Preface
Phoenix is a project that I haven't had much contact with. When a company I met last year used Phoenix to analyze tens of billions of records and delay in returning them at the second level, I slowly explored the inside of some phoenix. Last week, I talked with a Phoenix PMC & Committer about the location and future development of Phoenix, and found that Phoenix is still competitive. From the recent releases of Phoenix, Phoenix is also developing rapidly. Phoenix Con has also been organized in the Phoenix community to promote phoenix: PhoenixCon 2017 . The purpose of this paper is to sort out the structure and inside story of phoenix, and how Phoenix supports real-time analysis of massive data.
Framework
phoenix is specifically enhanced for HBase. Specifically, there are several aspects of HBase:
- HBase is relatively low-level and has no SQL interface. For those students who want to use SQL, the cost of conversion is high.
- HBase does not support secondary indexing (HBase itself has some solutions, but phoenix is the best one)
- HBase does not support transactions
In recent years, from SQL to NO-SQL, to the rise of New SQL. In fact, NewSQL itself has no major technological innovations (except for hardware such as persistent memory itself), just architecture innovation or a hybrid architecture. It doesn't matter whether Phoenix is NewSQL or not. What matters is what problems it solves.
The roughly phoenix embedded in HBase is shown below.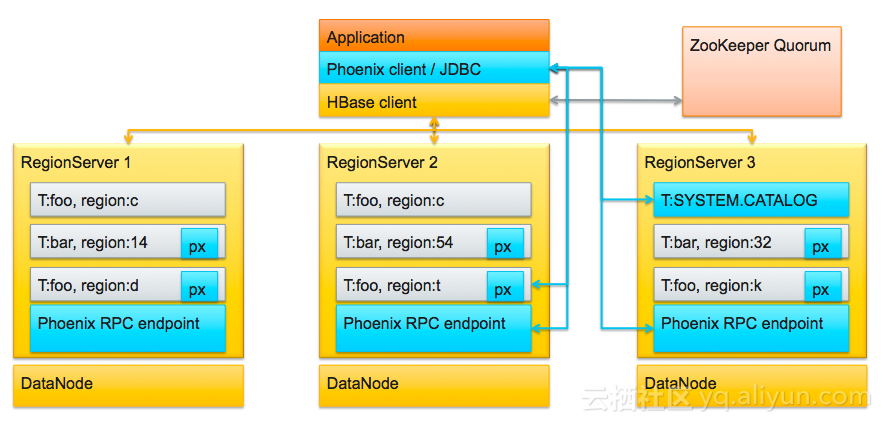
phoenix mainly adds secondary index and SQL support to HBase. As for things and some other support, it's a icing on the cake. The more phoenix looks at it, the more NewSQL it becomes. phoenix's official documents are relatively complete, so I will not move them.
- secondary indexing: http://phoenix.apache.org/secondary_indexing.html
- standard SQL: https://phoenix.apache.org/language/index.html
In particular:
- Support join (hash joinSort-Merge Join)
- Optimizing related SQL (now docking Calcite: http://calcite.apache.org/ )
- Support jdbc direct access
performance
phoenix is suitable for real-time analysis of massive data.
- phoenix basically queries a small amount of data on massive data by establishing an index, and basically returns it in real time.
- phoenix also supports some complex SQL operations, including join, sub-query, etc.
- phoenix is not suitable for ETL, such as 10T data to 10T data.
Here's a comparison with Hadoop hive: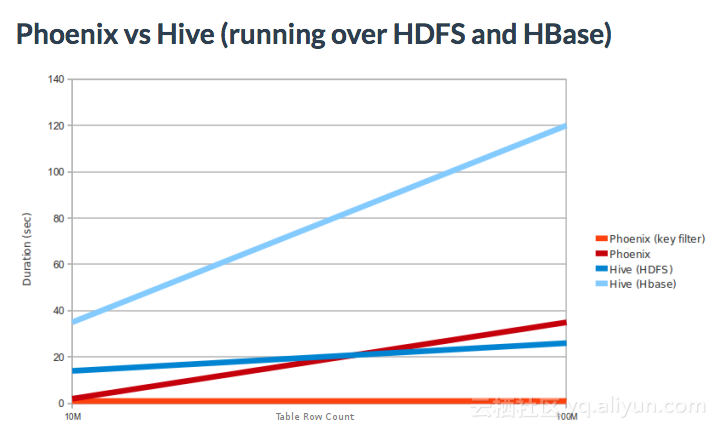
Come from: https://phoenix.apache.org/performance.html
Among the four scenarios, Hive On HBase is the worst and phoenix (key filter) is the fastest. The reason is that phoenix (key filter) has left the index and the query time is less than 1 s. In addition, compared with phoenix on HDFS, Hive on HDFS has a dividing line of about 5000w data volume and a time of about 20 seconds. In fact, hive start-up time is about 5 seconds, and another MR/TEZ job is about 10 seconds (with some optimization in the follow-up).
