Basic concepts in hash table
Hash table definition:
Hash table (also known as hash table) is a data structure that performs insertion, deletion and lookup in constant time. It is a data structure that is accessed directly according to the key value. That is, it accesses records by mapping key values to a location in the table to speed up the search. Given table M, there is a function f(key). For any given keyword value key, after substituting into the function, if the address recorded in the table containing the keyword can be obtained, table M is called hash table, and function f(key) is hash function.
Calculation of hash function H(ElementType Key,HashTable H):
If the keyword Key is an integer number, our corresponding hash function (or hash function) mainly has the following methods:
① Folding method
② Direct addressing method
③ Square middle method
④ Divide and remainder method (more commonly used): that is, the address of the keyword key in the hash table is key% H - > tablesize. But because of this, when using the hash table, two keywords will be hashed to the same address in the hash table, which is hash conflict. So we need to solve hash conflicts, which is the key of this chapter.
Several solutions to hash conflict
Separate link method
The so-called separate link method is to define an array in the form of array + linked list, and each subscript corresponds to the chain header of a linked list. If there is a conflict and the new element has appeared in the corresponding linked list in the hash table, no operation will be performed. On the contrary, if there is no conflict, the new keyword will be inserted into the chain header or tail of the corresponding address. As shown in the figure below:
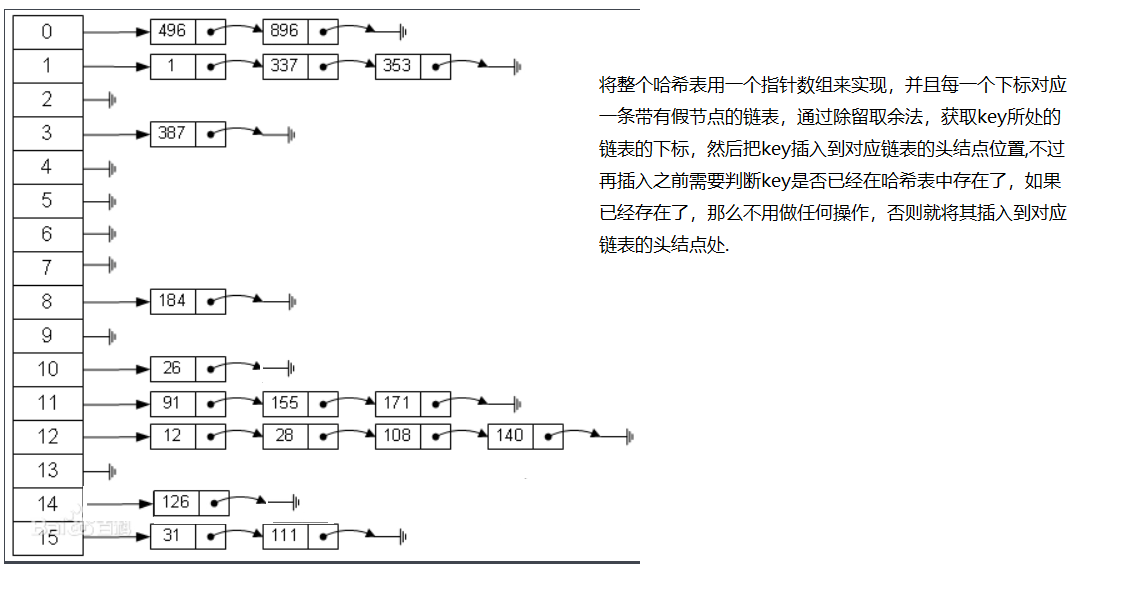
Therefore, when adopting the separate link method, we need to do the following preparations:
1. Define a Node structure Node, which is used to build a linked list
2. Define a structure that represents the hash table HashTable. The member variables of this structure mainly include an array of Node type pointers and an integer variable that represents the size of the hash table.
