1. Preface
In order to explore whether the ZGC feature of JDK15 is as good in HBase as rumored, I recompiled the community version of hbase-1.4.8 with AdoptOpenJDK15, then completed the fully distributed deployment and functional test of HBase after compilation, and shared the whole compilation process and solved problems one by one in the previous articles.
But the version of HBase we use online is cdh6 3.2-hbase2. 1.0, the big data components assembled by CDH are slightly different from the original version. The compilation of the community version of HBase is only used to test the water. If you want to experience the powerful features of ZGC online, you also need to make an article on the CDH version of HBase.
This article will be published as cdh6 3.1-hbase2. 1.0 (test environment) and cdh6 3.2-hbase2. Taking the two versions of 1.0 (online environment) as an example, this paper records the complete process of compiling CDH HBase by AdoptOpenJDK15, and expounds in detail the thinking process and methods of solving problems during the period.
After successful compilation, the original HBase jar package will be replaced in the CDH test cluster, with emphasis on modifying Java related parameters, and then restart the cluster to test the availability of HBase services, record the detailed deployment process, and troubleshoot each pit encountered.
The subsequent plan is to replace the original HBase jar package in the CDH, modify the startup parameters of the HBase cluster, successfully start the HBase service on the CDH, set the ZGC parameters, and perform the benchmark performance pressure test on HBase (we just vacated three online nodes), which will be shared in the next chapter.
2. Preparation
- cdh6. 3.2-hbase2. To download the 1.0 source code, please move to the official warehouse of GitHub Cloudera and select your favorite version
- AdoptOpenJDK15 please search the download page of the JDK and download the installation package of the corresponding operating system
- maven-3.5.0, the configuration recommended by maven configuration file, please refer to my history article
- The paid version of IDEA-2020.3 is better and the community version is enough. Download the latest version of IDEA mainly to select jdk15 on it
- Mac OS, the pit will be much less
3. Project configuration
3.1 project import
Import the project into the IDEA. After importing, it is a very standard maven project, as shown in the following figure:
When the project is loaded for the first time, a large number of third-party dependencies will be downloaded. Please wait patiently. After the dependencies are downloaded, we will not make any changes, and try whether jdk1 can be used 8 directly compile and package the project.
# Here I run directly and hit tar GZ package command. The default version of Hadoop is 3.0 mvn clean package -DskipTests assembly:single

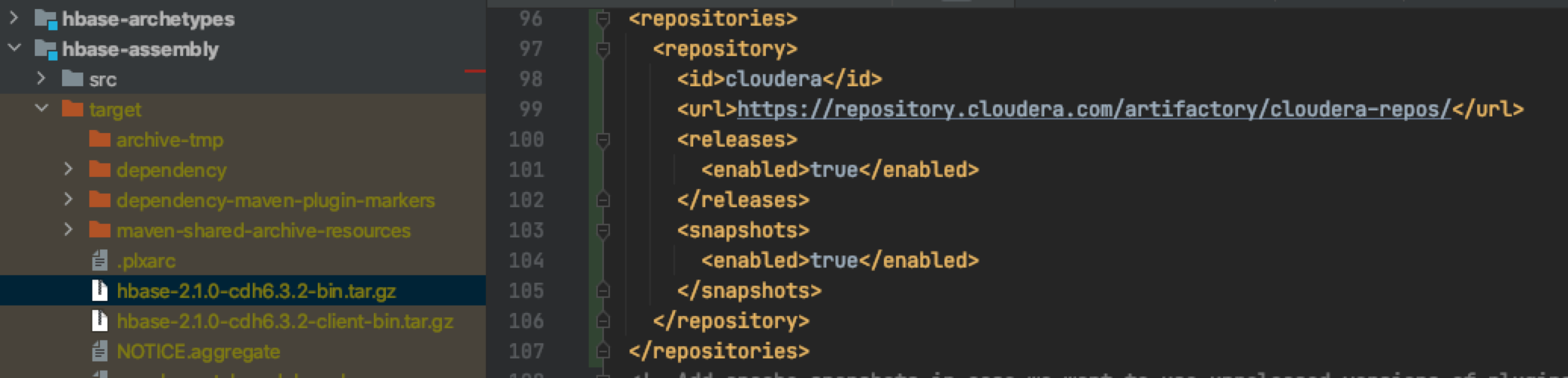
If the above exception is encountered during compilation, the POM. In the project root path Add the following configuration to XML:
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
After the above mvn command is run, you can find hbase-2.1.0-cdh6.0 in the target directory of the HBase assembly module 3.2-bin. tar. gz
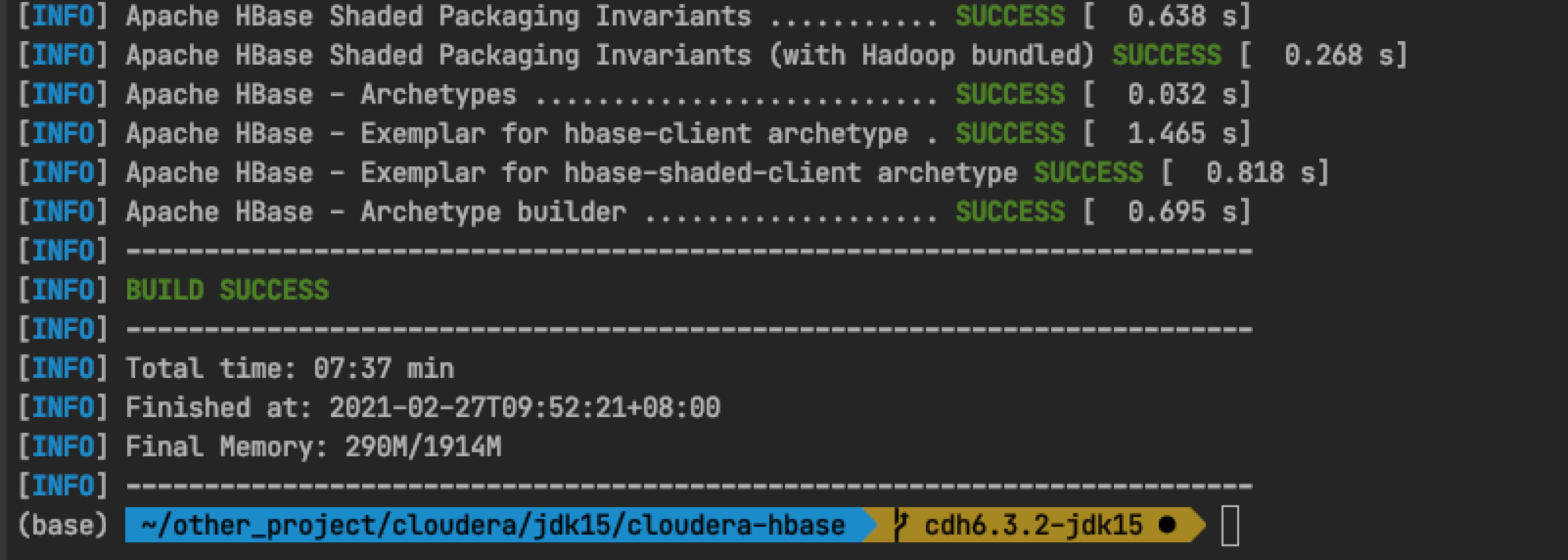
Location of tar package:
3.2 compilation configuration
The source code we downloaded can be compiled and packaged normally in the JDK8 environment. This version of HBase is based on the community version 2.1.0. The bosses have done a lot of work for us to be compatible with the higher version of JDK, so we can make it compile smoothly in the JDK15 environment with only a little change.
