,size_ 16,color_ FFFFFF,t_ 70)
preparation
- Install three CentOS-6.5 64 bit operating systems (complete JDK, SSH password free authentication, IP host name mapping, close firewall, etc.)
Host and service startup mapping table
| host | service |
|---|---|
| CentOSA | NameNode,zkfc,DataNode,JournalNode,Zookeeper,NodeManager |
| CentOSB | NameNode,zkfc,DataNode,JournalNode,Zookeeper,NodeManager,ResourceManager |
| CentOSC | DataNode,JournalNode,Zookeeper,NodeManager,ResourceManager |
Host information
| host name | IP information |
|---|---|
| CentOSA | 192.168.234.133 |
| CentOSB | 192.168.234.134 |
| CentOSC | 192.168.234.135 |
JDK installation and configuration
[root@CentOSX ~]# rpm -ivh jdk-8u171-linux-x64.rpm [root@CentOSX ~]# vi .bashrc JAVA_HOME=/usr/java/latest PATH=$PATH:$JAVA_HOME/bin CLASSPATH=. export JAVA_HOME export CLASSPATH export PATH [root@CentOSX ~]# source .bashrc
IP host name mapping
[root@CentOSX ~]# vi /etc/hosts 192.168.234.133 CentOSA 192.168.234.134 CentOSB 192.168.234.135 CentOSC
Turn off firewall
[root@CentOSX ~]# systemctl stop firewalld [root@CentOSX ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. [root@CentOSX ~]# firewall-cmd --state not running
SSH password free authentication
[root@CentOSX ~]# ssh-keygen -t rsa [root@CentOSX ~]# ssh-copy-id CentOSA [root@CentOSX ~]# ssh-copy-id CentOSB [root@CentOSX ~]# ssh-copy-id CentOSC
Zookeeper
[root@CentOSX ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/ [root@CentOSX ~]# mkdir /root/zkdata [root@CentOSA ~]# echo 1 >> /root/zkdata/myid [root@CentOSB ~]# echo 2 >> /root/zkdata/myid [root@CentOSC ~]# echo 3 >> /root/zkdata/myid [root@CentOSX ~]# touch /usr/zookeeper-3.4.6/conf/zoo.cfg [root@CentOSX ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg tickTime=2000 dataDir=/root/zkdata clientPort=2181 initLimit=5 syncLimit=2 server.1=CentOSA:2887:3887 server.2=CentOSB:2887:3887 server.3=CentOSC:2887:3887 [root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg [root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status zoo.cfg JMX enabled by default Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: `follower|leader` [root@CentOSX ~]# jps 5879 `QuorumPeerMain` 7423 Jps
Build Hadoop cluster (HDFS)
Extract and configure HADOOP_HOME
[root@CentOSX ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr/ [root@CentOSX ~]# vi .bashrc HADOOP_HOME=/usr/hadoop-2.9.2 JAVA_HOME=/usr/java/latest PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin CLASSPATH=. export JAVA_HOME export CLASSPATH export PATH export HADOOP_HOME [root@CentOSX ~]# source .bashrc
Configure core site xml vi /usr/hadoop-2.9. 2/etc/hadoop/core-site. xml
<!--to configure Namenode service ID-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>30</value>
</property>
<!--Configure rack scripts-->
<property>
<name>net.topology.script.file.name</name>
<value>/usr/hadoop-2.9.2/etc/hadoop/rack.sh</value>
</property>
<!--to configure ZK Service information-->
<property>
<name>ha.zookeeper.quorum</name>
<value>CentOSA:2181,CentOSB:2181,CentOSC:2181</value>
</property>
<!--to configure SSH Key location-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
Configure rack scripts
[root@CentOSX ~]# touch /usr/hadoop-2.9.2/etc/hadoop/rack.sh
[root@CentOSX ~]# chmod u+x /usr/hadoop-2.9.2/etc/hadoop/rack.sh
[root@CentOSX ~]# vi /usr/hadoop-2.9.2/etc/hadoop/rack.sh
while [ $# -gt 0 ] ; do
nodeArg=$1
exec</usr/hadoop-2.9.2/etc/hadoop/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result "
fi
done
[root@CentOSX ~]# touch /usr/hadoop-2.9.2/etc/hadoop/topology.data
[root@CentOSX ~]# vi /usr/hadoop-2.9.2/etc/hadoop/topology.data
192.168.234.133 /rack01
192.168.234.134 /rack01
192.168.234.135 /rack03
/usr/hadoop-2.9.2/etc/hadoop/rack.sh 192.168.234.133
Configure HDFS site xml vi /usr/hadoop-2.9. 2/etc/hadoop/hdfs-site. xml
<property> <name>dfs.replication</name> <value>3</value> </property> <!--Turn on automatic failover--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--explain core-site.xml content--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>CentOSA:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>CentOSB:9000</value> </property> <!--Configure log server information--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://CentOSA:8485;CentOSB:8485;CentOSC:8485/mycluster</value> </property> <!--Implementation class for failover--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
Configure slave VI / usr / hadoop-2.9 2/etc/hadoop/slaves
CentOSA CentOSB CentOSC
Because it is CentOS7, we need to install an additional plug-in. Otherwise, the NameNode cannot achieve automatic failover.
[root@CentOSX ~]# yum install -y psmisc
Start HDFS (cluster initialization)
[root@CentOSX ~]# hadoop-daemon.sh start journalnode (wait 10s) [root@CentOSA ~]# hdfs namenode -format [root@CentOSA ~]# hadoop-daemon.sh start namenode [root@CentOSB ~]# hdfs namenode -bootstrapStandby [root@CentOSB ~]# hadoop-daemon.sh start namenode #To register the Namenode information in zookeeper, you only need to execute the following instructions on either CentOSA or B [root@CentOSA|B ~]# hdfs zkfc -formatZK [root@CentOSA ~]# hadoop-daemon.sh start zkfc [root@CentOSB ~]# hadoop-daemon.sh start zkfc [root@CentOSX ~]# hadoop-daemon.sh start datanode
View rack information
[root@CentOSC ~]# hdfs dfsadmin -printTopology Rack: /rack01 192.168.73.131:50010 (CentOSA) 192.168.73.132:50010 (CentOSB) Rack: /rack03 192.168.73.133:50010 (CentOSC)
Resource Manager setup
yarn-site.xml vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>CentOSB</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>CentOSC</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>CentOSA:2181,CentOSB:2181,CentOSC:2181</value>
</property>
<!--Turn off physical memory check-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--Turn off virtual memory check-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
mapred-site.xml mv /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
vi /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
Start | close the Yan service
[root@CentOSB ~]# yarn-daemon.sh start|stop resourcemanager [root@CentOSC ~]# yarn-daemon.sh start|stop resourcemanager [root@CentOSX ~]# yarn-daemon.sh start|stop nodemanger