The official account of WeChat: Java essays
Follow to learn more about Java related technology sharing. Questions or suggestions, welcome to the official account message!
Introduction to HashMap
HashMap is mainly used to store key value pairs. It is implemented based on the Map interface of hash table. It is one of the commonly used Java collections.
JDK1. Before 8, HashMap was composed of array + linked list. Array is the main body of HashMap, and linked list mainly exists to solve hash conflict ("zipper method" to solve conflict).
JDK1. After the hash8 tree is black, it will speed up the search of the following two red trees.
- The length of the linked list is greater than the threshold (8 by default)
- HashMap array length exceeds 64
Analysis of underlying data structure
JDK1. Before 8
JDK1. Before 8, the bottom layer of HashMap was the combination of array and linked list, that is, linked list hash.
HashMap obtains the hash value through the hashCode of the key after being processed by the perturbation function, and then judges the storage position of the current element through (n - 1) & hash (where n refers to the length of the array). If there is an element in the current position, judge whether the hash value and key of the element to be stored are the same. If they are the same, they are directly overwritten, If it is not the same, resolve the conflict through the zipper method.
The so-called perturbation function refers to the hash method of HashMap. The hash method, that is, the perturbation function, is used to prevent some poorly implemented hashCode() methods. In other words, the collision can be reduced after using the perturbation function.
Source code of hash method of JDK 1.8 HashMap:
The hash method of JDK 1.8 is simpler than that of JDK 1.7, but the principle remains the same.
static final int hash(Object key) {
int h;
// key.hashCode(): returns the hash value, that is, hashcode
// ^: bitwise XOR
// >>>: move the unsigned right, ignore the sign bit, and fill up the empty bits with 0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Compare jdk1 7 HashMap hash method source code
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Compared with jdk1 The performance of 8 hash method and JDK 1.7 hash method will be slightly worse, because it has been disturbed for 4 times after all.
The so-called "zipper method" is to combine linked list and array. In other words, create a linked list array, and each cell in the array is a linked list. If hash conflicts are encountered, the conflicting values can be added to the linked list.
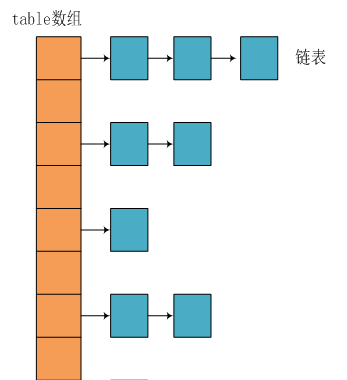
JDK1. After 8
Compared with previous versions, jdk1 After 8, there are great changes in resolving hash conflicts.
When the length of the linked list is greater than the threshold (8 by default), the treeifyBin() method will be called first. This method will determine whether to convert to red black tree according to HashMap array. Only when the array length is greater than or equal to 64, the operation of converting red black tree will be performed to reduce the search time. Otherwise, you just execute the resize() method to expand the capacity of the array. The relevant source code will not be posted here. Just focus on the treeifyBin() method!
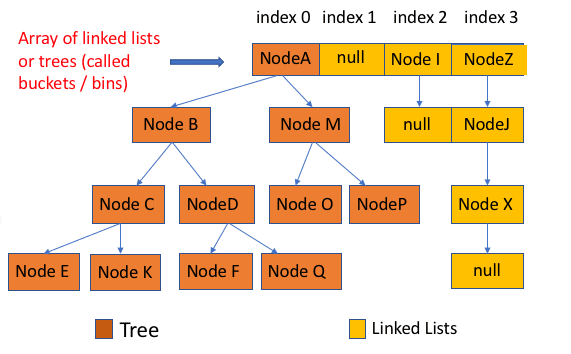
Properties of class:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// serial number
private static final long serialVersionUID = 362498820763181265L;
// The default initial capacity is 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// Maximum capacity
static final int MAXIMUM_CAPACITY = 1 << 30;
// Default fill factor
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// When the number of nodes on the bucket is greater than this value, it will turn into a red black tree
static final int TREEIFY_THRESHOLD = 8;
// When the number of nodes on the bucket is less than this value, the tree turns to the linked list
static final int UNTREEIFY_THRESHOLD = 6;
// The structure in the bucket is transformed into the minimum size of the table corresponding to the red black tree
static final int MIN_TREEIFY_CAPACITY = 64;
// An array of storage elements is always a power of 2
transient Node<k,v>[] table;
// A set that holds concrete elements
transient Set<map.entry<k,v>> entrySet;
// The number of stored elements. Note that this is not equal to the length of the array.
transient int size;
// Counter for each expansion and change of map structure
transient int modCount;
// Critical value when the actual size (capacity * filling factor) exceeds the critical value, capacity expansion will be carried out
int threshold;
// Loading factor
final float loadFactor;
}
-
loadFactor
The loadFactor loading factor controls the density of the data stored in the array. The closer the loadFactor is to 1, the more data (entries) stored in the array will be, the more dense it will be, that is, it will increase the length of the linked list. The smaller the loadFactor is, that is, it will approach 0, the less data (entries) stored in the array will be, and the more sparse it will be.
