VGG paper
<Very Deep Convolutional Networks for Large-Scale Image Recognition>
Thesis address: https://arxiv.org/abs/1409.1556
Network using duplicate elements (VGG)
This paper briefly describes the VGG16 network by learning the harvest of VGG and the reproduction of VGG16.
I Gain from learning VGG
- VGG network clearly points out and proves that the shallow and large convolution kernel is not as good as the deep and small convolution kernel.
Suppose that the input and output dimensions of convolution blocks a and b are the same (dimension = C may be set), in which convolution block a (1 convolution layer of 7 * 7) and convolution block b (composed of 3 convolution layers of 3 * 3).
Features: no matter whether h and w are changed or not, only shallow features (contour) can be obtained for convolution block a, while deep features (contour, ripple, lace, etc.) can be obtained for convolution block b. When h and w change, both convolution block a and convolution block b have the same receptive field.
Parameters: parameter PA of convolution block a = 7 * 7 * C ^ 2 = 49 * C ^ 2, parameter Pb of convolution block b = 3 * (3 * 3 * C ^ 2) = 3 * 9 * C ^ 2 = 27 * C ^ 2, obviously PA > Pb.
-
The scale n (h * w) of the picture determines the performance of VGG network. Multi-scale N training helps to improve the performance of VGG network.
The VGG network structure is shown below.
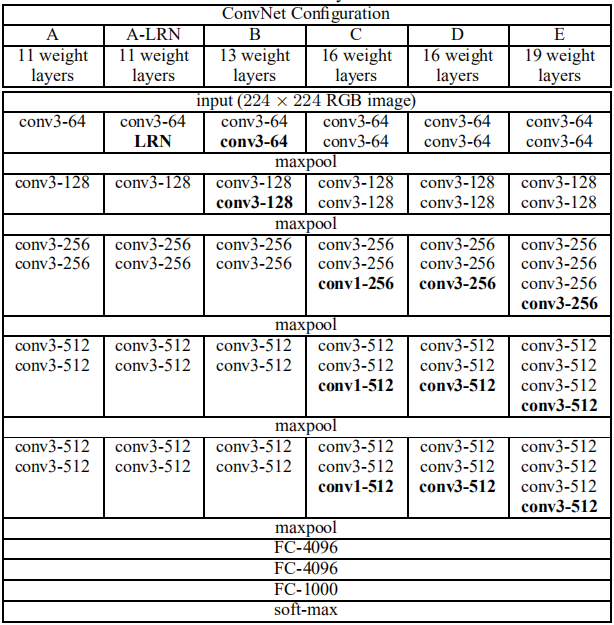
VGG16 network consists of five convolution blocks and one fully connected block. Each convolution block is followed by a 2 * 2 maximum pool layer with a step of 2. According to the size calculation formula after image convolution:
h
′
=
(
h
−
F
+
2
P
)
/
S
+
1
h' = (h-F+2P)/S+1
h′=(h−F+2P)/S+1
w
′
=
(
w
−
F
+
2
P
)
/
S
+
1
w' = (w-F+2P)/S+1
w′=(w−F+2P)/S+1
Where, the scale W(h, w) of the input picture, the size of the Filter (the size of the convolution kernel of the convolution layer or pooling layer) F * F, the step S, the filling P, and the scale N(h ', W') of the output picture.
The scale of the input picture of VGG16 network must be an integral multiple of 32. Since the convolution blocks constituting VGG16 are composed of several 3 * 3 convolution layers with step of 1 and filling of 1, the scale of the picture will not be changed. For the 2 * 2 maximum pooling layer with 2 steps after the convolution block, the scale of the picture is reduced to 1 / 2 of the original scale, and there are 5 2 * 2 maximum pooling layers with 2 steps. Therefore, the scale of the picture is reduced to (1 / 2) ^ 5 = 1 / 32 of the original scale.
It is advisable to set the scale of the input picture as N, and the use of multi-scale (N-32, N, N+32) can significantly improve the performance of VGG16 network.
