preface
HashMap has always been a classic topic that must be asked in the interview. We can't just use it for use. We should also be clear about the underlying principles and possible problems. There are many explanations on HashMap thread safety on the Internet. Why should I talk about this article? Because I want to be more simple and clear. Through my own understanding, this article brings you more clarity and integrity than most articles.
We all know that HashMap solves hash conflicts through zipper method. In case of hash conflicts, key value pairs of the same hash value will be stored in the data through linked list.
Moreover, we all know that HashMap is thread unsafe. It is not recommended to use HashMap in a multi-threaded environment. What is the main manifestation of thread unsafe? Next, this article explains this problem.
It is mainly analyzed from the following four aspects:
- Dead loop caused by capacity expansion under multithreading
- Capacity expansion under multithreading will result in element loss
- When put and get are concurrent, it may cause get to be null
- The code realizes the ring linked list generated by multithreading and the lost data
Dead loop caused by capacity expansion under multithreading
HashMap has been optimized a lot in jdk1.8. Firstly, the problems in jdk1.7 are analyzed. Jdk1.7 uses header insertion to store the linked list, that is, the next conflicting key value pair will be placed in front of the previous key value pair. When the capacity is expanded, it may lead to a ring linked list and cause an endless loop.
Let's use code to simulate the situation of dead loop:
class HashMapThread extends Thread {
private static AtomicInteger ai = new AtomicInteger();
private static Map<Integer, Integer> map = new HashMap<>();
@Override
public void run() {
while (ai.get() < 50000) {
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
}
public class wwwwww {
public static void main(String[] args) throws ParseException {
HashMapThread thread1 = new HashMapThread();
HashMapThread thread2 = new HashMapThread();
HashMapThread thread3 = new HashMapThread();
thread1.start();
thread2.start();
thread3.start();
}
}
Open multiple threads to carry out put operation continuously, and HashMap and AtomicInteger are shared globally. Run the code several times and you will find that there is an dead loop at this time.

Use the jps and jstack commands to check what causes the dead loop. The results are as follows
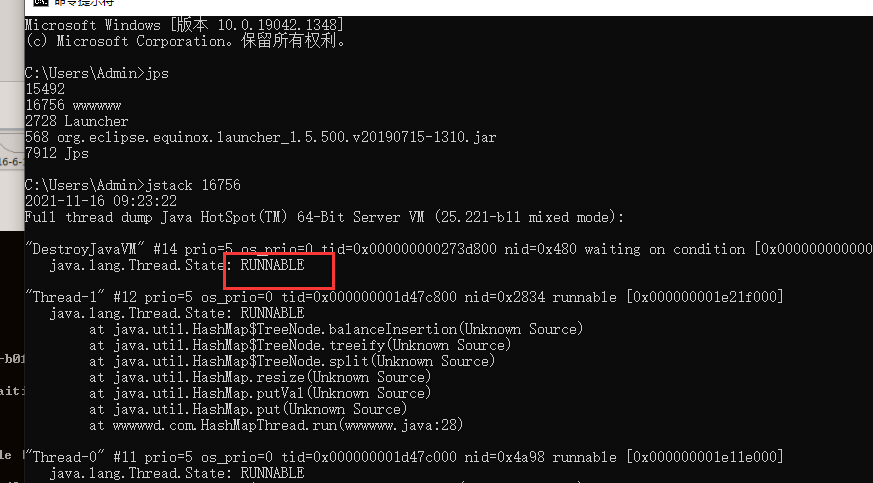
Through the above error message, we can know that the dead cycle occurs in the capacity expansion function of HashMap. The root cause of the problem is in the transfer method, as shown in the following figure:
Source code of resize expansion method:
// newCapacity is to expand new capacity
void resize(int newCapacity) {
// Old array, temporary over
Entry[] oldTable = table;
// Array capacity before capacity expansion
int oldCapacity = oldTable.length;
// MAXIMUM_ Capability is the maximum capacity, the 30th power of 2 = 1 < < 30
if (oldCapacity == MAXIMUM_CAPACITY) {
// The capacity is adjusted to the maximum value of Integer 0x7fffff (hexadecimal) = the 31st power of 2 - 1
threshold = Integer.MAX_VALUE;
return;
}
// Create a new array
Entry[] newTable = new Entry[newCapacity];
// Transfer the data from the old array to the new array
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// Reference new array
table = newTable;
// Recalculate threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
Here, a larger array will be created and transferred through the transfer method to copy the data of the old array to the new array.