Too large loadFactor leads to low efficiency in finding elements, too small leads to low utilization of arrays, and the stored data will be very scattered. The default value of loadFactor is 0.75f, which is a good critical value officially given.
The given default capacity is 16 and the load factor is 0.75. During the use of Map, data is constantly stored in it. When the number reaches 16 * 0.75 = 12, the capacity of the current 16 needs to be expanded. This process involves rehash, copying data and other operations, so it consumes a lot of performance.
-
threshold
threshold = capacity * loadFactor. When size > = threshold, the expansion of the array should be considered. In other words, this means a standard to measure whether the array needs to be expanded.
Node class source code:
// Inherited from map Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// Hash value, which is used to compare with the hash value of other elements when storing elements in hashmap
final K key;//key
V value;//value
// Point to next node
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// Override hashCode() method
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// Override the equals() method
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
Tree node class source code:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // father
TreeNode<K,V> left; // Left
TreeNode<K,V> right; // right
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // Judge color
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// Return root node
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
HashMap source code analysis
Construction method
There are four construction methods in HashMap, which are as follows:
// Default constructor.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// Constructor containing another "Map"
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//This method will be analyzed below
}
// Specifies the constructor for the capacity size
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// Specifies the constructor for capacity size and load factor
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
putMapEntries method:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// Determine whether the table has been initialized
if (table == null) { // pre-size
// Uninitialized, s is the actual number of elements of m
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// If the calculated t is greater than the threshold, the threshold is initialized
if (t > threshold)
threshold = tableSizeFor(t);
}
// It has been initialized and the number of m elements is greater than the threshold. Capacity expansion is required
else if (s > threshold)
resize();
// Add all elements in m to HashMap
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
put method
HashMap only provides put for adding elements, and putVal method is only a method called for put method, which is not provided to users.
The analysis of the elements added to putVal method is as follows:
- If there is no element in the array position, it will be inserted directly.
- If there are elements in the array position, compare it with the key to be inserted. If the keys are the same, directly overwrite it. If the keys are different, judge whether p is a tree node. If so, call e = ((treenode < K, V >) p) Puttreeval (this, tab, hash, key, value) adds elements to the. If not, traverse the linked list (insert the tail of the linked list).
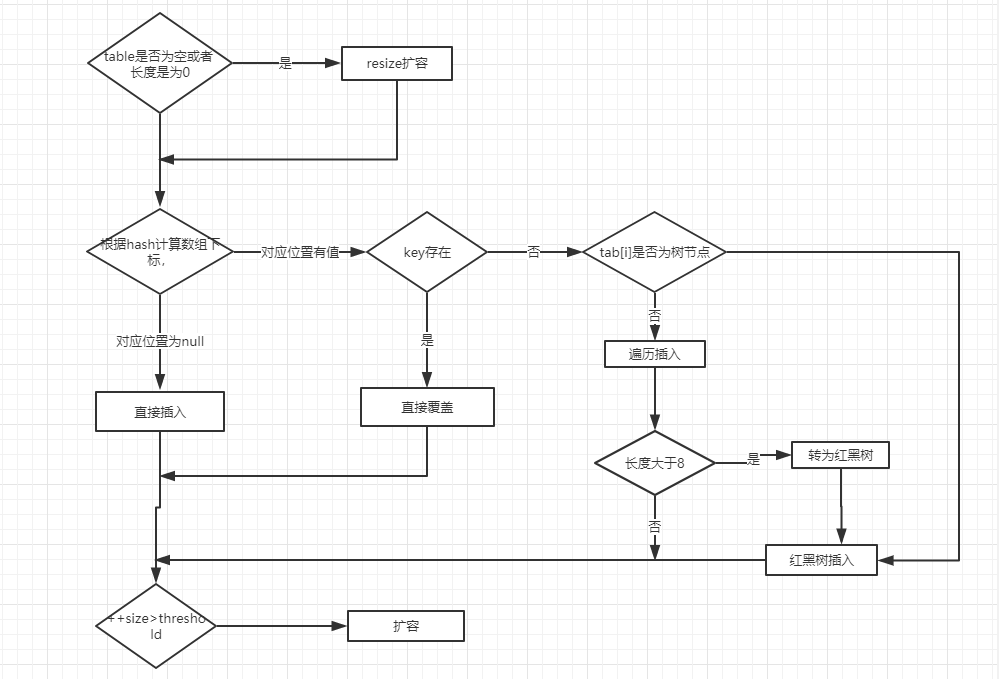
Note: there are two small problems in the figure above:
- After direct overwrite, you should return. There will be no subsequent operation. Refer to jdk8 HashMap Java 658 lines( issue#608).
- When the length of the linked list is greater than the threshold (8 by default) and the length of the HashMap array exceeds 64, the operation of converting the linked list to red black tree will be executed. Otherwise, it will only expand the capacity of the array. Refer to the treeifyBin() method of HashMap( issue#1087).