First, modify the compilation plug-in Maven Compiler configuration:
<!-- Old configuration -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<source>${compileSource}</source>
<target>${compileSource}</target>
<showWarnings>true</showWarnings>
<showDeprecation>false</showDeprecation>
<useIncrementalCompilation>false</useIncrementalCompilation>
<compilerArgument>-Xlint:-options</compilerArgument>
</configuration>
</plugin>
<!-- New configuration -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<source>${compileSource}</source>
<target>${compileSource}</target>
<showWarnings>true</showWarnings>
<showDeprecation>false</showDeprecation>
<useIncrementalCompilation>false</useIncrementalCompilation>
<compilerArgs>
<arg>--add-exports=java.base/jdk.internal.access=ALL-UNNAMED</arg>
<arg>--add-exports=java.base/jdk.internal=ALL-UNNAMED</arg>
<arg>--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED</arg>
<arg>--add-exports=java.base/sun.security.pkcs=ALL-UNNAMED</arg>
<arg>--add-exports=java.base/sun.nio.ch=ALL-UNNAMED</arg>
<!-- --add-opens Your configuration may not be required-->
<arg>--add-opens=java.base/java.nio=ALL-UNNAMED</arg>
<arg>--add-opens=java.base/jdk.internal.misc=ALL-UNNAMED</arg>
</compilerArgs>
</configuration>
</plugin>
The compileSource is changed to 15
<!-- <compileSource>1.8</compileSource>--> <compileSource>15</compileSource>
Update pom configuration and run mvn compilation command:
# 1. Switch the local jdk version to 15 jdk15 # 2. Run the mvn compilation command mvn clean package -DskipTests
3.3 package javax Annotation does not exist
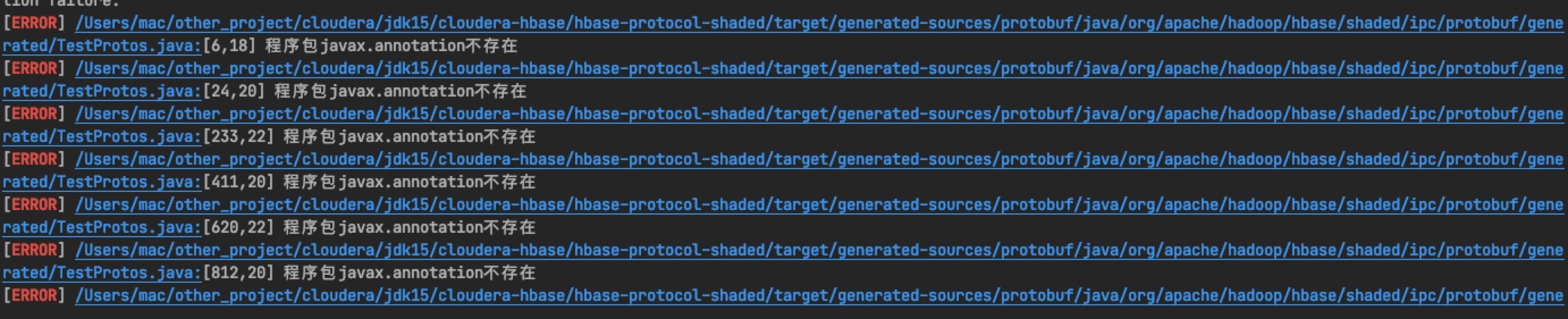
Add the following dependencies to the project root pom file, which should be added under the dependencies tab:
<dependencies>
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.1</version>
</dependency>
</dependencies>
3.4 Maven shade plugin upgrade
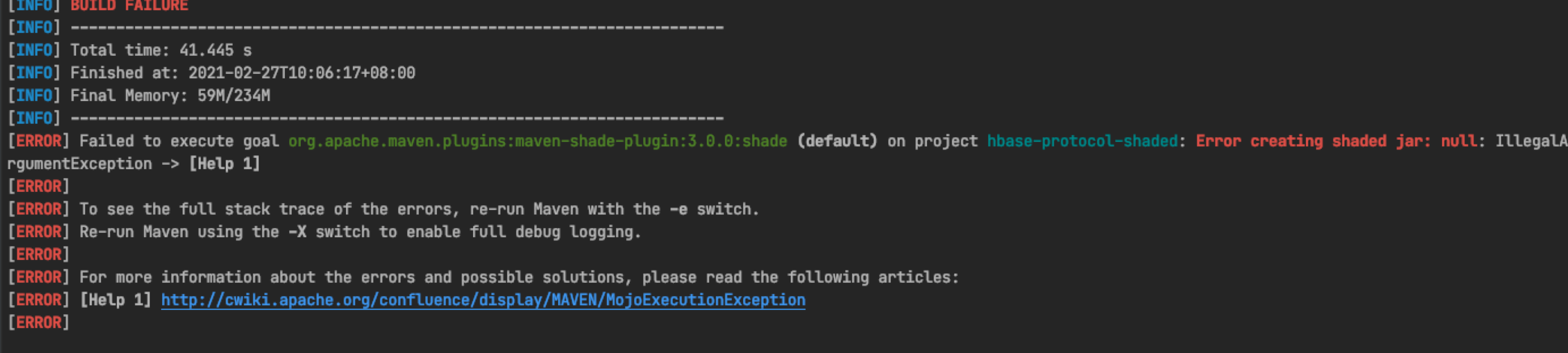
Upgrade Maven shade plugin version to 3.2.4
3.5 package javax xml. ws. HTTP does not exist
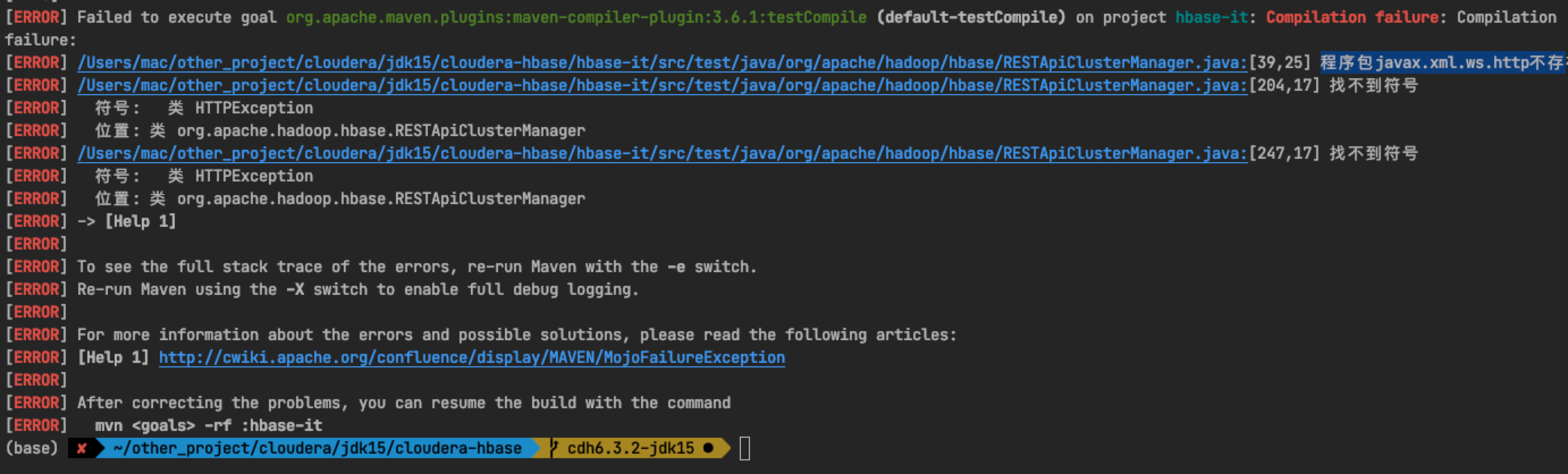
Add the following dependencies to pom:
<dependency>
<groupId>jakarta.xml.ws</groupId>
<artifactId>jakarta.xml.ws-api</artifactId>
<version>2.3.3</version>
</dependency>
3.6 Some Enforcer rules have failed.

Upgrade Maven enforcer plugin version to 3.0.0-M3.
After the version upgrade, it is found that the error is still reported. Continue to check the error information upward, which may be caused by the inspected exception of the license. It was also mentioned in the article before. Please refer to the solution. You can also add the - X parameter after the mvn compilation command to view more detailed DEBUG log information when the mvn compilation command is executed.
3.7 HBase spark module compilation error
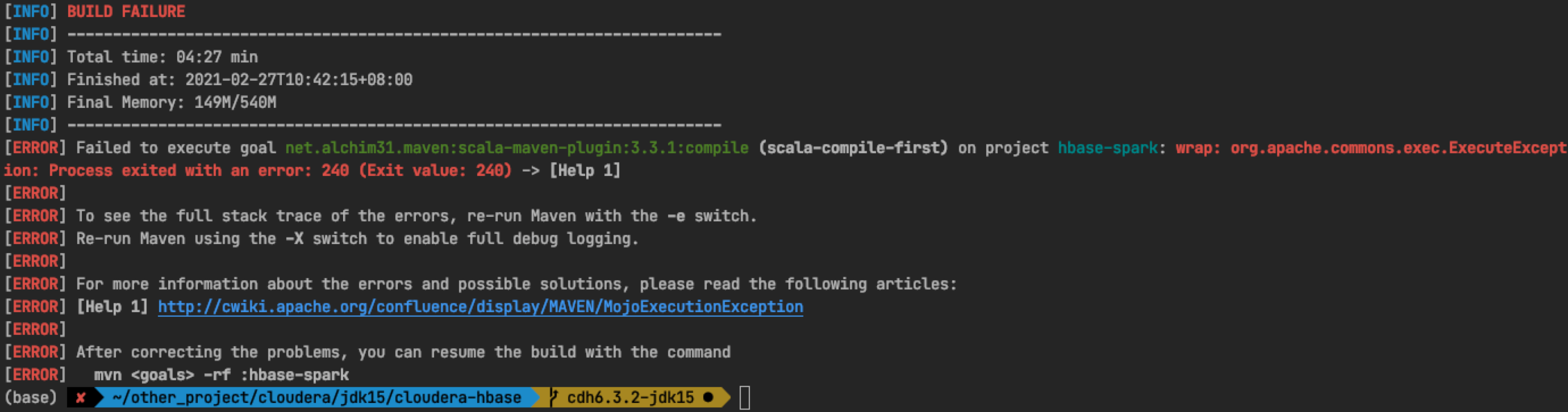
The above exception was thrown when the HBase spark module was compiled. First try to upgrade the version of the scala Maven plugin in the module pom file to 4.4.0. After the upgrade, the problem still cannot be solved. It will not help after - X outputs detailed exception log information.