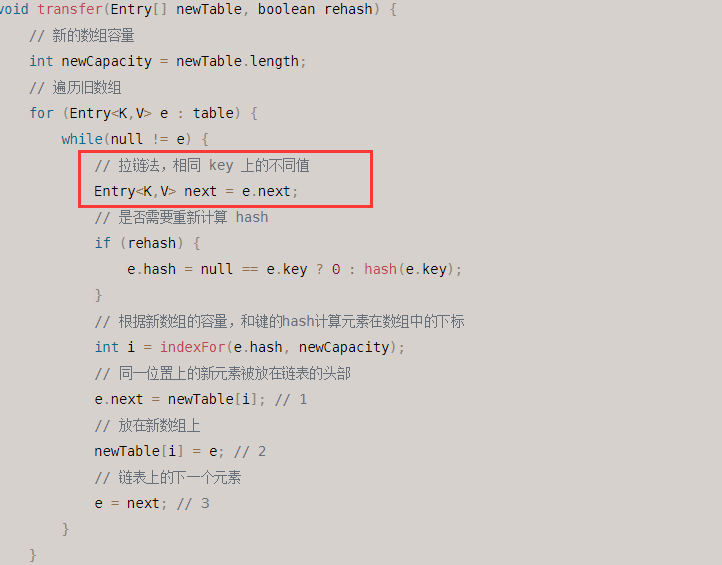
void transfer(Entry[] newTable, boolean rehash) {
// New array capacity
int newCapacity = newTable.length;
// Traverse old array
for (Entry<K,V> e : table) {
while(null != e) {
// Zipper method, different values on the same key
Entry<K,V> next = e.next;
// Need to recalculate hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// Calculate the subscript of the element in the array according to the capacity of the new array and the hash of the key
int i = indexFor(e.hash, newCapacity);
// New elements in the same position are placed at the head of the linked list
e.next = newTable[i]; // 1
// Put on new array
newTable[i] = e; // 2
// The next element on the linked list
e = next; // 3
}
}
}
Mainly pay attention to the marked points 1, 2 and 3. Here, it can be seen that the header insertion method is used in the process of transferring data, and the order of the linked list will be reversed. Here is also the key place to form an endless loop.
Normal expansion process
In the case of single thread, the normal capacity expansion process is as follows:
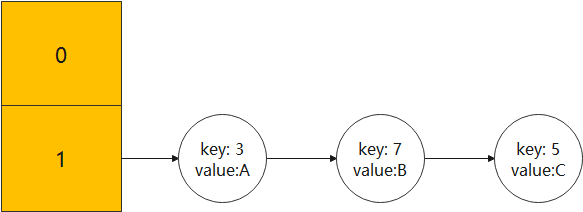
- Suppose our hash algorithm is a simple key mod, which is the size of the table (that is, the length of the array).
- At first, the size=2, key=3,5,7 of the hash table conflict in table[1] after mod 2.