Corresponding code:
#include<stdio.h>
#include<stdlib.h>
typedef struct NODE *Node;
typedef Node * List;
typedef struct HASHTABLE HashTable;
struct NODE{
int data;
Node next;
};
struct HASHTABLE{
int size;//Indicates the size of the hash table
List arr;
};
//Initialize hash table
void init(HashTable &H,int size){
H.size = size;//Initialize the size of the hash table
H.arr = (List)malloc(sizeof(Node) * size);//Allocate space to the pointer array in the hash table
if(H.arr == NULL){
printf("Pointer array failed to allocate space!!!\n");
exit(0);
}
int i;
for(i = 0; i < size; i++){
H.arr[i] = (Node)malloc(sizeof(struct NODE));//Allocate space to each node
if(H.arr[i] == NULL){
printf("Node assignment failed!!!\n");
exit(0);
}
//Each subscript corresponds to a linked list, and this linked list is a linked list with false nodes
H.arr[i]->next = NULL;
}
}
int hash(HashTable &H,int key){
return key % H.size;//The key address in the hash table is obtained by using the division, retention and remainder method
}
/*
Find keyword key in hash table:
1,First, we need to use the division, retention and remainder method to obtain the linked list position of the key in the hash table
2,After finding the linked list, traverse the linked list to determine whether the node with the value tail key can be found. If it can be found,
This node will be returned, otherwise null will be returned
*/
Node find(HashTable &H,int key){
int pos;
Node L,cur;
pos = hash(H,key);//Gets the position of the key in the hash table
L = H.arr[pos];//Get the linked list of the address where the key is located
cur = L->next;//Since l is a linked list with false nodes, L - > next is the real head node of the linked list
while(cur != NULL && cur->data != key){
//If the current node is not empty and the value of the current node is not the keyword to be found, continue to traverse the linked list
cur = cur->next;
}
return cur;
}
/*
Insert keyword in hash table
Judge whether the keyword already exists in the hash table. If it exists, no operation will be carried out, otherwise it will be deleted
Insert it into the head of the corresponding linked list
*/
void insert(HashTable &H,int key){
Node L,p;
p = find(H,key);
if(p == NULL){
//If p is empty, it means that there is no node with this keyword in the hash table, then insert the new node into the corresponding chain header
L = H.arr[key % H.size];//Get the linked list where the keyword is located
p = (Node)malloc(sizeof(struct NODE));
