Storage structure - fields
// Hash bucket is used to store linked lists // Initialize when first used instead of when defined. The length is 2^n transient Node<K,V>[] table; // Save cached entrySet transient Set<Map.Entry<K,V>> entrySet; // Number of key value pairs owned by the current map transient int size; // Record the number of times the internal structure of Hash Map has been changed (e.g. re hashing) for concurrent exceptions transient int modCount; // threshold int threshold; // Load factor final float loadFactor;
1. Construction method
// Construction method
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// The maximum initial capacity shall not exceed 2 ^ 30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// Set the threshold and find the exponential power of 2 > = initialCapacity
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
The construction method in HashMap has four overloads, which are responsible for initializing three parameters
-
initialCapacity initial capacity (default 16)
The bottom layer of HashMap is realized by array + linked list (turn to red black tree when it exceeds 8), and the initial capacity represents the initial size of the array;
-
loadFactor load factor (default 0.75)
loadFactor = number of currently loaded elements / total capacity, used to calculate the maximum load of hashmap;
-
Threshold threshold
The maximum number of key value pairs that can be accommodated by HashMap. If it exceeds, it needs to be expanded. The calculation method = initialCapacity * loadFactor;
Here is an interesting method, tableSizeFor(), which uses the bit operation of unsigned right shift to round the initial capacity up to the exponential power of 2 (for example, enter 10 and return 2 ^ 4 = 16) Here's a good analysis
2. New method
There are two new methods in hashmap:
-
put(K key, V value)
Most commonly, the bottom layer directly calls the putval function below
-
putMapEntries(Map<? extends K, ? extends V> m, boolean evict)
The bottom layer of this method also calls putVal()
There are three main calls to this method:
- When initializing a map with another map
- putAll()
- clone()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. If the hash table is not initialized, initialize it first
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2.1 the hash algorithm finds the corresponding bucket. If there is no data in the bucket, the data will be directly added to the bucket
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 2.2 the hash algorithm finds the corresponding bucket. If there is data in the bucket, hash collision occurs
else {
Node<K,V> e; K k;
// 3.1 the same key already exists. Handle it uniformly in step 4
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 3.2 the linked list in the bucket has been converted to a red black tree, and the red black tree is directly used for insertion
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 3.3 the bucket is inserted after traversing the linked list backward to find a null value
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// If the length of the linked list exceeds the treelization threshold, the linked list will be transformed into a red black tree
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// If the same key already exists, handle it uniformly in step 4
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 4. If e is not empty, it means that the newly inserted key already exists in the original hash bucket, and the original key value pair can be updated
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// If size > threshold after insertion, expand the capacity
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
🚀 3. Implementation of capacity expansion mechanism
In the new process, a key function called resize() is called, which has two main functions.
- Initialize the hash bucket size when HashMap is not initialized
- Expand (double) hash bucket size

Resizing is to recalculate the capacity and constantly add elements to the HashMap object. When the length of the array inside the HashMap object is greater than default_ LOAD_ FACTOR * DEFAULT_ INITIAL_ For capability, HashMap needs to expand the length of the array so that more elements can be loaded. The method is to use a new array to replace the existing array with small capacity, and then transfer all the data in the original array to the new array.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// Calculate the capacity after expansion
if (oldCap > 0) {
// If the current capacity has exceeded the maximum capacity, the current hash bucket will not be returned during capacity expansion
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// If the current Map is uninitialized (oldCap=0) but the threshold is not empty, it indicates that the capacity and threshold are specified during definition
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// If the current Map is uninitialized (oldCap=0) and the threshold value is empty, it means that the default value is not specified during initialization
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// If the threshold is not set, the map is uninitialized, but the capacity and threshold have specified values
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// ===========Capacity expansion: transfer all nodes in the current hash bucket to the new hash bucket===========
if (oldTab != null) {
// Move each bucket to a new bucket
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// Release the object reference in the old array
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// Rehash process: linked list optimization rehash code block
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Original index: the hash bucket is distinguished according to whether the hash value added after capacity expansion is 0 or 1
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Original index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Put the original index into the bucket
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Put the original index + oldCap into the bucket
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Optimization of JDK1.8
In JDK1.7, the resize process adopts the header insertion method. The specific process can be found through this Code: e.next = newTable[i]; Assigning the value of the original array to the next of the new node can prove to be a header insertion method, which also leads to the inversion of the relative position of the data in each bucket when resizing each expansion;
See the following figure for specific operation:

