Firstly, hash table is a common data structure used to find data.
So why use a hash table? Can't arrays and linked lists also be searched?
Let's start with the array. If the data stored in the array corresponds to the subscript, the search speed is really fast, but what if it's the following example?
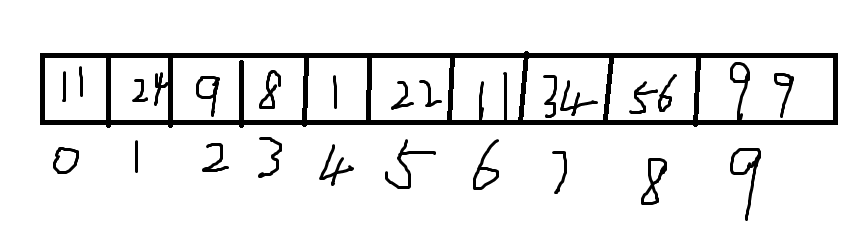 (don't mind if you don't draw well)
(don't mind if you don't draw well)
As you can see, each element in the array does not correspond to its subscript. Then, when searching for data, you need to compare elements one by one. When the amount of data is small, it is acceptable, but when the amount of data is large, the efficiency will be quite low.
The same is true of linked lists.
Let me introduce another example.
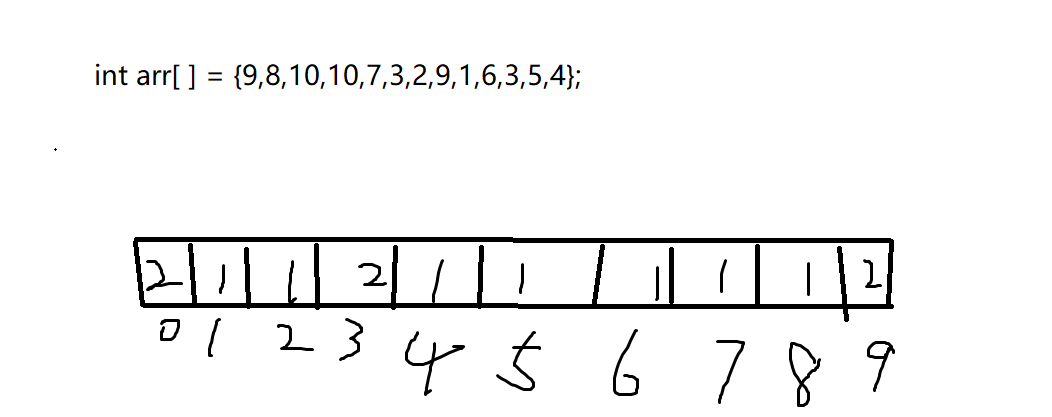
Smart, you may have found the rule, that is, take the remainder of each element in the arr and the largest element, that is, 10, and save the number of results in a new array.
The size of this new array is equal to the largest value in arr. In other words, if the maximum value is 100, the size of the array is 100. Let's not discuss space first. Let's first look at the efficiency of the search. If I want to find 10, I just need to take the remainder of 10 and 10, that is, find out whether the value of 0 position in the new array is 0 or not, indicating that there is 10 in arr. Is this search efficient? However, the disadvantage of this method is that it consumes a lot of space resources.
Therefore, with the improvement of this method, hash lookup evolved.
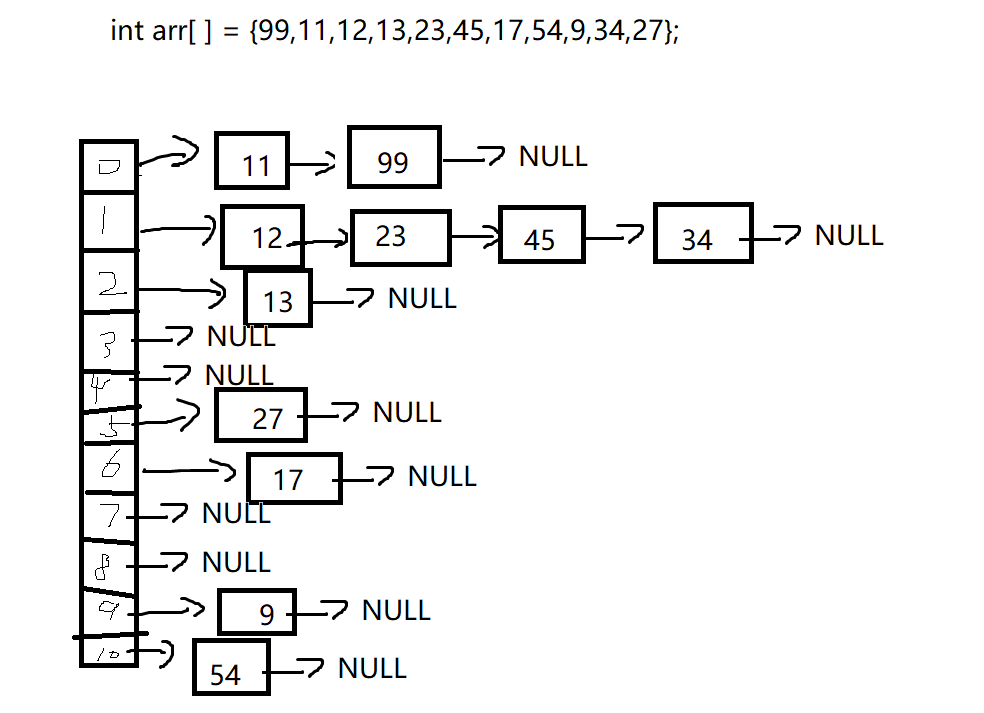
(it's really ugly. If you have a more convenient drawing software, please leave a message.)