- Next, resize the hash table with size=4, and then all
The process is as follows:
The data structure before capacity expansion is as follows:
The data structure after capacity expansion is as follows:
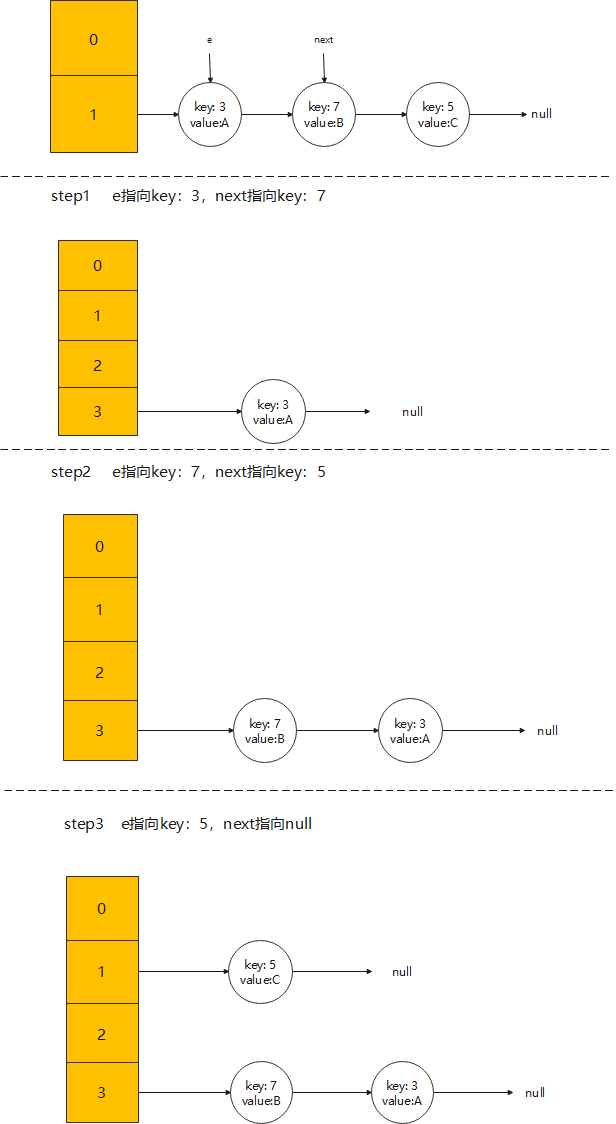
In the single threaded environment, everything seems OK, and the expansion process is quite smooth. Next, let's see what happens in the multi-threaded environment.
Capacity expansion process under multithreading
Suppose that two threads A and B are expanding at the same time. At this time, note in the source code above: entry < K, V > next = e.next; This line of code (key code)
Thread A executes to entry < K, V > next = e.next; This line of thread is suspended, so now in thread A: e = 6; next = 8;

After thread A is suspended, thread B starts to expand the capacity. Assuming that node 6 and node 8 still have hash conflicts in the new array, the capacity expansion process of thread B is as follows:
- Request a space twice the size of the old array

- Migrate node 6 to a new array

- Migrate node 8 to a new array

At this time, the capacity expansion of thread B has been completed, the successor node of node 8 is node 6, and the successor node of node 6 is null.