p->next = L->next;
p->data = key;
L->next = p;
printf("Insert successful!!!\n");
}else{
printf("keyword%d It already exists in the hash table, and the subscript of the linked list is%d\n",key,key % H.size);
}
}
void deleteElement(HashTable &H,int key){
Node L,p,tmp;
p = find(H,key);
if(p != NULL){
//If p is not empty, there is no node with this keyword in the hash table
L = H.arr[key % H.size];//Get the linked list where the keyword is located
p = L;
while(p->next != NULL && p->next->data != key){
//Find the previous node to delete the node
p = p->next;
}
tmp = p->next;//Deleted node found
p->next = p->next->next;
free(tmp);//Release the node to be deleted
printf("Deleted successfully!!!\n");
}else{
printf("keyword%d Does not exist in hash table\n",key);
}
}
void display(HashTable &H){
int i;
Node L;
for(i = 0; i < H.size; i++){
L = H.arr[i]->next;
if(L == NULL){
printf("NULL\n");
}else{
while(L != NULL){
printf("%5d",L->data);
L = L->next;
}
printf("\n");
}
}
}
int main(){
HashTable h;
int n,i,key;
printf("Please enter the size of the hash table:");
scanf("%d",&n);
init(h,n);
printf("Please enter the number of elements:");
scanf("%d",&n);
printf("Please enter each keyword:");
for(i = 0; i < n; i++){
scanf("%d",&key);
insert(h,key);
}
while(1){
printf("Please enter an option: 1,Insert 2. Find 3. Delete 4. Traverse hash table 0. Exit\n");
scanf("%d",&n);
switch(n){
case 1:
printf("Please enter the number to be inserted:");
scanf("%d",&key);
insert(h,key);
break;
case 2:
printf("Please enter the number to be found:");
scanf("%d",&key);
if(find(h,key)){
printf("Found, the subscript of the linked list is%d\n",key % h.size);
}else{
printf("Cannot find in hash table%d\n",key);
}
break;
case 3:
printf("Please enter the number to be deleted:");
scanf("%d",&key);
deleteElement(h,key);
break;
case 4:
display(h);
break;
case 0:
printf("Exit the system");
exit(0);
}
}
return 0;
}
Operation results:
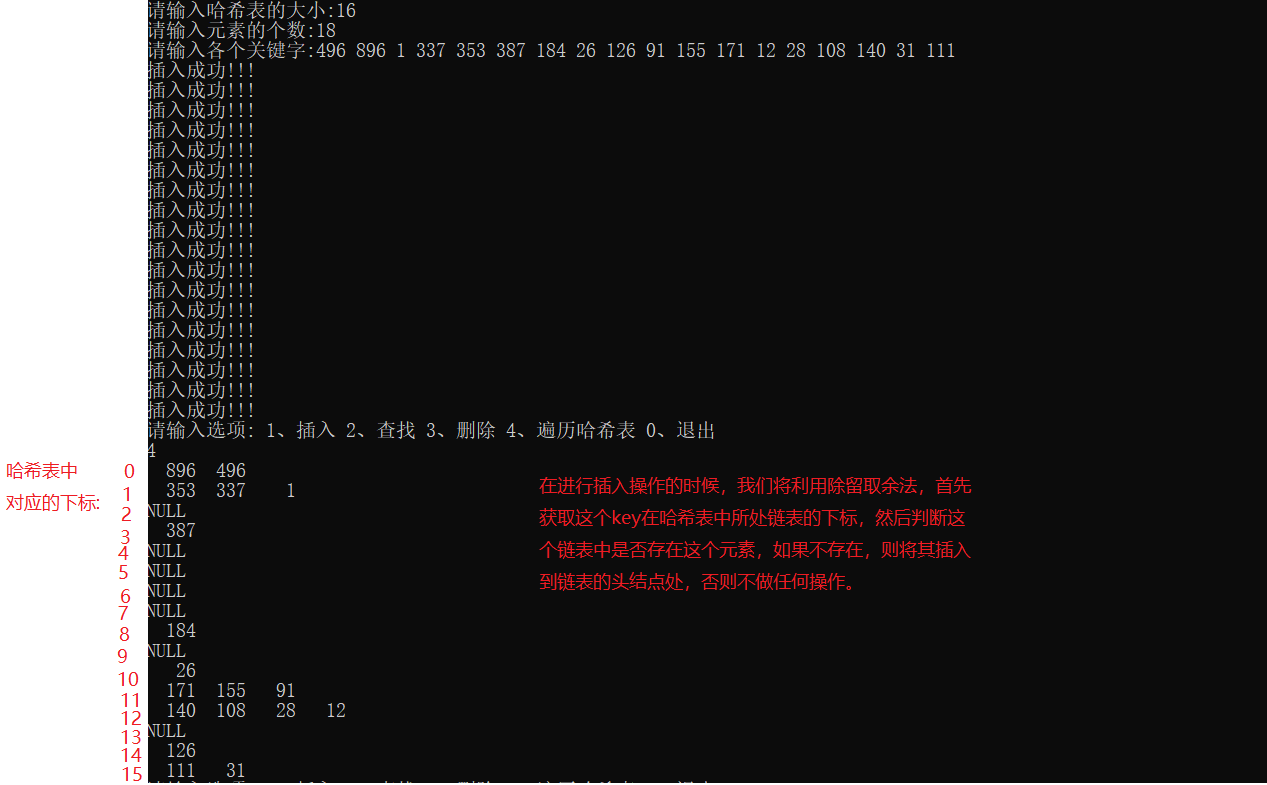
Open address method
The open address method is implemented by array. Its basic idea is: if there is a conflict, you need to find an empty unit to store this keyword. Therefore, in the ith conflict, the subscript of the keyword in the hash table is: hash = (hash (key) + F (i))% h.tablesize
Linear detection method
The so-called linear detection method is that in the above basic formula, F(i) = 1,2,3,4 The form of N moves back. In other words, if there is a conflict, it adds F(i) to the current subscript (i.e. key% tablesize).