II Reproduction of VGG16 network
- Data preprocessing
The VGG network adopts a very simple processing method. The mean value of the three RGB channels of the sample is subtracted from the three RGB channels respectively.
"""
path Is the prefix of the file path
folders For a dictionary (category) kind,list list),The picture name is stored in the list
"""
# Small number of samples
import cv2
import numpy as np
means = [0., 0., 0.]
stdevs = [0., 0., 0.]
img_list = []
for string in folders:
path_next = path + "\\" + string
for file in folders[string]:
file = path_next + "\\" + file
#The matrix read in by opencv is BGR
img = cv2.imread(file)
img = img[:, :, :, np.newaxis]
# print(img.shape)
# img.shape = (h, w, 3, 1)
img_list.append(img)
imgs = np.concatenate(img_list, axis=3)
# print(imgs.shape)
# imgs.shape = (h, w, 3, n)
imgs = imgs.astype(np.float32) / (255.)
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # Line up
# pixels.shape = (h*w*n, )
means[i] += np.mean(pixels)
stdevs[i] += np.std(pixels)
# BGR -- > RGB, CV reading needs conversion, PIL reading does not need conversion
# You can also think about it this way. opencv reads BGR and PIL reads RGB. If you cross use it, you need to use it.
means.reverse()
stdevs.reverse()
# The number of samples is too large
"""
When the number of samples is too large, the method of parameter estimation in probability theory and mathematical statistics is adopted.
For samples x1,x2,x3,...,xn,expect u1,u2,u3,...,un,variance v1^2,v2^2,v3^2,...,vn^2,All from the same sample X Obtained by random sampling.
Might as well set u1,u2,u3,...,un The mean value of is u,v1^2,v2^2,v3^2,...,vn^2 The mean value of is v.
NX = x1+x2+x3+...+xn
E(NX) = u1+u2+u3+...+un = n*u
D(NX) = v1^2+v2^2+v3^2+...+vn^2 = n*v^2
X = NX/n = (x1+x2+x3+...+xn)/n
E(X) = E(NX)/n = u
D(X) = D(NX)/(n*n) = v^2/n
sample X Our expectations are u,The standard deviation is v/sqrt(n).
"""
"""
import cv2
import random
import math
import numpy as np
means = [0., 0., 0.]
stdevs = [0., 0., 0.]
for epoch in range(1000):
img_list = []
for string in folders:
path_next = path + "\\" + string
for file in folders[string]:
random_num = np.random.uniform() # np. random. Uniform (0,1) samples are evenly distributed between 0-1
if random_num < 0.001:
file = path_next + "\\" + file
img = cv2.imread(file)
#The matrix read in by opencv is BGR
img = img[:, :, :, np.newaxis]
# print(img.shape)
# img.shape = (h, w, 3, 1)
img_list.append(img)
imgs = np.concatenate(img_list, axis=3)
#print(imgs.shape)
# imgs.shape = (h, w, 3, n)
imgs = imgs.astype(np.float32) / (255.)
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # Line up
# print(pixels.shape)
# pixels.shape = (h*w*n, )
means[i] += np.mean(pixels)
stdevs[i] += np.std(pixels)
#if (epoch+1)%100 == 0:
#print("normMean = {}".format(means))
#print("normStd = {}".format(stdevs))
# BGR -- > RGB, CV reading needs conversion, PIL reading does not need conversion
# You can also think about it this way. opencv reads BGR and PIL reads RGB. If you cross use it, you need to use it.
means.reverse()
stdevs.reverse()
use_means = [0., 0., 0.]
use_stdevs = [0., 0., 0.]
for i in range(3):
use_means[i] = means[i] / 1000
use_stdevs[i] = stdevs[i] / math.sqrt(1000)
print(use_means)
print(use_stdevs)
"""
- Parameter control
batch_size = 8 # Amount of data fed each time, batch_ The size can be adjusted according to the configuration of the computer lr = 0.01 # Learning rate step_size = 1 # The learning rate is updated every n epoch s, and the data set is too large, so it is reduced epoch_num = 50 # Total iterations num_print = 1120 # Print every n batch times, and the data set is too large, so increase it num_check = 1 # Verify the model every n epoch s. If the effect is better, save the model. The data set is too large, so it is reduced
- Data set construction
"""
train_path For a dictionary (category) kind,list list),The absolute path of the picture is stored in the list
"""
import torch
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import cv2
# Setting the size independently is conducive to the multi-scale training of VGG network
size = 224
# The mean and standard deviation are set according to the VGG paper, minus the sample mean, and the standard deviation is set to 1.
