brief introduction
Introduction to HashMap
HashMap is an implementation of Map interface based on hash table, which is used to store key value pairs. Due to the implementation of Map interface, HashMap allows null to be used as key and value, which is the same as other ordinary key values, that is, null can be used as the value of multiple keys, but can only be used as one key
The default initialization capacity of HashMap is 16, and it will be expanded later. The length of each expansion is twice the previous length (the size of HashMap is the power of 2)
HashMap default parameters
// Default capacity 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // Maximum capacity static final int MAXIMUM_CAPACITY = 1 << 30; // Default load factor 0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; // The threshold value of the linked list node to the red black tree node, 9 nodes to static final int TREEIFY_THRESHOLD = 8; // The threshold value of red black tree node conversion linked list node, and 6 nodes are converted static final int UNTREEIFY_THRESHOLD = 6; // Minimum length of table when converting to red black tree static final int MIN_TREEIFY_CAPACITY = 64;
Node node
// Linked list node, inherited from Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// Hash value, which is used to compare with hash values of other elements when storing elements in hashmap
final K key;//key
V value;//value
// Point to next node
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// Override hashCode() method
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// Override the equals() method
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
Number node
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // father
TreeNode<K,V> left; // Left
TreeNode<K,V> right; // right
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // Judge color
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// Return root node
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
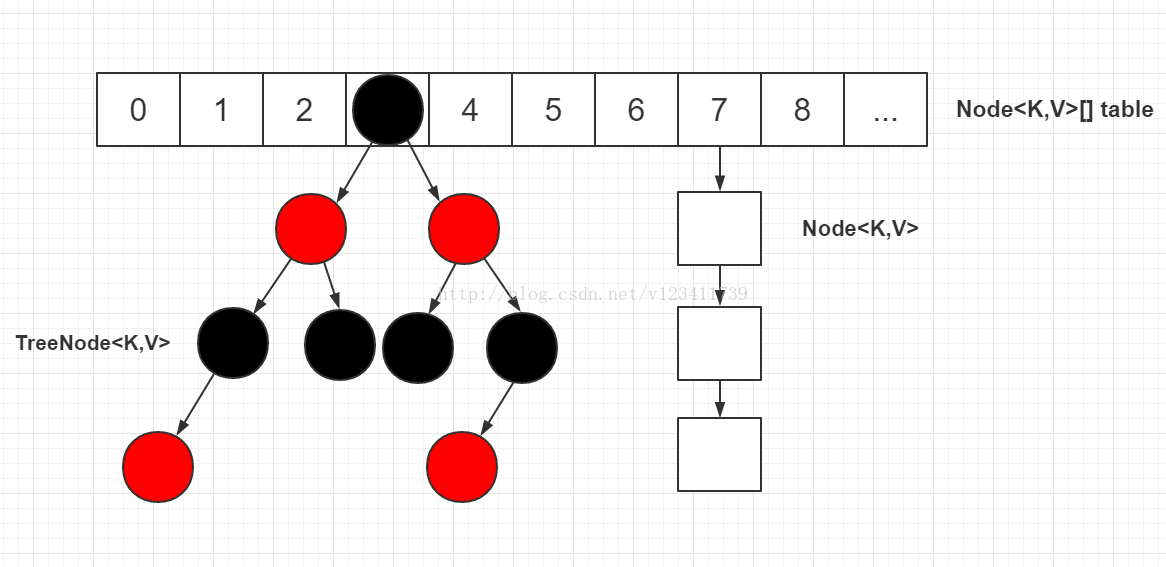
Underlying storage structure
In jdk1 Before 8, the hash linked list formed by array and linked list was used at the bottom of HashMap

During storage, HashMap obtains the hash value of the key. After taking the module to obtain the storage location, judge whether there is an element in the current location. If there is no element, store the element,
If there are elements in the current position, judge whether the hash values of the two elements are equal. If they are equal, they directly overwrite the elements in the HashMap. If the hash values are not equal, the zipper method is used to solve the conflict and form a synonym list
Zipper method:
The so-called "zipper method" is to combine linked list and array. In other words, create a linked list array, and each cell in the array is a linked list. If hash conflicts are encountered, the conflicting values can be added to the linked list.
JDK1. After 8, HashMap introduces a red black tree for element storage to improve query efficiency. When the length of a location synonym list is greater than 8, HashMap will turn the list into a red black tree for storage
Differences between HashMap and hashTable
HashMap allows null key and value, but Hashtable does not.
