1, HDFS overview
1. HDFS generation background
- With the increasing amount of data, if there is not enough data in one operating system, it will be allocated to more operating systems
But it is not convenient for management and maintenance. There is an urgent need for a system to manage files on multiple machines
Distributed file management system. HDFS is just one kind of distributed file management system
2. HDFS definition
- HDFS (Hadoop Distributed File System) is a file system used to store files through the target
Record the tree to locate the file; Secondly, it is distributed, and many servers unite to realize its functions, the services in the cluster
Each has its own role. - Usage scenario of HDFS: it is suitable for the scenario of one write and multiple readouts. A file is created, written, and closed
Then you don't need to change.
3. HDFS benefits
-
1. High fault tolerance
The data is automatically saved in multiple copies. It improves fault tolerance by adding copies.

When a copy is lost, it can be recovered automatically.

-
2. Suitable for handling big data
Data scale: it can handle data with data scale of GB, TB or even PBFile size: it can handle a large number of files with a size of more than one million
-
3. It can be built on cheap machines and improve reliability through multi copy mechanism.
4. HDFS disadvantages
-
It is not suitable for low latency data access, such as millisecond data storage.
-
Unable to efficiently store a large number of small files.
If a large number of small files are stored, it will occupy a large amount of memory in the NameNode to store files and directories
Block information. This is not desirable because the memory of NameNode is always limited;
The addressing time of small file storage will exceed the reading time, which violates the design goal of HDFS. -
Concurrent writing and random file modification are not supported.
A file can only have one write, and multiple threads are not allowed to write at the same time;
Only data append is supported, and random modification of files is not supported
2, HDFS composition architecture
1. HDFS composition architecture
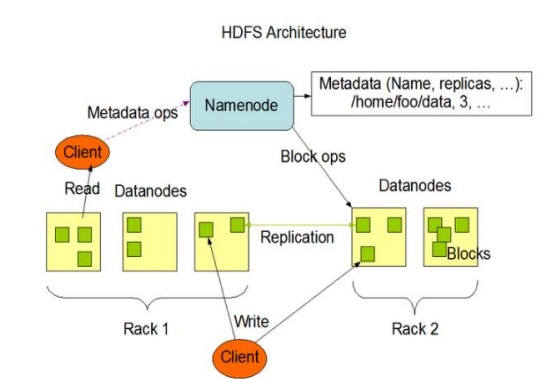
2,NameNode(nn)
NameNode (nn) is the Master, which is a supervisor and manager.
(1) Manage the namespace of HDFS;
(2) Configure replica policy;
(3) Managing Block mapping information;
(4) Handle client read and write requests.
3,DataNode
DataNode: Slave. The NameNode issues a command, and the DataNode performs the actual operation.
(1) Storing actual data blocks;
(2) Perform read / write operation of data block
4,Client
Client: the client
(1) File segmentation. When uploading files to HDFS, the Client divides the files into blocks one by one, and then uploads them;
(2) Interact with NameNode to obtain file location information;
(3) Interact with DataNode to read or write data;
(4) The Client provides some commands to manage HDFS, such as NameNode formatting;
(5) The Client can access HDFS through some commands, such as adding, deleting, checking and modifying HDFS;
5,Secondary NameNode
Secondary NameNode: not a hot standby of NameNode. When the NameNode hangs, it cannot immediately replace the NameNode and provide services.
(1) Assist NameNode to share its workload, such as regularly merging Fsimage and Edits and pushing them to NameNode;
(2) In case of emergency, the NameNode can be recovered.
3, HDFS file block size (interview focus)
1. HDFS file block size
Files in HDFS are physically stored in blocks, and the size of blocks can be determined by configuration parameters
(dfs.blocksize). The default size is Hadoop 2 x/3. 128M in X version, 1 64M in X version.
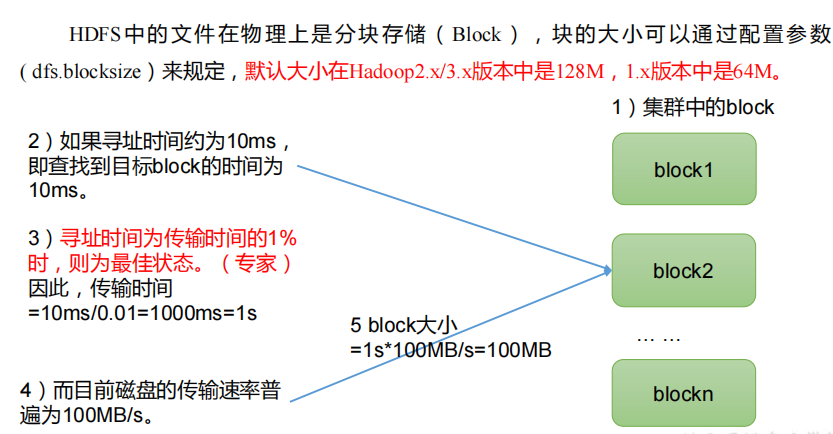
2. Why can't the block size be set too small or too large?
(1) The block setting of HDFS is too small, which will increase the addressing time, and the program has been looking for the starting position of the block;