JDK1.8 makes many optimizations in the capacity expansion function. Since each capacity expansion is a power-2 expansion, the position of each element after capacity expansion is in the original hash bucket or the original hash bucket + 2^n-1 (i.e. the original index + the length of the original hash bucket)
According to the above properties, we can determine whether the new hash bucket is 0 or 1 according to the new bit of the hash value (for example, the last 1-bit hash value is used to locate before capacity expansion, and the last 2-bit hash value is used to locate after capacity expansion). If it is 0, the index remains unchanged, and if it is 1, the index becomes "original index+oldCap", Instead of recalculating the hash value every time according to the new capacity after capacity expansion, as in JDK1.7;
At the same time, the resize of JDK1.8 also avoids the change of the relative position of data
Thread safety
In the multithreading scenario, try to avoid using thread unsafe HashMap, and use thread safe ConcurrentHashMap, or wrap it with Collections.synchronizedMap(new HashMap(...));
The main problem of thread insecurity in JDK1.7 is that the reverse insertion method is used during capacity expansion, and dead cycles may occur during concurrency, resulting in 100% CPU occupation. However, JDK1.8 uses two linked lists to operate separately, ensuring that the linked list is inserted in sequence when it is inserted into the Map to avoid dead cycles;
The specific causes in JDK1.7 are analyzed as follows (transferred from Left ear mouse (my blog)
1. There are two concurrent threads
The core function of resize in JDK1.7 is used to transfer data from the old hash bucket to the new hash bucket
do {
Entry<K,V> next = e.next; // < -- suppose that the thread is suspended by scheduling as soon as it executes here
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
The execution of thread 1 is suspended at the above code, and the execution of thread 2 is completed. Therefore, there are the following situations, and the hash table in thread 2 is expanded:

Note that e of Thread1 points to key(3) and next points to key(7). After rehash of thread 2, it points to the list reorganized by thread 2. We can see that the order of the linked list is reversed.
2. The thread is scheduled for execution
- First, execute newTalbe[i] = e; (the pointer of hash bucket index=3 points to key3)
- Then e = next, resulting in e pointing to key(7),
- next = e.next in the next cycle causes next to point to key(3)

3. Everything is fine
The thread continues to work. Take off the key(7), put it in the first one of the newTable[i], and then move e and next down.
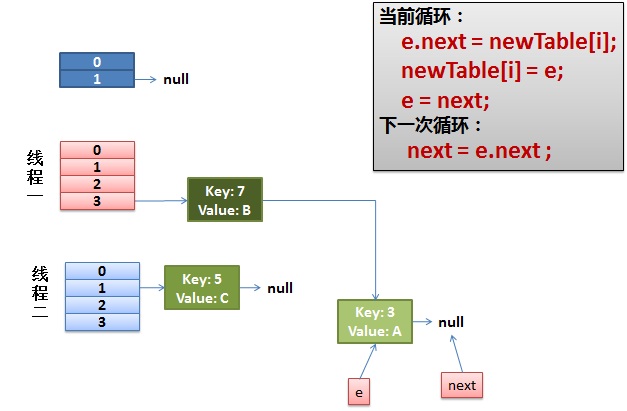
4. Infinite Loop appears in the ring link
e.next = newTable[i] causes key(3).next points to key(7)
Note: at this time, the key(7).next has pointed to key(3), and the ring linked list appears.

Therefore, as soon as our thread is scheduled to HashMap.get(11) again, we will encounter Infinite Loop again
4. Find
The search and deletion logic are similar and relatively simple. The following only takes the search as an example to show the source code and comments;
Some common search related API s are implemented with the following functions: eg: get(), containsKey()
// The hash value of the incoming key and the target key
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
// 1. Find the first data in the corresponding hash bucket according to the hash algorithm
(first = tab[(n - 1) & hash]) != null) {
// 2. Judge whether it is the specified key. If it is a key, return directly
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 3. The header node is not found, indicating that it is in the subsequent nodes of the header node
if ((e = first.next) != null) {
// 3.1 if it has been converted to a red black tree, search through the tree
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 3.2 if it is a linked list traversal search
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Recommended reading: