1. Introduction to Phoenix
Hbase is suitable for storing a large number of NOSQL data with low requirements for relational operations. Due to the limitations of Hbase design, it is not possible to directly use the native API to perform the operations such as condition judgment and aggregation commonly used in relational databases. Hbase is excellent. Some teams seek to provide a more common developer oriented operation mode on Hbase, such as Apache Phoenix.
Phoenix based on Hbase provides business oriented developers with query operations on Hbase in the way of standard SQL, and supports most of the features of standard SQL: conditional operation, grouping, paging, and other advanced query syntax.
1.1 Phoenix installation
Download the installation package: Official website address
Upload, decompress, modify the name, etc
Copy the jar package to the hbase lib directory of all nodes
Configure environment variables

Start hbase
start-hbase.sh
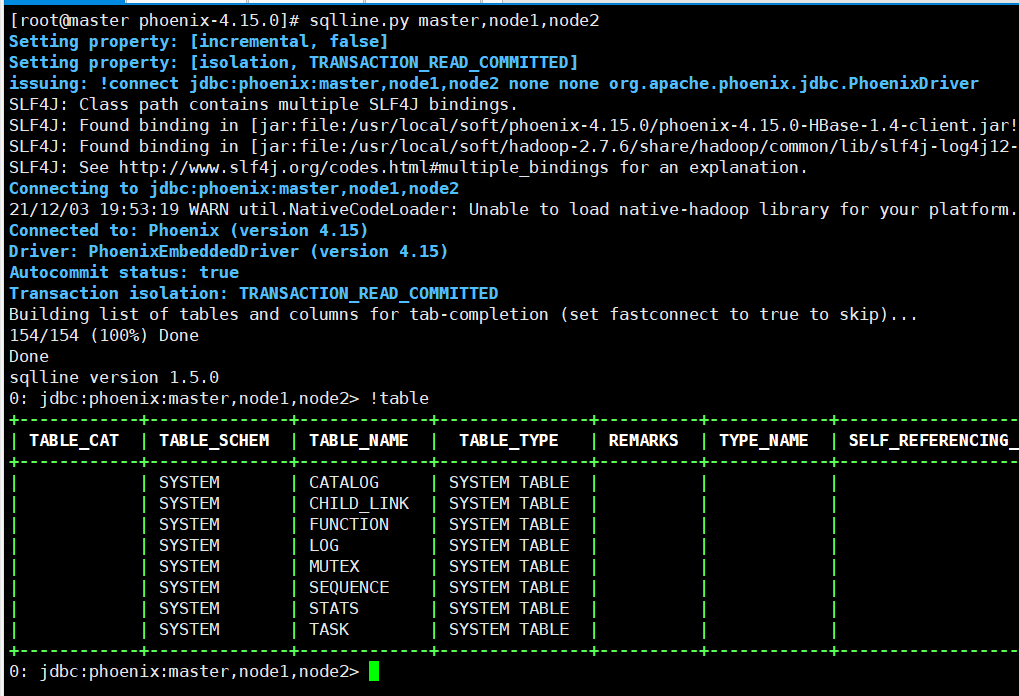
Start Phoenix
sqlline.py master,node1,node2
1.2 common commands
# 1. Create table
CREATE TABLE IF NOT EXISTS STUDENT (
id VARCHAR NOT NULL PRIMARY KEY,
name VARCHAR,
age BIGINT,
gender VARCHAR ,
clazz VARCHAR
);
# 2. Show all tables
!table
# 3. Insert data
upsert into STUDENT values('1500100004','Ge Deyao',24,'male','Science class 3');
upsert into STUDENT values('1500100005','Xuanguqin',24,'male','Science class 6');
upsert into STUDENT values('1500100006','Yi Yanchang',24,'female','Science class 3');
# 4. Query data, support most sql syntax,
select * from STUDENT ;
select * from STUDENT where age=24;
select gender ,count(*) from STUDENT group by gender;
select * from student order by gender;
# 5. Delete data
delete from STUDENT where id='1500100004';
# 6. Delete table
drop table STUDENT;
# 7. Exit command line
!quit
For more syntax, please refer to the official website: Official website syntax address
1.3 phoenix table mapping
By default, tables created directly in hbase cannot be viewed through phoenix
If you need to operate the table directly created in hbase in phoenix, you need to map the table in phoenix. There are two mapping methods: View mapping and table mapping
1.3.1. View mapping
The view created by Phoenix is read-only, so it can only be used for query. You cannot modify the source data through the view
# The hbase shell enters the hbase command line hbase shell # Create hbase table create 'student','info' # insert data put 'student','1001','info:name','zs' put 'student','1001','info:age','20' put 'student','1001','info:gender','m' put 'student','1002','info:name','ls' put 'student','1002','info:age','21' put 'student','1002','info:gender','f'
View data scan 'student'

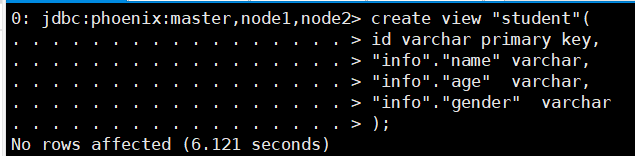
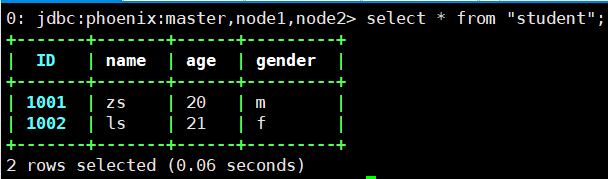
# Create a view in phoenix, and the primary key corresponds to the rowkey in hbase create view "student"( id varchar primary key, "info"."name" varchar, "info"."age" varchar, "info"."gender" varchar ); # When querying data in phoenix, the table name is enclosed in double quotation marks select * from "student"; # Delete view drop view "student";
1.3.2 table mapping
There are two types of table mapping to HBase created using Apache Phoenix:
1) When a table already exists in HBase, you can create an associated table in a similar way to creating a view. You only need to change the create view to create table.
2) When there is no table in HBase, you can directly use the create table instruction to create the required table, and the description of HBase table structure can be displayed as needed in the create instruction.
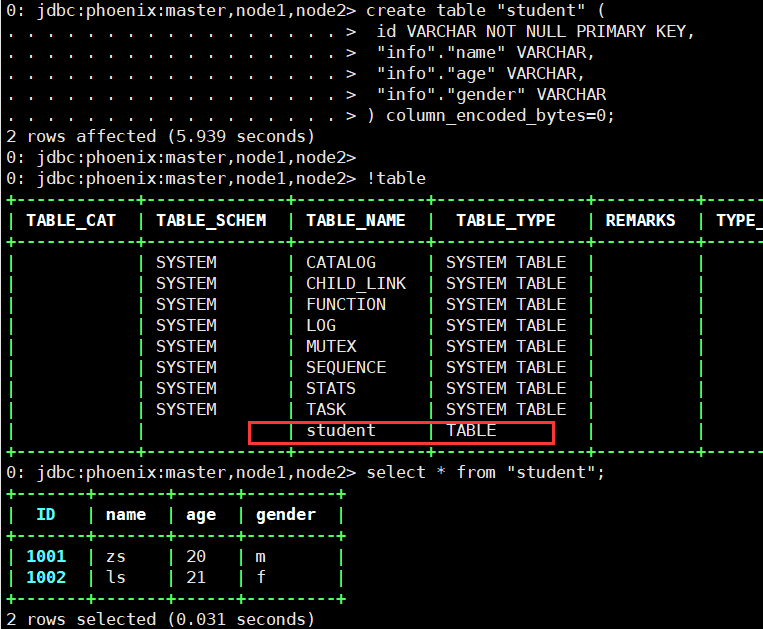
In the first case, create a table mapping as follows:
create table "student" ( id VARCHAR NOT NULL PRIMARY KEY, "info"."name" VARCHAR, "info"."age" VARCHAR, "info"."gender" VARCHAR ) column_encoded_bytes=0;
Column must be added when creating table mapping_ encoded_ bytes=0
1.3.3 difference between view mapping and table mapping
For the associated table created with create table, if the table is modified, the source data will also change. At the same time, if the associated table is deleted, the source table will also be deleted.
The associated table created with create view cannot modify the data, but can only query the data. If the view is deleted, the source data will not change.
2. Phoenix secondary index
For Hbase, the only way to accurately locate a row of records is to query through rowkey. If you do not search data through rowkey, you must compare the values of each row row row by row. For large tables, the cost of full table scanning is unacceptable.
2.1. Enable index support
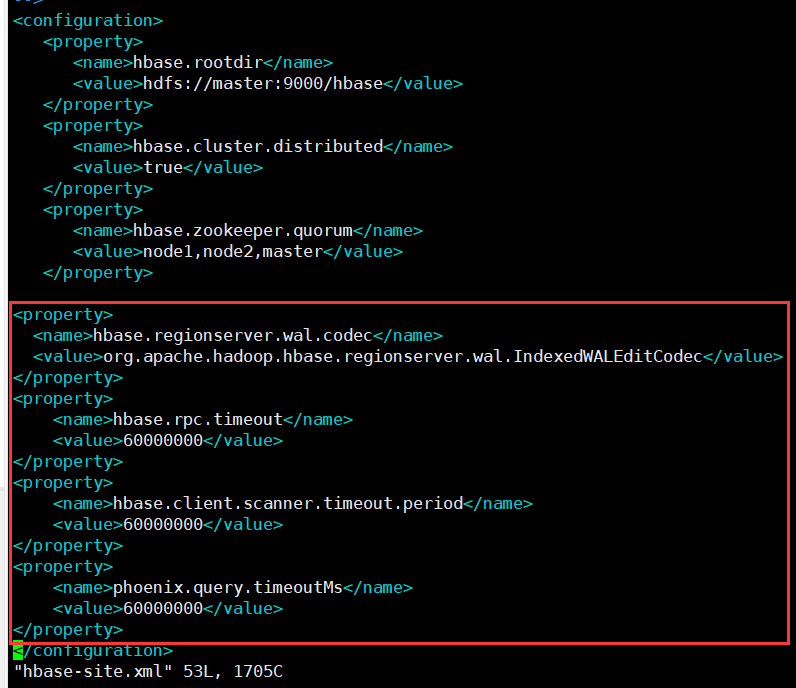
Add the following configuration in hbase-site.xml under the conf directory of HBase, and synchronize the modified configuration file to other nodes
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
 Modify hbase-site.xml in the bin directory under the phoenix directory
Modify hbase-site.xml in the bin directory under the phoenix directory
Add the following
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
Restart hbase and Phoenix after modification
2.2. Global index
the global index is suitable for scenarios with more reads and less writes. If a global index is used, reading data basically does not lose performance, and all performance losses come from writing data. The addition, deletion and modification of the data table will update the related index table (if the data is deleted, the data in the index table will also be deleted; if the data is increased, the data in the index table will also be increased)
note: for global indexes, by default, Phoenix will not use the index table unless hint is used if the column retrieved in the query statement is not in the index table.