Next, compare the two arrays:
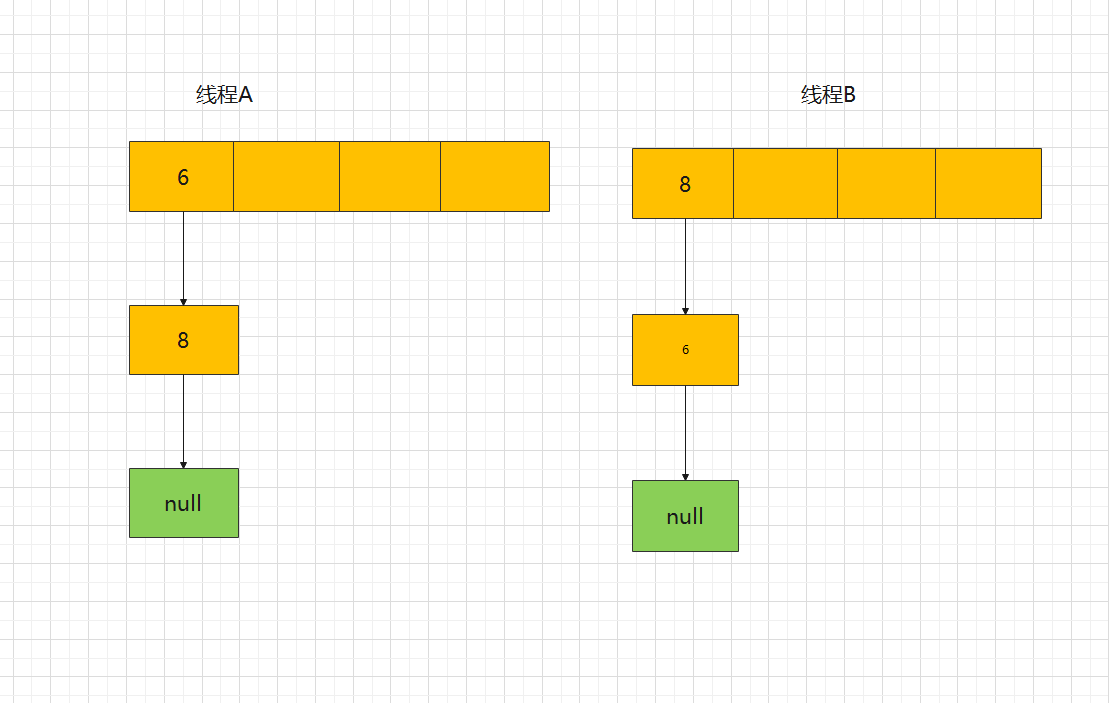
At this time, switch to thread A, and the current state of thread A: e = 6; next = 8, then execute entry < K, V > next = e.next; The following code migrates the node e = 6 to the new array and assigns the node next = 8 to E. After node 6 is expanded and migrated, the results are shown in the following figure:

Then, when executing the while loop for the second time, the current pending node e = 8, and when executing entry < K, V > next = e.next; In this line, since thread B changes the successor node of node 8 to node 6 during capacity expansion, next is not null, but next = 6.
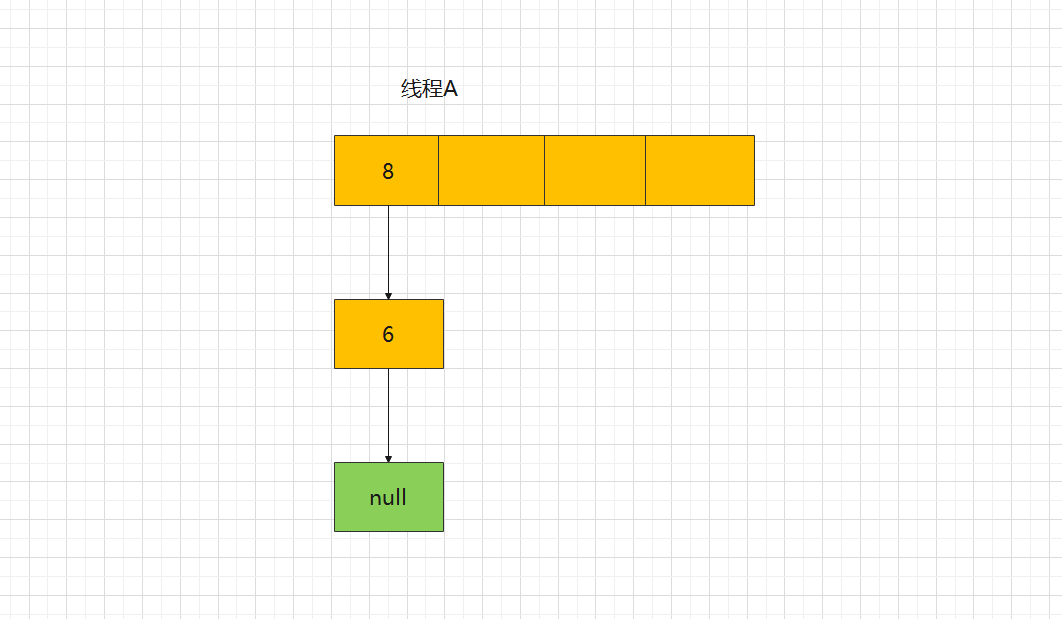