You can then try the following method to modify the scala Maven plugin configuration in the pom file of HBase spark module as follows:
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<!-- <version>3.3.1</version>-->
<version>3.4.6</version>
<configuration>
<charset>${project.build.sourceEncoding}</charset>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-nobootcp</arg>
<arg>-target:jvm-1.8</arg>
<!-- <arg>-feature</arg>
<arg>-target:jvm-1.8</arg>-->
</args>
</configuration>
......
If you can't solve this exception, you can also choose to skip the compilation of HBase spark module. Ignoring it will not affect your use of HBase. It is only a tool module, rather than running inside the HBase service as a component. Therefore, we can use HBase spark compiled by JDK8 to enable spark to read and write data in the HBase cluster.
Rerun the compilation command, and the compilation of the module also passes smoothly.
After solving the above compilation problems, continue to run our compilation command:
mvn clean package -DskipTests mvn clean package -DskipTests assembly:single
The compilation command is executed successfully, and HBase can be packaged with JDK15.
3.8 handle some compile time warnings
If you are an OCD patient, you can pay attention to the log output during compilation and optimize some warning messages.
Such as: org apache. maven. plugins:maven-resources-plugin is missing
– add opens has no effect during compilation. Delete the -- add opens configuration in the compilation plug-in

When compiling hbase-1.4.8, we mainly modified bytes Import sun. Java and its related classes misc. Unsafe;
Sun. In Bytes and UnsafeAccess misc. Replace unsafe with JDK internal. misc. Unsafe
However, when compiling this version, no relevant exceptions are reported. Only the warnings here. We can also replace the above classes to use the practices recommended in the higher version JDK.
Check the compilation logs one by one. Most of them are warnings about the use of outdated APIs. When compiling with a higher version of JDK, you only need to pay attention to whether the outdated APIs are deleted, and then find alternative classes.
4. Local startup and function test
4.1 HMaster Application configuration
Although the above compiled commands have been successfully executed, it remains to be verified whether HBase can really provide read-write services. We'd better not directly replace the online jar package, but first try to start the HMaster process locally to simply test the basic functions of HBase. About how HBase's source code runs in IDEA, and has shared many articles in official account before, there is only a lot of detailed description of the configuration process in DEBUG.
We directly add the Application of HMaster in the IDEA and try to run this process after configuration.
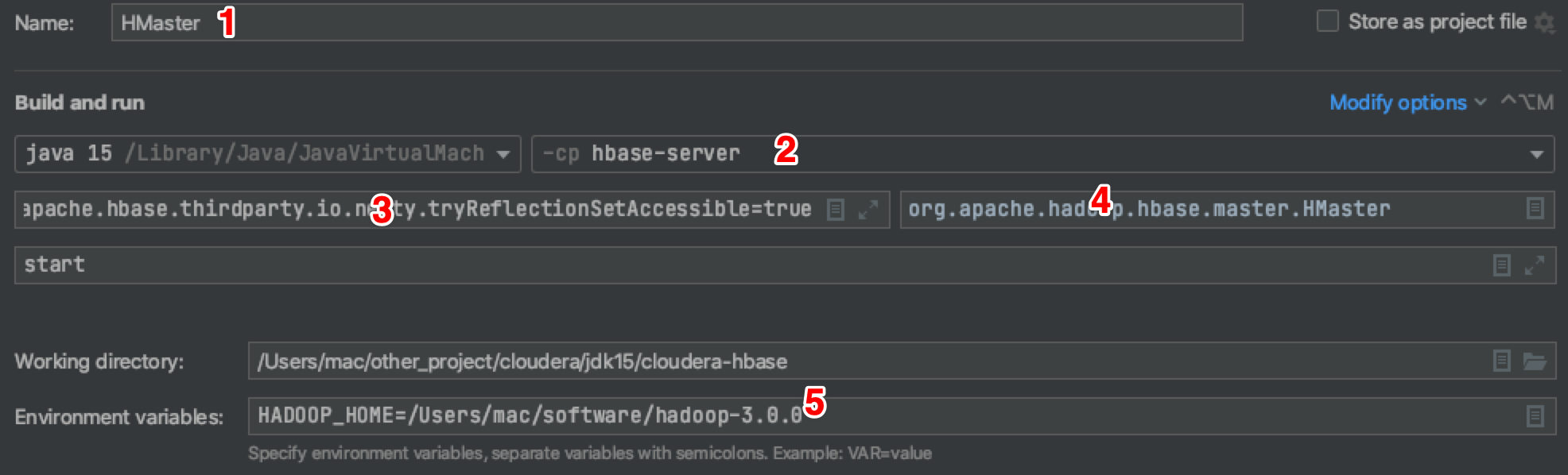
- Name of Application
- The module to which the HMaster process belongs
- VM Options
- Full pathname of HMaster main class
- HADOOP_HOME, a hadoop directory is decompressed locally, mainly to eliminate warnings
- start runtime main function parameters
More detailed configuration of VM Options is as follows:
-Dproc_master -XX:OnOutOfMemoryError="kill -9 %p" -XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Dhbase.log.dir=/Users/mac/other_project/cloudera/jdk15/cloudera-hbase/hbase-data/logs -Dhbase.log.file=hbase-root-master.log -Dhbase.home.dir=/Users/mac/other_project/cloudera/jdk15/cloudera-hbase/bin/. -Dhbase.id.str=root -Dhbase.root.logger=INFO,console,DRFA --illegal-access=deny --add-exports=java.base/jdk.internal.access=ALL-UNNAMED --add-exports=java.base/jdk.internal=ALL-UNNAMED --add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/sun.security.pkcs=ALL-UNNAMED --add-exports=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens java.base/jdk.internal.misc=ALL-UNNAMED -Dorg.apache.hbase.thirdparty.io.netty.tryReflectionSetAccessible=true
Some JVM parameters required by JDK15 runtime are very important. If you are interested, you can ponder the role of each configuration. The addition of these configurations is basically to report an error, and then find the corresponding configuration to solve it.
Copy the conf directory to the HBase server directory and turn it into a resources folder, HBase site Add the following configuration to the XML configuration file:
<property>
# This configuration is to skip version checking
<name>hbase.defaults.for.version.skip</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>file:///Users/mac/other_project/cloudera/jdk15/cloudera-hbase/hbase-data/hbase</value>
<description>hbase Local data address</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/Users/mac/other_project/cloudera/jdk15/cloudera-hbase/hbase-data/zookeeper-data</value>
<description>hbase built-in zk Data directory address</description>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
4.2 localhost/unresolved:2181 detailed analysis and resolution of exceptions
After the above configuration is completed, you can click the run button to run the process.

The HMaster process starts with an error and cannot connect to the zookeeper embedded in HBase. The reason is that there is an error in the address resolution of zookeeper. The host address is localhost / < unresolved >: 2181
HBase boss estimated that he could see the cause of the exception at a glance, but the problem really puzzled me for a day or two. Moreover, I foolishly thought that in the cluster environment, after connecting an independent ZK address, the exception would not appear. However, after the compiled jar package is replaced, the HBase service on the CDH cannot live or die, and the error report is consistent with that at local startup.
Finally, the exception of address resolution was successfully solved by slightly changing part of the code in the StaticHostProvider class of CDH zookeeper. But I still want to record the whole thinking process of solving the problem at that time. Anxious partners can skip to the specific steps to solve the problem below.
In the face of this exception, my first thought was that the embedded zookeeper service did not start normally. In order to verify this conjecture, I first interrupted to the code location after the zookeeper server was started and pulled down the log.
