1. Experimental contents
-
MNIST data loading and visualization
-
Read the relevant materials and papers of LeNet-5 and implement the network layer by layer under any framework of Keras, tensorflow or pytoch
Construction of network model -
Model training is implemented on MNIST data set to evaluate model performance indicators
-
Take a photo containing multiple handwritten digits and use it after image clipping, binarization and other image preprocessing
The CNN model trained on MNIST data set is used for classification prediction -
(optional) translate and rotate MNIST or your handwritten data to varying degrees, with equal or unequal length and width
Example) observe the performance change of neural network after stretching and other processing -
PPT report (3min for each group), submit 3-5 pages of experimental report, and briefly describe the method principle, experimental steps and method reference
Numerical discussion and experimental results; It is necessary to clearly explain the division of labor of team members and give the ranking within the group (the same contribution can be marked #).
2 experimental principle
LeNet:

LeNet is the ancestor of convolutional neural network. LeCun proposed it in 1998 to solve the visual task of handwritten numeral recognition. Since then, the most basic architecture of CNN has been determined: convolution layer, pooling layer and full connection layer. Today, the LeNet used in major deep learning frameworks is a simplified and improved LeNet-5 (- 5 means 5 layers), which is slightly different from the original LeNet, such as changing the activation function to the now commonly used ReLu.
LeNet-5 is different from the existing conv - > pool - > relu. It uses conv1 - > pool - > conv2 - > pool2 and then connects to the full connection layer. However, the mode of the convolution layer followed by the pooling layer remains unchanged.
Take the above figure as an example to make an in-depth analysis of the classic LeNet:
First, the input image is a single channel 28 * 28 image, which is represented by a matrix [b, 1,28,28]
-
The convolution kernel size used in the first convolution layer conv1 is 5 * 5, the sliding step size is 1, and the number of convolution cores is 6. After passing through this layer, the image size becomes 24, 28-5 + 1 = 24, and the output matrix is [b, 6,24,24].
-
The pool core size of the first pool layer is 2 * 2 and the step size is 2. This is max pool without overlap. After the pool operation, the image size is halved to 14 × 14. The output matrix is [b, 6,14,14].
-
The convolution core size of the second convolution layer conv2 is 5 * 5, the step size is 1, the number of convolution cores is 16, the image size after convolution becomes 10, and the output matrix is [b,16,10,10]
-
The core size of the second pool layer pool2 is 2 * 2 and the step size is 2. This is max pool without overlap. After the pool operation, the image size is halved to 4 × 4. The output matrix is [b, 16, 5, 5].
-
Pool 2 is followed by full junction layer fc1, the number of neurons is 120, and then connected with relu activation function.
-
Then connected with fc2, the number of neurons was 84, and then connected with relu activation function.
-
The output layer obtains the 10 dimensional feature vector, which is used for the classification training of 10 numbers, which is sent to softmax classification to obtain the probability output of the classification result.
3 specific implementation
Implementation of LeNet based on PaddlePaddle
Load data:
Complete the loading and preprocessing normalization of MNIST data set with the paddle.vision.datasets.MNIST provided by the propeller frame.
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
# Normalize the data set using transform
print('download training data and load training data')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('load finished')
Here, try to take the 666 data in the training set:
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))
The results are as follows:


