HashMap source code nanny level analysis
Jdk1.0 is used here 7 jdk1. 8 becomes a node node. First analyze 1.7 and then 1.8
1, What is a hash table
hash table
It is a very important data structure with rich application scenarios. The core of many caching technologies (such as memcached) is to maintain a large hash table in memory. This paper will explain the implementation principle of HashMap in java collection framework and analyze the HashMap source code of JDK7.
1. Hash collision:
Hash an element to get a storage address. When inserting, it is found that it has been occupied by other elements. In fact, this is the so-called hash conflict, also known as hash collision
2. Solution:
Array + linked list
2, Implementation principle of HashMap
1.hashmap skeleton: power Entry object array of 2
The backbone of HashMap is an entry array. Entry is the basic unit of HashMap. Each entry contains a key value pair. (in fact, the so-called Map is actually a collection that saves the mapping relationship between two objects)
/** The trunk is a power of Entry array 2 * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry is a HashMap static inner class object in HashMap. The code is as follows
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//Store the reference to the next Entry, single linked list structure
int hash;//The value obtained by hashing the hashcode value of the key is stored in the Entry to avoid repeated calculation
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
Several other important fields
/**Number of key value pairs actually stored*/
transient int size;
/**Threshold value. When table = = {}, this value is the initial capacity (the default is 16); When the table is filled, that is, after allocating memory space for the table,
threshold Generally, it is capacity*loadFactory. HashMap needs to refer to threshold when expanding capacity, which will be discussed in detail later*/
int threshold;
/**The load factor represents the filling degree of the table. The default is 0.75 In order to reduce the collision, the collision probability is lower
The reason for the existence of the load factor is to slow down the hash conflict. If the initial bucket is 16 and the capacity is expanded only when it is full of 16 elements, there may be more than one element in some buckets.
Therefore, the loading factor is 0.75 by default, that is, the HashMap with a size of 16 will expand to 32 when it reaches the 13th element.
Once the capacity is expanded, it is doubled cloning. The default is 16 and the load factor is 0.75, which will be expanded to 32 and then 64
*/
final float loadFactor;
/**HashMap The number of times changed. Because HashMap is not thread safe, when iterating over HashMap,
If the participation of other threads causes the structure of HashMap to change (such as put, remove and other operations),
The exception ConcurrentModificationException needs to be thrown*/
It can be considered hashmap Version number, a little cas What do you mean
transient int modCount;
Construct an empty HashMap with the specified initial capacity and default load factor (0.75)
public HashMap(int initialCapacity, float loadFactor) {
//The incoming initial capacity is verified here. The maximum capacity cannot exceed maximum_ CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//The init method is not actually implemented in HashMap, but there will be a corresponding implementation in its subclass, such as linkedHashMap
}
2.put(): allocate memory space
From the above code, we can see that in the conventional constructor, there is no memory space allocated for the array table (except for the constructor whose input parameter is the specified Map), but the table array is really constructed when the put operation is executed
public V put(K key, V value) {
//If the table array is an empty array {}, fill the array (allocate the actual memory space for the table), and the input parameter is threshold,
//At this time, the threshold is initialCapacity, and the default is 1 < < 4 (24 = 16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//If the key is null, the storage location is on the conflict chain of table[0] or table[0]
if (key == null)
return putForNullKey(value);
int hash = hash(key);//The hashcode of the key is further calculated to ensure uniform hash
int i = indexFor(hash, table.length);//Gets the actual location in the table
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//If the corresponding data already exists, perform the overwrite operation. Replace the old value with the new value and return the old value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//When ensuring concurrent access, if the internal structure of HashMap changes, the rapid response fails
addEntry(hash, key, value, i);//Add an entry
return null;
}
① The inflateTable() method allocates storage space
This method is used to allocate storage space in memory for the backbone array table. Through roundUpToPowerOf2(toSize), you can ensure that the capacity is greater than or equal to the nearest quadratic power of toSize. For example, if toSize=13, then capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacity must be a power of 2
/**Here is the value of threshold, taking capacity*loadFactor and maximum_ Minimum value of capability + 1,
capaticy It must not exceed maximum_ Capability, unless loadFactor is greater than 1 */
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
After initialization:
threshold: 12
table: 16
② hash Function: ensure uniform distribution of storage locations
Note: if the key is null, the conflict chain where the storage location is table[0] or table[0] is the first location. The null hash value is considered as 0
/**This is a magical function, using a lot of XOR, shift and other operations
The hashcode of the key is further calculated and the binary bit is adjusted to ensure that the final storage location is evenly distributed as far as possible*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
③ The actual storage location is obtained through further processing by indexFor
/**
* Return array subscript
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
④ Traverses the linked list of the specified array position, and whether there are old values
Traverse a specific linked list and use next to find the next entry node until the node is null. If the corresponding data already exists, perform the overwrite operation and return the old value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//If the corresponding data already exists, perform the overwrite operation. Replace the old value with the new value and return the old value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
⑤ modCount operation record + 1
modCount++;
⑥ Implementation of addEntry: save the current key value
The current key node does not exist. Add the current key value
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
//When the size exceeds the critical threshold and a hash conflict is about to occur, the capacity is expanded
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
During the first put, the critical threshold is 12 through debugging,
table[bucketIndex] is the insertion position of the table,
size is the number of key value pairs that already exist in the container
Therefore, if the two conditions (the number of key value pairs in the container is greater than or equal to 12) + (the table position inserted by the key value pair is not null) are met, the capacity will be expanded to twice the original
Human talk means that the capacity of key value pairs will be expanded only when they exceed the threshold and hash collision occurs at the same time!!!