Create DIANXIN.sql and upload data file DIANXIN.csv
# Create DIANXIN.sql
CREATE TABLE IF NOT EXISTS DIANXIN (
mdn VARCHAR ,
start_date VARCHAR ,
end_date VARCHAR ,
county VARCHAR,
x DOUBLE ,
y DOUBLE,
bsid VARCHAR,
grid_id VARCHAR,
biz_type VARCHAR,
event_type VARCHAR ,
data_source VARCHAR ,
CONSTRAINT PK PRIMARY KEY (mdn,start_date)
) column_encoded_bytes=0;
phoenix import data
psql.py master,node1,node2 DIANXIN.sql DIANXIN.csv
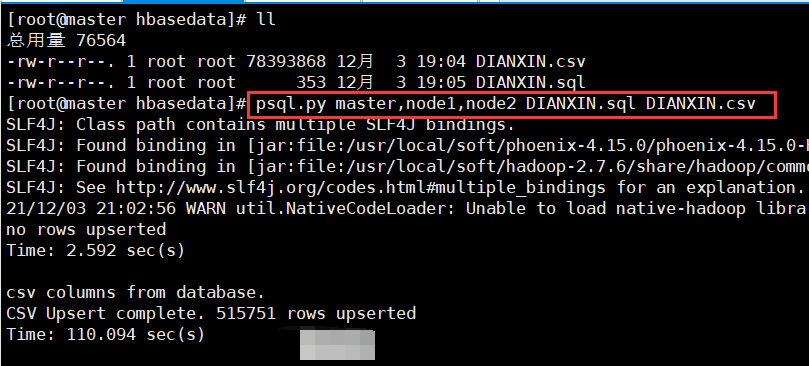
Successfully imported data
2.2.1. Create a global index
Principle: creating an index is to splice the index column to be created with rowkey, and then use the prefix filtering of rowkey to realize millisecond query
Creating a global index is a little slow
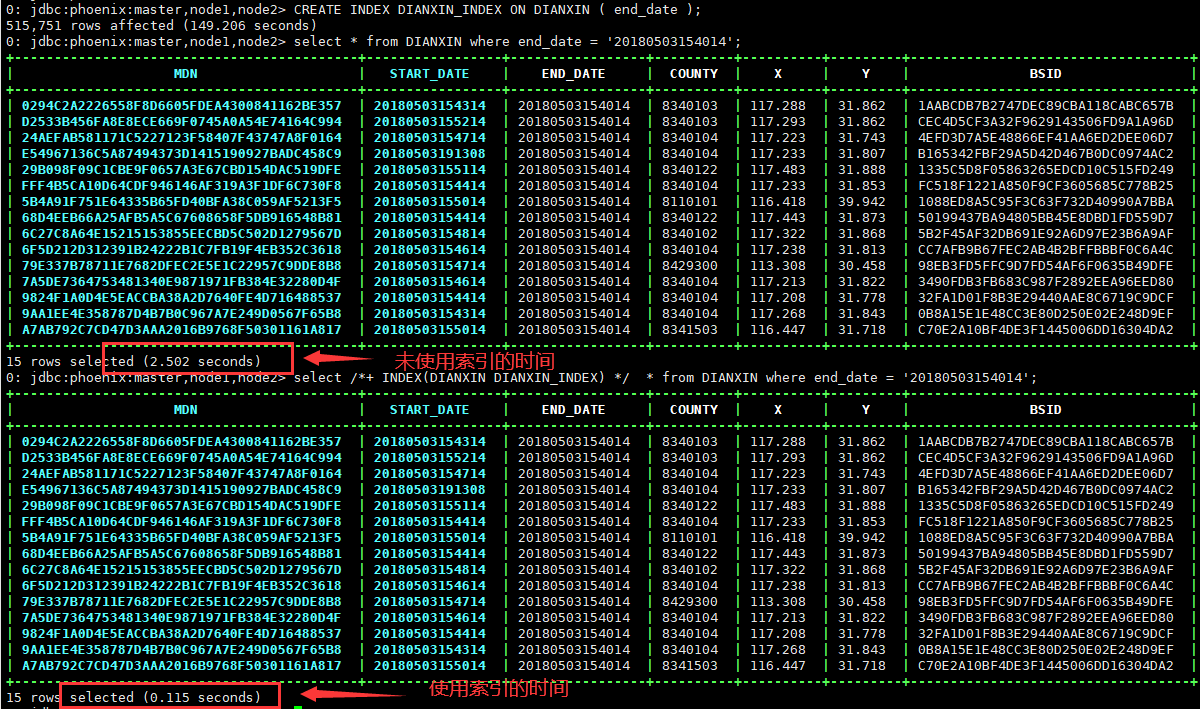
# Create global index CREATE INDEX DIANXIN_INDEX ON DIANXIN ( end_date ); # Query data (index not effective) select * from DIANXIN where end_date = '20180503154014'; # Force use of index (index effective) hint select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014'; select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014' and start_date = '20180503154614'; # Fetch index column, (index effective) select end_date from DIANXIN where end_date = '20180503154014'; # Create multi column index CREATE INDEX DIANXIN_INDEX1 ON DIANXIN ( end_date,COUNTY ); # Multi condition query (index validation) select end_date,MDN,COUNTY from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # Query all columns (index not effective) select * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # Query all columns (index effective) select /*+ INDEX(DIANXIN DIANXIN_INDEX1) */ * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # Single condition (index not effective) select end_date from DIANXIN where COUNTY = '8340103'; # Single condition (index effective) end_date before select COUNTY from DIANXIN where end_date = '20180503154014'; # Delete index drop index DIANXIN_INDEX on DIANXIN;
2.3 local index
local indexes are suitable for scenarios with more writes and less reads, or scenarios with limited storage space. Like the global index, Phoenix will automatically select whether to use the local index when querying. Because the index data and the original data are stored on the same machine, the local index avoids the overhead of network data transmission, so it is more suitable for the scenario of multiple writes. Since it is impossible to determine in advance which Region the data is in, you need to check the data in each Region when reading the data, resulting in some performance loss.