The maximum number in array arr is 99. If you follow the above method, you need to apply for an integer array with a size of 99*sizeof(int).
However, there are only 11 data, which will cause a waste of resources.
An array of size 11 is created here. Why 11? Because the size is 11? No, because here 11 is a prime number, which can make the remainder distribution more uniform when the array is used for remainder operation.
First, let's talk about some concepts of hash table.
"Hash table (also known as hash table) is based on Key And directly access the data structure stored in memory. In other words, it accesses the records by calculating a function about the Key value and mapping the data of the required query to a position in the table, which speeds up the search speed. This mapping function is called a hash function, and the array of records is called a hash.
(the function of the mapping function here is to take the remainder of the array elements, and the hash table is the array with the size of 11 in the figure.)
Why is there a linked list after every element in the array?
Careful friends may have found that the elements in the same linked list are the same as the remainder after 11. This situation is called hash conflict. To solve this problem, add a linked list after the element to save the data with the same remainder.
Common methods to resolve hash conflicts are:
1. Open addressing method
2. Chain address method (usually hash table + linked list. If you want to optimize it again, you can replace the linked list with a binary tree)
OK, the concept is almost introduced. Now let's talk about how to use hash table to save and search data.
First, we get the array to save the data. First, we find the length of the defined hash table, and generally take the prime number (there is no specified method, but the selection of this number will also affect the search efficiency).
Save the data as shown in the figure above.
Then, when searching for data, first obtain the key value of the data (that is, the remainder, which is generally the length of the hash table).
Then it looks up the data in the form of linked list or binary tree.
The following is the code of chained address method (Hash Table + linked list)
#define TABLESIZE 7
typedef struct pNode
{
int data; // Data field in linked list
struct pNode* next; // The address of the next node of each node in the linked list
}Node;
typedef struct Hash_Table
{
int size; // The number of data stored in the hash table
int length; // Length of hash table
struct pNode* head; // First address of linked list array
}Hash;
int hash_key(int data) // Returns the hash table subscript
{
return data % TABLESIZE;
}
Hash* Init_HashTable() // Initialize hash table
{
Hash* hash = (Hash*)malloc(sizeof(struct Hash_Table));
hash->length = TABLESIZE;
hash->size = 0;
hash->head = (Node*)malloc(sizeof(Node) * TABLESIZE); // Apply for the address array space for storing different subscript chain headers
for (int i = 0; i < TABLESIZE; i++)
{
hash->head[i].data = -1;
hash->head[i].next = NULL;
}
return hash;
}
int find(Hash* hash, int data) // Find whether a data exists in the hash table
{
if (!hash) return 0;
int key = hash_key(data);
Node* pCur = hash->head[key].next;
while (pCur)
{
if (pCur->data == data) return 1;
pCur = pCur->next;
}
return 0;
}
void insert(Hash* hash, int data) // Insert into hash table
{
if (!find(hash, data))
{
int key = hash_key(data);
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = hash->head[key].next;
hash->head[key].next = newNode;
hash->size += 1;
return;
}
else
{
printf("The data already exists in the hash table!");
return;
}
}
void del(Hash* hash, int data) // Delete an element in the hash table
{
if (!hash)return;
if (!find(hash, data))
{
printf("The element does not exist!\n");
return;
}
else
{
int key = hash_key(data);
Node* pre = &hash->head[key];
Node* pCur = hash->head[key].next;
while (pCur)
{
if (pCur->data == data)
{
pre->next = pCur->next;
free(pCur);
pCur = NULL;
return;
}
pre = pCur;
pCur = pCur->next;
}
}
}
void destory(Hash* hash) // Destroy hash table
{
if (!hash) return;
Node *next, *pCur;
for (int i = 0; i < TABLESIZE; i++)
{
pCur = hash->head[i].next;
while (pCur)
{
next = pCur->next;
free(pCur);
pCur = next;
}
}
free(hash->head);
free(hash);
}
void foreach_hashtable(Hash* hash) // Traversal hash table
{
if (!hash) return;
for (int i = 0; i < TABLESIZE; i++)
{
Node* pCur = hash->head[i].next;
printf("[%d]:\n", i);
if (!pCur)
{
printf("NULL\n");
}
while (pCur)
{
printf("%d\n", pCur->data);
pCur = pCur->next;
}
}
}