Visible data loaded successfully.
Modeling:
We directly use the API s under pad.nn, such as Conv2D, MaxPool2D and Linear, to complete the construction of LeNet.
The code is as follows:
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
Model training:
Build an example through the Model provided by the pad, and use the encapsulated training and testing interface to quickly complete the Model training and testing.
from paddle.metric import Accuracy
model = paddle.Model(LeNet()) # Encapsulate Model with Model
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# Configuration model
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# Training model
model.fit(train_dataset,
epochs=2,
batch_size=64,
verbose=1
)
The training process is as follows:
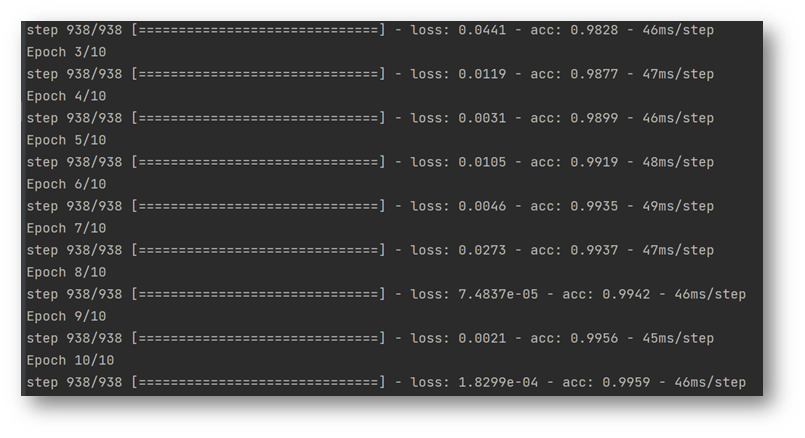
Model test:
Use Model.evaluate to predict the model:
The results are as follows:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-8eap7ppc-1634528724500)( https://i.loli.net/2021/10/13/h5jz6xHeRAOEZqL.png )]
Implementation of LeNet5 based on Pytorch
Load data:
batch_size = 256
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1, shuffle=True)
Modeling:
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.pooling = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.AF = nn.ReLU()
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
for m in self.modules():
if isinstance(m, (nn.Conv3d, nn.Conv2d, nn.Conv1d)):
nn.init.xavier_uniform_(m.weight.data)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight.data)
nn.init.constant_(m.bias.data, 0.0)
def forward(self, x):
x = self.AF(self.conv1(x))
x = self.pooling(x)
x = self.AF(self.conv2(x))
x = self.pooling(x)
x = x.view(x.size(0), -1)
x = self.AF(self.fc1(x))
x = self.AF(self.fc2(x))
x = self.fc3(x)
return x
Model training:
if __name__=="__main__":
batch_size = 256
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1, shuffle=True)
loss = nn.CrossEntropyLoss()
loss.to(device)
net =LeNet5()
net.to(device)
net.train()
epoch = 10
lr = 1e-2
optimizer = optim.SGD(net.parameters(), lr=lr, momentum = 0.9)
for i in range(epoch):
net.train()
for j, (X, y) in enumerate(train_loader):
optimizer.zero_grad()
X,y = autograd.Variable(X).to(device), autograd.Variable(y).to(device)
y_hat = net(X)
# print(y_hat)
l = loss(y_hat, y)
# print(l)
l.backward()
optimizer.step()
test_acc = evaluate_accuracy(net, test_loader)
print("epoch:{}, test_acc:{}".format(i,test_acc))
Training process:
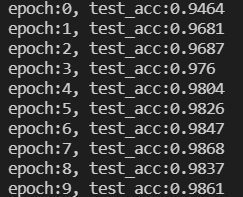
Shooting handwritten numeral recognition
Take photos and collect handwritten numerals
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-gioybwtf-1634528724502)( https://i.loli.net/2021/10/12/OnFLr1f3xiJPuW7.jpg )]
Save as a single picture by screenshot clipping
Image processing
Convert to grayscale image and change image size
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
def load_image(file):
im = Image.open(file).convert('L')
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)
im = im / 255.0 * 2.0 - 1.0
return im

Send to network test
files = os.listdir('testpic')
for file in files:
img = load_image('testpic/' + file)
plt.imshow(img[0][0], cmap=plt.cm.gray)
plt.show()
from Mnist_paddlepaddle import LeNet
model = paddle.Model(LeNet())
model.load('mnist_checkpoint/test')
result = model.predict_batch(img)
print("Inference result of image is:{}".format(np.argmax(result)), end=' ')
print("The real label is: {}".format(file[4]))
result:

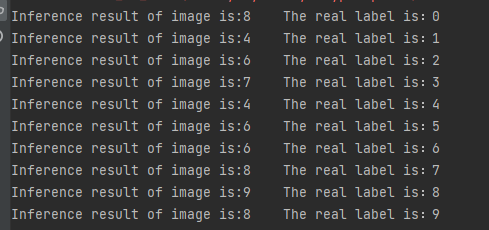
It can be seen that there are many mistakes. Observing the Mnist data set, it is found that the number proportion in the screenshot is too small
Re cut a group of pictures:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-5sez14rh-1634528724508)( https://i.loli.net/2021/10/12/k9hDOrHtP3Cgoa8.png )]
Test results:
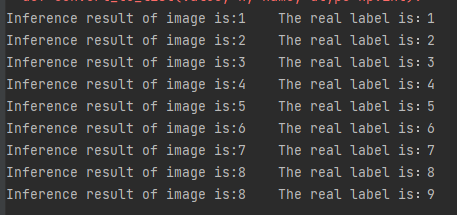
There was only one mistake this time.
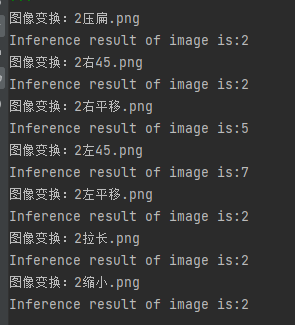
After image translation, rotation and scaling
Take the number 2 as an example.
Original picture:


result:
Digit 5:
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-pfxqwcd3-1634528724512)( https://i.loli.net/2021/10/12/631miPgd5WZlMew.png )]
result:
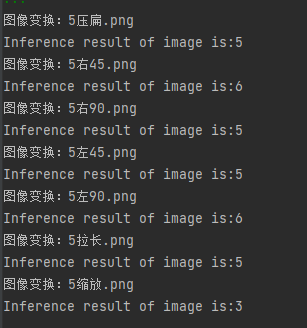
so

Therefore, data augmentation and Spatial Transformer Layer are needed to solve such problems.