Note: for local indexes, the index table will be used regardless of whether hint is specified in the query or whether the query columns are all in the index table.
# Create local index CREATE LOCAL INDEX DIANXIN_LOCAL_IDEX ON DIANXIN(grid_id); # Index validation select grid_id from dianxin where grid_id='117285031820040'; # Index validation select * from dianxin where grid_id='117285031820040';
2.4 coverage index
overwrite index is to store the original data in the index data table, so that the query results can be returned directly without going to the original table of HBase to obtain data.
Note: both the select column and the where column of the query need to appear in the index.
# Create overlay index CREATE INDEX DIANXIN_INDEX_COVER ON DIANXIN ( x,y ) INCLUDE ( county ); # Query all columns (index not effective) select * from DIANXIN where x=117.288 and y =31.822; # Force use of index (index takes effect) select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ * from DIANXIN where x=117.288 and y =31.822; # The column in the query index (effective index) mdn is part of the RowKey of the DIANXIN table select x,y,county from DIANXIN where x=117.288 and y =31.822; select mdn,x,y,county from DIANXIN where x=117.288 and y =31.822; # Query criteria must be placed in the index. Columns in select can be placed in INCLUDE (save data in the index) select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ x,y,count(*) from DIANXIN group by x,y;
3,Phoenix JDBC
Add dependency
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.15.0-HBase-1.4</version>
</dependency>
Sample code
Connection conn = DriverManager.getConnection("jdbc:phoenix:master,node1,node2:2181");
PreparedStatement ps = conn.prepareStatement("select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date=?");
ps.setString(1, "20180503212649");
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String mdn = rs.getString("mdn");
String start_date = rs.getString("start_date");
String end_date = rs.getString("end_date");
String x = rs.getString("x");
String y = rs.getString("y");
String county = rs.getString("county");
System.out.println(mdn + "\t" + start_date + "\t" + end_date + "\t" + x + "\t" + y + "\t" + county);
}
ps.close();
conn.close();