When a hash conflict occurs and the size is greater than the threshold, the array needs to be expanded. When expanding, you need to create a new array with a length twice that of the previous array, and then transfer all the elements in the current Entry array. The length of the new array after expansion is twice that of the previous array. Therefore, capacity expansion is a relatively resource consuming operation.
The capacity expansion method here will be analyzed later and the process will continue. After capacity expansion, refresh the hash value and recalculate the bucket index bucketIndex
⑦ createEntry() create node
void createEntry(int hash, K key, V value, int bucketIndex) {
//First, take out the data of the original container location, which may be empty or a linked list
Entry<K,V> e = table[bucketIndex];
//Re assign the value, update the key value hash of the current location to the incoming key value object, and point the next to the data of the original location
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
key = k;
hash = h;
next = n;
}
⑧ resize() analysis
First write your own code and expand it
HashMap hashMap =new HashMap();
hashMap.put("1","lys");
hashMap.put("2","lys");
hashMap.put("3","lys");
hashMap.put("4","lys");
hashMap.put("5","lys");
hashMap.put("6","lys");
hashMap.put("7","lys");
hashMap.put("8","lys");
hashMap.put("9","lys");
hashMap.put("10","lys");
hashMap.put("11","lys");
hashMap.put("12","lys");
hashMap.put("13","lys");
hashMap.put("14","lys");
hashMap.put("15","lys");
hashMap.put("16","lys");
Execute to the capacity expansion breakpoint: it is found that the capacity expansion occurs only when key==15!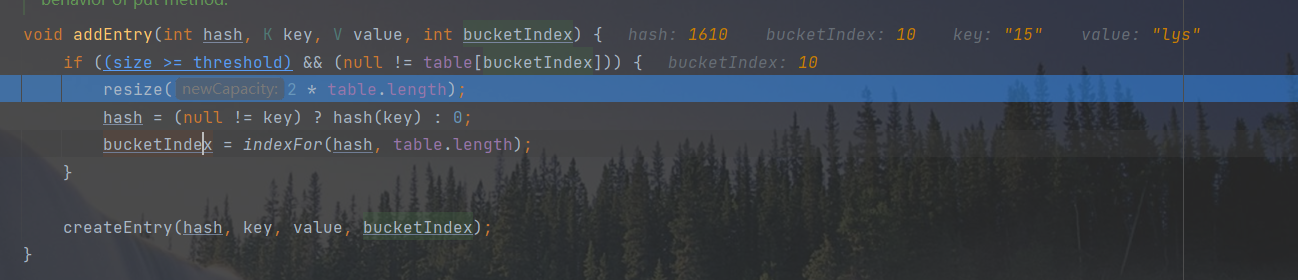
Source code analysis:
The default size is doubled
resize(2 * table.length);
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
If the bucket size is maximum_ CAPACITY = 1 << 30; 2 to the 30th power, the threshold is assigned as integer MAX_ VALUE; That is, the 31st power of 2 minus one
If you talk to others, you won't expand the capacity. Go back directly. The threshold has exceeded the capacity value. After triggering this logic, the linked list of this table will only be longer and longer
Then create a 2x empty ENTRY array, execute the transfer method, and finally recalculate the threshold of the new container
//Transfer all entries from the current table to the new table.