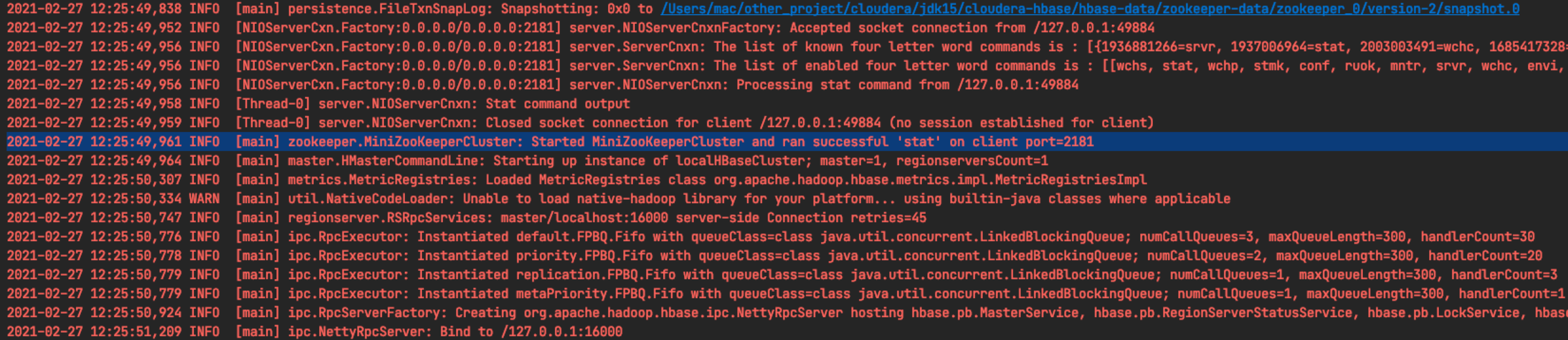
It can be seen from the log that MiniZooKeeperCluster has been successfully started. Search the key part of this log in this class.
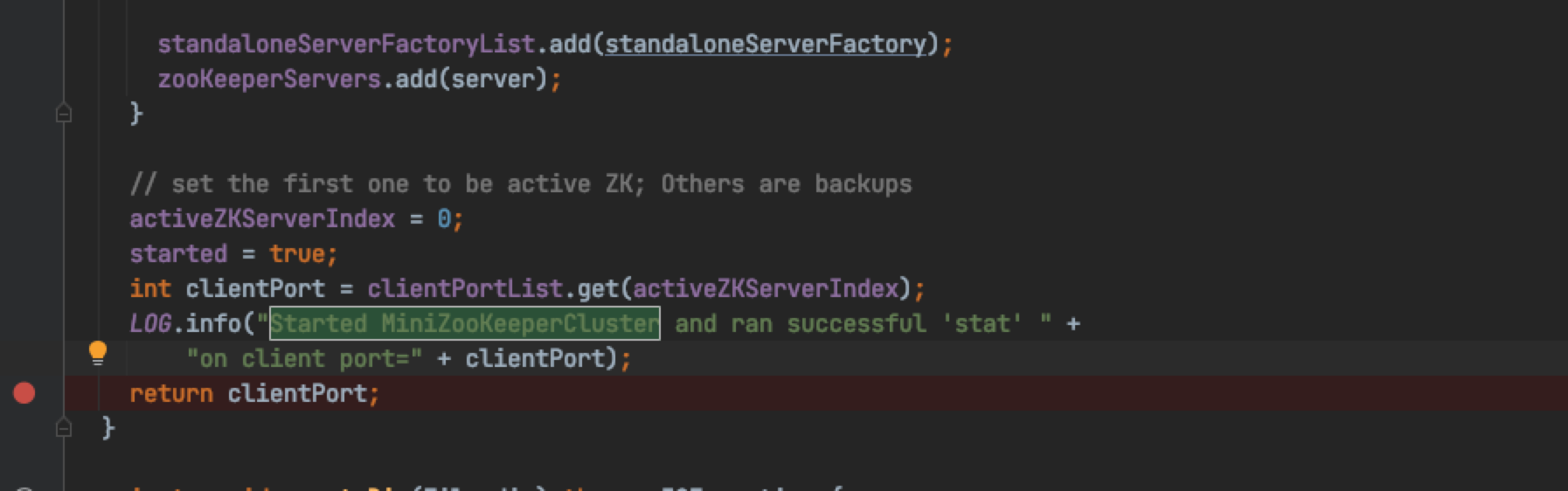
The location of the breakpoint is determined, and DEBUG runs the HMaster process.
telnet localhost 2181 # The local 2181 port can listen smoothly
Now it can be proved that the embedded zookeeper service has been started successfully, and the port 2181 has been occupied. Then we can connect our zk service with client tools such as zookeeper shell. Here, I use the zk shell.
zk-shell localhost:2181 Welcome to zk-shell (1.3.2) (DISCONNECTED) /> # cannot connect
Although the zk service has been started and the port is occupied, the client cannot connect.
There is no clue to explain why zk service is in such a situation. So, in order to avoid being taken to a detour, stay away from the truth further. You still need to turn around and focus on the abnormal appearance, just like peeling onions. If you want to see the innermost layer, you must tear off the outer skin.
Localhost / < unresolved >: the first problem to be solved is where the unresolved keyword in 2181 is generated or how to trigger it.
DEBUG is the best tool, which can track the execution link of each method and observe the data flow of each variable in turn.
The exception is the class zookeeper Thrown by clientcnxn, find this class, search the log key information, break points, observe the method call stack and pay attention to the changes of variables.
Clientcnxn, search this class directly, but I haven't found it yet. Observe the log context, zookeeper ClientCnxn,zookeeper.ZooKeeper,main,main-SendThread
With these keywords, even if we are very unfamiliar with the source code of zookeeper, we can guess that ClientCnxn and zookeeper belong to zookeeper. Zookeeper is active in the main thread, and ClientCnxn is active in a sub thread named SendThread in the main thread. Therefore, if you can't find ClientCnxn directly, go to the class zookeeper.
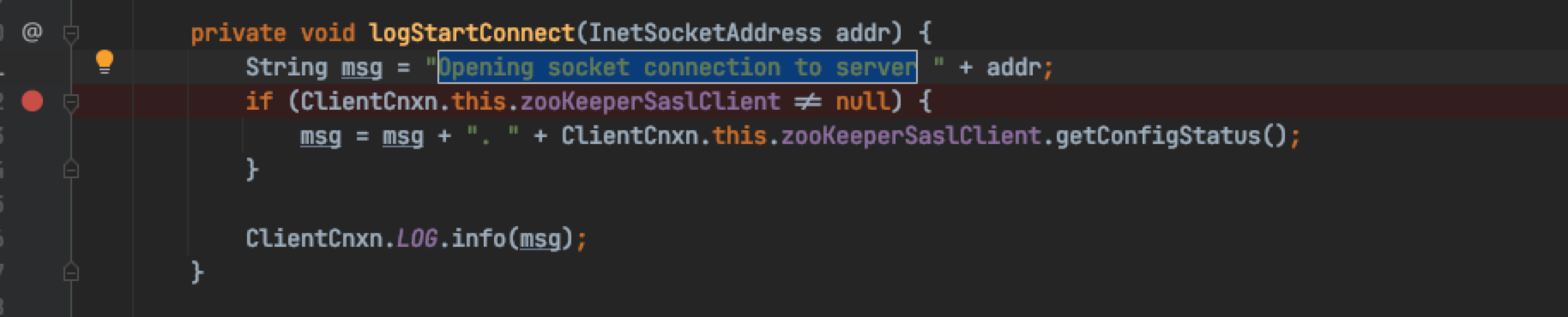
DEBUG information:
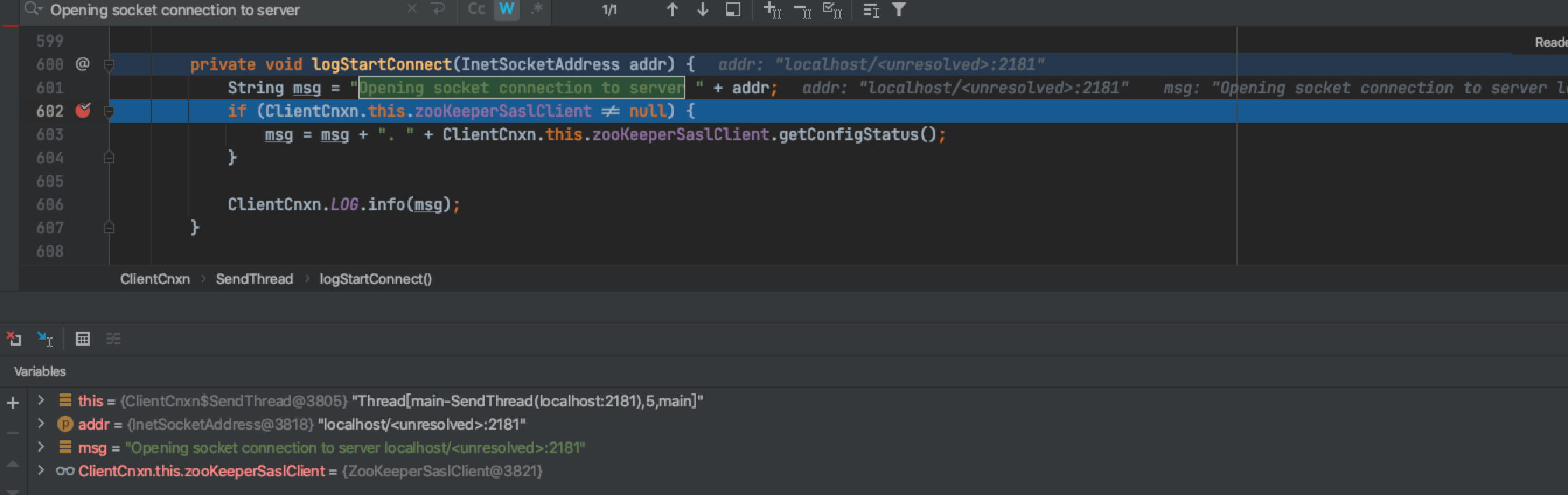
Keep tracking
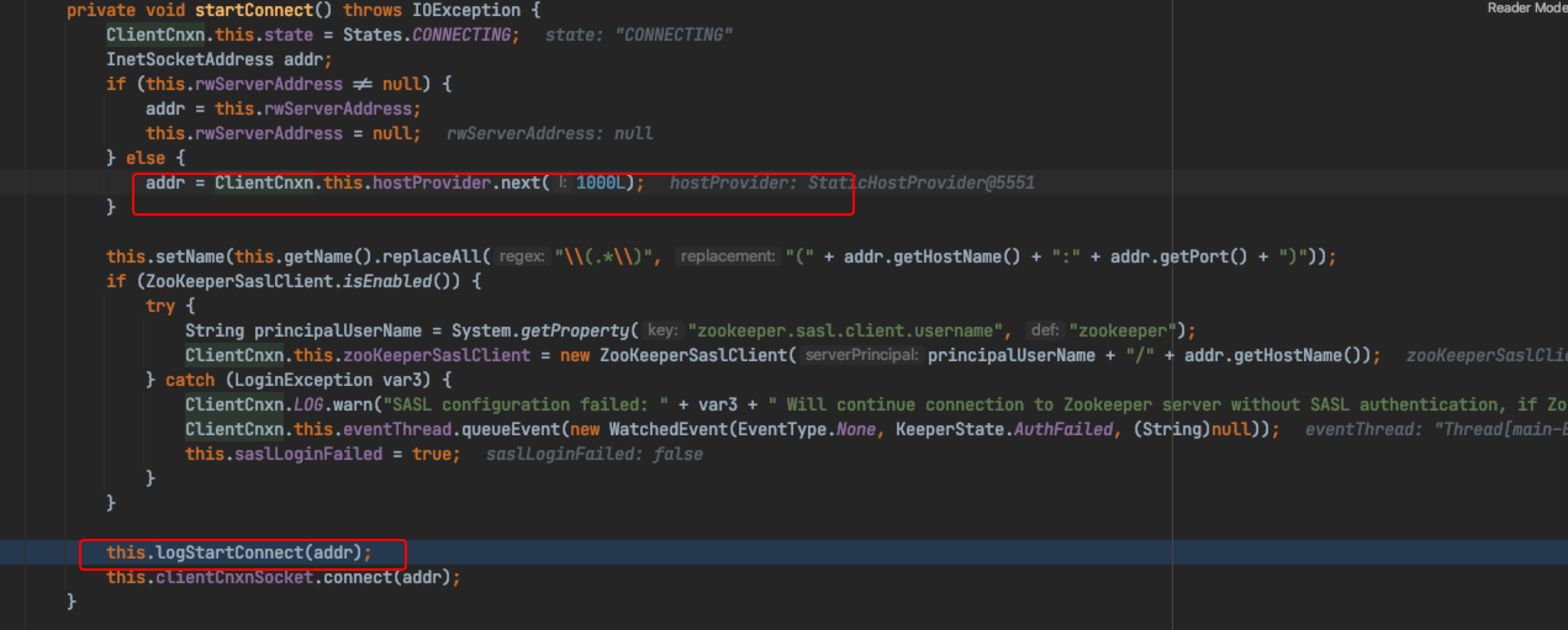
How the addr variable is generated, assigned and passed to the final call, DEBUG is very clear here.
Addr is finally addr = ClientCnxn this. hostProvider. next(1000L); Assignment, hostprovider is a member variable of ClientCnxn, which is assigned when constructing the ClientCnxn object.
Then we continue to track the call stack of the upper layer and need to DEBUG in its upper layer call class ZooKeeper. The important thing is to observe how ClientCnxn is initialized in ZooKeeper. The core is to pay attention to how the addr variable received by ClientCnxn is assigned.
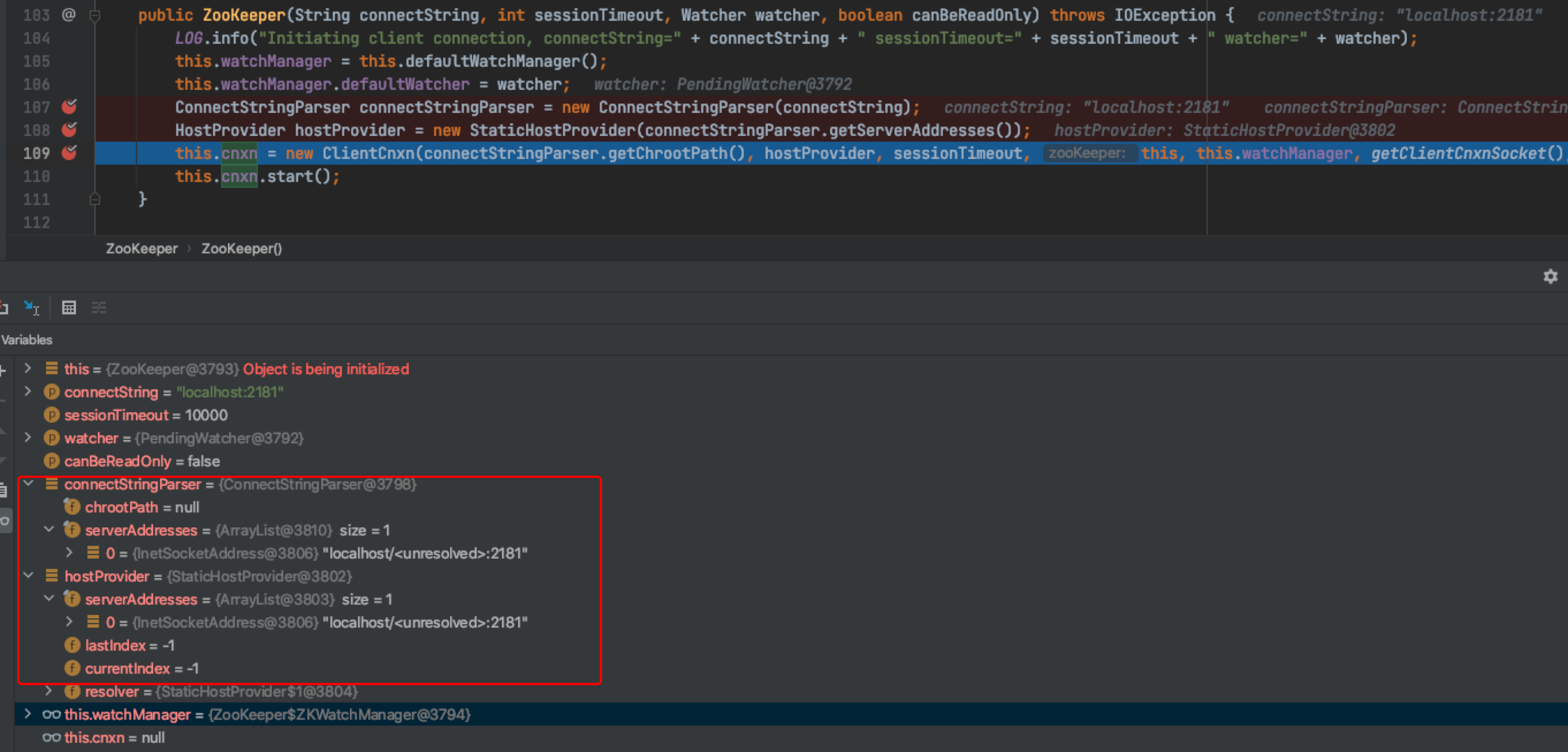
No ink. The connectionString=localhost:2181 we passed was obtained from the HBase configuration file. It is a normal and valid ZK address. When the ConnectStringParser parses this address, it parses the normal address into localhost / < unresolved >: 2181
The HostProvider is assigned the wrong address and then sent down to ClientCnxn. ClientCnxn links ZK with the wrong address, but it can't be connected. Therefore, we can finally confirm that the exception is caused when a ConnectStringParser parses the ZK address.
Why is there no such exception in JDK8? Why is there no such exception in hbase-1.4.8 compiled by JDK15.
-
Why is there no error in JDK8
There are differences in the implementation of the createUnresolved method of InetSocketAddress in jdk8 and jdk15. For specific comparison, please check the source code implementation of the two JDK versions.
InetSocketAddress.createUnresolved(host, port) # jdk15 @Override public String toString() { String formatted; if (isUnresolved()) { formatted = hostname + "/<unresolved>"; } else { formatted = addr.toString(); if (addr instanceof Inet6Address) { int i = formatted.lastIndexOf("/"); formatted = formatted.substring(0, i + 1) + "[" + formatted.substring(i + 1) + "]"; } } return formatted + ":" + port; } -
Why is there no error in hbase-1.4.8 compiled by JDK15
The implementation of the StaticHostProvider class of zookeeper in the community version hbase-1.4.8 is different from that of CDH zookeeper. If you are interested, you can compare it carefully. It can't be said that the implementation of CDH zookeeper is wrong. It can only be said that it doesn't consider the situation of the high version of JDK, but the HBase bosses in the community version have considered it, which has proved that the CDH product is indeed "half a beat" slower than the community version.
terms of settlement
- Big guys usually modify the source code of InetSocketAddress of JDK, and then recompile the JDK
- Generally, the boss will pull down the source code of the corresponding version of zookeeper in CDH, modify and re ant the source code of zookeeper
- For dishes, you can only unzip the jar compiled by zookeeper, pull out the source code inside, and alter statichostprovider Java this file, compiled, and then replaced back. Then why not directly modify statichostprovider class? It can only be said that ordinary mortals can't do the work of compiler.
Specific operation process
Unzip zookeeper-3.4.5-cdh6 3.2. Jar, create an empty maven project, and copy all the extracted code. pom. Under cloudera / maven packaging / zookeeper of the source project The dependency of XML comes from the maven project. build. Find [Dependency versions] in the. XML to map the version under Dependency versions to pom XML, the following is the complete pom.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cloudera.cdh</groupId>
<artifactId>zookeeper-root</artifactId>
<version>3.4.5-cdh6.3.1</version>
<packaging>pom</packaging>
<name>CDH ZooKeeper root</name>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>jline</groupId>
<artifactId>jline</artifactId>
<version>2.11</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.yetus/audience-annotations -->
<dependency>
<groupId>org.apache.yetus</groupId>
<artifactId>audience-annotations</artifactId>
<version>0.5.0</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.10.6.Final</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-all</artifactId>
<version>1.8.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>checkstyle</groupId>
<artifactId>checkstyle</artifactId>
<version>5.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>jdiff</groupId>
<artifactId>jdiff</artifactId>
<version>1.0.9</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>xerces</groupId>
<artifactId>xerces</artifactId>
<version>1.4.4</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.rat</groupId>
<artifactId>apache-rat-tasks</artifactId>
<version>0.6</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.4</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.2</version>
<optional>true</optional>
</dependency>
</dependencies>
</project>
After changing the source code, there is no packaging requirement, just need it to be compiled.
private void init(Collection<InetSocketAddress> serverAddresses) {
try{
for (InetSocketAddress address : serverAddresses) {
InetAddress ia = address.getAddress();
InetAddress resolvedAddresses[] = InetAddress.getAllByName((ia!=null) ? ia.getHostAddress():
address.getHostName());
for (InetAddress resolvedAddress : resolvedAddresses) {
if (resolvedAddress.toString().startsWith("/")
&& resolvedAddress.getAddress() != null) {
this.serverAddresses.add(
new InetSocketAddress(InetAddress.getByAddress(
address.getHostName(),
resolvedAddress.getAddress()),
address.getPort()));
} else {
this.serverAddresses.add(new InetSocketAddress(resolvedAddress.getHostAddress(), address.getPort()));
}
}
}
}catch (UnknownHostException e){
throw new IllegalArgumentException("UnknownHostException ws cached!");
}
if (this.serverAddresses.isEmpty()) {
throw new IllegalArgumentException("A HostProvider may not be empty!");
}
// Pay attention here
// Collections.shuffle(this.serverAddresses);
// this.serverAddresses.addAll(serverAddresses);
Collections.shuffle(this.serverAddresses);
}
Put the compiled statichostprovider Class file, replace it back into the previous decompression directory, and then type the directory into jar.
# Related commands cd /Users/mac/.m2/repository/org/apache/zookeeper/zookeeper/3.4.5-cdh6.3.2 jar cf zookeeper-3.4.5-cdh6.3.2.jar ./*
After the replacement, update the maven configuration, and then re run the HMaster process.
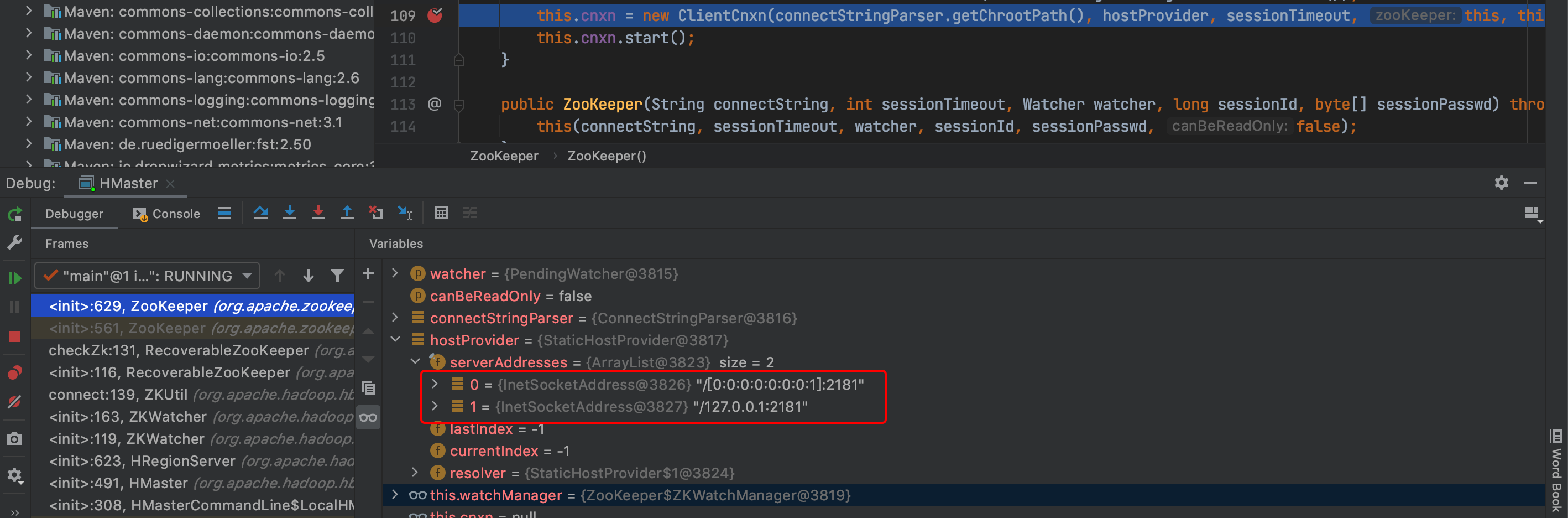
The address of localhost:2181 has been resolved to the correct IPv4 and IPv6 addresses. HMaster starts smoothly and no errors are reported!