(2) If the block is set too large, the time to transfer data from the disk will be significantly longer than the time to locate the block
Time required to start position. As a result, the program will be very slow in processing this data.
Summary: the size setting of HDFS block mainly depends on the disk transfer rate.
4, Shell operation of HDFS (development focus)
1. Basic grammar
hadoop fs specific command OR hdfs dfs specific command
The two are identical.
2. Complete command
hadoop fs
5, Common command upload and download
1. HDFS upload
1. Create a file
hadoop fs -mkdir /sanguo
2. HDFS upload (moveFromLocal)
-moveFromLocal: Cut and paste from local to HDFS [atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt Input: shuguo [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
3. Upload (copyFromLocal)
-copyFromLocal: Copy files from local file system to HDFS Path to [atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt Input: weiguo [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
4. Upload (put)
-put: Equivalent to copyFromLocal,More accustomed to production environment put [atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt Input: wuguo [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
5. Upload (appendToFile)
-appendToFile: Append a file to the end of an existing file [atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt Input: liubei [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2. HDFS Download
1. - copyToLocal: copy from HDFS to local
from HDFS above/sanguo/shuguo.txt Download to local current directory [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2. - get: equivalent to copyToLocal. The production environment is more used to get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
3. HDFS direct operation
1. Show directory (- ls)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo Found 3 items -rw-r--r-- 3 atguigu supergroup 14 2021-07-09 11:22 /sanguo/shuguo.txt -rw-r--r-- 3 atguigu supergroup 7 2021-07-09 11:19 /sanguo/weiguo.txt -rw-r--r-- 3 atguigu supergroup 7 2021-07-09 11:20 /sanguo/wuguo
2. View file (- cat)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt 2021-07-09 11:35:14,425 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false shuguo liubei
3. Modify permissions (chown)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4. Create path (- mkdir)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5. Copy from one path of HDFS to another path of HDFS (- cp)
-cp: from HDFS Copy a path to HDFS Another path to [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6. Move files (- mv) in HDFS directory
-mv: stay HDFS Move files in directory [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7. Displays data (- tail) at the end 1kb of a file
-tail: Show the end of a file 1 kb Data [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8. Delete file or folder (- rm)
-rm: Delete file or folder [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9. Recursively delete the directory and its contents (- rm -r)
-rm -r: Recursively delete the directory and its contents [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10. Statistics folder size information (- du)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo 27 81 /jinguo [atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo 14 42 /jinguo/shuguo.txt 7 21 /jinguo/weiguo.txt 6 18 /jinguo/wuguo.tx Note: 27 indicates the file size; 81 means 27*3 Copies;/jinguo Indicates the directory to view
11. Set the number of copies of files in HDFS (- setrep)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt

The number of replicas set here is only recorded in the metadata of the NameNode. Whether there will be so many replicas remains to be determined
Look at the number of datanodes. At present, there are only 3 devices, up to 3 replicas, and only the number of nodes increases to 10
The number of copies can reach 10.