The default initial capacity of HashMap is 16 and Hashtable is 11.
The capacity expansion of HashMap is twice the original, and the capacity expansion of Hashtable is twice the original plus 1.
HashMap is non thread safe and Hashtable is thread safe.
The hash value of HashMap is recalculated, and Hashtable directly uses hashCode.
HashMap removes the contains method in Hashtable.
HashMap inherits from AbstractMap class and Hashtable inherits from Dictionary class.
Internal source code
Construction method
Default parameterless construction
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
Contains another Map
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// Determine whether the table has been initialized
if (table == null) { // pre-size
// Uninitialized, s is the actual number of elements of m
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// If the calculated t is greater than the threshold, the threshold is initialized
if (t > threshold)
threshold = tableSizeFor(t);
}
// It has been initialized and the number of m elements is greater than the threshold value. Capacity expansion is required
else if (s > threshold)
resize();
// Add all elements in m to HashMap
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
Set initialization length
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
Set initial length and load factor
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) //Parameter judgment
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) //Load factor judgment
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
put(K key, V value)
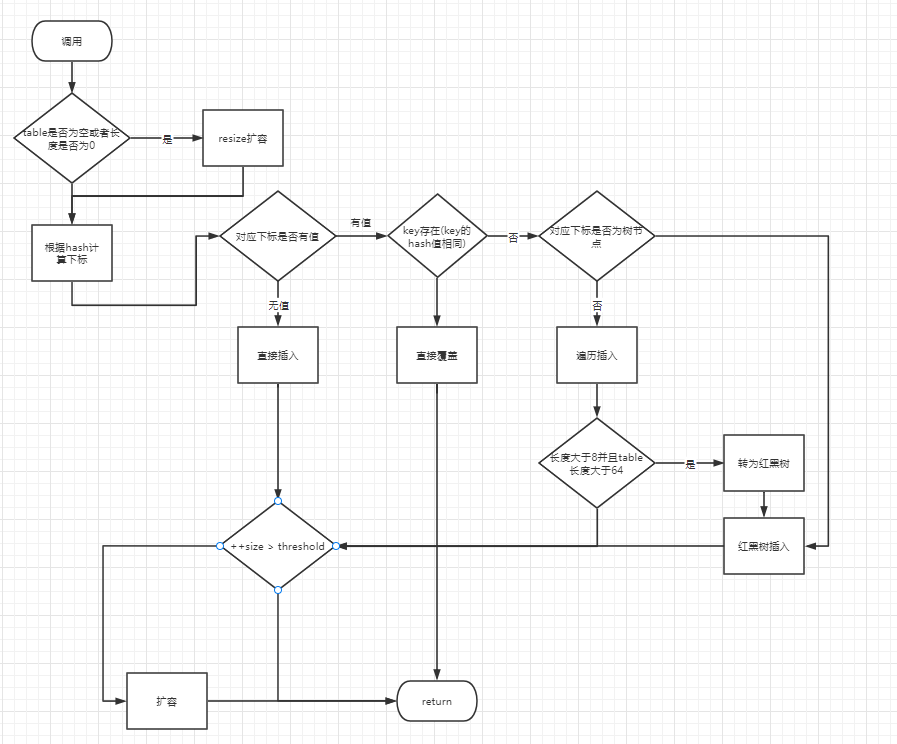
The put(K key,V value) method is the only addition method provided by HashMap. The other method putVal is a method called by the put method and is not provided to users
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
putVal judgment process
get(K key)
The get(Object key) method returns the corresponding value according to the specified key value. This method calls getEntry(Object key) to get the corresponding entry, and then returns entry getValue(). Therefore, getEntry() is the core of the algorithm. The idea of the algorithm is to get the subscript of the corresponding bucket through the hash() function, and then traverse the conflict linked list in turn through the key The equals (k) method to determine whether it is the entry you are looking for.
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Array elements are equal
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// More than one node in bucket
if ((e = first.next) != null) {
// get in tree
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// get in linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
resize() capacity expansion method
The resize() method is used to initialize the array or expand the capacity of the array. After each expansion, the capacity is twice that of the original and the data is migrated
Because capacity expansion will cause hash reallocation and traverse all elements, it will take a lot of time
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// If the maximum value is exceeded, it will not be expanded
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// If the maximum value is not exceeded, it will be expanded to twice the original value
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// Calculate the new resize upper limit
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Move each bucket to a new bucket
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Original index
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Original index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Put the original index into the bucket
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Put the original index + oldCap into the bucket
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}