4.3 run the HBase shell process to verify the data reading and writing function
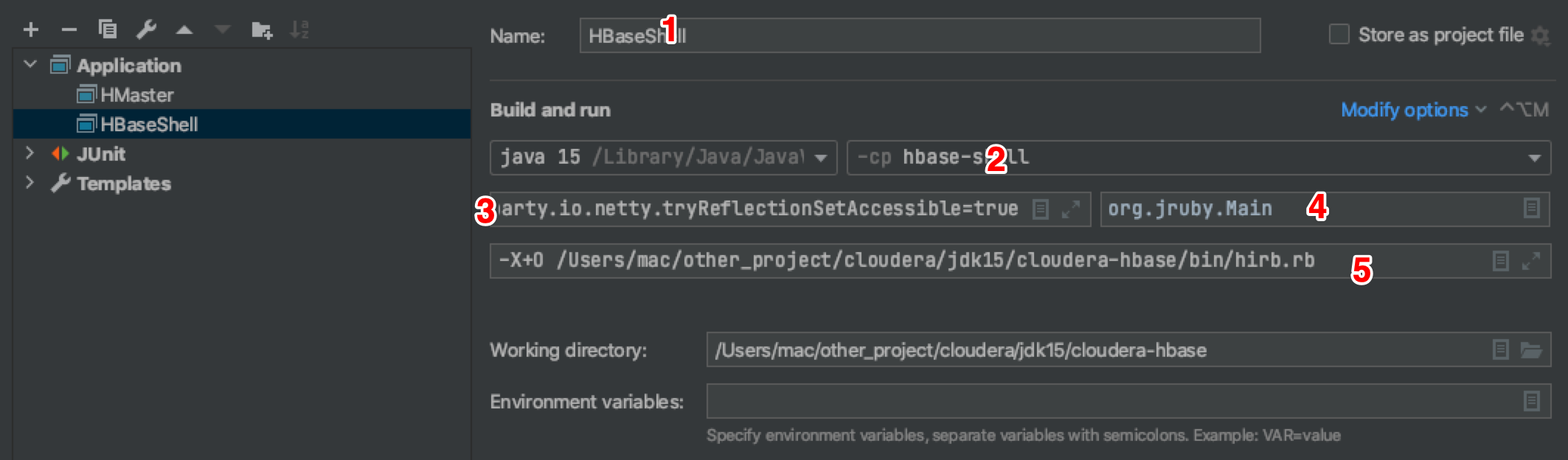
- HBaseShell Application Name
- HBase shell module
- VM parameters
- Run the main class org jruby. Main
- When passing parameters to the main function at runtime, pay attention to the path
Specific configuration of VM parameters:
-Dhbase.ruby.sources=/Users/mac/other_project/cloudera/jdk15/cloudera-hbase/hbase-shell/src/main/ruby --illegal-access=deny --add-exports=java.base/jdk.internal.access=ALL-UNNAMED --add-exports=java.base/jdk.internal=ALL-UNNAMED --add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/sun.security.pkcs=ALL-UNNAMED --add-exports=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens java.base/jdk.internal.misc=ALL-UNNAMED -Dorg.apache.hbase.thirdparty.io.netty.tryReflectionSetAccessible=
Data read / write verification:
create 'leo_test','info',SPLITS=>['1000000','2000000','3000000']
create 'leo_test2', 'info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
put 'leo_test','10001','info:name','leo'
scan 'leo_test'
flush 'leo_test'
major_compact 'leo_test'
status 'replication'
list_snapshots
snapshot 'leo_test','leo_test_snapshot'
clone_snapshot 'leo_test_snapshot','leo_test_clone'
scan 'leo_test_clone'
count 'leo_test_clone'
truncate 'leo_test2'
truncate_preserve 'leo_test'
The above commands can be used normally.
WEB-UI
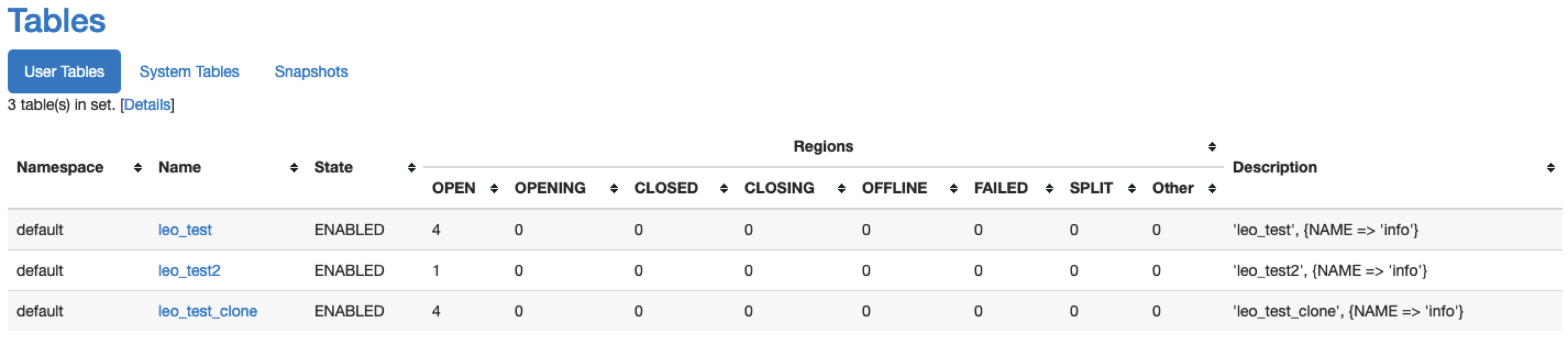
The WEB-UI can be accessed normally.
5. Integrate HBase hbtop
The online cluster integrates HBase hbtop. The compiled version also needs to recompile the HBase hbtop module. Refer to the historical articles for the specific operation process.
Then, recompile the project.
The above installation package Baidu cloud disk address can be installed and experienced by interested partners.
link:https://pan.baidu.com/s/1RlMGcfAOoIYbTn7GCvz4_w password: q5z8 Modified code hosting address: https://gitee.com/weixiaotome/cloudera-hbase After cloning the source code, please switch the corresponding branch.
6. Deploy compiled HBase on CDH
6.1 environmental preparation
This section records that the compiled HBase jar package is used to replace the original HBase jar package on the CDH platform, and the JDK version is separately specified as jdk15 for the HBase of CDH. Then, modify the startup parameters of the cluster to enable the cluster to start smoothly, and test whether its function is abnormal.
I will modify it in the CDH test cluster first. The version of HBase in the CDH test cluster is cdh6 3.1-hbase2. 1.0.
The general steps are as follows:
- Download and unzip the installation package of jdk15 without setting Java environment variables
- Replace the HBase related jar package in the CDH installation directory
- Modify the configuration parameters related to cluster java, and then restart the cluster
The download and decompression of jdk15 are omitted here.
Step 2: replace the jar package:
/opt/cloudera/parcels/CDH/lib/hbase/lib ll | grep hbase The directory is HBase of jar Package loading directory, you can see all the information it needs jar All soft even from../../../jars catalogue
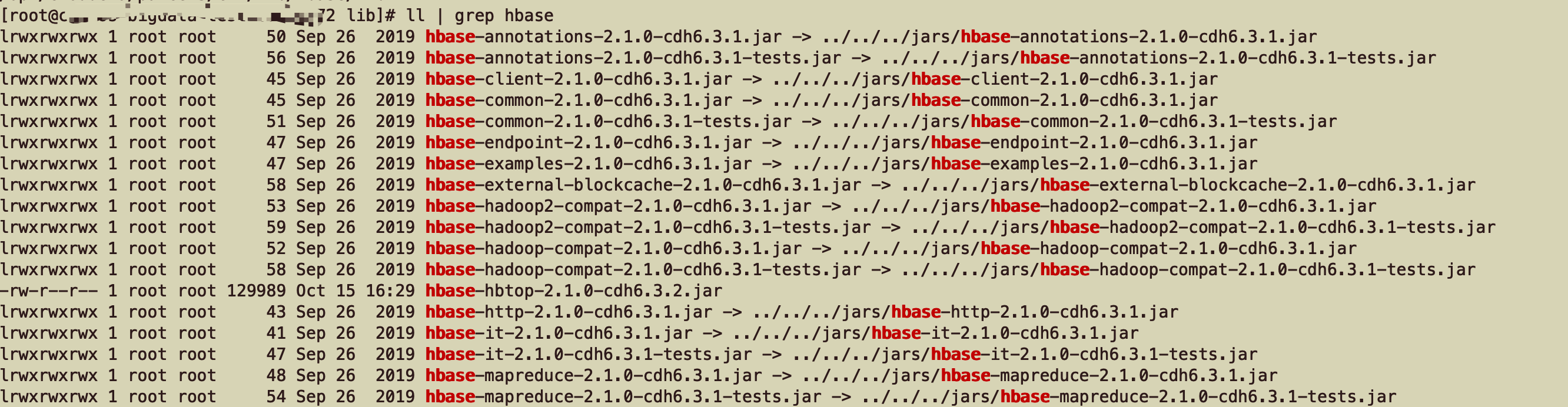
cd /opt/cloudera/parcels/CDH/jars ll | grep hbase & All filtered and HBase dependent jar,We compare the compiled HBase Involved in the installation package jar,Eliminate those that do not need to be replaced. hbase-metrics-api-2.1.0-cdh6.3.1.jar hbase-rest-2.1.0-cdh6.3.1.jar hbase-shaded-protobuf-2.2.1.jar hbase-http-2.1.0-cdh6.3.1.jar hbase-zookeeper-2.1.0-cdh6.3.1-tests.jar hbase-it-2.1.0-cdh6.3.1.jar hbase-rsgroup-2.1.0-cdh6.3.1-tests.jar hbase-it-2.1.0-cdh6.3.1-tests.jar hbase-external-blockcache-2.1.0-cdh6.3.1.jar hbase-rsgroup-2.1.0-cdh6.3.1.jar hbase-replication-2.1.0-cdh6.3.1.jar hbase-mapreduce-2.1.0-cdh6.3.1.jar hbase-common-2.1.0-cdh6.3.1-tests.jar hbase-protocol-shaded-2.1.0-cdh6.3.1.jar hbase-shaded-netty-2.2.1.jar hbase-common-2.1.0-cdh6.3.1.jar hbase-annotations-2.1.0-cdh6.3.1.jar hbase-shaded-miscellaneous-2.2.1.jar hbase-procedure-2.1.0-cdh6.3.1.jar hbase-hadoop-compat-2.1.0-cdh6.3.1.jar hbase-annotations-2.1.0-cdh6.3.1-tests.jar hbase-examples-2.1.0-cdh6.3.1.jar hbase-client-2.1.0-cdh6.3.1.jar hbase-metrics-2.1.0-cdh6.3.1.jar hbase-server-2.1.0-cdh6.3.1.jar hbase-shell-2.1.0-cdh6.3.1.jar hbase-testing-util-2.1.0-cdh6.3.1.jar hbase-mapreduce-2.1.0-cdh6.3.1-tests.jar hbase-server-2.1.0-cdh6.3.1-tests.jar hbase-resource-bundle-2.1.0-cdh6.3.1.jar hbase-protocol-2.1.0-cdh6.3.1.jar hbase-hadoop2-compat-2.1.0-cdh6.3.1.jar hbase-spark-it-2.1.0-cdh6.3.1.jar hbase-hadoop2-compat-2.1.0-cdh6.3.1-tests.jar hbase-spark-2.1.0-cdh6.3.1.jar hbase-hadoop-compat-2.1.0-cdh6.3.1-tests.jar hbase-endpoint-2.1.0-cdh6.3.1.jar hbase-thrift-2.1.0-cdh6.3.1.jar hbase-zookeeper-2.1.0-cdh6.3.1.jar
And don't forget to replace zookeeper - 3.4.5 - cdh6 3.1. jar
It is better to write a script to execute the above process automatically and prepare the rollback scheme to prevent the cluster from rolling back to the previous state with one click when it cannot be started.