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5142455680072308, 0.4990353952050209, 0.5186490820050239), (1.0, 1.0, 1.0))
])
# -----------------ready the dataset--------------------------
def default_loader(path, img_size):
img = cv2.imread(path)
if img_size is not None:
img = cv2.resize(img,(img_size,img_size),interpolation=cv2.INTER_NEAREST)
return img
class MyDataset(Dataset):
# Constructor
def __init__(self, path, transform=None, target_transform=None, loader=default_loader, img_size = None):
imgs = []
for classification in path:
for i in range(len(path[classification])):
img_path = path[classification][i]
img_label = labels[classification]
imgs.append((img_path,int(img_label)))#imgs contains image paths and labels
self.path = path
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
self.img_size = img_size
# hash_map establishment
def __getitem__(self, index):
img_path, img_label = self.imgs[index]
# Call opencv to open the picture
img = self.loader(img_path,self.img_size)
if self.transform is not None:
img = self.transform(img)
img_label -= 1
return img, img_label
def __len__(self):
return len(self.imgs)
train_data = MyDataset(train_path, transform=transform, img_size=size)
verification_data = MyDataset(verification_path, transform=transform, img_size=size)
test_data = MyDataset(test_path, transform=transform, img_size=size)
#train_data ,verification_data and test_data contains many training, verification and test data. Call DataLoader to load in batch
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
verification_loader = DataLoader(dataset=verification_data, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
- VGG16 network construction
import torch from torch import optim import torchvision import matplotlib.pyplot as plt import numpy as np from torchvision.utils import make_grid import time
There are two ideas about multi-scale training.
Idea 1: use the model loading function model load_ state_ dict(torch.load(PATH), strict=False). When loading some model parameters for pre training, it is likely to encounter key mismatch (the model weights are saved and loaded back in the form of key value pairs). Therefore, whether there are missing keys or more keys, you can use the_ state_ Set the strict parameter to false in the dict() function to ignore mismatched keys. (not recommended)
Idea 2: referring to the convolution neural networks NiN, GoogLeNet, ResNet, DenseNet and other networks in hands-on deep learning, the full connection block of VGG16 network is magically modified, and the convolution block temp is used to replace the full connection block. The convolution block temp is composed of two 1 * 1 convolution layers and one global average pooling layer, and finally connected with two full connection layers (one of which is the full connection layer shaping the category).
Idea 1 code implementation
from torch import nn
from torchsummary import summary
class VGG16Net(nn.Module):
def __init__(self):
super(VGG16Net,self).__init__()
# First layer, 2 convolution layers and 1 maximum pool layer
self.layer1 = nn.Sequential(
# Input 3 channels, convolution kernel 3 * 3, output 64 channels (such as sample pictures of 224 * 224 * 3, (224 + 2 * 1-3) / 1 + 1 = 224, output 224 * 224 * 64)
nn.Conv2d(3,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 64 channels, convolution kernel 3 * 3, output 64 channels (input 224 * 224 * 64, convolution 3 * 3 * 64 * 64, output 224 * 224 * 64)
nn.Conv2d(64,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 224 * 224 * 64, output 112 * 112 * 64
nn.MaxPool2d(kernel_size=2,stride=2)
)
# Second layer, 2 convolution layers and 1 maximum pool layer
self.layer2 = nn.Sequential(
# Input 64 channels, convolution kernel 3 * 3, output 128 channels
nn.Conv2d(64,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 128 channels, convolution kernel 3 * 3, output 128 channels
nn.Conv2d(128,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 112 * 112 * 128, output 56 * 56 * 128
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The third layer, three convolution layers and one maximum pool layer
self.layer3 = nn.Sequential(
# Input 128 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(128,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
#Input 56 * 56 * 256, output 28 * 28 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The fourth layer, three convolution layers and one maximum pool layer
self.layer4 = nn.Sequential(
# 256 input channels, convolution kernel 3 * 3, 512 output channels
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#Input 28 * 28 * 512, output 14 * 14 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The fifth layer, three convolution layers and one maximum pool layer
self.layer5 = nn.Sequential(
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#Input 14 * 14 * 512, output 7 * 7 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# VGG16--13 convolution layers
self.conv_layer = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
# VGG16--3 full connection layers
self.fc = nn.Sequential(
"""
Multi scale training, representing 3 times of training
Set the first full connection layer as follows
A,nn.Linear(512 * 6 * 6, 4096)
B,nn.Linear(512 * 8 * 8, 4096)
C,nn.Linear(512 * 7 * 7, 4096)
ensure C Just for the last workout.