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// The table is uninitialized or its length is 0, so it needs to be expanded
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash determines the bucket in which the element is stored. The bucket is empty, and the newly generated node is put into the bucket (at this time, this node is placed in the array)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// Element already exists in bucket
else {
Node<K,V> e; K k;
// The hash value of the first element (node in the array) in the comparison bucket is equal, and the key is equal
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// Assign the first element to e and record it with E
e = p;
// The hash values are not equal, that is, the key s are not equal; Red black tree node
else if (p instanceof TreeNode)
// Put it in the tree
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// Is a linked list node
else {
// Insert a node at the end of the linked list
for (int binCount = 0; ; ++binCount) {
// Reach the end of the linked list
if ((e = p.next) == null) {
// Insert a new node at the end
p.next = newNode(hash, key, value, null);
// When the number of nodes reaches the threshold (8 by default), execute the treeifyBin method
// This method will determine whether to convert to red black tree according to HashMap array.
// Only when the array length is greater than or equal to 64, the operation of converting red black tree will be performed to reduce the search time. Otherwise, it is just an expansion of the array.
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// Jump out of loop
break;
}
// Judge whether the key value of the node in the linked list is equal to the key value of the inserted element
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// Equal, jump out of loop
break;
// Used to traverse the linked list in the bucket. Combined with the previous e = p.next, you can traverse the linked list
p = e;
}
}
// Indicates that a node whose key value and hash value are equal to the inserted element is found in the bucket
if (e != null) {
// Record the value of e
V oldValue = e.value;
// onlyIfAbsent is false or the old value is null
if (!onlyIfAbsent || oldValue == null)
//Replace old value with new value
e.value = value;
// Post access callback
afterNodeAccess(e);
// Return old value
return oldValue;
}
}
// Structural modification
++modCount;
// If the actual size is greater than the threshold, the capacity will be expanded
if (++size > threshold)
resize();
// Post insert callback
afterNodeInsertion(evict);
return null;
}
Let's compare jdk1 7 code of put method
The analysis of put method is as follows:
- ① If there is no element in the array position, it will be inserted directly.
- ② If there is an element in the location of the array, traverse the linked list with this element as the header node, and compare it with the inserted key in turn. If the key is the same, it will be directly overwritten. If it is different, the header insertion method will be used to insert the element.
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // First traverse
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // Reinsert
return null;
}
get method
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Array elements are equal
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// More than one node in bucket
if ((e = first.next) != null) {
// get in the tree
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// get in linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
resize method
Capacity expansion will be accompanied by a re hash allocation, and all elements in the hash table will be traversed, which is very time-consuming. When writing programs, try to avoid resize.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// If you exceed the maximum value, you won't expand any more, so you have to collide with you
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// If the maximum value is not exceeded, it will be expanded to twice the original value
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// Calculate the new resize upper limit
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Move each bucket to a new bucket
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Original index
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Original index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Put the original index into the bucket
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Put the original index + oldCap into the bucket
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap common method test
package map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
// The key cannot be repeated, and the value can be repeated
map.put("san", "Zhang San");
map.put("si", "Li Si");
map.put("wu", "Wang Wu");
map.put("wang", "Lao Wang");
map.put("wang", "Lao Wang 2");// Lao Wang is covered
map.put("lao", "Lao Wang");
System.out.println("-------Direct output hashmap:-------");
System.out.println(map);
/**
* Traverse HashMap
*/
// 1. Get all keys in the Map
System.out.println("-------foreach obtain Map All keys in:------");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.print(key+" ");
}
System.out.println();//Line feed
// Get all values in Map 2
System.out.println("-------foreach obtain Map All values in:------");
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value+" ");
}
System.out.println();//Line feed
// 3. Get the value of the key and the corresponding value of the key at the same time
System.out.println("-------obtain key At the same time key Corresponding value:-------");
Set<String> keys2 = map.keySet();
for (String key : keys2) {
System.out.print(key + ": " + map.get(key)+" ");
}
/**
* This is recommended if you want to traverse both key and value, because if you get the keySet first and then execute the map Get (key). The map will be traversed twice.
* One is to get the keySet and the other is to traverse all keys.
*/
// When I call the put(key,value) method, I will first encapsulate the key and value into
// The Entry object is a static internal class object, and the Entry object is added to the array, so we want to get
// For all key value pairs in the map, we just need to get all Entry objects in the array, and then
// The key value pairs can be obtained by calling the getKey() and getValue() methods in the Entry object
Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
/**
* HashMap Other common methods
*/
System.out.println("after map.size(): "+map.size());
System.out.println("after map.isEmpty(): "+map.isEmpty());
System.out.println(map.remove("san"));
System.out.println("after map.remove(): "+map);
System.out.println("after map.get(si): "+map.get("si"));
System.out.println("after map.containsKey(si): "+map.containsKey("si"));
System.out.println("after containsValue(Li Si): "+map.containsValue("Li Si"));
System.out.println(map.replace("si", "Li Si 2"));
System.out.println("after map.replace(si, Li Si 2):"+map);
}
}
official account
- Pay attention to the official account and receive the technology sharing on Java instantly.