Test data: http://phoenix-bin.github.io/client/performance/phoenix-20160718043634.htm
It includes some major scenarios, such as Aggregation, Count Distinct, IN/LIKE Clause, LIMIT. The test data set is basically a million-level, and takes about a few seconds.
Cloud HBase
at present Cloud HBase Phoenix version 4.6 is also supported, and users can download it directly. http://hbase-cloud2.oss-cn-hangzhou.aliyuncs.com/phoenix-4.6.0-HBase-1.1.tar.gz
Let's briefly demonstrate the function of join. https://phoenix.apache.org/joins.html#joining-tables-with-indices-eg1
CREATE TABLE IF NOT EXISTS Customers( CustomerID VARCHAR NOT NULL, CustomerName VARCHAR, Country VARCHAR CONSTRAINT pk PRIMARY KEY(CustomerID) ); CREATE TABLE IF NOT EXISTS Items( ItemID VARCHAR NOT NULL, ItemName VARCHAR, Price Decimal CONSTRAINT pk PRIMARY KEY(ItemID) ); SELECT O.OrderID, C.CustomerName FROM ORDERS AS O INNER JOIN CUSTOMERS AS C ON O.CustomerID = C.CustomerID; 0: jdbc:phoenix:hb-bp18zlo0b209p7g23-001.hbas> CREATE INDEX iOrders ON Orders (ItemID) INCLUDE (CustomerID, Quantity); 5 rows affected (1.519 seconds) 0: jdbc:phoenix:hb-bp18zlo0b209p7g23-001.hbas> CREATE INDEX i2Orders ON Orders (CustomerID) INCLUDE (ItemID, Quantity); 5 rows affected (1.502 seconds) 0: jdbc:phoenix:hb-bp18zlo0b209p7g23-001.hbas> CREATE INDEX iItems ON Items (ItemName) INCLUDE (Price); 6 rows affected (1.427 seconds) 0: jdbc:phoenix:hb-bp18zlo0b209p7g23-001.hbas> SELECT O.OrderID, C.CustomerName, C.Country, O.Date . . . . . . . . . . . . . . . . . . . . . . .> FROM Orders AS O . . . . . . . . . . . . . . . . . . . . . . .> INNER JOIN Customers AS C . . . . . . . . . . . . . . . . . . . . . . .> ON O.CustomerID = C.CustomerID; +------------------------------------------+------------------------------------------+------------------------------------------+-------------------------+ | O.ORDERID | C.CUSTOMERNAME | C.COUNTRY | O.DATE | +------------------------------------------+------------------------------------------+------------------------------------------+-------------------------+ | 1630781 | Alps Nordic AB | Sweden | 0009-01-22 13:00:00.000 | | 1630782 | Salora Oy | Finland | 0009-02-22 13:00:00.000 | | 1630783 | Logica | Belgium | 0009-03-22 13:00:00.000 | | 1630784 | Alps Nordic AB | Sweden | 0009-04-22 13:00:00.000 | | 1630785 | Deister Electronics | Germany | 0009-05-22 13:00:00.000 | +------------------------------------------+------------------------------------------+------------------------------------------+-------------------------+ 5 rows selected (0.136 seconds) 0: jdbc:phoenix:hb-bp18zlo0b209p7g23-001.hbas> SELECT ItemName, sum(Price * Quantity) AS OrderValue . . . . . . . . . . . . . . . . . . . . . . .> FROM Items . . . . . . . . . . . . . . . . . . . . . . .> JOIN Orders . . . . . . . . . . . . . . . . . . . . . . .> ON Items.ItemID = Orders.ItemID . . . . . . . . . . . . . . . . . . . . . . .> WHERE Orders.CustomerID > 'C002' . . . . . . . . . . . . . . . . . . . . . . .> GROUP BY ItemName; +------------------------------------------+------------------------------------------+ | ITEMNAME | ORDERVALUE | +------------------------------------------+------------------------------------------+ | BX016 | 10374 | | MU3508 | 1.44E+4 | | XT2217 | 46436 | +------------------------------------------+------------------------------------------+ 3 rows selected (0.184 seconds)
Last
Welcome to Ali Yunyun HBase Technology Exchange Group: https://yq.aliyun.com/articles/82911