"""
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),# Randomly discard 50% of neurons
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),# Randomly discard 50% of neurons
"""
The first method
nn.Linear(4096, n)
shape = (-1, n),n Indicates the number of categories
The second method is as follows, in VGG16 Followed by a full connection layer
"""
nn.Linear(4096, 1000),
# Followed by a fully connected layer, shape = (-1, n), n indicates the number of categories
nn.Linear(1000, 29)
)
def forward(self,x):
x = self.conv_layer(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg_model=VGG16Net().to(device)
summary(vgg_model, (3,224,224)) #Print network structure
Idea 2 code implementation
from torch import nn
from torchsummary import summary
class VGG16Net(nn.Module):
def __init__(self):
super(VGG16Net,self).__init__()
# First layer, 2 convolution layers and 1 maximum pool layer
self.layer1 = nn.Sequential(
# Input 3 channels, convolution kernel 3 * 3, output 64 channels (such as sample pictures of 224 * 224 * 3, (224 + 2 * 1-3) / 1 + 1 = 224, output 224 * 224 * 64)
nn.Conv2d(3,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 64 channels, convolution kernel 3 * 3, output 64 channels (input 224 * 224 * 64, convolution 3 * 3 * 64 * 64, output 224 * 224 * 64)
nn.Conv2d(64,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Input 224 * 224 * 64, output 112 * 112 * 64
nn.MaxPool2d(kernel_size=2,stride=2)
)
# Second layer, 2 convolution layers and 1 maximum pool layer
self.layer2 = nn.Sequential(
# Input 64 channels, convolution kernel 3 * 3, output 128 channels
nn.Conv2d(64,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 128 channels, convolution kernel 3 * 3, output 128 channels
nn.Conv2d(128,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Input 112 * 112 * 128, output 56 * 56 * 128
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The third layer, three convolution layers and one maximum pool layer
self.layer3 = nn.Sequential(
# Input 128 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(128,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# Input 256 channels, convolution kernel 3 * 3, output 256 channels
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
#Input 56 * 56 * 256, output 28 * 28 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The fourth layer, three convolution layers and one maximum pool layer
self.layer4 = nn.Sequential(
# 256 input channels, convolution kernel 3 * 3, 512 output channels
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#Input 28 * 28 * 512, output 14 * 14 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# The fifth layer, three convolution layers and one maximum pool layer
self.layer5 = nn.Sequential(
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# Input 512 channels, convolution kernel 3 * 3, output 512 channels
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#Input 14 * 14 * 512, output 7 * 7 * 256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# Magic change VGG16 -- sixth floor
self.layer6 = nn.Sequential(
nn.Conv2d(512, 4096,1),
nn.BatchNorm2d(4096),
nn.ReLU(inplace=True),
nn.Conv2d(4096, 4096,1),
nn.BatchNorm2d(4096),
nn.ReLU(inplace=True)
)
# VGG16--15 convolution layers
self.conv_layer = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5,
self.layer6
)
# VGG16--1 full connection layer
self.fc = nn.Sequential(
nn.Linear(4096, 1000),
nn.ReLU(inplace=True),
nn.Dropout(0.5),# Randomly discard 50% of neurons
nn.Linear(1000, 29)
)
def forward(self,x):
x = self.conv_layer(x)