Corresponding code:
/*
Linear detection method:
When there is a conflict, move back until you find the first empty one
Unit, then press the number into this unit
*/
#include<stdio.h>
#include<stdlib.h>
#define Empty 0
#define Occupy 1
typedef struct HASHTABLE HashTable;
typedef struct ELEMENT Element;
struct ELEMENT{
int val;//value
int state;//Indicates whether this element is empty. If it is 0, it means empty. Otherwise, it is not empty
};
struct HASHTABLE{
Element *arr;//Use an integer array to represent the hash table
int size;//Size of hash table
};
//Initialize hash table
void init(HashTable &H,int size){
H.arr = (Element *)malloc(sizeof(Element) * size);
if(H.arr == NULL){
printf("Failed to allocate space for hash table array!!!\n");
exit(0);
}
int i;
//Initialize the hash table, indicating that it is an empty table
for(i = 0; i < size; i++){
H.arr[i].state = Empty;
}
H.size = size;
}
//Define hash function
int hash(HashTable &H,int key){
return key % H.size;
}
//Find the subscript corresponding to the key in the hash table
int findElement(HashTable &H,int key){
int pos;
pos = hash(H,key);//Find the address where the keyword is hashed in the hash table
while(H.arr[pos].state != Empty && H.arr[pos].val != key){
//If the current subscript is not empty and the corresponding value is not the keyword we are looking for, move it back
pos++;
/*
pos %= H.size;
*/
if(pos >= H.size)
pos -= H.size;//If the corresponding POS is greater than or equal to H.size when moving backward, we need to return to the position with the subscript pos - H.size
}
/*
At this time, there are two situations for the returned pos, which may be that the pos subscript in the hash table is empty, so let's
When performing corresponding operations, you need to judge whether the current element is empty,
It is also possible that the pos subscript is not empty, and the element value corresponding to this subscript is the keyword we are looking for
*/
return pos;
}
//Insert element
void insertElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);//Find the position of the key in the hash table
/*
Judge whether the pos subscript is empty in the hash table. If it is empty, it means that it is not found
At this time, we press the key into the pos subscript, otherwise we don't need to do anything to avoid
Insert duplicate number
*/
if(H.arr[pos].state == Empty){
H.arr[pos].val = key;
H.arr[pos].state = Occupy;//After the element is inserted, it should be noted that the subscript already has a value