Then execute the third while loop. Since the successor node of node 6 is null, next = null;, After executing the third while loop, the result is: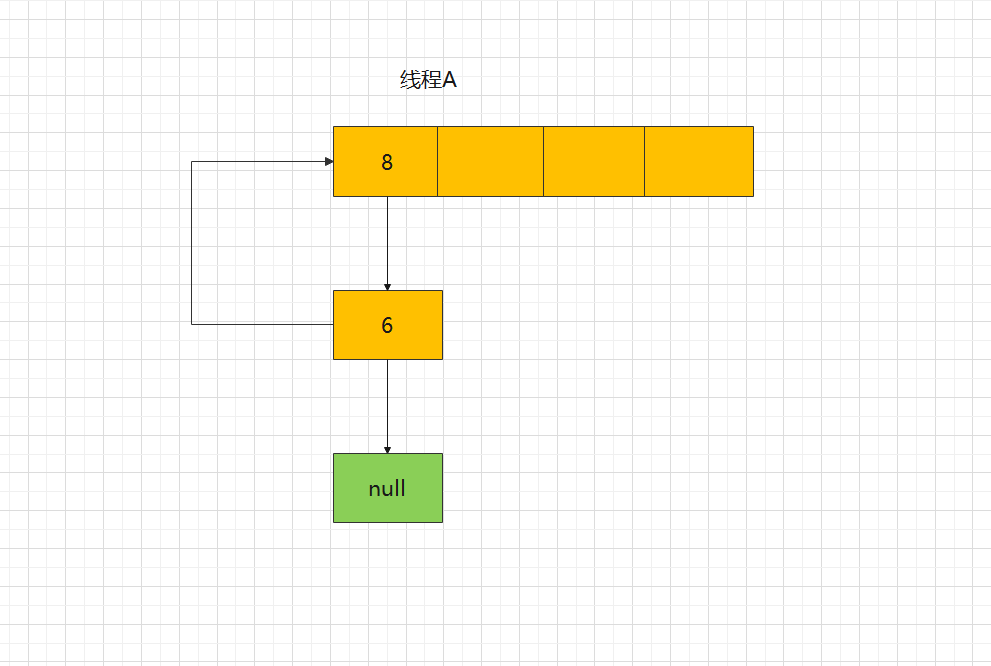
At the end of the loop, you can see that it has become a ring linked list. If you execute the get() method query at this time, it will lead to an endless loop.This problem has been fixed in jdk1.8. The original order of the linked list will be maintained during capacity expansion, so there will be no ring linked list.
Capacity expansion under multithreading will lead to data loss
Thread A and thread B execute the put operation at the same time. If the calculated index position is the same, the previous key will be overwritten by the next key, resulting in the loss of elements.