void transfer(Entry[] newTable, boolean rehash) {
//The newCapacity is 32
int newCapacity = newTable.length;
//hashmap array traversal
for (Entry<K,V> e : table) {
while(null != e) {
//First, take out the next element
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//Recalculate bucket index
int i = indexFor(e.hash, newCapacity);
//Point the next chain of the current entry to the new index position. The newTable[i] may be empty or it may also be an entry chain. If it is an entry chain, it is inserted directly at the head of the linked list.
e.next = newTable[i];
//Store the current element in a new container
newTable[i] = e;
//Point e to the next element
e = next;
}
}
}
Conclusion: the outer for traverses the array and the inner while traverses the linked list until next. It's a little coquettish. In essence, it recalculates the bucket index of the elements in the old container and adds it to the expanded container
Here e.next = newTable[i]; It's hard to understand. It took me a long time to understand. Here's a chestnut
For example, when newtable[i] is empty and the first entry element is named e1, the nextEntry of e1 is null
When e2 is also placed in this new table [i], the nextEntry node of e2 is e1
When e3 also puts this newtable, the nextEntry node of e3 is e2,
. . .
In other words, the new value is inserted at the head of the linked list and stored in the array position. The longer the data is, the lower it will be. Suppose the insertion point i==1, draw a graph
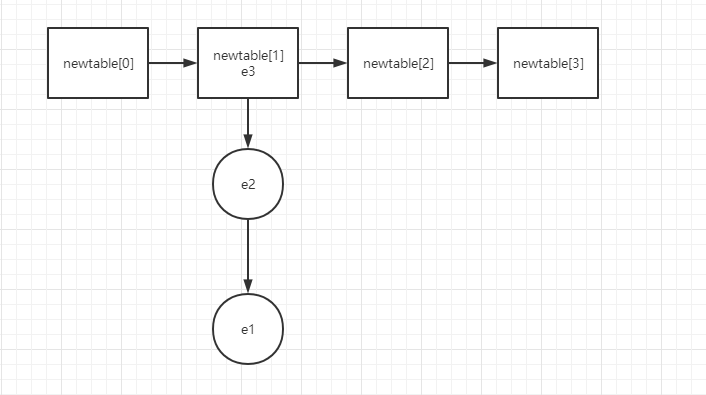
3.get()
public V get(Object key) {
//If the key is null, you can directly go to table[0] to retrieve it.
if (key == null)
return getForNullKey();
//Call the getEntry method to get the entry
Entry<K,V> entry = getEntry(key);
//Returns a value if it is not null
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
//There is no key value pair in the current collection. null is returned
if (size == 0) {
return null;
}
//Calculate the hash value through the hashcode value of the key
int hash = (key == null) ? 0 : hash(key);
//Indexfor (hash & length-1) obtains the final array index, then traverses the linked list and finds the corresponding records through the equals method
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
private V getForNullKey() {
//There is no key value pair in the current collection. null is returned
if (size == 0) {
return null;
}
//Traverse the linked list of table[0], take out the entry with null key value, and return the value value
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4. Questions:
Question 1: why must the array length of HashMap be a power of 2?
Because the length of the supporting array of hashMap is always a power of 2, the low-order data can be as different as possible by moving right, so as to make the distribution of hash values as uniform as possible.
Index = h& (length-1) the data is more evenly distributed, reducing the probability of hash collision
The following two questions still need to be answered after finding a reasonable explanation.
Question 2: why not do modCount + + in the first line of the put () method?
Why modCount + + after each execution;?
For example, when the key value is null, the modCount + + in putForNullKey() method;
modCount + + at the exit of put () method;
Why not do modCount + + on the first line of the put () method?, So I only wrote the code once
A: the current feeling is that there is no need to write more code.
Question 3: why does addEntry judge whether the key is null? Calculated the hash value again?
if (key == null)
return putForNullKey(value);
The null judgment of key value has been made earlier. I don't understand why another judgment is made here?
The hash value algorithm is the same, and the calculated value is the same. Why do you calculate it again? I think it's enough to recalculate the bucket index, because the algorithm for calculating the bucket index is
//The capacity of h: hashcode and length buckets needs to be passed in
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
Because the capacity has changed, it must be recalculated.
A: I don't understand at present.
4.JDK1. Performance optimization of HashMap in 8
What if there is too much data on the chain of an array slot (i.e. the zipper is too long) leading to performance degradation?
JDK1.8 at jdk1 On the basis of 7, the red black tree is added for optimization. That is, when the linked list exceeds 8, the linked list will be transformed into a red black tree. The performance of HashMap will be improved by using the characteristics of rapid addition, deletion, modification and query of red black tree, in which the insertion, deletion, search and other algorithms of red black tree will be used.