6.2 configuring java parameters of HBase related services in CDH
Specify a separate JDK for HBase of CDH
Configure Java related parameters in the CDH interface, similar to those recorded in the previous article, in HBase env Add Java related parameters to SH related scripts.
When configuring parameters, it is best to turn off HBase service first.
Search the environment advanced configuration in the configuration search box, and set Java from top to bottom_ HOME=/usr/java/openjdk-15.0.2.
- HBase service environment advanced configuration code snippet (safety valve)
- hbase-env. HBase client environment advanced configuration code snippet (safety valve) for
- Code snippet for advanced configuration of HBase REST Server environment (safety valve)
- Code snippet for advanced configuration of HBase Thrift Server environment (safety valve)
- Master environment advanced configuration code snippet (safety valve)
- Code snippet for advanced configuration of RegionServer environment (safety valve)
Set the JVM parameters required for startup for the above services respectively
Search java in the configuration search box and set it from top to bottom.
-
Client Java configuration options
Original configuration: - XX: + heapdumponoutofmemoryerror - DJava net. preferIPv4Stack=true
-
Java configuration options for HBase REST Server
Original configuration: {{JAVA_GC_ARGS}}
-
Java configuration options for HBase Thrift Server
Original configuration: {{JAVA_GC_ARGS}}
-
Java configuration options for HBase Master
Original configuration: {{java_gc_args}} - XX: reservedcodachesize = 256M
-
Java configuration options for HBase RegionServer
Original configuration: {{java_gc_args}} - XX: reservedcodachesize = 256M
-XX:+UseZGC -XX:+UnlockExperimentalVMOptions --illegal-access=deny --add-exports=java.base/jdk.internal.access=ALL-UNNAMED --add-exports=java.base/jdk.internal=ALL-UNNAMED --add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/sun.security.pkcs=ALL-UNNAMED --add-exports=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens java.base/jdk.internal.misc=ALL-UNNAMED -Dorg.apache.hbase.thirdparty.io.netty.tryReflectionSetAccessible=true
After the configuration is completed, try to restart the HBase service. You can distribute the client configuration according to the prompt. You can restart the whole CDH cluster to observe whether there are services dependent on HBase that may fail to start.
6.3 testing the availability of HBase
hbase shell
HBase restart on CDH and all its services can be started smoothly without exception. Then we run HBase shell, connect HBase service, run the following test command, and test whether the original table can be read and written normally.
create 'leo_test','info',SPLITS=>['1000000','2000000','3000000']
create 'leo_test2', 'info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
put 'leo_test','10001','info:name','leo'
scan 'leo_test'
flush 'leo_test'
major_compact 'leo_test'
status 'replication'
list_snapshots
snapshot 'leo_test','leo_test_snapshot'
clone_snapshot 'leo_test_snapshot','leo_test_clone'
scan 'leo_test_clone'
count 'leo_test_clone'
truncate 'leo_test2'
truncate_preserve 'leo_test'

When this exception occurs, cancel the line feed in the client Java configuration. After redistributing the client configuration, you can connect to hbase.
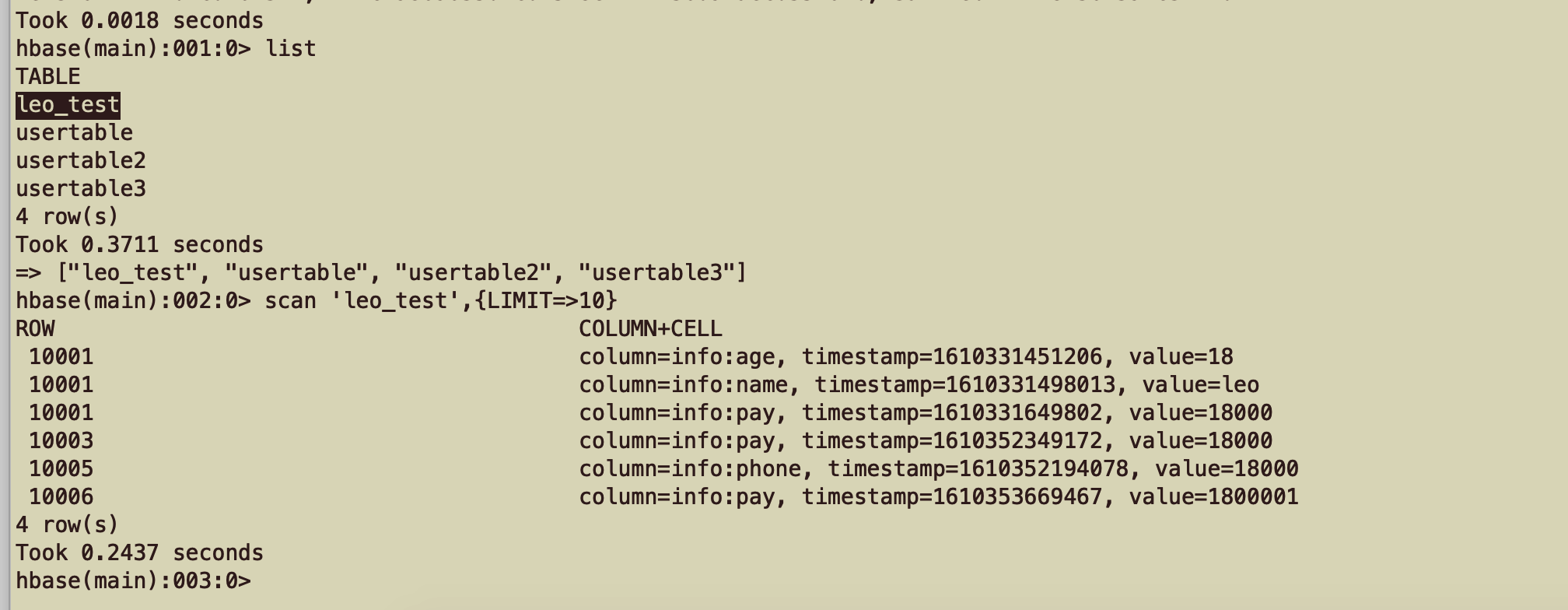
HBase commands can be used normally, and the previous tables can be read and written normally.
WEB-UI
It can be accessed normally
API for ThriftServer
import happybase
pool = happybase.ConnectionPool(size=3, host='xx.x.x.xx', port=9090)
with pool.connection() as connection:
table = connection.table("leo_test")
print list(table.scan())
Thrift API can be used normally.

7. Summary
We have adopted many optimization methods for online HBase, from the adjustment of core parameters, G1 optimization, main and standby fusing, and HDFS heterogeneous storage under test recently, in order to maximize the overall performance bottleneck of HBase. The continuous exploration of ZGC also wants to continue to try to optimize the read-write performance of HBase from the level of GC, constantly break through the bottleneck, and deepen their understanding and learning of JVM.
8. Reference links
- https://blog.csdn.net/qq_28074313/article/details/92569901