Next, let's look at some of the source code of the put method in jdk1.8:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //Initialization operation n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // If the hash value and key value of the newly inserted node and the P node in the table are the same, assign the p value to e first if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // Judge if it is a tree node and insert the red black tree else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //Traverse the current linked list for (int binCount = 0; ; ++binCount) { //Judge that if the linked list has only one head node, insert a new node at the end of the linked list with the tail insertion method if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //Judge if the length of the linked list is greater than the threshold 8, turn the linked list into a red black tree if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //If the hash value and key value of the newly inserted node and e node (p.next) are the same, directly jump out of the for loop if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //Find the node with the same key value and consider the new value overwriting the old value if (e != null) { // existing mapping for key V oldValue = e.value; //Judge whether overwrite is allowed and whether value is empty if (!onlyIfAbsent || oldValue == null) e.value = value; //Callback to allow LinkedHashMap post operation afterNodeAccess(e); return oldValue; } } //modCount is the number of operations ++modCount; //Judge whether to expand the array if the size is greater than the threshold if (++size > threshold) resize(); //Callback to allow LinkedHashMap post operation afterNodeInsertion(evict); return null; }Focus on the two codes here:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);Under normal conditions, after thread A and thread B execute the put method, the status of the table is as follows:
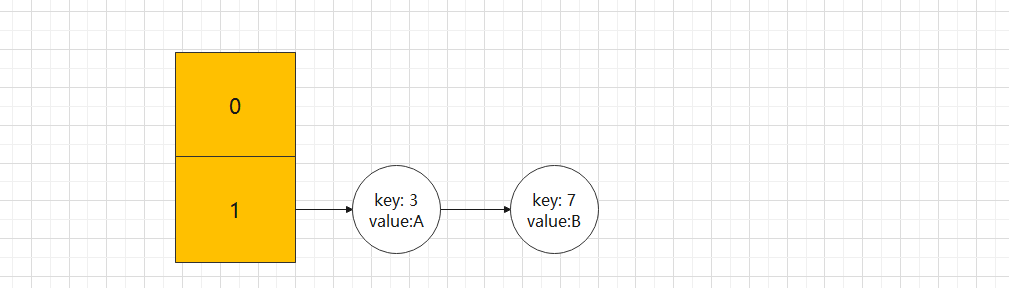
Now both threads execute the if ((P = tab [i = (n - 1) & hash]) = = null) code. Suppose thread A executes ab[i] = newNode(hash, key, value, null) first; In this code, the status of table is shown as follows:

Next, thread B executes tab[i] = newNode(hash, key, value, null). The status of the table is as follows:
Element 3 is missing after execution.When put and get are concurrent, it may cause get to be null
When thread A executes put, the number of elements exceeds the threshold value. Thread B executes get at this time, which may lead to this problem.
Next, let's look at some of the source code of the resize method in jdk1.8:
final Node<K,V>[] resize() { //Old array Node<K,V>[] oldTab = table; //Old array capacity / length int oldCap = (oldTab == null) ? 0 : oldTab.length; //Old array expansion threshold int oldThr = threshold; //New array capacity and new array expansion threshold int newCap, newThr = 0; //If the old array capacity is greater than 0 if (oldCap > 0) { //If the capacity of the old array is greater than or equal to the maximum capacity if (oldCap >= MAXIMUM_CAPACITY) { //Then directly modify the old array expansion threshold to the maximum integer value threshold = Integer.MAX_VALUE; //Return the capacity of the old array and do no other operations return oldTab; } //If the capacity of the old array is less than the maximum capacity and the capacity of the new array is still less than the maximum capacity after expanding to twice the capacity of the old array, else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) //And the capacity of the old array is greater than or equal to the default initialization capacity of 16 //Expand the new array threshold to twice the capacity expansion threshold of the old array newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold //If the capacity of the old array is less than or equal to 0 and the capacity expansion threshold of the old array is greater than 0 (this will be done when the put operation is performed after new HashMap(0)) / / assign the old array threshold to the capacity of the new array newCap = oldThr; else { // zero initial threshold signifies using defaults //If both the old array capacity and the old array threshold are less than 0, the array needs to be initialized newCap = DEFAULT_INITIAL_CAPACITY;//Set the new array capacity to the default initialization capacity of 16 //Assign the new array expansion threshold value as the default load factor of 0.75 times the default initialization capacity of 16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { //After the above logic, the capacity expansion threshold of the new array is still 0, indicating that the capacity expansion threshold of the new array has not been processed, but the capacity of the new array has been processed before coming here, //Therefore, it is necessary to recalculate according to the formula of the new array capacity load factor float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //Assign the new array expansion threshold value to the expansion threshold field of HashMap threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) //Create a new array according to the capacity of the new array Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //Assign the created new array to the array field of HashMap table = newTab; //Omit part of the source code //Returns the processed new array return newTab; }A new array is created at the code node < K, V > [] newtab = (node < K, V > []) new node [newcap], and table = newTab assigns the newly created empty array to table.
