A few days ago, during an interview with pdd, the interviewer asked HashMap once. He thought he had a good command, but he didn't think he was too skinny. In the spirit of Geek, just dig into HashMap. First, HashMap is introduced in detail based on JDK, and then the source code is analyzed.
The Implementation Characteristics of HashMap
1. HashMap and HashTable are similar, but the difference is:
- HashMap Thread Insecurity
- HashMap can store null keys and null values
- Relative performance is high because threads are insecure
2. HashMap storage does not guarantee sequential storage
3. The time and capacity of HashMap iterating over the entire set are related to key pairs. An example of HashMap has two parameters that affect its performance: initial capacity and load factor.
4. HashMap is stored in hash bucket mode.
5. Its Iterator iterator uses a fast failure mechanism
6. If you use a custom class as a Key, you need to pay attention to its equals method and hashCode method.
7. HashMap has a thread-safe version: ConcurrentHashMap
8. HashMap implementations include trees, which I'll talk about in another article.
The following features are explained:
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
HashMap is an implementation of the Map interface based on hash tables, providing all options and allowing null key and null value. HashMap class is approximately equal to Hashtable. The difference is that HashMap is asynchronous, that is, thread insecurity and hashtable does not allow null storage; HashMap class does not guarantee sequential storage, that is, in what order you store, he does not necessarily write in the map in that order.
This implementation provides constant-time performance for the basic operations (get and put), assuming the hash function disperses the elements properly among the buckets. Iteration over collection views requires time proportional to the "capacity" of the HashMap instance (the number of buckets) plus its size (the number of key-value mappings). Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
Assuming that hash functions properly scatter elements between buckets, the implementation of HashMap provides constant time performance for basic operations (get and put). That is, the time required to iterate over the entire set is proportional to the number of hashMap buckets and the number of key values. Capacity refers to the number of buckets in the hash bucket (the hash bucket means the following), so try not to set too much capacity for initialization.
hash bucket
When we use hash value to store data, we will encounter conflicts. The commonly used methods to resolve conflicts are: open address, chain address, overflow area, in which the chain address is the hash bucket. ,
We will set the hash value of the element to a bucket, and the elements with the same hash value will be put into a bucket, as shown below. Finding elements based on hash values and values is also a step. Find the barrel of hash values. If the first element in the barrel is to find, it ends. Otherwise, continue to find the next element until it finds the element.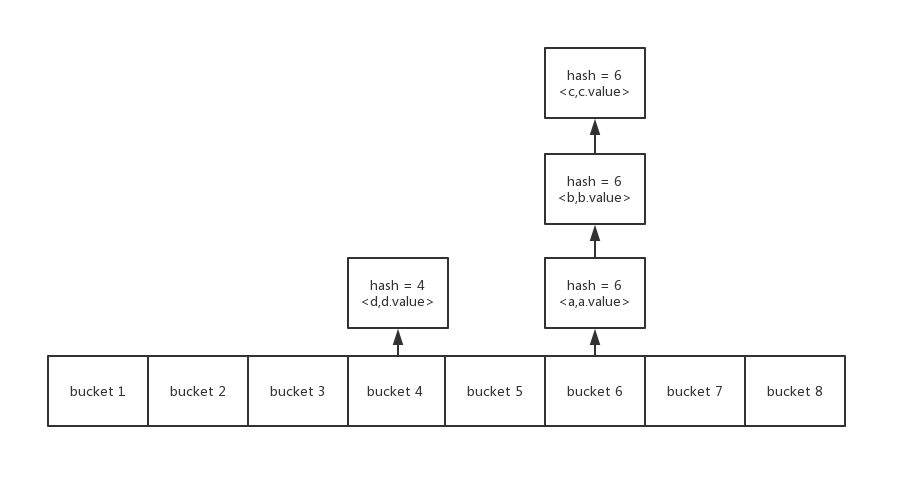
An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
HashMap instances have two parameters that affect their performance: initial capacity and load factor. Capacity is the number of buckets in the hash table (explained above), and the initial capacity is only the capacity when the hash table is created. Loading factor is a measure of the degree of completeness that a hash table is allowed to obtain before automatically increasing capacity. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table will be re-hashed (i.e., reconstructing the internal data structure) so that the hash table has about twice the number of barrels.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
As a general rule, the default load factor (.75) provides a good trade-off between time and space costs. Higher values reduce space overhead, but increase lookup costs (reflected in most operations of the HashMap class, including get and put). When setting its initial capacity, the number of expected entries in the map and their load factors should be considered to minimize the number of re-hashing operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, the reload operation will not occur.
If many mappings are to be stored in a HashMap instance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table. Note that using many keys with the same hashCode() is a sure way to slow down performance of any hash table. To ameliorate impact, when keys are Comparable, this class may use comparison order among keys to help break ties.
If there are too many key pairs stored, giving him enough initial capacity will be more efficient than expanding his capacity (because the Hash table needs to be adjusted). Using many keys with the same hashCode () slows down any hash table performance. To improve this situation, when keys are comparable, this class can use their order to reduce this impact.
If the loading factor is 0.75 (default, best) and the current capacity is 16, the expansion will be carried out when the number of keys exceeds 16.
Note that this implementation is not synchronized. If multiple threads access a hash map concurrently, and at least one of the threads modifies the map structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more mappings; merely changing the value associated with a key that an instance already contains is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the map. If no such object exists, the map should be "wrapped" using the Collections.synchronizedMap method. This is best done at creation time, to prevent accidental unsynchronized access to the map:
Use Map M = Collections. synchronized Map (new HashMap (...));
We can notice that the implementation of HashMap is asynchronous, so if adding or deleting HashMap requires external synchronization, the usual method is object lock, or using the synchronized Map method of Collections tool class to wrap it. And it's best to wrap the object when it's created. (Or use Concurrent HashMap, which I'll write out later.)
The iterators returned by all of this class's "collection view methods" are fail-fast: if the map is structurally modified at any time after the iterator is created, in any way except through the iterator's own remove method, the iterator will throw a ConcurrentModificationException. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw ConcurrentModificationException on a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs.
The above is about the fail-fast mechanism of Iterator iterator, which is not only for HashMap, but also for all Collection Iterator iterators. Once the set is structured in the iteration process, exceptions will be thrown except for the remove method in the iterator. Consequently, when concurrent modifications are encountered, they will fail quickly and cleanly, avoiding the risk of uncertain behavior at uncertain times in the future. It is also important to note that the fast failure mechanism behavior of iterators cannot be guaranteed. For example, in some cases, deleting elements in iterators may not cause exceptions, but it must not be assumed that elements can be deleted during iterations. For collections such as HashMap, ArrayList, structured operations during iterations can lead to exceptions, and exceptions are not thrown as long as specific elements are manipulated. If you want to get a deeper understanding, you can check the implementation code of these collections.
Custom classes as Key values need to be noted:
If you use a custom class as a key and rewrite the equals method and hashCode method, you need to ensure that the criteria for judging the two methods are the same. That is, when two keys are compared by equals, the hashCode should be the same. For more details, see: Judging Object Equality and the Same Object Problem-Rewriting equals Method for Custom Classes and hashCode Method, and Encountering HashSet Set Set Problem HashMap has the same key storage as HashSet