# Global average pooling layer
x = nn.functional.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg_model=VGG16Net().to(device)
summary(vgg_model, (3,224,224)) #Print network structure
- model training
# VGG16
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = VGG16Net().to(device)
# Adjusting parameters # Cross entropy criterion = nn.CrossEntropyLoss() # iterator optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.8, weight_decay=0.001) # Update learning rate schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5, last_epoch=-1)
# train
# Loss diagram
loss_list = []
start = time.time()
correct_optimal = 0.0
for epoch in range(epoch_num):
model.train()
running_loss = 0.0
for i, (inputs, labels) in enumerate(train_loader, 0):
# From train_ Take out 64 data from loader
inputs, labels = inputs.to(device), labels.to(device)
# Gradient clearing
optimizer.zero_grad()
# model training
outputs = model(inputs)
#print(outputs.shape)
# Back propagation
loss = criterion(outputs,labels).to(device)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i+1) % num_print == 0:
print('[%d epoch, %d] loss:%.6f' %(epoch+1, i+1, running_loss/num_print))
loss_list.append(running_loss/num_print)
running_loss = 0.0
# Print the learning rate and confirm whether the learning rate is updated
lr_1 = optimizer.param_groups[0]['lr']
print("learn_rate: %.15f"%lr_1)
schedule.step()
# Verification mode
if (epoch+1) % num_check == 0:
# No gradient update required
model.eval()
correct = 0.0
total = 0
with torch.no_grad():
print("=======================check=======================")
for inputs, labels in verification_loader:
# From train_ Take batch from loader_ Size data
inputs, labels = inputs.to(device), labels.to(device)
# Model validation
outputs = model(inputs)
pred = outputs.argmax(dim=1) #Returns the index of the maximum value in each row
total = total + inputs.size(0)
correct = correct + torch.eq(pred, labels).sum().item()
correct = 100 * correct/total
print("Accuracy of the network on the 19850 verification images:%.2f %%" %correct )
print("===================================================")
# Model saving
if correct > correct_optimal:
PATH = "VVG\\VGG16 model_" + str(epoch) + "_" + str(correct) + ".pth"
torch.save(model.state_dict(), 'VGG/VGG16_%03d-correct%.3f.pth' % (epoch + 1, correct))
correct_optimal = correct
end=time.time()
print("time:{}".format(end-start))
- Draw loss diagram
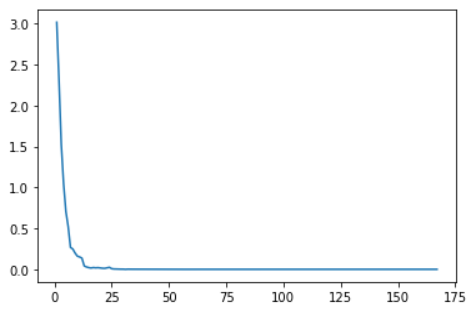
import matplotlib.pyplot as plt x = [ i+1 for i in range(len(loss_list)) ] # plot function drawing plt.plot(x, loss_list) # The show function shows the figure. If there is no line of code, the program completes the drawing, but it cannot be seen plt.show()
The loss figure is as follows, in which five units represent one epoch.
7. Model test
# Inspection mode, no gradient update required
model.eval()
correct = 0.0
total = 0
with torch.no_grad():
print("=======================check=======================")
for inputs, labels in test_loader:
# From train_ Take batch from loader_ Size data
inputs, labels = inputs.to(device), labels.to(device)
# Model test
outputs = model(inputs)
pred = outputs.argmax(dim=1) #Returns the index of the maximum value in each row
total = total + inputs.size(0)
correct = correct + torch.eq(pred, labels).sum().item()
correct = 100 * correct/total
print("Accuracy of the network on the 25907 test images:%.2f %%" %correct )
print("===================================================")
Finally, I wish you always have a skeptical heart, always look up to the theory, not just talk on paper, put your ideas into practice and keep thinking.