At this time, after thread A executes table = newTab, the table in thread B also changes. When thread B goes to get, it will get null because the element has not been transferred.
The code realizes the ring linked list generated by multithreading and the lost data
public class Table { String value; Table next; private int hash = 1; public Table(String value, Table next) { this.value = value; this.next = next; } public String getValue() { return value; } public void setValue(String value) { this.value = value; } public Table getNext() { return next; } public void setNext(Table next) { this.next = next; } @Override public String toString() { if (null != value) { return value + "->" + (null == next ? null : next.toString()); } return null; } }transient static Table[] table; public static void main(String[] args) throws ParseException { Table c = new Table("7", null); Table b = new Table("5", c); Table a = new Table("3", b); table = new Table[4]; table[1] = a; System.out.println("initial table Value:" + a.toString()); Thread thread = new Thread(new Runnable() { @Override public void run() { Table[] newTable = new Table[8]; int count = 1 ; for (Table e : table) { if (null != e) { System.out.println("thread A Give up CPU Before time slice,Operational table Is:" + e.toString()); } while (null != e) { Table next = e.next; //The main reason for generating an endless loop is here. The first traversal of the above next is B - > C - > null, // The next time B is traversed, because thread 2 is modified to C - > b - > A - > null, the next of node B points to node a again //Thread 1 gives up the CPU time slice and waits for thread 2 to complete the operation try { Thread.sleep(5000); } catch (InterruptedException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } System.out.println("=============The first"+count+"Secondary cycle=============="); System.out.println("thread A Continue execution,Operational table Is:" + e.toString()); e.next = newTable[1]; newTable[1] = e; e = next; count ++; } } table = newTable; } }); thread.start(); new Thread(new Runnable() { @Override public void run() { Table[] newTable = new Table[8]; for (Table e : table) { if (null != e) { System.out.println("thread B start,Operational table Is:" + e.toString()); } while (null != e) { try { Thread.sleep(500); } catch (InterruptedException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } Table next = e.next; e.next = newTable[1]; newTable[1] = e; e = next; } } System.out.println("thread B Expansion completed,table Is:" + newTable[1].toString()); try { Thread.sleep(6000); } catch (InterruptedException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } table = newTable; } }).start(); try { Thread.sleep(20000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("2 After the expansion of threads,final table Is:" + table[1].value + "->" + table[1].next.value + "->" + table[1].next.next.value); }Results of final operation:
initial table Value: 3->5->7->null thread A Give up CPU Before time slice,Operational table Is: 3->5->7->null thread B start,Operational table Is: 3->5->7->null thread B Expansion completed,table Is: 7->5->3->null =============1st cycle============== thread A Continue execution,Operational table Is: 3->null =============2nd cycle============== thread A Continue execution,Operational table Is: 5->3->null =============3rd cycle============== thread A Continue execution,Operational table Is: 3->null 2 After the expansion of threads,final table Is: 3->5->3
From the final result of the operation, a circular linked list appears in 3 - > 5 - > 3, in which element 7 is lost. From this, we can see that HashMap not only has an dead loop, but also may lose data.
summary
- In jdk1.7, because the header insertion method is used during capacity expansion, a circular list may be formed in a multithreaded environment, resulting in an endless loop.
- Changing the tail insertion method in jdk1.8 can avoid dead loop in multi-threaded environment, but it still can not avoid the problem of node loss.
How to solve these problems in multithreaded environment? Three solutions:
- Replace HashMap with Hashtable
- The Collections.synchronizedMap method wraps the HashMap
- Replace HashMap with ConcurrentHashMap
- Of course, it is officially recommended to use ConcurrentHashMap to achieve thread safety.
last
How concurrent HashMap ensures thread safety will be explained in the next article.