}
}
/*
Delete element: using lazy deletion, we don't really delete this element from the
The number of deleted elements in the hash table should be moved forward. On the contrary, we just
Mark the status corresponding to the currently deleted element as Empty. At this time, you can insert the element next time
The subscript is inserted to achieve the effect of deletion
*/
void deleteElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);
if(H.arr[pos].state == Occupy){
//Judge whether the element to be deleted can be found. If it is occupancy, it indicates that it is found
printf("Deleted element%d The subscript in the hash table is%d\n",key,pos);
H.arr[pos].state = Empty;//After deletion, mark the status corresponding to this subscript as Empty
}
}
void display(HashTable &H){
int i;
for(i = 0; i < H.size; i++){
if(H.arr[i].state == Empty){
printf("%5d: NULL\n",i);
}else{
printf("%5d: %d\n",i,H.arr[i].val);
}
}
}
int main(){
HashTable h;
int n,i,key,pos;
printf("Please enter the size of the hash table:");
scanf("%d",&n);
init(h,n);//Initialize hash table
printf("Please enter the number of elements:");
scanf("%d",&n);
printf("Please enter each keyword:");
for(i = 0; i < n; i++){
scanf("%d",&key);
insertElement(h,key);
}
while(1){
printf("Please enter an option: 1,Insert 2. Find 3. Delete 4. Traverse hash table 0. Exit\n");
scanf("%d",&n);
switch(n){
case 1:
printf("Please enter the number to be inserted:");
scanf("%d",&key);
insertElement(h,key);
break;
case 2:
printf("Please enter the number to be found:");
scanf("%d",&key);
pos = findElement(h,key);
if(h.arr[pos].state == Occupy){
/*
After obtaining the keyword of key, we need to judge whether the subscript is empty in the hash table. If
If it is empty, it indicates that there is no way to find the key in the hash table, otherwise it is found
*/
printf("Found, the hash table subscript is%d\n",pos);
}else{
printf("Cannot find in hash table%d\n",key);
}
break;
case 3:
printf("Please enter the number to be deleted:");
scanf("%d",&key);
deleteElement(h,key);
break;
case 4:
display(h);
break;
case 0:
printf("Exit the system");
exit(0);
}
}
return 0;
}
Operation results:
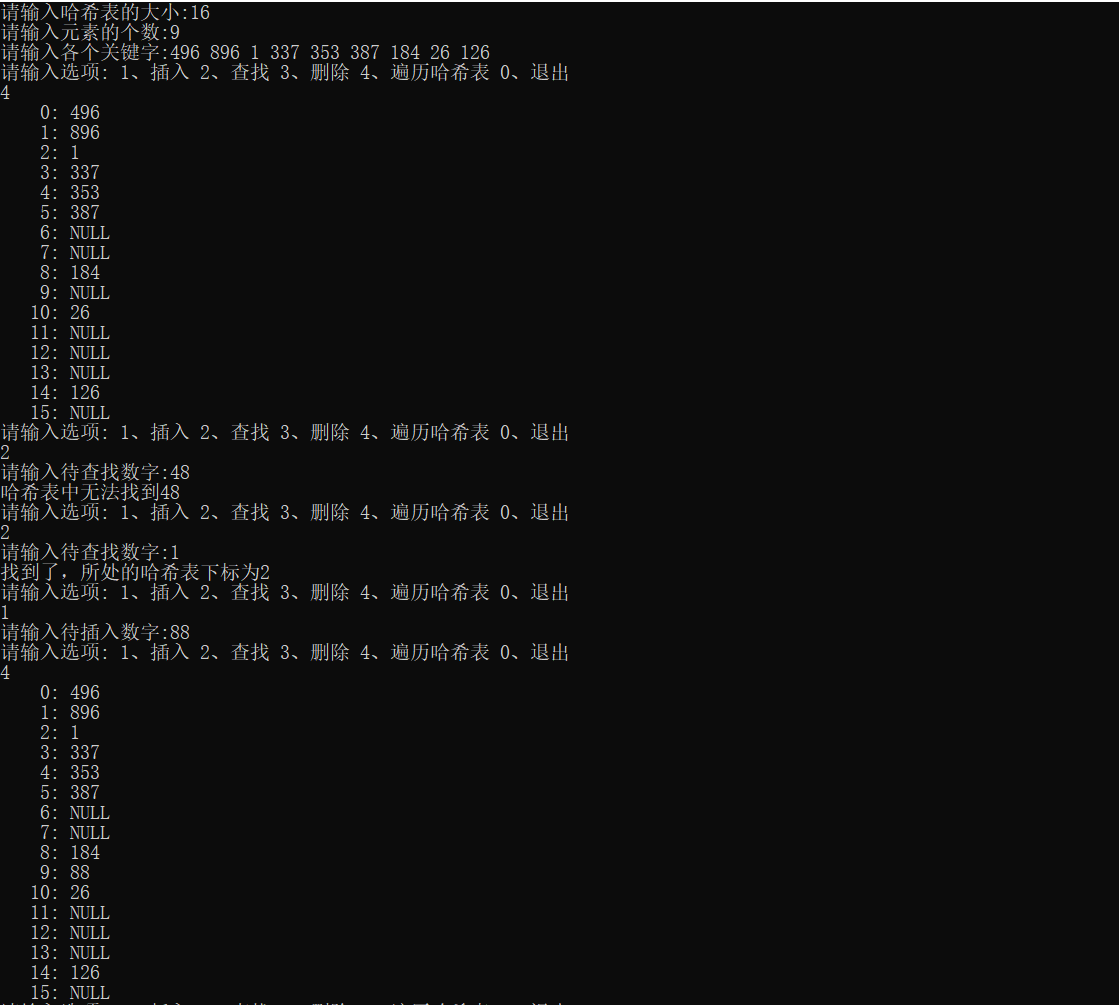
Square detection method
The so-called square detection method is to use F(i) = 1 in the above basic formula ²,- one ², two ²,- two ² Move back in the form of. In other words, if there is a conflict, it adds F(i) to the current subscript (i.e. key% tablesize).
Corresponding code:
#include<stdio.h>
#include<stdlib.h>
#define Empty 0
#define Occupy 1
typedef struct HASHTABLE HashTable;
typedef struct ELEMENT Element;
struct ELEMENT{
int val;//value
int state;//Indicates whether this element is empty. If it is 0, it means empty. Otherwise, it is not empty
};
struct HASHTABLE{
Element *arr;//Use an integer array to represent the hash table
int size;//Size of hash table
};
//Initialize hash table
void init(HashTable &H,int size){
H.arr = (Element *)malloc(sizeof(Element) * size);
if(H.arr == NULL){
printf("Failed to allocate space for hash table array!!!\n");
exit(0);
}
int i;
//Initialize the hash table, indicating that it is an empty table
for(i = 0; i < size; i++){
H.arr[i].state = Empty;
}
H.size = size;
}
//Define hash function
int hash(HashTable &H,int key){
return key % H.size;
}
//Find the subscript corresponding to the key in the hash table
int findElement(HashTable &H,int key){
int pos,oldPos,d,count;
count = 0;
oldPos = hash(H,key);//Find the address where the keyword is hashed in the hash table
pos = oldPos;
while(H.arr[pos].state != Empty && H.arr[pos].val != key){
//If the current subscript is not empty and the corresponding value is not the keyword we are looking for, move it back
count++;//Number of conflicts
if(count % 2 == 0){
//The number of collisions is even. We need to subtract the square of F(i)
d = count / 2;
pos = oldPos - d * d;
while(pos < 0)
pos += H.size;
}else{
//The number of conflicts is an odd number. We need to add the square of F(i)
d = (count + 1) / 2;
pos = oldPos + d * d;
while(pos >= H.size)
pos -= H.size;
}
}
/*
At this time, there are two situations for the returned pos, which may be that the pos subscript in the hash table is empty, so let's
When performing corresponding operations, you need to judge whether the current element is empty,
It is also possible that the pos subscript is not empty, and the element value corresponding to this subscript is the keyword we are looking for
*/
return pos;
}
//Insert element
void insertElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);//Find the position of the key in the hash table
/*
Judge whether the pos subscript is empty in the hash table. If it is empty, it means that it is not found
At this time, we press the key into the pos subscript, otherwise we don't need to do anything to avoid
Insert duplicate number
*/
if(H.arr[pos].state == Empty){
H.arr[pos].val = key;
H.arr[pos].state = Occupy;//After the element is inserted, it should be noted that the subscript already has a value
}
}
/*
Delete element: using lazy deletion, we don't really delete this element from the
The number of deleted elements in the hash table should be moved forward. On the contrary, we just
Mark the status corresponding to the currently deleted element as Empty. At this time, you can insert the element next time
The subscript is inserted to achieve the effect of deletion
*/
void deleteElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);
if(H.arr[pos].state == Occupy){
//Judge whether the element to be deleted can be found. If it is occupancy, it indicates that it is found
printf("Deleted element%d The subscript in the hash table is%d\n",key,pos);
H.arr[pos].state = Empty;//After deletion, mark the status corresponding to this subscript as Empty
}
}
void display(HashTable &H){
int i;
for(i = 0; i < H.size; i++){
if(H.arr[i].state == Empty){
printf("%5d: NULL\n",i);
}else{
printf("%5d: %d\n",i,H.arr[i].val);
}
}
}
int main(){
HashTable h;
int n,i,key,pos;
printf("Please enter the size of the hash table:");
scanf("%d",&n);
init(h,n);
printf("Please enter the number of elements:");
scanf("%d",&n);
printf("Please enter each keyword:");
for(i = 0; i < n; i++){
scanf("%d",&key);
insertElement(h,key);
}
while(1){
printf("Please enter an option: 1,Insert 2. Find 3. Delete 4. Traverse hash table 0. Exit\n");
scanf("%d",&n);
switch(n){
case 1:
printf("Please enter the number to be inserted:");
scanf("%d",&key);
insertElement(h,key);
break;
case 2:
printf("Please enter the number to be found:");
scanf("%d",&key);
pos = findElement(h,key);
if(h.arr[pos].state == Occupy){
printf("Found, the hash table subscript is%d\n",pos);
}else{
printf("Cannot find in hash table%d\n",key);
}
break;
case 3:
printf("Please enter the number to be deleted:");
scanf("%d",&key);
deleteElement(h,key);
break;
case 4:
display(h);
break;
case 0:
printf("Exit the system");
exit(0);
}
}
return 0;
}
Operation results:
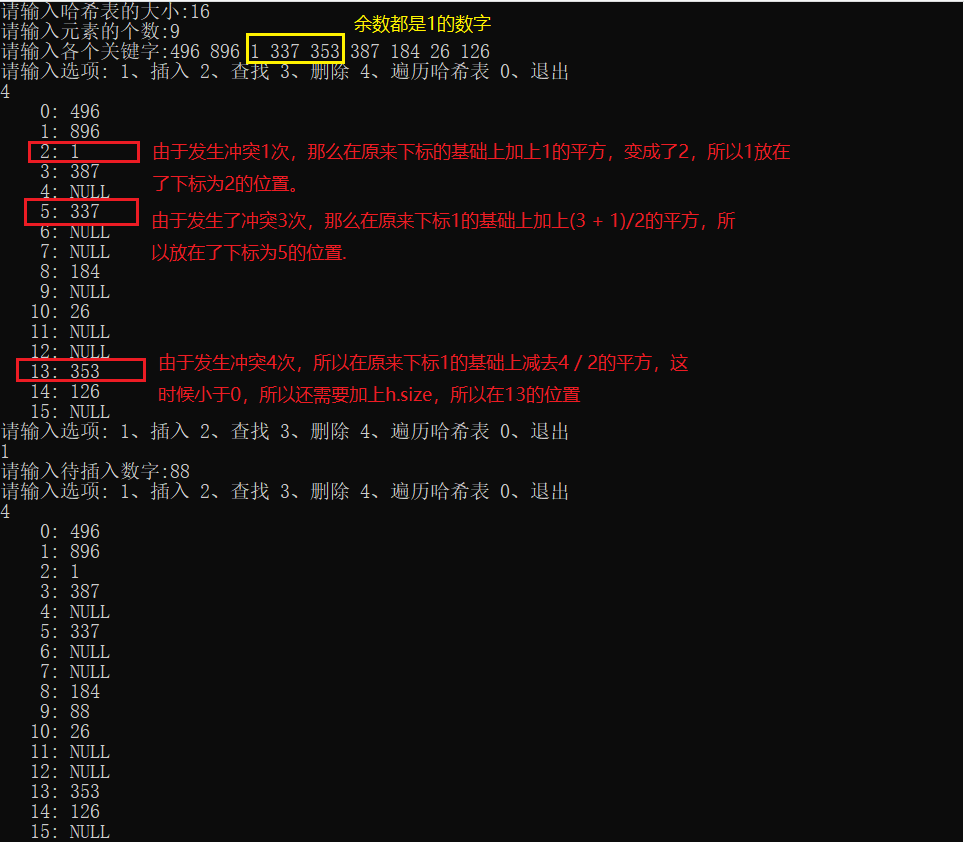
Double hash
The so-called double hash is F(i) = i * hash2(key), and hash2 (key) = P - (key% P), where p is a prime number
Corresponding code:
#include<stdio.h>
#include<stdlib.h>
#define Empty 0
#define Occupy 1
typedef struct HASHTABLE HashTable;
typedef struct ELEMENT Element;
struct ELEMENT{
int val;//value
int state;//Indicates whether this element is empty. If it is 0, it means empty. Otherwise, it is not empty
};
struct HASHTABLE{
Element *arr;//Use an integer array to represent the hash table
int size;//Size of hash table
};
//Initialize hash table
void init(HashTable &H,int size){
H.arr = (Element *)malloc(sizeof(Element) * size);
if(H.arr == NULL){
printf("Failed to allocate space for hash table array!!!\n");
exit(0);
}
int i;
//Initialize the hash table, indicating that it is an empty table
for(i = 0; i < size; i++){
H.arr[i].state = Empty;
}
H.size = size;
}
//Define hash function
int hash(HashTable &H,int key){
return key % H.size;
}
int hash2(int key,int p){
return p - (key % p);
}
//Find the subscript corresponding to the key in the hash table
int findElement(HashTable &H,int key){
int pos,oldPos,d,count;
count = 0;//count indicates the number of conflicts
oldPos = hash(H,key);//Find the address where the keyword is hashed in the hash table
d = hash2(key,7);//Here, the value of p is 7
pos = oldPos;
while(H.arr[pos].state != Empty && H.arr[pos].val != key){
//If the current element is not empty and is not the keyword you are looking for, continue hashing
count++;
//Double hash
pos = oldPos + count * d;
while(pos >= H.size)
pos -= H.size;
}
/*
At this time, there are two situations for the returned pos, which may be that the pos subscript in the hash table is empty, so let's
When performing corresponding operations, you need to judge whether the current element is empty,
It is also possible that the pos subscript is not empty, and the element value corresponding to this subscript is the keyword we are looking for
*/
return pos;
}
//Insert element
void insertElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);//Find the position of the key in the hash table
/*
Judge whether the pos subscript is empty in the hash table. If it is empty, it means that it is not found
At this time, we press the key into the pos subscript, otherwise we don't need to do anything to avoid
Insert duplicate number
*/
if(H.arr[pos].state == Empty){
H.arr[pos].val = key;
H.arr[pos].state = Occupy;//After the element is inserted, it should be noted that the subscript already has a value
}
}
/*
Delete element: using lazy deletion, we don't really delete this element from the
The number of deleted elements in the hash table should be moved forward. On the contrary, we just
Mark the status corresponding to the currently deleted element as Empty. At this time, you can insert the element next time
The subscript is inserted to achieve the effect of deletion
*/
void deleteElement(HashTable &H,int key){
int pos;
pos = findElement(H,key);
if(H.arr[pos].state == Occupy){
//Judge whether the element to be deleted can be found. If it is occupancy, it indicates that it is found
printf("Deleted element%d The subscript in the hash table is%d\n",key,pos);
H.arr[pos].state = Empty;//After deletion, mark the status corresponding to this subscript as Empty
}
}
void display(HashTable &H){
int i;
for(i = 0; i < H.size; i++){
if(H.arr[i].state == Empty){
printf("%5d: NULL\n",i);
}else{
printf("%5d: %d\n",i,H.arr[i].val);
}
}
}
int main(){
HashTable h;
int n,i,key,pos;
printf("Please enter the size of the hash table:");
scanf("%d",&n);
init(h,n);
printf("Please enter the number of elements:");
scanf("%d",&n);
printf("Please enter each keyword:");
for(i = 0; i < n; i++){
scanf("%d",&key);
insertElement(h,key);
}
while(1){
printf("Please enter an option: 1,Insert 2. Find 3. Delete 4. Traverse hash table 0. Exit\n");
scanf("%d",&n);
switch(n){
case 1:
printf("Please enter the number to be inserted:");
scanf("%d",&key);
insertElement(h,key);
break;
case 2:
printf("Please enter the number to be found:");
scanf("%d",&key);
pos = findElement(h,key);
if(h.arr[pos].state == Occupy){
printf("Found, the hash table subscript is%d\n",pos);
}else{
printf("Cannot find in hash table%d\n",key);
}
break;
case 3:
printf("Please enter the number to be deleted:");
scanf("%d",&key);
deleteElement(h,key);
break;
case 4:
display(h);
break;
case 0:
printf("Exit the system");
exit(0);
}
}
return 0;
}
Operation results:
Re hashing
For the open address hash method using square detection, if the table is filled too full, the running time of the operation will consume the process, and the insert operation may fail, because there may be no way to find a suitable location for insertion, resulting in too many movements (i.e. it may fall into an endless loop, resulting in timeout). At this time, we need to re hash, that is, create another table about twice the size, scan the original hash table, calculate the address of each element in the original hash table in the new table, and then insert it into the new table. The reason why we need to re calculate the address of each element in the original hash table in the new table, Because the size of the table has changed, the element addresses in the old and new tables are different.